 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
NAS-Bench-Suite-Zero: Accelerating Research on Zero Cost Proxies
Oct 06, 2022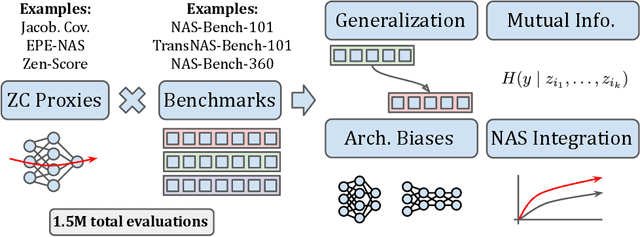
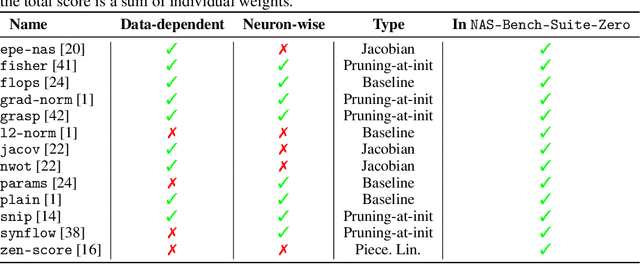
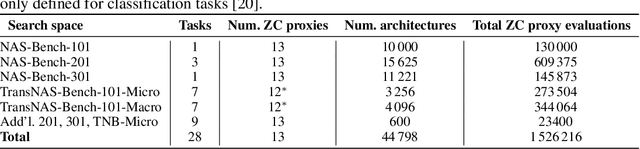
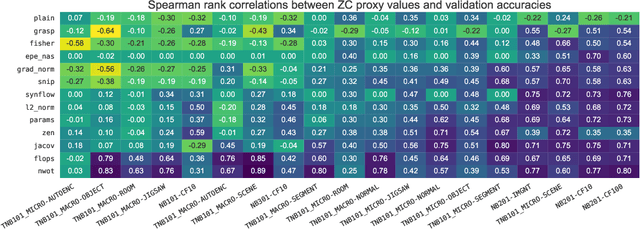
Zero-cost proxies (ZC proxies) are a recent architecture performance prediction technique aiming to significantly speed up algorithms for neural architecture search (NAS). Recent work has shown that these techniques show great promise, but certain aspects, such as evaluating and exploiting their complementary strengths, are under-studied. In this work, we create NAS-Bench-Suite: we evaluate 13 ZC proxies across 28 tasks, creating by far the largest dataset (and unified codebase) for ZC proxies, enabling orders-of-magnitude faster experiments on ZC proxies, while avoiding confounding factors stemming from different implementations. To demonstrate the usefulness of NAS-Bench-Suite, we run a large-scale analysis of ZC proxies, including a bias analysis, and the first information-theoretic analysis which concludes that ZC proxies capture substantial complementary information. Motivated by these findings, we present a procedure to improve the performance of ZC proxies by reducing biases such as cell size, and we also show that incorporating all 13 ZC proxies into the surrogate models used by NAS algorithms can improve their predictive performance by up to 42%. Our code and datasets are available at https://github.com/automl/naslib/tree/zerocost.
Neural Architecture Search for Dense Prediction Tasks in Computer Vision
Feb 15, 2022The success of deep learning in recent years has lead to a rising demand for neural network architecture engineering. As a consequence, neural architecture search (NAS), which aims at automatically designing neural network architectures in a data-driven manner rather than manually, has evolved as a popular field of research. With the advent of weight sharing strategies across architectures, NAS has become applicable to a much wider range of problems. In particular, there are now many publications for dense prediction tasks in computer vision that require pixel-level predictions, such as semantic segmentation or object detection. These tasks come with novel challenges, such as higher memory footprints due to high-resolution data, learning multi-scale representations, longer training times, and more complex and larger neural architectures. In this manuscript, we provide an overview of NAS for dense prediction tasks by elaborating on these novel challenges and surveying ways to address them to ease future research and application of existing methods to novel problems.
NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy
Feb 11, 2022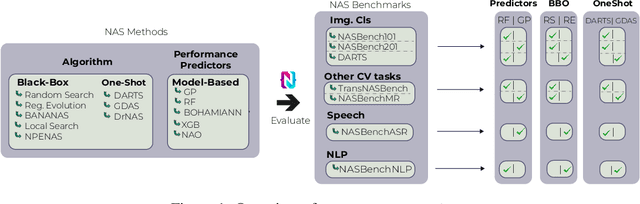
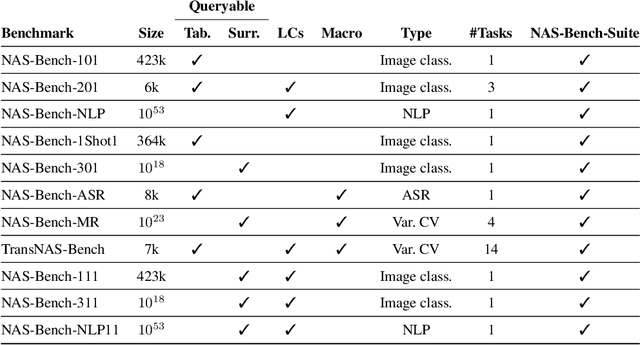
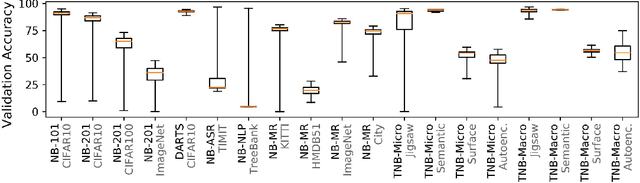
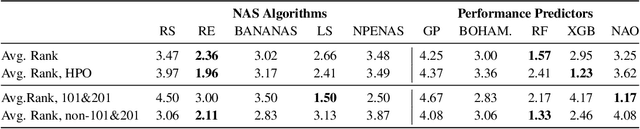
The release of tabular benchmarks, such as NAS-Bench-101 and NAS-Bench-201, has significantly lowered the computational overhead for conducting scientific research in neural architecture search (NAS). Although they have been widely adopted and used to tune real-world NAS algorithms, these benchmarks are limited to small search spaces and focus solely on image classification. Recently, several new NAS benchmarks have been introduced that cover significantly larger search spaces over a wide range of tasks, including object detection, speech recognition, and natural language processing. However, substantial differences among these NAS benchmarks have so far prevented their widespread adoption, limiting researchers to using just a few benchmarks. In this work, we present an in-depth analysis of popular NAS algorithms and performance prediction methods across 25 different combinations of search spaces and datasets, finding that many conclusions drawn from a few NAS benchmarks do not generalize to other benchmarks. To help remedy this problem, we introduce NAS-Bench-Suite, a comprehensive and extensible collection of NAS benchmarks, accessible through a unified interface, created with the aim to facilitate reproducible, generalizable, and rapid NAS research. Our code is available at https://github.com/automl/naslib.
Multi-headed Neural Ensemble Search
Jul 09, 2021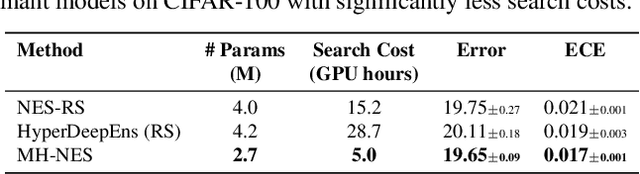
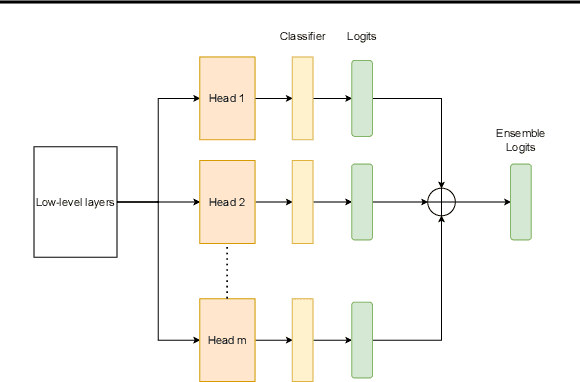
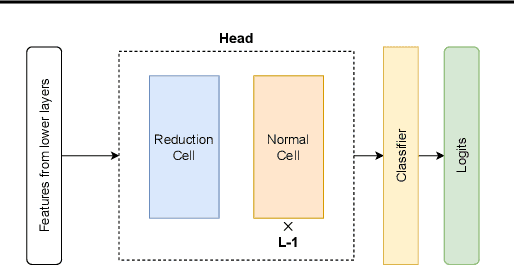
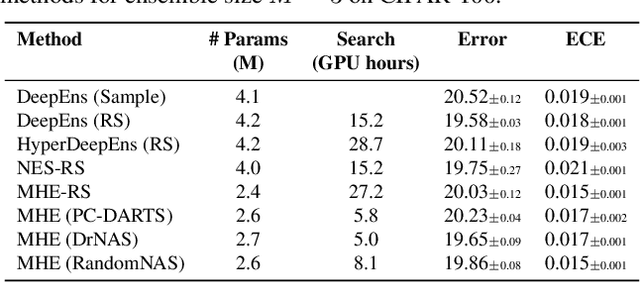
Ensembles of CNN models trained with different seeds (also known as Deep Ensembles) are known to achieve superior performance over a single copy of the CNN. Neural Ensemble Search (NES) can further boost performance by adding architectural diversity. However, the scope of NES remains prohibitive under limited computational resources. In this work, we extend NES to multi-headed ensembles, which consist of a shared backbone attached to multiple prediction heads. Unlike Deep Ensembles, these multi-headed ensembles can be trained end to end, which enables us to leverage one-shot NAS methods to optimize an ensemble objective. With extensive empirical evaluations, we demonstrate that multi-headed ensemble search finds robust ensembles 3 times faster, while having comparable performance to other ensemble search methods, in both predictive performance and uncertainty calibration.
