 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErased but Not Forgotten: How Backdoors Compromise Concept Erasure
Apr 29, 2025



The expansion of large-scale text-to-image diffusion models has raised growing concerns about their potential to generate undesirable or harmful content, ranging from fabricated depictions of public figures to sexually explicit images. To mitigate these risks, prior work has devised machine unlearning techniques that attempt to erase unwanted concepts through fine-tuning. However, in this paper, we introduce a new threat model, Toxic Erasure (ToxE), and demonstrate how recent unlearning algorithms, including those explicitly designed for robustness, can be circumvented through targeted backdoor attacks. The threat is realized by establishing a link between a trigger and the undesired content. Subsequent unlearning attempts fail to erase this link, allowing adversaries to produce harmful content. We instantiate ToxE via two established backdoor attacks: one targeting the text encoder and another manipulating the cross-attention layers. Further, we introduce Deep Intervention Score-based Attack (DISA), a novel, deeper backdoor attack that optimizes the entire U-Net using a score-based objective, improving the attack's persistence across different erasure methods. We evaluate five recent concept erasure methods against our threat model. For celebrity identity erasure, our deep attack circumvents erasure with up to 82% success, averaging 57% across all erasure methods. For explicit content erasure, ToxE attacks can elicit up to 9 times more exposed body parts, with DISA yielding an average increase by a factor of 2.9. These results highlight a critical security gap in current unlearning strategies.
IDiff-Face: Synthetic-based Face Recognition through Fizzy Identity-Conditioned Diffusion Models
Aug 10, 2023



The availability of large-scale authentic face databases has been crucial to the significant advances made in face recognition research over the past decade. However, legal and ethical concerns led to the recent retraction of many of these databases by their creators, raising questions about the continuity of future face recognition research without one of its key resources. Synthetic datasets have emerged as a promising alternative to privacy-sensitive authentic data for face recognition development. However, recent synthetic datasets that are used to train face recognition models suffer either from limitations in intra-class diversity or cross-class (identity) discrimination, leading to less optimal accuracies, far away from the accuracies achieved by models trained on authentic data. This paper targets this issue by proposing IDiff-Face, a novel approach based on conditional latent diffusion models for synthetic identity generation with realistic identity variations for face recognition training. Through extensive evaluations, our proposed synthetic-based face recognition approach pushed the limits of state-of-the-art performances, achieving, for example, 98.00% accuracy on the Labeled Faces in the Wild (LFW) benchmark, far ahead from the recent synthetic-based face recognition solutions with 95.40% and bridging the gap to authentic-based face recognition with 99.82% accuracy.
The Effect of Wearing a Mask on Face Recognition Performance: an Exploratory Study
Aug 20, 2020
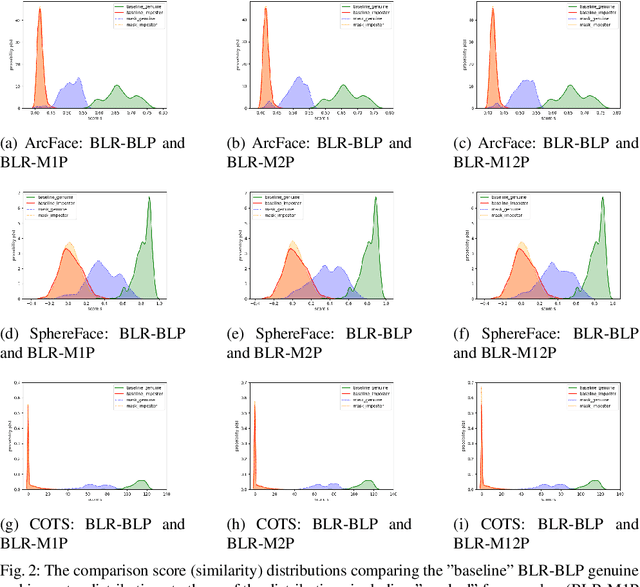
Face recognition has become essential in our daily lives as a convenient and contactless method of accurate identity verification. Process such as identity verification at automatic border control gates or the secure login to electronic devices are increasingly dependant on such technologies. The recent COVID-19 pandemic have increased the value of hygienic and contactless identity verification. However, the pandemic led to the wide use of face masks, essential to keep the pandemic under control. The effect of wearing a mask on face recognition in a collaborative environment is currently sensitive yet understudied issue. We address that by presenting a specifically collected database containing three session, each with three different capture instructions, to simulate realistic use cases. We further study the effect of masked face probes on the behaviour of three top-performing face recognition systems, two academic solutions and one commercial off-the-shelf (COTS) system.