 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adaptation through Synthetic Data: Fine-Tuning Large Language Models for German Law
Jan 20, 2026Large language models (LLMs) often struggle in specialized domains such as legal reasoning due to limited expert knowledge, resulting in factually incorrect outputs or hallucinations. This paper presents an effective method for adapting advanced LLMs to German legal question answering through a novel synthetic data generation approach. In contrast to costly human-annotated resources or unreliable synthetic alternatives, our approach systematically produces high-quality, diverse, and legally accurate question-answer pairs directly from authoritative German statutes. Using rigorous automated filtering methods and parameter-efficient fine-tuning techniques, we demonstrate that LLMs adapted with our synthetic dataset significantly outperform their baseline counterparts on German legal question answering tasks. Our results highlight the feasibility of using carefully designed synthetic data as a robust alternative to manual annotation in high-stakes, knowledge-intensive domains.
Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
Dec 28, 2025Recent Reinforcement Learning (RL) advances for Large Language Models (LLMs) have improved reasoning tasks, yet their resource-constrained application to medical imaging remains underexplored. We introduce ChexReason, a vision-language model trained via R1-style methodology (SFT followed by GRPO) using only 2,000 SFT samples, 1,000 RL samples, and a single A100 GPU. Evaluations on CheXpert and NIH benchmarks reveal a fundamental tension: GRPO recovers in-distribution performance (23% improvement on CheXpert, macro-F1 = 0.346) but degrades cross-dataset transferability (19% drop on NIH). This mirrors high-resource models like NV-Reason-CXR-3B, suggesting the issue stems from the RL paradigm rather than scale. We identify a generalization paradox where the SFT checkpoint uniquely improves on NIH before optimization, indicating teacher-guided reasoning captures more institution-agnostic features. Furthermore, cross-model comparisons show structured reasoning scaffolds benefit general-purpose VLMs but offer minimal gain for medically pre-trained models. Consequently, curated supervised fine-tuning may outperform aggressive RL for clinical deployment requiring robustness across diverse populations.
History Rhymes: Macro-Contextual Retrieval for Robust Financial Forecasting
Nov 16, 2025Financial markets are inherently non-stationary: structural breaks and macroeconomic regime shifts often cause forecasting models to fail when deployed out of distribution (OOD). Conventional multimodal approaches that simply fuse numerical indicators and textual sentiment rarely adapt to such shifts. We introduce macro-contextual retrieval, a retrieval-augmented forecasting framework that grounds each prediction in historically analogous macroeconomic regimes. The method jointly embeds macro indicators (e.g., CPI, unemployment, yield spread, GDP growth) and financial news sentiment in a shared similarity space, enabling causal retrieval of precedent periods during inference without retraining. Trained on seventeen years of S&P 500 data (2007-2023) and evaluated OOD on AAPL (2024) and XOM (2024), the framework consistently narrows the CV to OOD performance gap. Macro-conditioned retrieval achieves the only positive out-of-sample trading outcomes (AAPL: PF=1.18, Sharpe=0.95; XOM: PF=1.16, Sharpe=0.61), while static numeric, text-only, and naive multimodal baselines collapse under regime shifts. Beyond metric gains, retrieved neighbors form interpretable evidence chains that correspond to recognizable macro contexts, such as inflationary or yield-curve inversion phases, supporting causal interpretability and transparency. By operationalizing the principle that "financial history may not repeat, but it often rhymes," this work demonstrates that macro-aware retrieval yields robust, explainable forecasts under distributional change. All datasets, models, and source code are publicly available.
From Retinal Pixels to Patients: Evolution of Deep Learning Research in Diabetic Retinopathy Screening
Nov 14, 2025



Diabetic Retinopathy (DR) remains a leading cause of preventable blindness, with early detection critical for reducing vision loss worldwide. Over the past decade, deep learning has transformed DR screening, progressing from early convolutional neural networks trained on private datasets to advanced pipelines addressing class imbalance, label scarcity, domain shift, and interpretability. This survey provides the first systematic synthesis of DR research spanning 2016-2025, consolidating results from 50+ studies and over 20 datasets. We critically examine methodological advances, including self- and semi-supervised learning, domain generalization, federated training, and hybrid neuro-symbolic models, alongside evaluation protocols, reporting standards, and reproducibility challenges. Benchmark tables contextualize performance across datasets, while discussion highlights open gaps in multi-center validation and clinical trust. By linking technical progress with translational barriers, this work outlines a practical agenda for reproducible, privacy-preserving, and clinically deployable DR AI. Beyond DR, many of the surveyed innovations extend broadly to medical imaging at scale.
A Survey on Current Trends and Recent Advances in Text Anonymization
Aug 29, 2025The proliferation of textual data containing sensitive personal information across various domains requires robust anonymization techniques to protect privacy and comply with regulations, while preserving data usability for diverse and crucial downstream tasks. This survey provides a comprehensive overview of current trends and recent advances in text anonymization techniques. We begin by discussing foundational approaches, primarily centered on Named Entity Recognition, before examining the transformative impact of Large Language Models, detailing their dual role as sophisticated anonymizers and potent de-anonymization threats. The survey further explores domain-specific challenges and tailored solutions in critical sectors such as healthcare, law, finance, and education. We investigate advanced methodologies incorporating formal privacy models and risk-aware frameworks, and address the specialized subfield of authorship anonymization. Additionally, we review evaluation frameworks, comprehensive metrics, benchmarks, and practical toolkits for real-world deployment of anonymization solutions. This review consolidates current knowledge, identifies emerging trends and persistent challenges, including the evolving privacy-utility trade-off, the need to address quasi-identifiers, and the implications of LLM capabilities, and aims to guide future research directions for both academics and practitioners in this field.
