 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Weight Initialization Paradigm for Tensorial Convolutional Neural Networks
May 28, 2022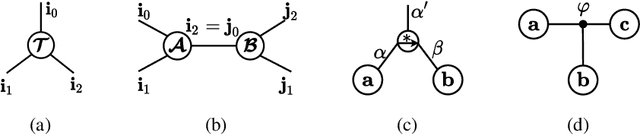
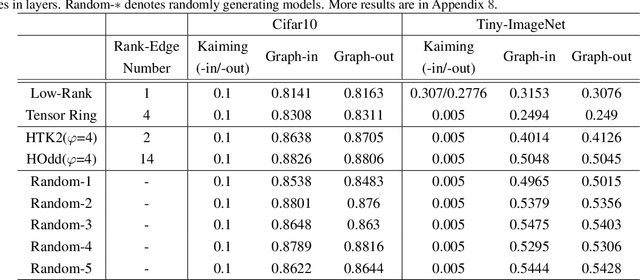
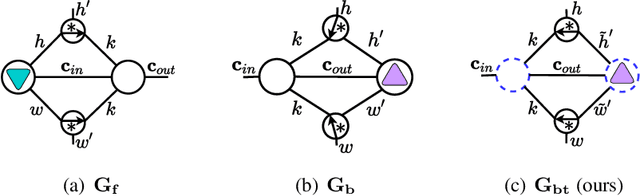

Tensorial Convolutional Neural Networks (TCNNs) have attracted much research attention for their power in reducing model parameters or enhancing the generalization ability. However, exploration of TCNNs is hindered even from weight initialization methods. To be specific, general initialization methods, such as Xavier or Kaiming initialization, usually fail to generate appropriate weights for TCNNs. Meanwhile, although there are ad-hoc approaches for specific architectures (e.g., Tensor Ring Nets), they are not applicable to TCNNs with other tensor decomposition methods (e.g., CP or Tucker decomposition). To address this problem, we propose a universal weight initialization paradigm, which generalizes Xavier and Kaiming methods and can be widely applicable to arbitrary TCNNs. Specifically, we first present the Reproducing Transformation to convert the backward process in TCNNs to an equivalent convolution process. Then, based on the convolution operators in the forward and backward processes, we build a unified paradigm to control the variance of features and gradients in TCNNs. Thus, we can derive fan-in and fan-out initialization for various TCNNs. We demonstrate that our paradigm can stabilize the training of TCNNs, leading to faster convergence and better results.
PLOG: Table-to-Logic Pretraining for Logical Table-to-Text Generation
May 25, 2022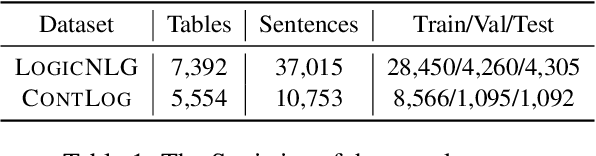

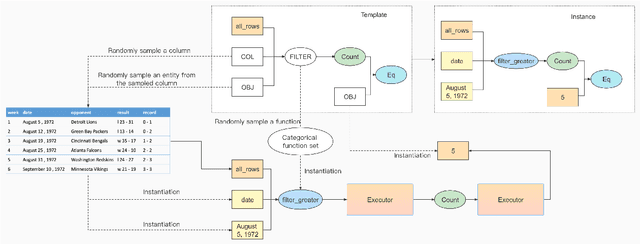

Logical table-to-text generation is a task that involves generating logically faithful sentences from tables, which requires models to derive logical level facts from table records via logical inference. It raises a new challenge on the logical-level content planning of table-to-text models. However, directly learning the logical inference knowledge from table-text pairs is very difficult for neural models because of the ambiguity of natural language and the scarcity of parallel data. Hence even large-scale pre-trained language models present low logical fidelity on logical table-to-text. In this work, we propose a PLOG (Pretrained Logical Form Generator) framework to improve the generation fidelity. Specifically, PLOG is first pretrained on a table-to-logic-form generation (table-to-logic) task, then finetuned on downstream table-to-text tasks. The formal definition of logical forms enables us to collect large amount of accurate logical forms from tables without human annotation. In addition, PLOG can learn logical inference from table-logic pairs much more definitely than from table-text pairs. To evaluate our model, we further collect a controlled logical table-to-text dataset CONTLOG based on an existing dataset. On two benchmarks, LOGICNLG and CONTLOG, PLOG outperforms strong baselines by a large margin on the logical fidelity, demonstrating the effectiveness of table-to-logic pretraining.
