 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Optimizers for MLPs in Tabular Deep Learning
Apr 16, 2026MLP is a heavily used backbone in modern deep learning (DL) architectures for supervised learning on tabular data, and AdamW is the go-to optimizer used to train tabular DL models. Unlike architecture design, however, the choice of optimizer for tabular DL has not been examined systematically, despite new optimizers showing promise in other domains. To fill this gap, we benchmark \Noptimizers optimizers on \Ndatasets tabular datasets for training MLP-based models in the standard supervised learning setting under a shared experiment protocol. Our main finding is that the Muon optimizer consistently outperforms AdamW, and thus should be considered a strong and practical choice for practitioners and researchers, if the associated training efficiency overhead is affordable. Additionally, we find exponential moving average of model weights to be a simple yet effective technique that improves AdamW on vanilla MLPs, though its effect is less consistent across model variants.
TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling
Oct 31, 2024



Deep learning architectures for supervised learning on tabular data range from simple multilayer perceptrons (MLP) to sophisticated Transformers and retrieval-augmented methods. This study highlights a major, yet so far overlooked opportunity for substantially improving tabular MLPs: namely, parameter-efficient ensembling -- a paradigm for implementing an ensemble of models as one model producing multiple predictions. We start by developing TabM -- a simple model based on MLP and our variations of BatchEnsemble (an existing technique). Then, we perform a large-scale evaluation of tabular DL architectures on public benchmarks in terms of both task performance and efficiency, which renders the landscape of tabular DL in a new light. Generally, we show that MLPs, including TabM, form a line of stronger and more practical models compared to attention- and retrieval-based architectures. In particular, we find that TabM demonstrates the best performance among tabular DL models. Lastly, we conduct an empirical analysis on the ensemble-like nature of TabM. For example, we observe that the multiple predictions of TabM are weak individually, but powerful collectively. Overall, our work brings an impactful technique to tabular DL, analyses its behaviour, and advances the performance-efficiency trade-off with TabM -- a simple and powerful baseline for researchers and practitioners.
TabReD: A Benchmark of Tabular Machine Learning in-the-Wild
Jun 27, 2024



Benchmarks that closely reflect downstream application scenarios are essential for the streamlined adoption of new research in tabular machine learning (ML). In this work, we examine existing tabular benchmarks and find two common characteristics of industry-grade tabular data that are underrepresented in the datasets available to the academic community. First, tabular data often changes over time in real-world deployment scenarios. This impacts model performance and requires time-based train and test splits for correct model evaluation. Yet, existing academic tabular datasets often lack timestamp metadata to enable such evaluation. Second, a considerable portion of datasets in production settings stem from extensive data acquisition and feature engineering pipelines. For each specific dataset, this can have a different impact on the absolute and relative number of predictive, uninformative, and correlated features, which in turn can affect model selection. To fill the aforementioned gaps in academic benchmarks, we introduce TabReD -- a collection of eight industry-grade tabular datasets covering a wide range of domains from finance to food delivery services. We assess a large number of tabular ML models in the feature-rich, temporally-evolving data setting facilitated by TabReD. We demonstrate that evaluation on time-based data splits leads to different methods ranking, compared to evaluation on random splits more common in academic benchmarks. Furthermore, on the TabReD datasets, MLP-like architectures and GBDT show the best results, while more sophisticated DL models are yet to prove their effectiveness.
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Jul 26, 2023



