 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Interpretability by generalized distillation in Supervised Classification
Dec 05, 2020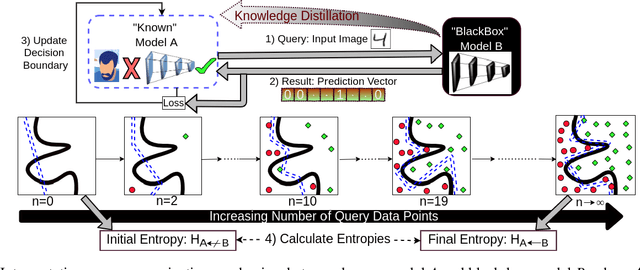
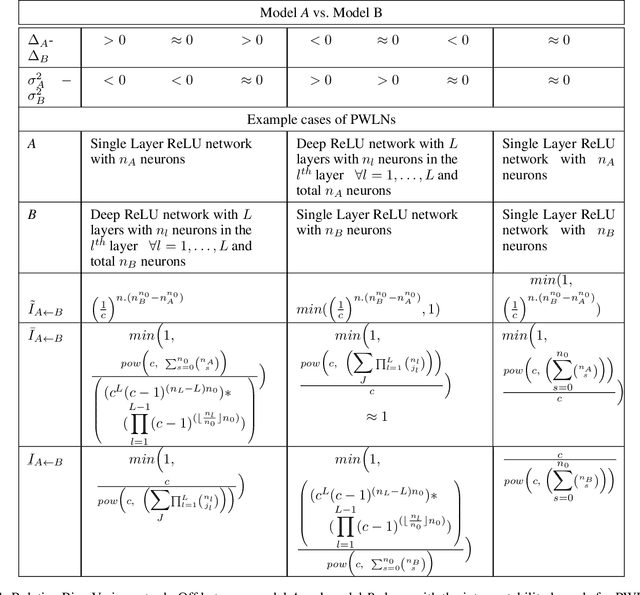
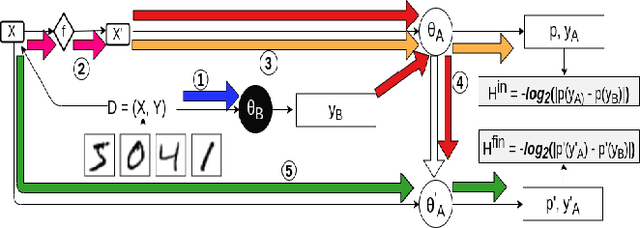
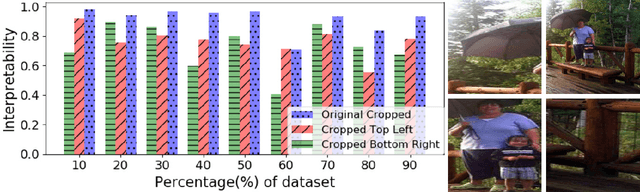
The ability to interpret decisions taken by Machine Learning (ML) models is fundamental to encourage trust and reliability in different practical applications. Recent interpretation strategies focus on human understanding of the underlying decision mechanisms of the complex ML models. However, these strategies are restricted by the subjective biases of humans. To dissociate from such human biases, we propose an interpretation-by-distillation formulation that is defined relative to other ML models. We generalize the distillation technique for quantifying interpretability, using an information-theoretic perspective, removing the role of ground-truth from the definition of interpretability. Our work defines the entropy of supervised classification models, providing bounds on the entropy of Piece-Wise Linear Neural Networks (PWLNs), along with the first theoretical bounds on the interpretability of PWLNs. We evaluate our proposed framework on the MNIST, Fashion-MNIST and Stanford40 datasets and demonstrate the applicability of the proposed theoretical framework in different supervised classification scenarios.
