 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating German Transformer Language Models with Syntactic Agreement Tests
Jul 07, 2020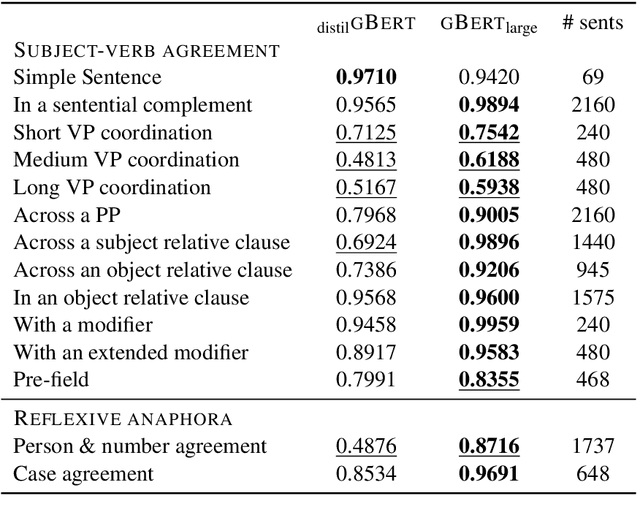
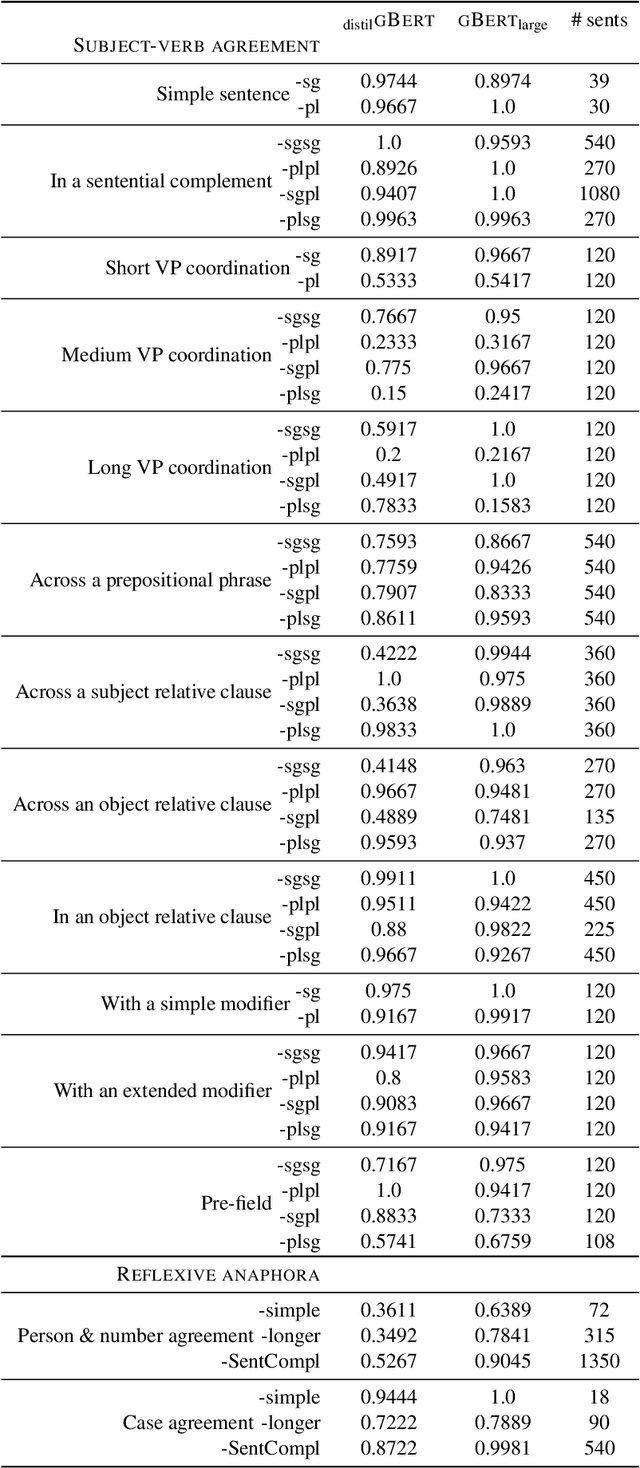
Pre-trained transformer language models (TLMs) have recently refashioned natural language processing (NLP): Most state-of-the-art NLP models now operate on top of TLMs to benefit from contextualization and knowledge induction. To explain their success, the scientific community conducted numerous analyses. Besides other methods, syntactic agreement tests were utilized to analyse TLMs. Most of the studies were conducted for the English language, however. In this work, we analyse German TLMs. To this end, we design numerous agreement tasks, some of which consider peculiarities of the German language. Our experimental results show that state-of-the-art German TLMs generally perform well on agreement tasks, but we also identify and discuss syntactic structures that push them to their limits.