Semi-Supervised Formality Style Transfer with Consistency Training
Mar 25, 2022
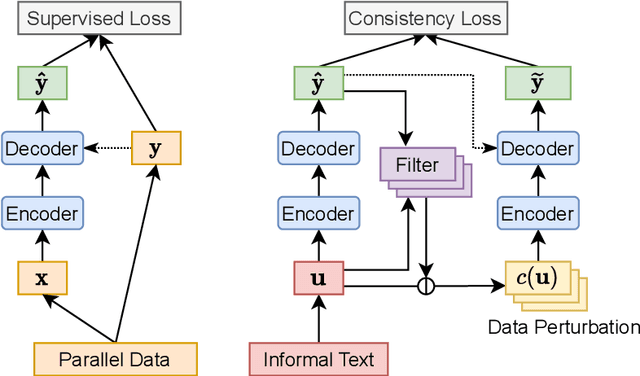
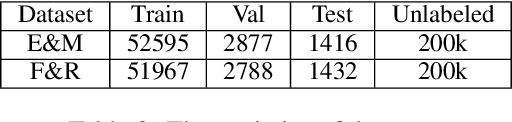
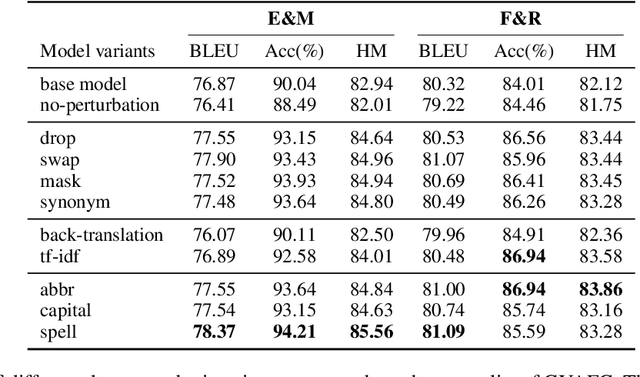
Formality style transfer (FST) is a task that involves paraphrasing an informal sentence into a formal one without altering its meaning. To address the data-scarcity problem of existing parallel datasets, previous studies tend to adopt a cycle-reconstruction scheme to utilize additional unlabeled data, where the FST model mainly benefits from target-side unlabeled sentences. In this work, we propose a simple yet effective semi-supervised framework to better utilize source-side unlabeled sentences based on consistency training. Specifically, our approach augments pseudo-parallel data obtained from a source-side informal sentence by enforcing the model to generate similar outputs for its perturbed version. Moreover, we empirically examined the effects of various data perturbation methods and propose effective data filtering strategies to improve our framework. Experimental results on the GYAFC benchmark demonstrate that our approach can achieve state-of-the-art results, even with less than 40% of the parallel data.