MAAD-Face: A Massively Annotated Attribute Dataset for Face Images
Dec 02, 2020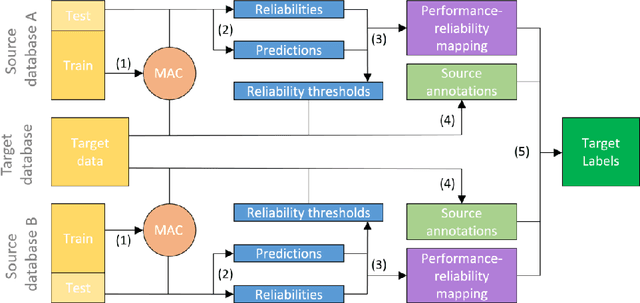

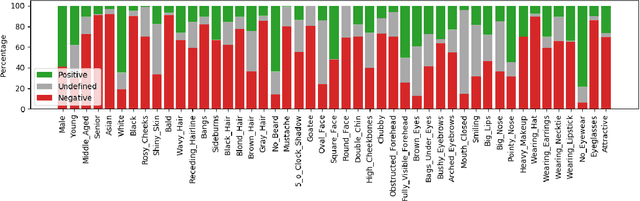
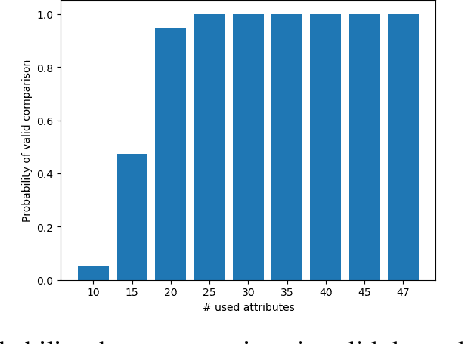
Soft-biometrics play an important role in face biometrics and related fields since these might lead to biased performances, threatens the user's privacy, or are valuable for commercial aspects. Current face databases are specifically constructed for the development of face recognition applications. Consequently, these databases contain large amount of face images but lack in the number of attribute annotations and the overall annotation correctness. In this work, we propose MAADFace, a new face annotations database that is characterized by the large number of its high-quality attribute annotations. MAADFace is build on the VGGFace2 database and thus, consists of 3.3M faces of over 9k individuals. Using a novel annotation transfer-pipeline that allows an accurate label-transfer from multiple source-datasets to a target-dataset, MAAD-Face consists of 123.9M attribute annotations of 47 different binary attributes. Consequently, it provides 15 and 137 times more attribute labels than CelebA and LFW. Our investigation on the annotation quality by three human evaluators demonstrated the superiority of the MAAD-Face annotations over existing databases. Additionally, we make use of the large amount of high-quality annotations from MAAD-Face to study the viability of soft-biometrics for recognition, providing insights about which attributes support genuine and imposter decisions. The MAAD-Face annotations dataset is publicly available.
Micro Stripes Analyses for Iris Presentation Attack Detection
Nov 03, 2020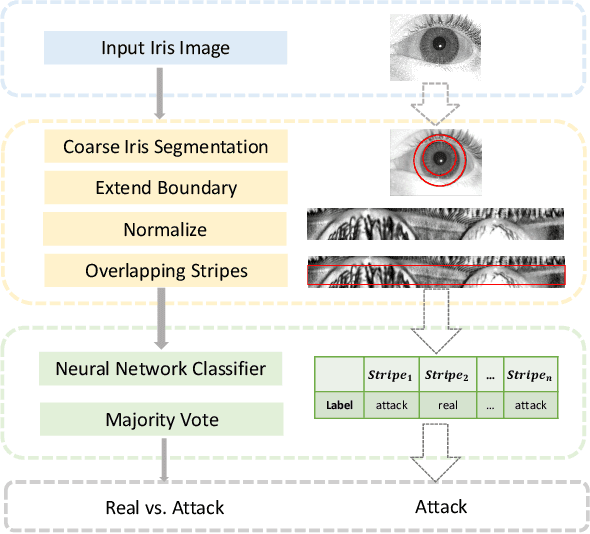


Iris recognition systems are vulnerable to the presentation attacks, such as textured contact lenses or printed images. In this paper, we propose a lightweight framework to detect iris presentation attacks by extracting multiple micro-stripes of expanded normalized iris textures. In this procedure, a standard iris segmentation is modified. For our presentation attack detection network to better model the classification problem, the segmented area is processed to provide lower dimensional input segments and a higher number of learning samples. Our proposed Micro Stripes Analyses (MSA) solution samples the segmented areas as individual stripes. Then, the majority vote makes the final classification decision of those micro-stripes. Experiments are demonstrated on five databases, where two databases (IIITD-WVU and Notre Dame) are from the LivDet-2017 Iris competition. An in-depth experimental evaluation of this framework reveals a superior performance compared with state-of-the-art algorithms. Moreover, our solution minimizes the confusion between textured (attack) and soft (bona fide) contact lens presentations.
