 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
Oct 23, 2024Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Using Captum to Explain Generative Language Models
Dec 09, 2023Captum is a comprehensive library for model explainability in PyTorch, offering a range of methods from the interpretability literature to enhance users' understanding of PyTorch models. In this paper, we introduce new features in Captum that are specifically designed to analyze the behavior of generative language models. We provide an overview of the available functionalities and example applications of their potential for understanding learned associations within generative language models.
Comparative Explanations of Recommendations
Nov 01, 2021

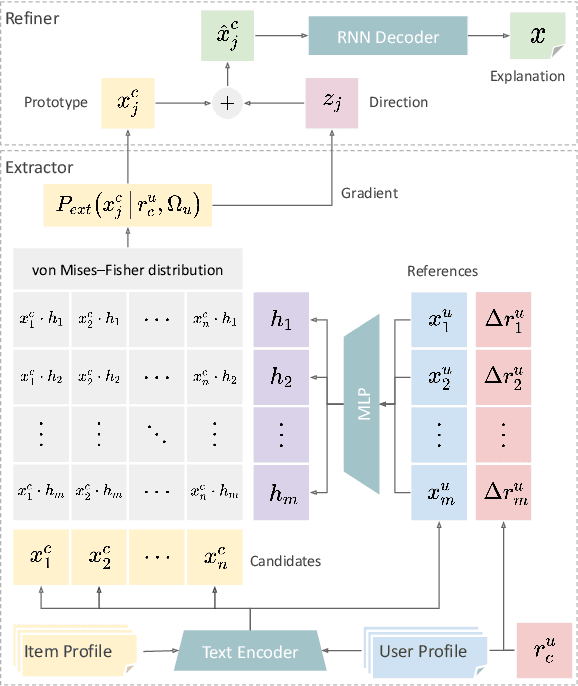
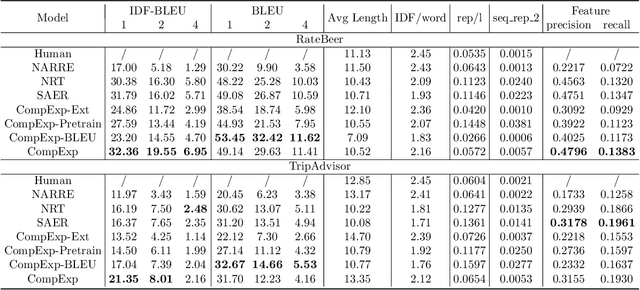
As recommendation is essentially a comparative (or ranking) process, a good explanation should illustrate to users why an item is believed to be better than another, i.e., comparative explanations about the recommended items. Ideally, after reading the explanations, a user should reach the same ranking of items as the system's. Unfortunately, little research attention has yet been paid on such comparative explanations. In this work, we develop an extract-and-refine architecture to explain the relative comparisons among a set of ranked items from a recommender system. For each recommended item, we first extract one sentence from its associated reviews that best suits the desired comparison against a set of reference items. Then this extracted sentence is further articulated with respect to the target user through a generative model to better explain why the item is recommended. We design a new explanation quality metric based on BLEU to guide the end-to-end training of the extraction and refinement components, which avoids generation of generic content. Extensive offline evaluations on two large recommendation benchmark datasets and serious user studies against an array of state-of-the-art explainable recommendation algorithms demonstrate the necessity of comparative explanations and the effectiveness of our solution.
Explanation as a Defense of Recommendation
Jan 24, 2021
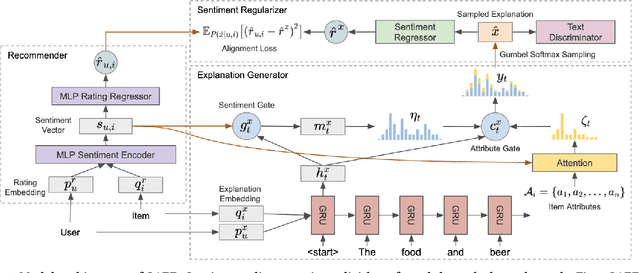
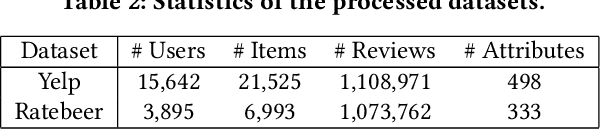
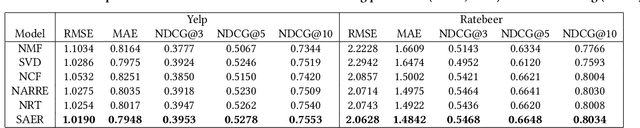
Textual explanations have proved to help improve user satisfaction on machine-made recommendations. However, current mainstream solutions loosely connect the learning of explanation with the learning of recommendation: for example, they are often separately modeled as rating prediction and content generation tasks. In this work, we propose to strengthen their connection by enforcing the idea of sentiment alignment between a recommendation and its corresponding explanation. At training time, the two learning tasks are joined by a latent sentiment vector, which is encoded by the recommendation module and used to make word choices for explanation generation. At both training and inference time, the explanation module is required to generate explanation text that matches sentiment predicted by the recommendation module. Extensive experiments demonstrate our solution outperforms a rich set of baselines in both recommendation and explanation tasks, especially on the improved quality of its generated explanations. More importantly, our user studies confirm our generated explanations help users better recognize the differences between recommended items and understand why an item is recommended.