Towards Effective Multi-Task Interaction for Entity-Relation Extraction: A Unified Framework with Selection Recurrent Network
Feb 15, 2022Entity-relation extraction aims to jointly solve named entity recognition (NER) and relation extraction (RE). Recent approaches use either one-way sequential information propagation in a pipeline manner or two-way implicit interaction with a shared encoder. However, they still suffer from poor information interaction due to the gap between the different task forms of NER and RE, raising a controversial question whether RE is really beneficial to NER. Motivated by this, we propose a novel and unified cascade framework that combines the advantages of both sequential information propagation and implicit interaction. Meanwhile, it eliminates the gap between the two tasks by reformulating entity-relation extraction as unified span-extraction tasks. Specifically, we propose a selection recurrent network as a shared encoder to encode task-specific independent and shared representations and design two sequential information propagation strategies to realize the sequential information flow between NER and RE. Extensive experiments demonstrate that our approaches can achieve state-of-the-art results on two common benchmarks, ACE05 and SciERC, and effectively model the multi-task interaction, which realizes significant mutual benefits of NER and RE.
Table Pre-training: A Survey on Model Architectures, Pretraining Objectives, and Downstream Tasks
Jan 27, 2022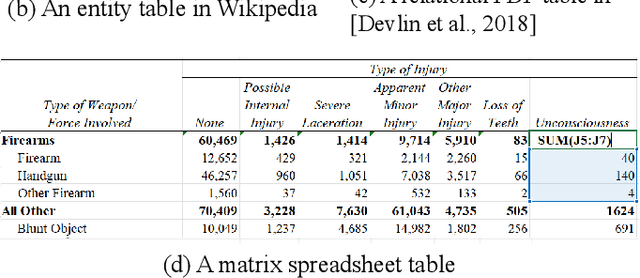


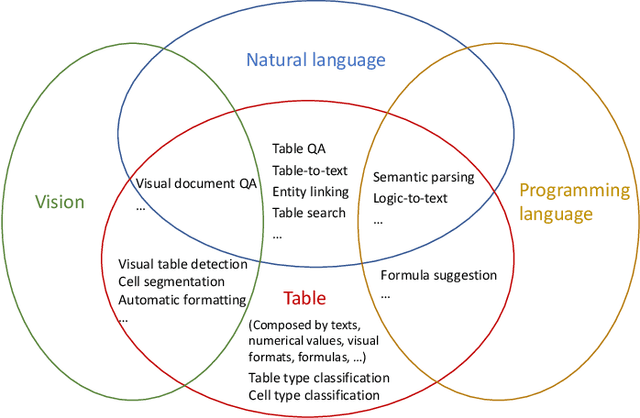
Since a vast number of tables can be easily collected from web pages, spreadsheets, PDFs, and various other document types, a flurry of table pre-training frameworks have been proposed following the success of text and images, and they have achieved new state-of-the-arts on various tasks such as table question answering, table type recognition, column relation classification, table search, formula prediction, etc. To fully use the supervision signals in unlabeled tables, a variety of pre-training objectives have been designed and evaluated, for example, denoising cell values, predicting numerical relationships, and implicitly executing SQLs. And to best leverage the characteristics of (semi-)structured tables, various tabular language models, particularly with specially-designed attention mechanisms, have been explored. Since tables usually appear and interact with free-form text, table pre-training usually takes the form of table-text joint pre-training, which attracts significant research interests from multiple domains. This survey aims to provide a comprehensive review of different model designs, pre-training objectives, and downstream tasks for table pre-training, and we further share our thoughts and vision on existing challenges and future opportunities.