On Benchmarking Iris Recognition within a Head-mounted Display for AR/VR Application
Oct 20, 2020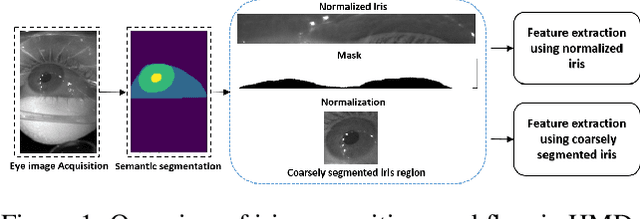
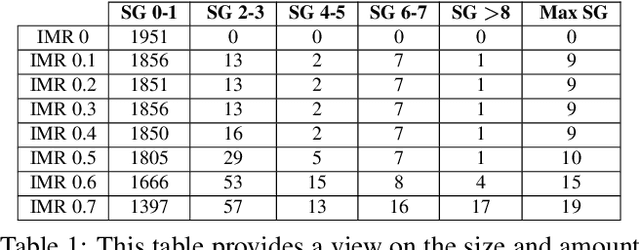
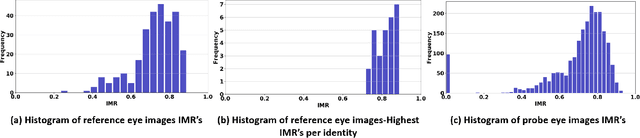

Augmented and virtual reality is being deployed in different fields of applications. Such applications might involve accessing or processing critical and sensitive information, which requires strict and continuous access control. Given that Head-Mounted Displays (HMD) developed for such applications commonly contains internal cameras for gaze tracking purposes, we evaluate the suitability of such setup for verifying the users through iris recognition. In this work, we first evaluate a set of iris recognition algorithms suitable for HMD devices by investigating three well-established handcrafted feature extraction approaches, and to complement it, we also present the analysis using four deep learning models. While taking into consideration the minimalistic hardware requirements of stand-alone HMD, we employ and adapt a recently developed miniature segmentation model (EyeMMS) for segmenting the iris. Further, to account for non-ideal and non-collaborative capture of iris, we define a new iris quality metric that we termed as Iris Mask Ratio (IMR) to quantify the iris recognition performance. Motivated by the performance of iris recognition, we also propose the continuous authentication of users in a non-collaborative capture setting in HMD. Through the experiments on a publicly available OpenEDS dataset, we show that performance with EER = 5% can be achieved using deep learning methods in a general setting, along with high accuracy for continuous user authentication.
Beyond Identity: What Information Is Stored in Biometric Face Templates?