* SwissText + KONVENS 2020
QURATOR: Innovative Technologies for Content and Data Curation
Apr 25, 2020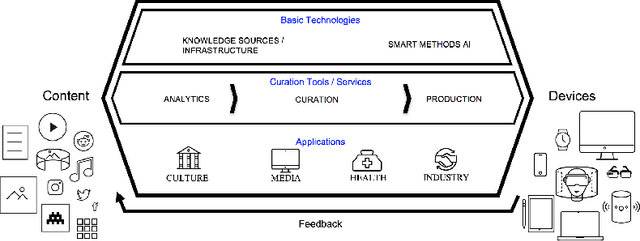
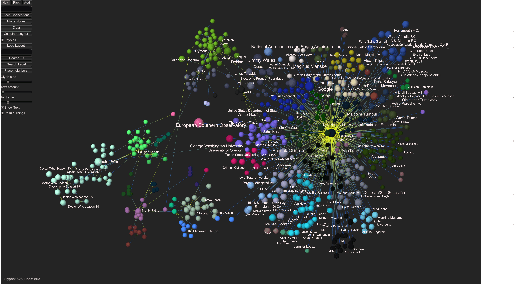
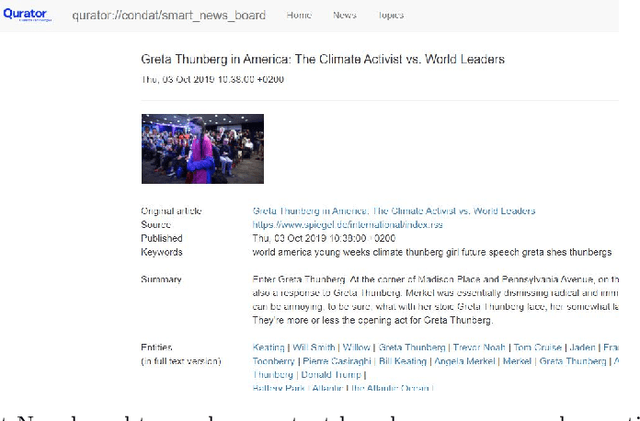
In all domains and sectors, the demand for intelligent systems to support the processing and generation of digital content is rapidly increasing. The availability of vast amounts of content and the pressure to publish new content quickly and in rapid succession requires faster, more efficient and smarter processing and generation methods. With a consortium of ten partners from research and industry and a broad range of expertise in AI, Machine Learning and Language Technologies, the QURATOR project, funded by the German Federal Ministry of Education and Research, develops a sustainable and innovative technology platform that provides services to support knowledge workers in various industries to address the challenges they face when curating digital content. The project's vision and ambition is to establish an ecosystem for content curation technologies that significantly pushes the current state of the art and transforms its region, the metropolitan area Berlin-Brandenburg, into a global centre of excellence for curation technologies.
Towards Discourse Parsing-inspired Semantic Storytelling
Apr 25, 2020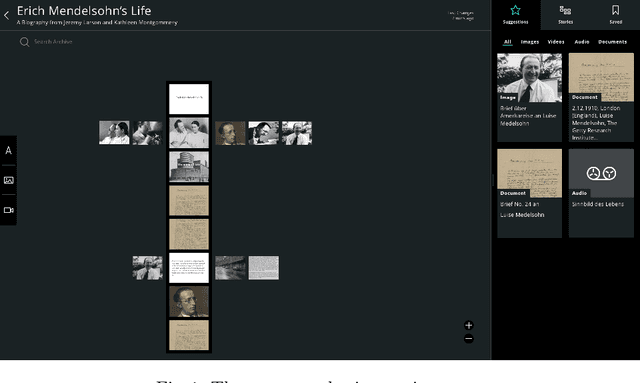

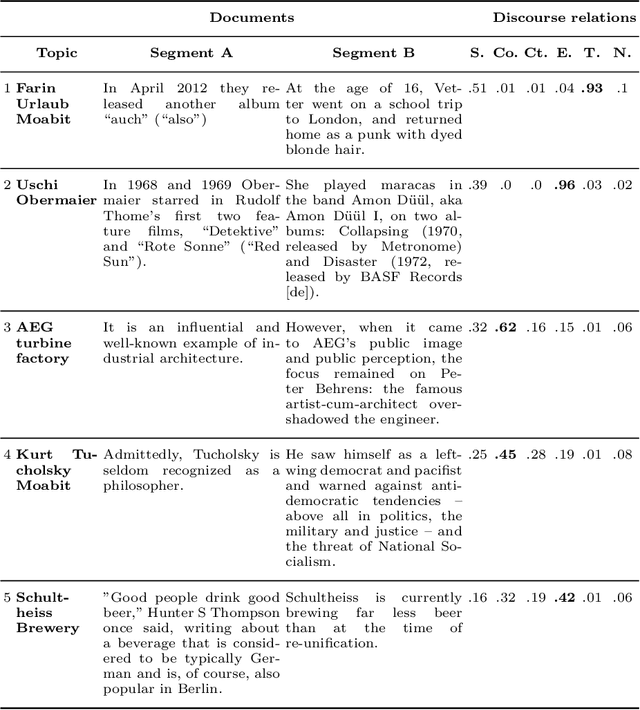
Previous work of ours on Semantic Storytelling uses text analytics procedures including Named Entity Recognition and Event Detection. In this paper, we outline our longer-term vision on Semantic Storytelling and describe the current conceptual and technical approach. In the project that drives our research we develop AI-based technologies that are verified by partners from industry. One long-term goal is the development of an approach for Semantic Storytelling that has broad coverage and that is, furthermore, robust. We provide first results on experiments that involve discourse parsing, applied to a concrete use case, "Explore the Neighbourhood!", which is based on a semi-automatically collected data set with documents about noteworthy people in one of Berlin's districts. Though automatically obtaining annotations for coherence relations from plain text is a non-trivial challenge, our preliminary results are promising. We envision our approach to be combined with additional features (NER, coreference resolution, knowledge graphs