Reasoning LLMs in the Medical Domain: A Literature Survey
Aug 26, 2025The emergence of advanced reasoning capabilities in Large Language Models (LLMs) marks a transformative development in healthcare applications. Beyond merely expanding functional capabilities, these reasoning mechanisms enhance decision transparency and explainability-critical requirements in medical contexts. This survey examines the transformation of medical LLMs from basic information retrieval tools to sophisticated clinical reasoning systems capable of supporting complex healthcare decisions. We provide a thorough analysis of the enabling technological foundations, with a particular focus on specialized prompting techniques like Chain-of-Thought and recent breakthroughs in Reinforcement Learning exemplified by DeepSeek-R1. Our investigation evaluates purpose-built medical frameworks while also examining emerging paradigms such as multi-agent collaborative systems and innovative prompting architectures. The survey critically assesses current evaluation methodologies for medical validation and addresses persistent challenges in field interpretation limitations, bias mitigation strategies, patient safety frameworks, and integration of multimodal clinical data. Through this survey, we seek to establish a roadmap for developing reliable LLMs that can serve as effective partners in clinical practice and medical research.
Towards Automated Regulatory Compliance Verification in Financial Auditing with Large Language Models
Jul 22, 2025The auditing of financial documents, historically a labor-intensive process, stands on the precipice of transformation. AI-driven solutions have made inroads into streamlining this process by recommending pertinent text passages from financial reports to align with the legal requirements of accounting standards. However, a glaring limitation remains: these systems commonly fall short in verifying if the recommended excerpts indeed comply with the specific legal mandates. Hence, in this paper, we probe the efficiency of publicly available Large Language Models (LLMs) in the realm of regulatory compliance across different model configurations. We place particular emphasis on comparing cutting-edge open-source LLMs, such as Llama-2, with their proprietary counterparts like OpenAI's GPT models. This comparative analysis leverages two custom datasets provided by our partner PricewaterhouseCoopers (PwC) Germany. We find that the open-source Llama-2 70 billion model demonstrates outstanding performance in detecting non-compliance or true negative occurrences, beating all their proprietary counterparts. Nevertheless, proprietary models such as GPT-4 perform the best in a broad variety of scenarios, particularly in non-English contexts.
* Accepted and published at BigData 2023, 10 pages, 3 figures, 5 tables
Advancing Risk and Quality Assurance: A RAG Chatbot for Improved Regulatory Compliance
Jul 22, 2025Risk and Quality (R&Q) assurance in highly regulated industries requires constant navigation of complex regulatory frameworks, with employees handling numerous daily queries demanding accurate policy interpretation. Traditional methods relying on specialized experts create operational bottlenecks and limit scalability. We present a novel Retrieval Augmented Generation (RAG) system leveraging Large Language Models (LLMs), hybrid search and relevance boosting to enhance R&Q query processing. Evaluated on 124 expert-annotated real-world queries, our actively deployed system demonstrates substantial improvements over traditional RAG approaches. Additionally, we perform an extensive hyperparameter analysis to compare and evaluate multiple configuration setups, delivering valuable insights to practitioners.
* Accepted and published at BigData 2024, 3 pages, 3 tables, 2 figures
Improving Zero-Shot Text Matching for Financial Auditing with Large Language Models
Aug 14, 2023


Auditing financial documents is a very tedious and time-consuming process. As of today, it can already be simplified by employing AI-based solutions to recommend relevant text passages from a report for each legal requirement of rigorous accounting standards. However, these methods need to be fine-tuned regularly, and they require abundant annotated data, which is often lacking in industrial environments. Hence, we present ZeroShotALI, a novel recommender system that leverages a state-of-the-art large language model (LLM) in conjunction with a domain-specifically optimized transformer-based text-matching solution. We find that a two-step approach of first retrieving a number of best matching document sections per legal requirement with a custom BERT-based model and second filtering these selections using an LLM yields significant performance improvements over existing approaches.
QURATOR: Innovative Technologies for Content and Data Curation
Apr 25, 2020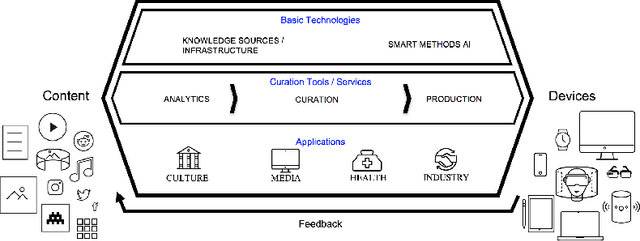
In all domains and sectors, the demand for intelligent systems to support the processing and generation of digital content is rapidly increasing. The availability of vast amounts of content and the pressure to publish new content quickly and in rapid succession requires faster, more efficient and smarter processing and generation methods. With a consortium of ten partners from research and industry and a broad range of expertise in AI, Machine Learning and Language Technologies, the QURATOR project, funded by the German Federal Ministry of Education and Research, develops a sustainable and innovative technology platform that provides services to support knowledge workers in various industries to address the challenges they face when curating digital content. The project's vision and ambition is to establish an ecosystem for content curation technologies that significantly pushes the current state of the art and transforms its region, the metropolitan area Berlin-Brandenburg, into a global centre of excellence for curation technologies.