Sep 21, 2020
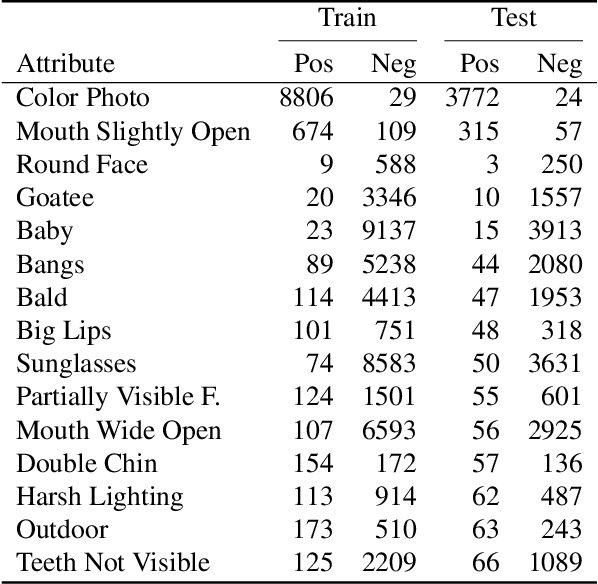
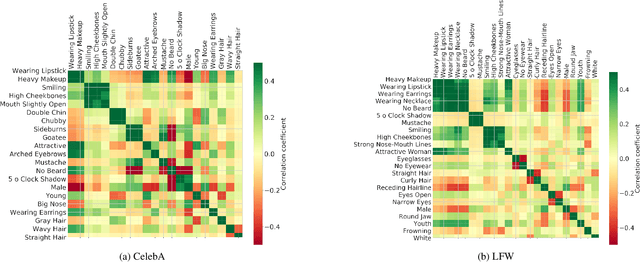
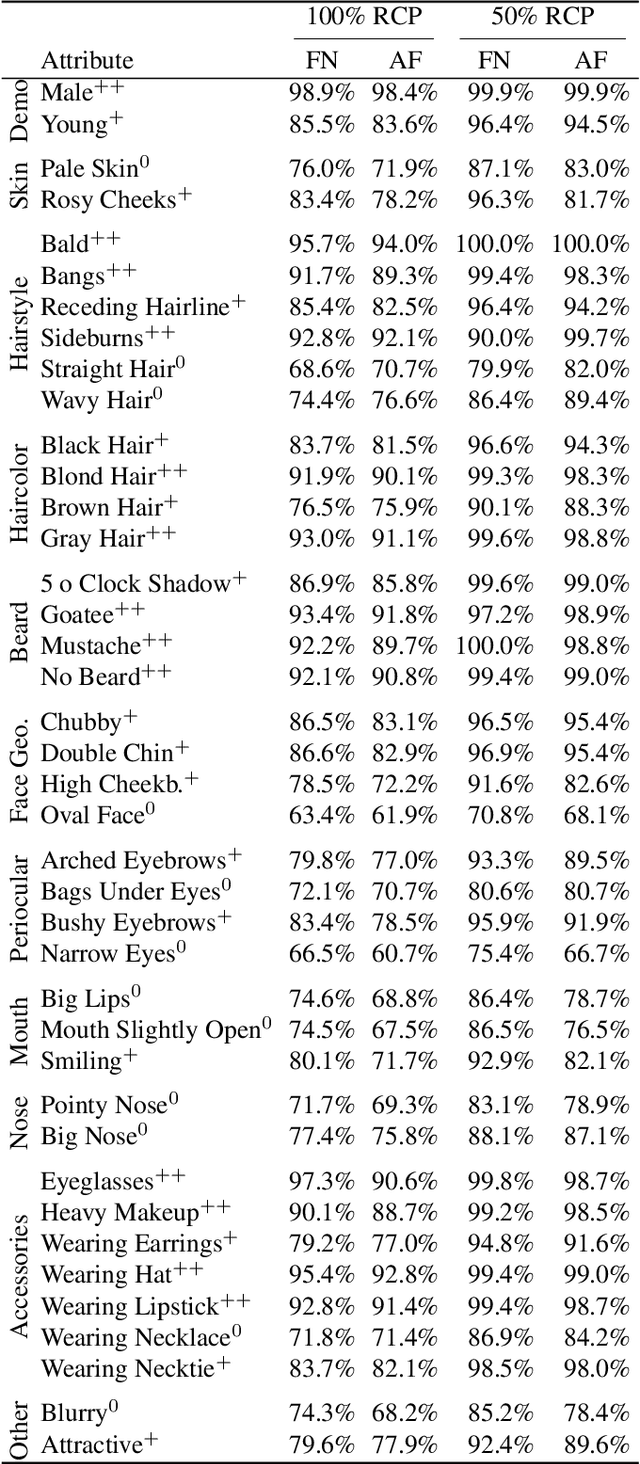
Deeply-learned face representations enable the success of current face recognition systems. Despite the ability of these representations to encode the identity of an individual, recent works have shown that more information is stored within, such as demographics, image characteristics, and social traits. This threatens the user's privacy, since for many applications these templates are expected to be solely used for recognition purposes. Knowing the encoded information in face templates helps to develop bias-mitigating and privacy-preserving face recognition technologies. This work aims to support the development of these two branches by analysing face templates regarding 113 attributes. Experiments were conducted on two publicly available face embeddings. For evaluating the predictability of the attributes, we trained a massive attribute classifier that is additionally able to accurately state its prediction confidence. This allows us to make more sophisticated statements about the attribute predictability. The results demonstrate that up to 74 attributes can be accurately predicted from face templates. Especially non-permanent attributes, such as age, hairstyles, haircolors, beards, and various accessories, found to be easily-predictable. Since face recognition systems aim to be robust against these variations, future research might build on this work to develop more understandable privacy preserving solutions and build robust and fair face templates.