Personalized Lane Change Decision Algorithm Using Deep Reinforcement Learning Approach
Dec 17, 2021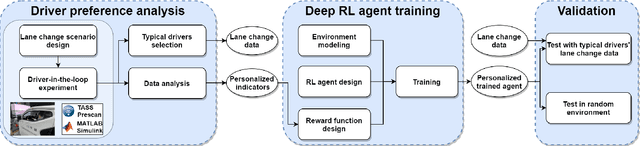



To develop driving automation technologies for human, a human-centered methodology should be adopted for ensured safety and satisfactory user experience. Automated lane change decision in dense highway traffic is challenging, especially when considering the personalized preferences of different drivers. To fulfill human driver centered decision algorithm development, we carry out driver-in-the-loop experiments on a 6-Degree-of-Freedom driving simulator. Based on the analysis of the lane change data by drivers of three specific styles,personalization indicators are selected to describe the driver preferences in lane change decision. Then a deep reinforcement learning (RL) approach is applied to design human-like agents for automated lane change decision, with refined reward and loss functions to capture the driver preferences.The trained RL agents and benchmark agents are tested in a two-lane highway driving scenario, and by comparing the agents with the specific drivers at the same initial states of lane change, the statistics show that the proposed algorithm can guarantee higher consistency of lane change decision preferences. The driver personalization indicators and the proposed RL-based lane change decision algorithm are promising to contribute in automated lane change system developing.
Improving Logical-Level Natural Language Generation with Topic-Conditioned Data Augmentation and Logical Form Generation
Dec 12, 2021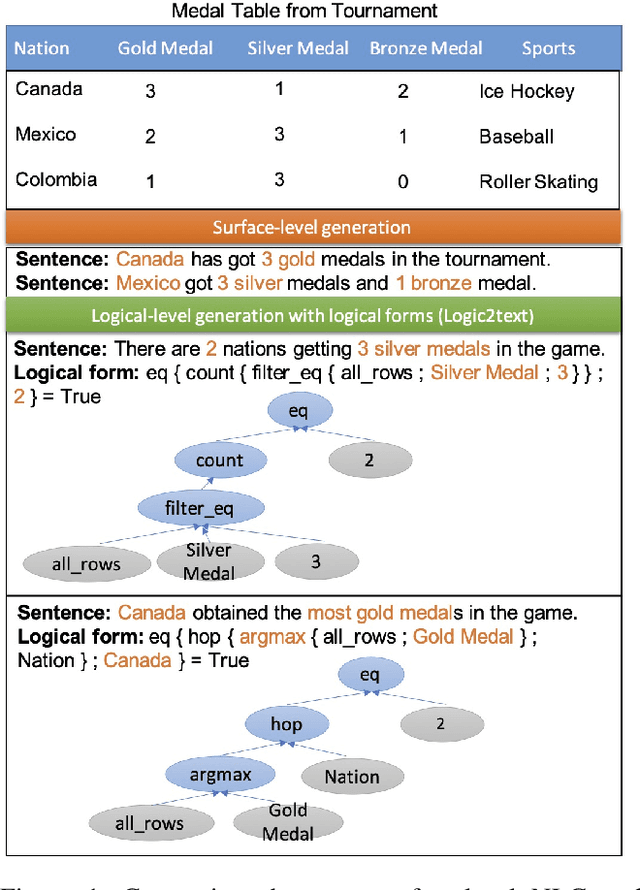

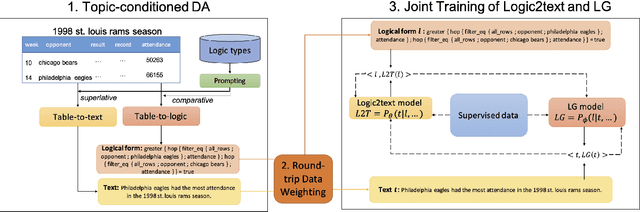
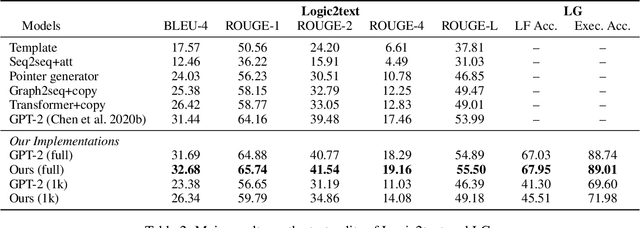
Logical Natural Language Generation, i.e., generating textual descriptions that can be logically entailed by a structured table, has been a challenge due to the low fidelity of the generation. \citet{chen2020logic2text} have addressed this problem by annotating interim logical programs to control the generation contents and semantics, and presented the task of table-aware logical form to text (Logic2text) generation. However, although table instances are abundant in the real world, logical forms paired with textual descriptions require costly human annotation work, which limits the performance of neural models. To mitigate this, we propose topic-conditioned data augmentation (TopicDA), which utilizes GPT-2 to generate unpaired logical forms and textual descriptions directly from tables. We further introduce logical form generation (LG), a dual task of Logic2text that requires generating a valid logical form based on a text description of a table. We also propose a semi-supervised learning approach to jointly train a Logic2text and an LG model with both labeled and augmented data. The two models benefit from each other by providing extra supervision signals through back-translation. Experimental results on the Logic2text dataset and the LG task demonstrate that our approach can effectively utilize the augmented data and outperform supervised baselines by a substantial margin.