Deep learning (DL) models for tabular data problems are receiving increasingly more attention, while the algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution. Following the recent trends in other domains, such as natural language processing and computer vision, several retrieval-augmented tabular DL models have been recently proposed. For a given target object, a retrieval-based model retrieves other relevant objects, such as the nearest neighbors, from the available (training) data and uses their features or even labels to make a better prediction. However, we show that the existing retrieval-based tabular DL solutions provide only minor, if any, benefits over the properly tuned simple retrieval-free baselines. Thus, it remains unclear whether the retrieval-based approach is a worthy direction for tabular DL. In this work, we give a strong positive answer to this question. We start by incrementally augmenting a simple feed-forward architecture with an attention-like retrieval component similar to those of many (tabular) retrieval-based models. Then, we highlight several details of the attention mechanism that turn out to have a massive impact on the performance on tabular data problems, but that were not explored in prior work. As a result, we design TabR -- a simple retrieval-based tabular DL model which, on a set of public benchmarks, demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed ``GBDT-friendly'' benchmark (see the first figure).
Revisiting Pretraining Objectives for Tabular Deep Learning
Jul 12, 2022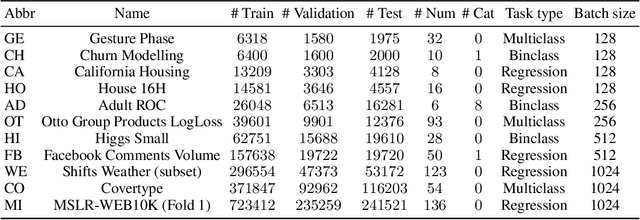
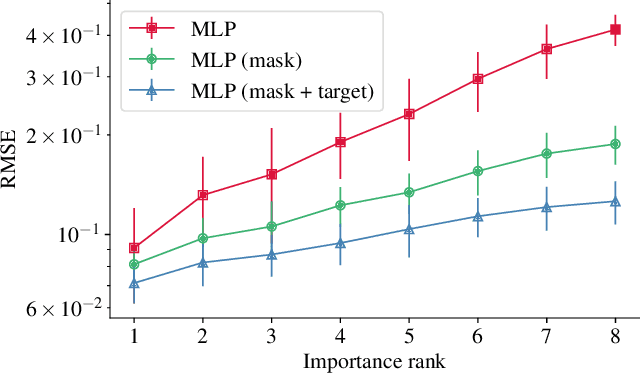
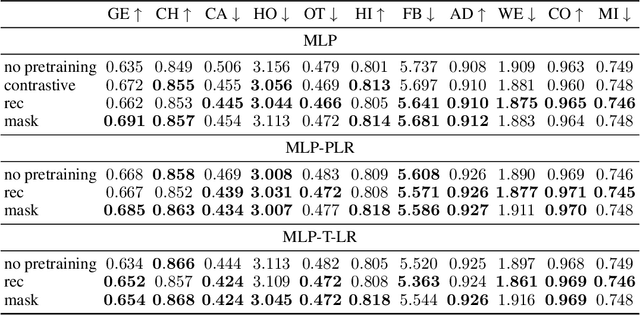
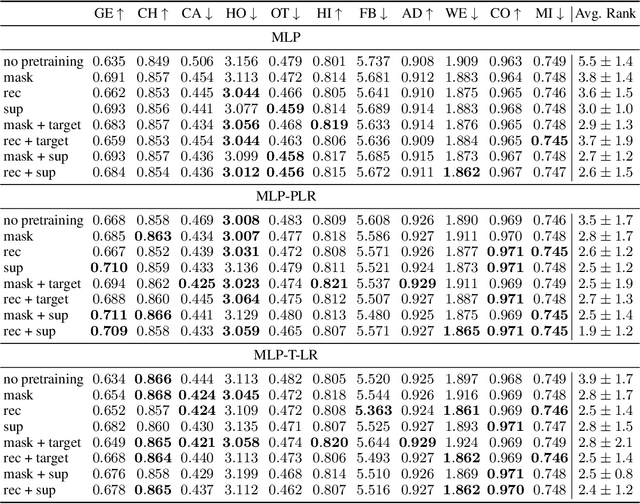
Recent deep learning models for tabular data currently compete with the traditional ML models based on decision trees (GBDT). Unlike GBDT, deep models can additionally benefit from pretraining, which is a workhorse of DL for vision and NLP. For tabular problems, several pretraining methods were proposed, but it is not entirely clear if pretraining provides consistent noticeable improvements and what method should be used, since the methods are often not compared to each other or comparison is limited to the simplest MLP architectures. In this work, we aim to identify the best practices to pretrain tabular DL models that can be universally applied to different datasets and architectures. Among our findings, we show that using the object target labels during the pretraining stage is beneficial for the downstream performance and advocate several target-aware pretraining objectives. Overall, our experiments demonstrate that properly performed pretraining significantly increases the performance of tabular DL models, which often leads to their superiority over GBDTs.
On Embeddings for Numerical Features in Tabular Deep Learning
Mar 15, 2022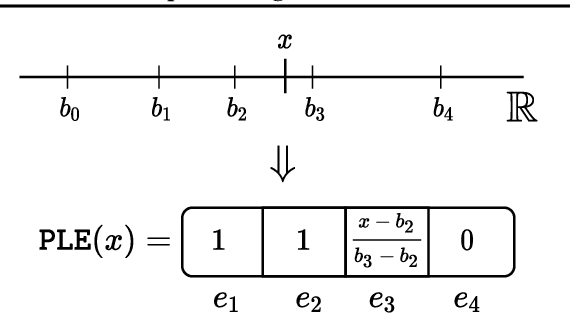