Progressive Bilateral-Context Driven Model for Post-Processing Person Re-Identification
Sep 07, 2020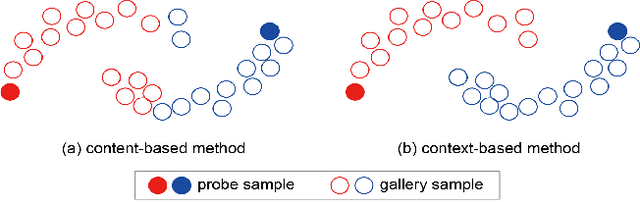
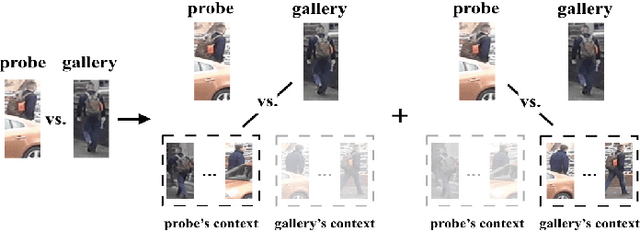

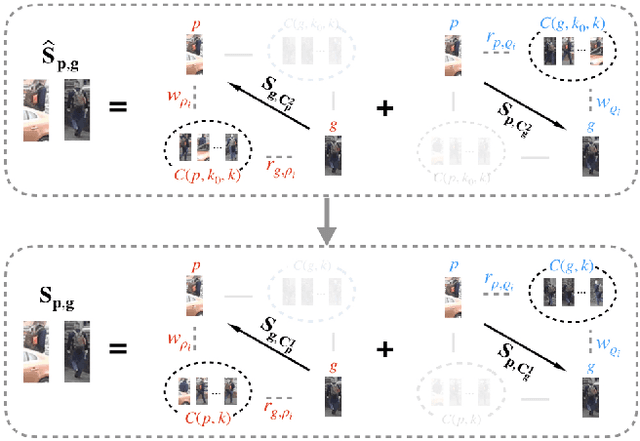
Most existing person re-identification methods compute pairwise similarity by extracting robust visual features and learning the discriminative metric. Owing to visual ambiguities, these content-based methods that determine the pairwise relationship only based on the similarity between them, inevitably produce a suboptimal ranking list. Instead, the pairwise similarity can be estimated more accurately along the geodesic path of the underlying data manifold by exploring the rich contextual information of the sample. In this paper, we propose a lightweight post-processing person re-identification method in which the pairwise measure is determined by the relationship between the sample and the counterpart's context in an unsupervised way. We translate the point-to-point comparison into the bilateral point-to-set comparison. The sample's context is composed of its neighbor samples with two different definition ways: the first order context and the second order context, which are used to compute the pairwise similarity in sequence, resulting in a progressive post-processing model. The experiments on four large-scale person re-identification benchmark datasets indicate that (1) the proposed method can consistently achieve higher accuracies by serving as a post-processing procedure after the content-based person re-identification methods, showing its state-of-the-art results, (2) the proposed lightweight method only needs about 6 milliseconds for optimizing the ranking results of one sample, showing its high-efficiency. Code is available at: https://github.com/123ci/PBCmodel.