Personalized Highway Pilot Assist Considering Leading Vehicle's Lateral Behaviours
Dec 11, 2021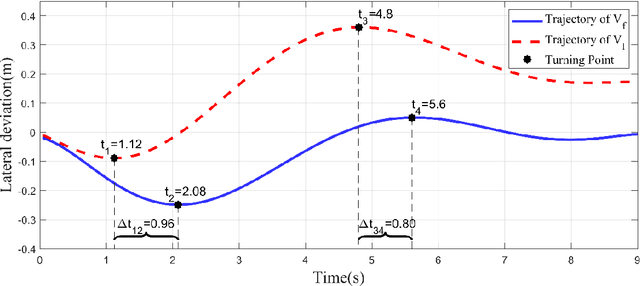

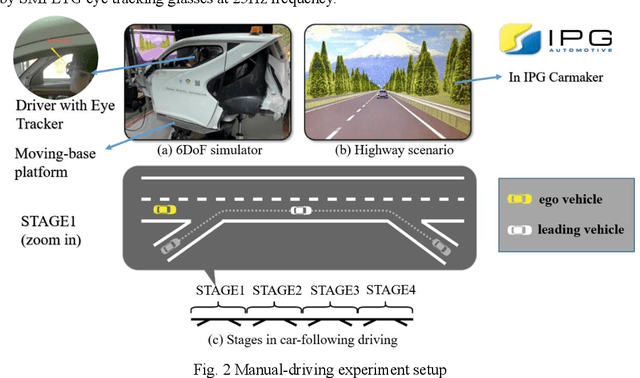
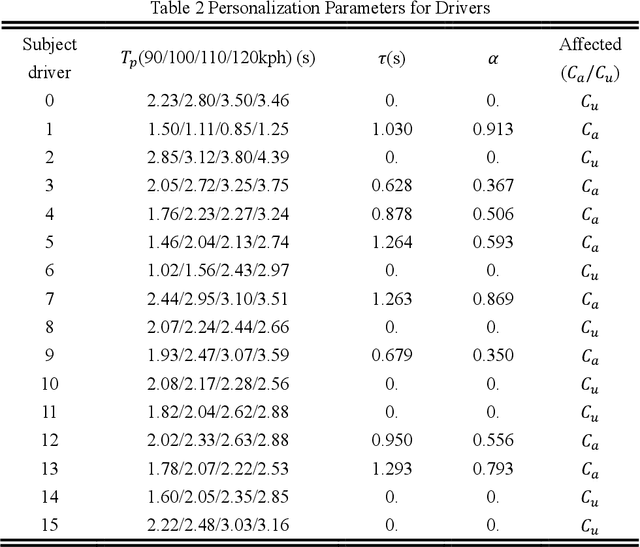
Highway pilot assist has become the front line of competition in advanced driver assistance systems. The increasing requirements on safety and user acceptance are calling for personalization in the development process of such systems. Inspired by a finding on drivers' car-following preferences on lateral direction, a personalized highway pilot assist algorithm is proposed, which consists of an Intelligent Driver Model (IDM) based speed control model and a novel lane-keeping model considering the leading vehicle's lateral movement. A simulated driving experiment is conducted to analyse driver gaze and lane-keeping Behaviours in free-driving and following driving scenario. Drivers are clustered into two driving style groups referring to their driving Behaviours affected by the leading vehicle, and then the personalization parameters for every specific subject driver are optimized. The proposed algorithm is validated through driver-in-the-loop experiment based on a moving-base simulator. Results show that, compared with the un-personalized algorithms, the personalized highway pilot algorithm can significantly reduce the mental workload and improve user acceptance of the assist functions.