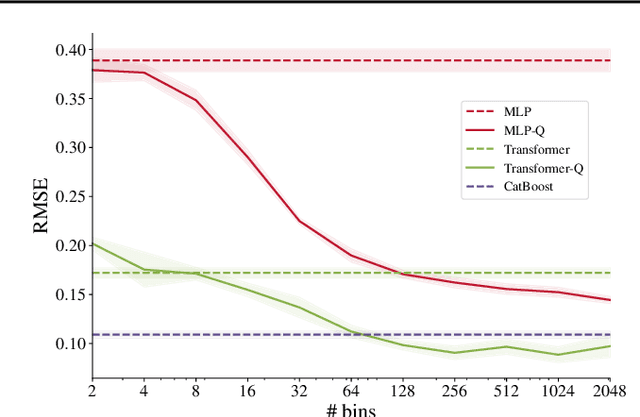

Recently, Transformer-like deep architectures have shown strong performance on tabular data problems. Unlike traditional models, e.g., MLP, these architectures map scalar values of numerical features to high-dimensional embeddings before mixing them in the main backbone. In this work, we argue that embeddings for numerical features are an underexplored degree of freedom in tabular DL, which allows constructing more powerful DL models and competing with GBDT on some traditionally GBDT-friendly benchmarks. We start by describing two conceptually different approaches to building embedding modules: the first one is based on a piecewise linear encoding of scalar values, and the second one utilizes periodic activations. Then, we empirically demonstrate that these two approaches can lead to significant performance boosts compared to the embeddings based on conventional blocks such as linear layers and ReLU activations. Importantly, we also show that embedding numerical features is beneficial for many backbones, not only for Transformers. Specifically, after proper embeddings, simple MLP-like models can perform on par with the attention-based architectures. Overall, we highlight embeddings for numerical features as an important design aspect with good potential for further improvements in tabular DL.
Revisiting Deep Learning Models for Tabular Data
Jun 22, 2021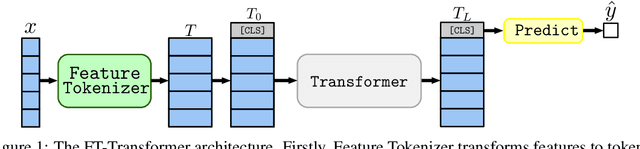
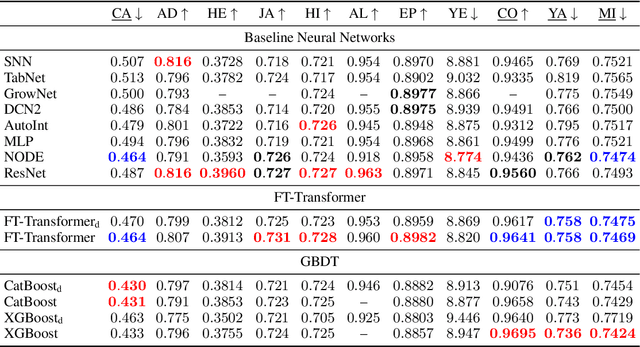
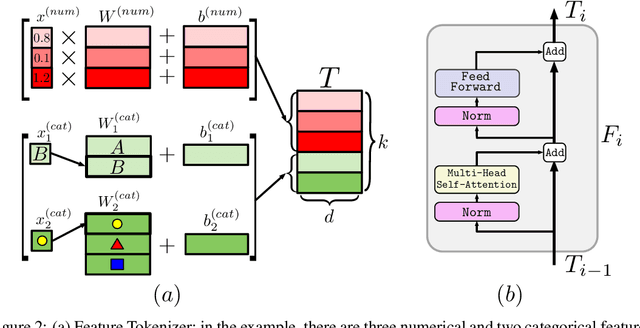
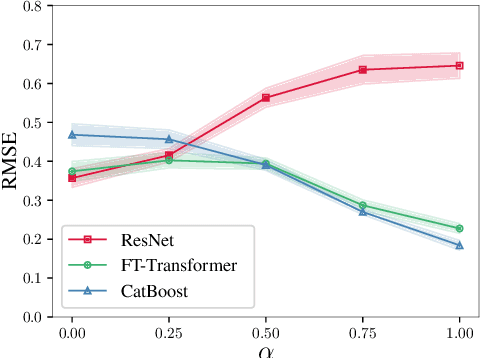
The necessity of deep learning for tabular data is still an unanswered question addressed by a large number of research efforts. The recent literature on tabular DL proposes several deep architectures reported to be superior to traditional "shallow" models like Gradient Boosted Decision Trees. However, since existing works often use different benchmarks and tuning protocols, it is unclear if the proposed models universally outperform GBDT. Moreover, the models are often not compared to each other, therefore, it is challenging to identify the best deep model for practitioners. In this work, we start from a thorough review of the main families of DL models recently developed for tabular data. We carefully tune and evaluate them on a wide range of datasets and reveal two significant findings. First, we show that the choice between GBDT and DL models highly depends on data and there is still no universally superior solution. Second, we demonstrate that a simple ResNet-like architecture is a surprisingly effective baseline, which outperforms most of the sophisticated models from the DL literature. Finally, we design a simple adaptation of the Transformer architecture for tabular data that becomes a new strong DL baseline and reduces the gap between GBDT and DL models on datasets where GBDT dominates.