Iris Liveness Detection Competition (LivDet-Iris) -- The 2020 Edition
Sep 01, 2020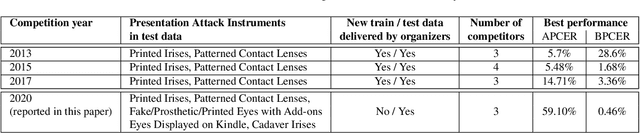
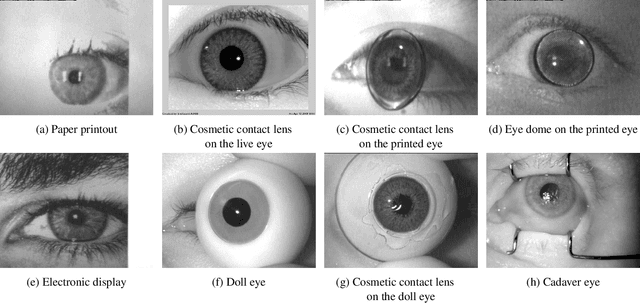
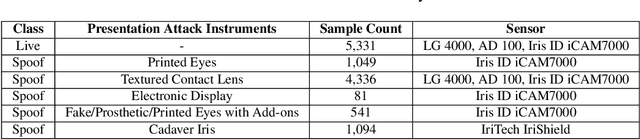
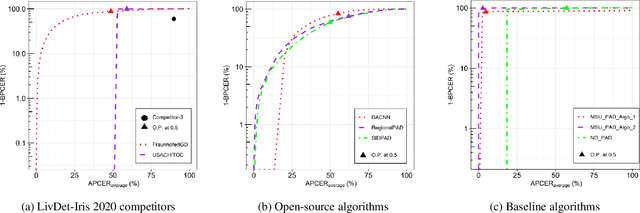
Launched in 2013, LivDet-Iris is an international competition series open to academia and industry with the aim to assess and report advances in iris Presentation Attack Detection (PAD). This paper presents results from the fourth competition of the series: LivDet-Iris 2020. This year's competition introduced several novel elements: (a) incorporated new types of attacks (samples displayed on a screen, cadaver eyes and prosthetic eyes), (b) initiated LivDet-Iris as an on-going effort, with a testing protocol available now to everyone via the Biometrics Evaluation and Testing (BEAT)(https://www.idiap.ch/software/beat/) open-source platform to facilitate reproducibility and benchmarking of new algorithms continuously, and (c) performance comparison of the submitted entries with three baseline methods (offered by the University of Notre Dame and Michigan State University), and three open-source iris PAD methods available in the public domain. The best performing entry to the competition reported a weighted average APCER of 59.10\% and a BPCER of 0.46\% over all five attack types. This paper serves as the latest evaluation of iris PAD on a large spectrum of presentation attack instruments.
The Effect of Wearing a Mask on Face Recognition Performance: an Exploratory Study
Aug 20, 2020
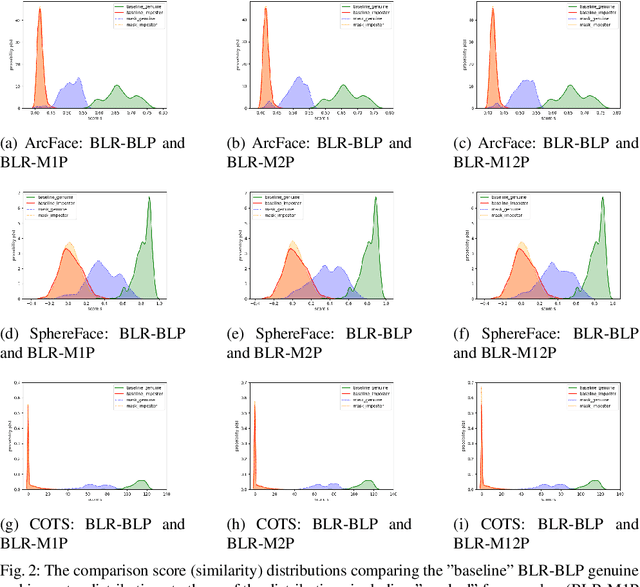
Face recognition has become essential in our daily lives as a convenient and contactless method of accurate identity verification. Process such as identity verification at automatic border control gates or the secure login to electronic devices are increasingly dependant on such technologies. The recent COVID-19 pandemic have increased the value of hygienic and contactless identity verification. However, the pandemic led to the wide use of face masks, essential to keep the pandemic under control. The effect of wearing a mask on face recognition in a collaborative environment is currently sensitive yet understudied issue. We address that by presenting a specifically collected database containing three session, each with three different capture instructions, to simulate realistic use cases. We further study the effect of masked face probes on the behaviour of three top-performing face recognition systems, two academic solutions and one commercial off-the-shelf (COTS) system.