Smoothed Differential Privacy
Jul 09, 2021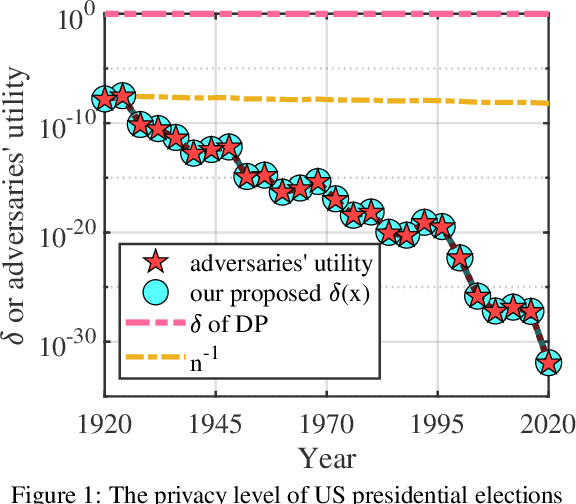
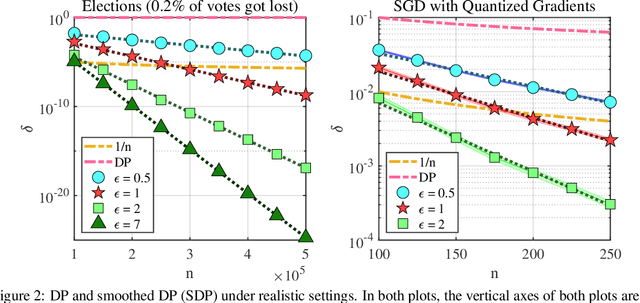
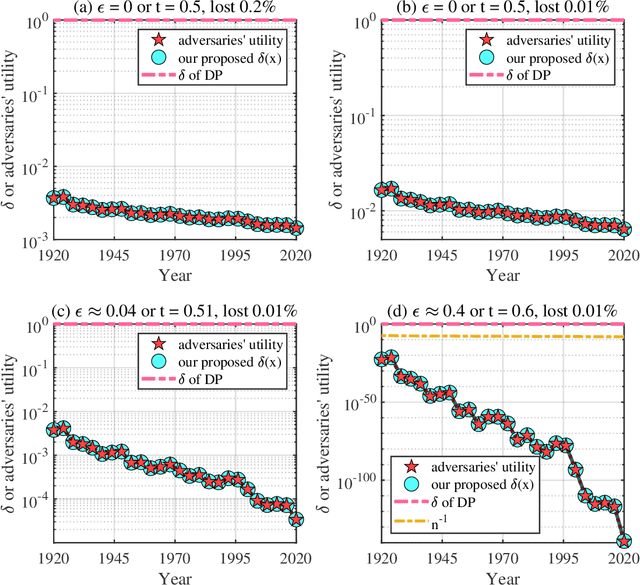
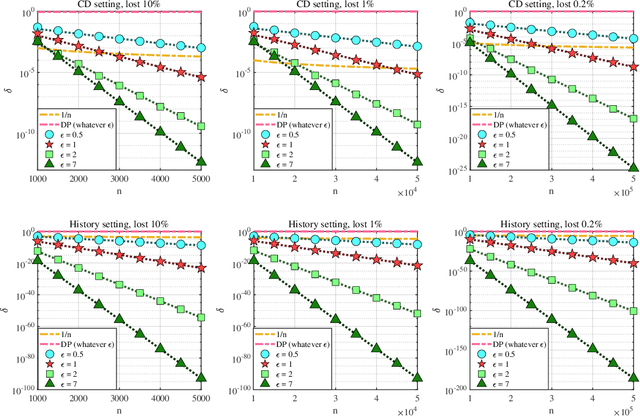
Differential privacy (DP) is a widely-accepted and widely-applied notion of privacy based on worst-case analysis. Often, DP classifies most mechanisms without external noise as non-private [Dwork et al., 2014], and external noises, such as Gaussian noise or Laplacian noise [Dwork et al., 2006], are introduced to improve privacy. In many real-world applications, however, adding external noise is undesirable and sometimes prohibited. For example, presidential elections often require a deterministic rule to be used [Liu et al., 2020], and small noises can lead to dramatic decreases in the prediction accuracy of deep neural networks, especially the underrepresented classes [Bagdasaryan et al., 2019]. In this paper, we propose a natural extension and relaxation of DP following the worst average-case idea behind the celebrated smoothed analysis [Spielman and Teng, 2004]. Our notion, the smoothed DP, can effectively measure the privacy leakage of mechanisms without external noises under realistic settings. We prove several strong properties of the smoothed DP, including composability, robustness to post-processing and etc. We proved that any discrete mechanism with sampling procedures is more private than what DP predicts. In comparison, many continuous mechanisms with sampling procedures are still non-private under smoothed DP. Experimentally, we first verified that the