Bag of Tricks for Neural Architecture Search
Jul 08, 2021While neural architecture search methods have been successful in previous years and led to new state-of-the-art performance on various problems, they have also been criticized for being unstable, being highly sensitive with respect to their hyperparameters, and often not performing better than random search. To shed some light on this issue, we discuss some practical considerations that help improve the stability, efficiency and overall performance.
How Powerful are Performance Predictors in Neural Architecture Search?
Apr 02, 2021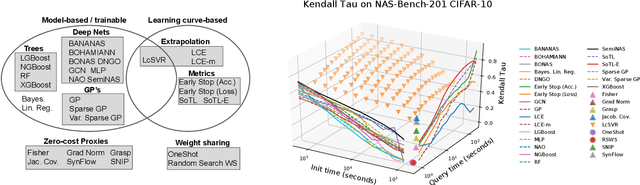
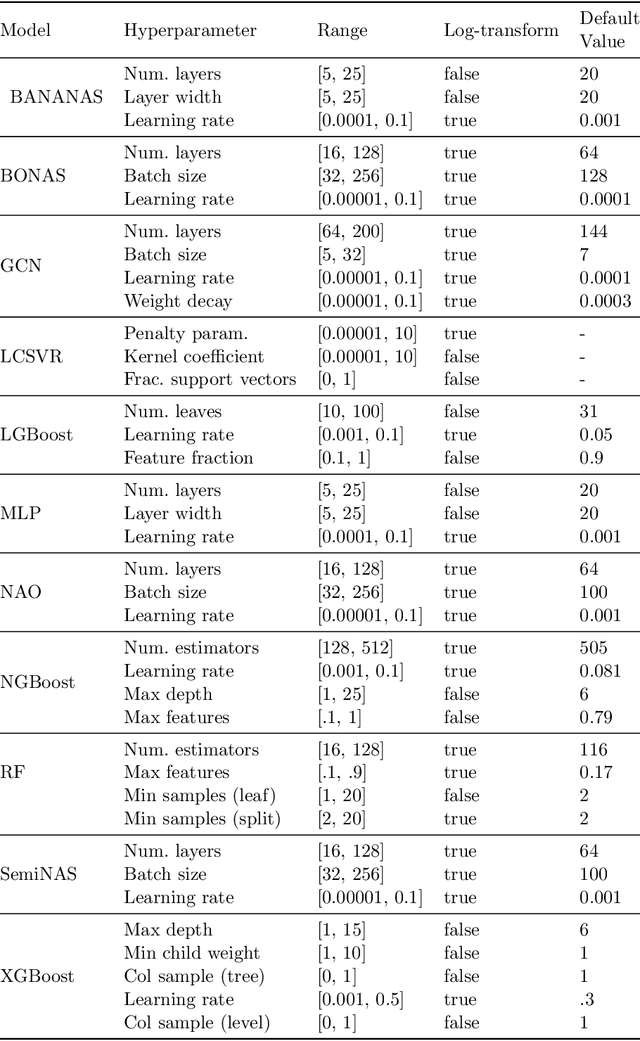
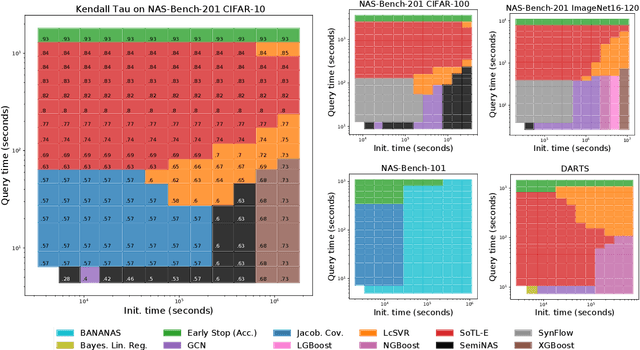
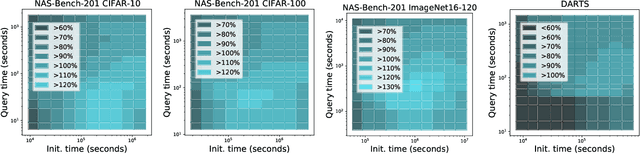
Early methods in the rapidly developing field of neural architecture search (NAS) required fully training thousands of neural networks. To reduce this extreme computational cost, dozens of techniques have since been proposed to predict the final performance of neural architectures. Despite the success of such performance prediction methods, it is not well-understood how different families of techniques compare to one another, due to the lack of an agreed-upon evaluation metric and optimization for different constraints on the initialization time and query time. In this work, we give the first large-scale study of performance predictors by analyzing 31 techniques ranging from learning curve extrapolation, to weight-sharing, to supervised learning, to "zero-cost" proxies. We test a number of