AutoSNAP: Automatically Learning Neural Architectures for Instrument Pose Estimation
Jun 26, 2020

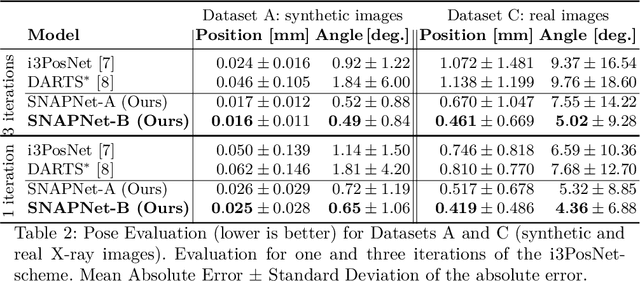
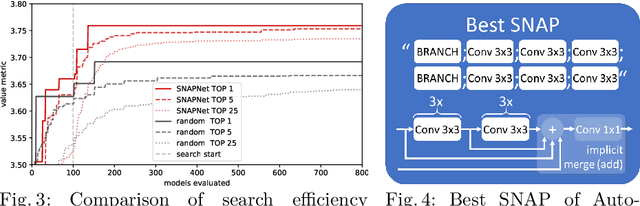
Despite recent successes, the advances in Deep Learning have not yet been fully translated to Computer Assisted Intervention (CAI) problems such as pose estimation of surgical instruments. Currently, neural architectures for classification and segmentation tasks are adopted ignoring significant discrepancies between CAI and these tasks. We propose an automatic framework (AutoSNAP) for instrument pose estimation problems, which discovers and learns the architectures for neural networks. We introduce 1)~an efficient testing environment for pose estimation, 2)~a powerful architecture representation based on novel Symbolic Neural Architecture Patterns (SNAPs), and 3)~an optimization of the architecture using an efficient search scheme. Using AutoSNAP, we discover an improved architecture (SNAPNet) which outperforms both the hand-engineered i3PosNet and the state-of-the-art architecture search method DARTS.
Style-transfer GANs for bridging the domain gap in synthetic pose estimator training
Apr 28, 2020


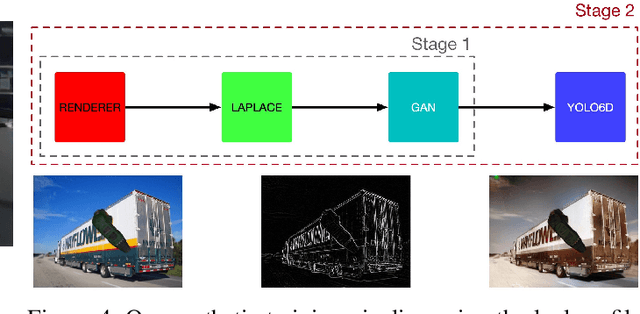
Given the dependency of current CNN architectures on a large training set, the possibility of using synthetic data is alluring as it allows generating a virtually infinite amount of labeled training data. However, producing such data is a non-trivial task as current CNN architectures are sensitive to the domain gap between real and synthetic data. We propose to adopt general-purpose GAN models for pixel-level image translation, allowing to formulate the domain gap itself as a learning problem. Here, we focus on training the single-stage YOLO6D object pose estimator on synthetic CAD geometry only, where not even approximate surface information is available. Our evaluation shows a considerable improvement in model performance when compared to a model trained with the same degree of domain randomization, while requiring only very little additional effort.