discrete sampling mechanisms are private in real-world elections. Then, we apply the smoothed DP notion on quantized gradient descent, which indicates some neural networks can be private without adding any extra noises. We believe that these results contribute to the theoretical foundation of realistic privacy measures beyond worst-case analysis.
Certifiably Robust Interpretation via Renyi Differential Privacy
Jul 04, 2021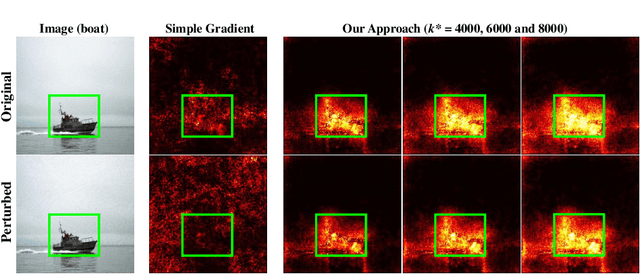


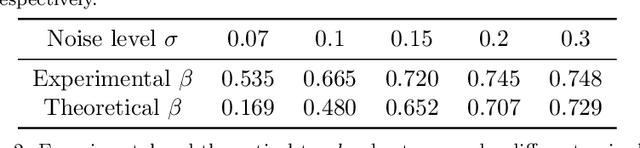
Motivated by the recent discovery that the interpretation maps of CNNs could easily be manipulated by adversarial attacks against network interpretability, we study the problem of interpretation robustness from a new perspective of \Renyi differential privacy (RDP). The advantages of our Renyi-Robust-Smooth (RDP-based interpretation method) are three-folds. First, it can offer provable and certifiable top-$k$ robustness. That is, the top-$k$ important attributions of the interpretation map are provably robust under any input perturbation with bounded $\ell_d$-norm (for any $d\geq 1$, including $d = \infty$). Second, our proposed method offers $\sim10\%$ better experimental robustness than existing approaches in terms of the top-$k$ attributions. Remarkably, the accuracy of Renyi-Robust-Smooth also outperforms existing approaches. Third, our method can provide a smooth tradeoff between robustness and computational efficiency. Experimentally, its top-$k$ attributions are {\em twice} more robust than existing approaches when the computational resources are highly constrained.