correlation- and rank-based performance measures in a variety of settings, as well as the ability of each technique to speed up predictor-based NAS frameworks. Our results act as recommendations for the best predictors to use in different settings, and we show that certain families of predictors can be combined to achieve even better predictive power, opening up promising research directions. Our code, featuring a library of 31 performance predictors, is available at https://github.com/automl/naslib.
Smooth Variational Graph Embeddings for Efficient Neural Architecture Search
Oct 09, 2020
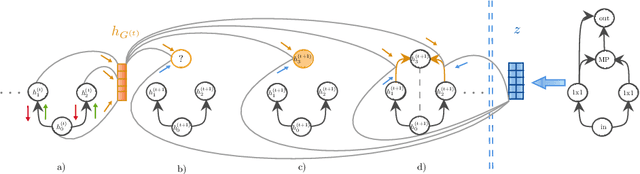
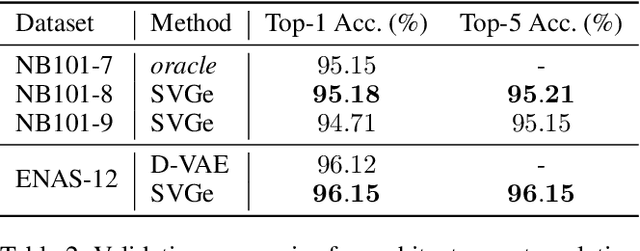
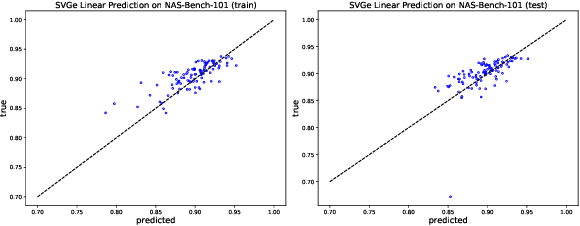
In this paper, we propose an approach to neural architecture search (NAS) based on graph embeddings. NAS has been addressed previously using discrete, sampling based methods, which are computationally expensive as well as differentiable approaches, which come at lower costs but enforce stronger constraints on the search space. The proposed approach leverages advantages from both sides by building a smooth variational neural architecture embedding space in which we evaluate a structural subset of architectures at training time using the predicted performance while it allows to extrapolate from this subspace at inference time. We evaluate the proposed approach in the context of two common search spaces, the graph structure defined by the ENAS approach and the NAS-Bench-101 search space, and improve over the state of the art in both.
NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search
Aug 22, 2020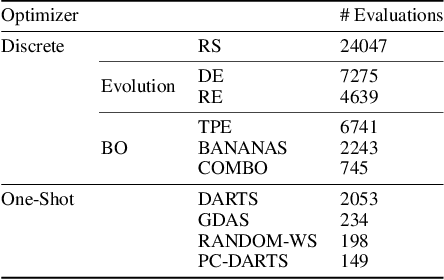
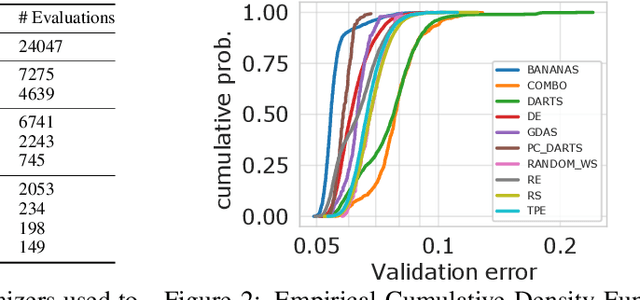
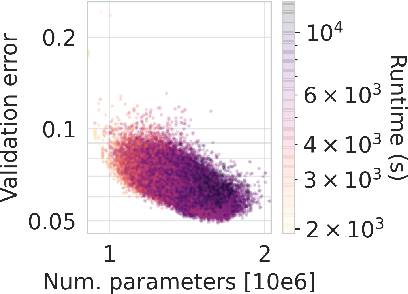
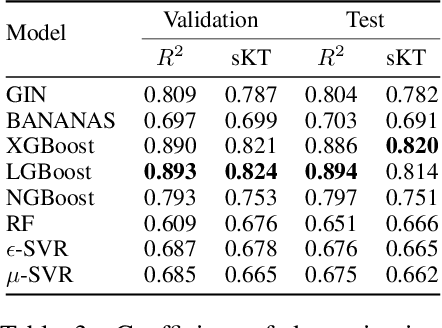
Neural Architecture Search (NAS) is a logical next step in the automatic learning of representations, but the development of NAS methods is slowed by high computational demands. As a remedy, several tabular NAS benchmarks were proposed to simulate runs of NAS methods in seconds. However, all existing NAS benchmarks are limited to extremely small architectural spaces since they rely on exhaustive evaluations of the space. This leads to unrealistic results, such as a strong performance of local search and random search, that do not transfer to larger search spaces. To overcome this fundamental limitation, we propose NAS-Bench-301, the first model-based surrogate NAS benchmark, using a search space containing $10^{18}$ architectures, orders of magnitude larger than any previous NAS benchmark. We first motivate the benefits of using such a surrogate benchmark compared to a tabular one by smoothing out the noise stemming from the stochasticity of single SGD runs in a tabular benchmark. Then, we analyze our new dataset consisting of architecture evaluations and comprehensively evaluate various regression models as surrogates to demonstrate their capability to model the architecture space, also using deep ensembles to model uncertainty. Finally, we benchmark a wide range of NAS algorithms using NAS-Bench-301 allowing us to obtain comparable results to the true benchmark at a fraction of the cost.
Neural Ensemble Search for Performant and Calibrated Predictions
Jun 15, 2020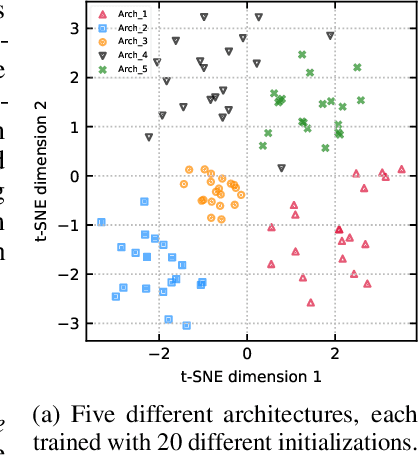
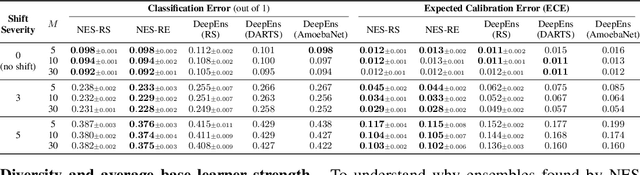


Ensembles of neural networks achieve superior performance compared to stand-alone networks not only in terms of accuracy on in-distribution data but also on data with distributional shift alongside improved uncertainty calibration. Diversity among networks in an ensemble is believed to be key for building strong ensembles, but typical approaches only ensemble different weight vectors of a fixed architecture. Instead, we investigate neural architecture search (NAS) for explicitly constructing ensembles to exploit diversity among networks of varying architectures and to achieve robustness against distributional shift. By directly optimizing ensemble performance, our methods implicitly encourage diversity among networks, without the need to explicitly define diversity. We find that the resulting ensembles are more diverse compared to ensembles composed of a fixed architecture and are therefore also more powerful. We show significant improvements in ensemble performance on image classification tasks both for in-distribution data and during distributional shift with better uncertainty calibration.