 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide-Area Crowd Counting: Multi-View Fusion Networks for Counting in Large Scenes
Dec 02, 2020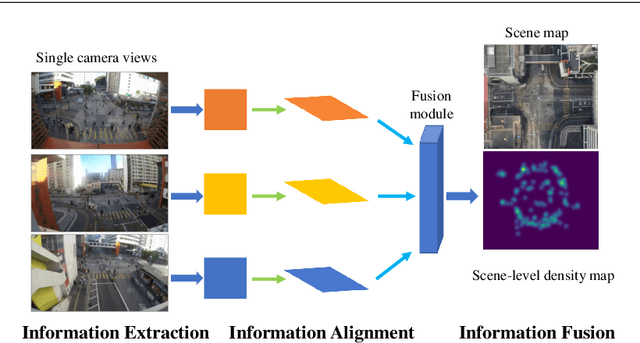

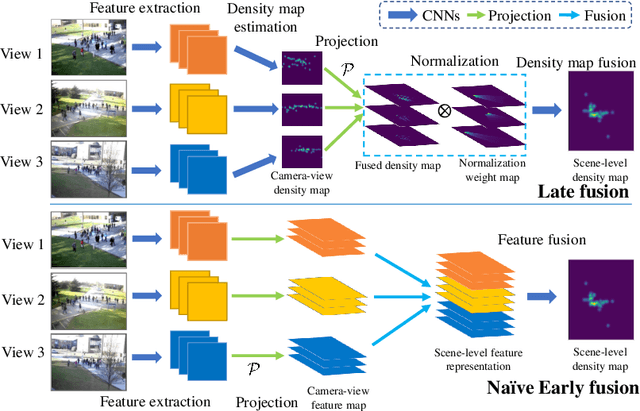

Crowd counting in single-view images has achieved outstanding performance on existing counting datasets. However, single-view counting is not applicable to large and wide scenes (e.g., public parks, long subway platforms, or event spaces) because a single camera cannot capture the whole scene in adequate detail for counting, e.g., when the scene is too large to fit into the field-of-view of the camera, too long so that the resolution is too low on faraway crowds, or when there are too many large objects that occlude large portions of the crowd. Therefore, to solve the wide-area counting task requires multiple cameras with overlapping fields-of-view. In this paper, we propose a deep neural network framework for multi-view crowd counting, which fuses information from multiple camera views to predict a scene-level density map on the ground-plane of the 3D world. We consider three versions of the fusion framework: the late fusion model fuses camera-view density map; the naive early fusion model fuses camera-view feature maps; and the multi-view multi-scale early fusion model ensures that features aligned to the same ground-plane point have consistent scales. A rotation selection module further ensures consistent rotation alignment of the features. We test our 3 fusion models on 3 multi-view counting datasets, PETS2009, DukeMTMC, and a newly collected multi-view counting dataset containing a crowded street intersection. Our methods achieve state-of-the-art results compared to other multi-view counting baselines.
Improve Generalization and Robustness of Neural Networks via Weight Scale Shifting Invariant Regularizations
Aug 07, 2020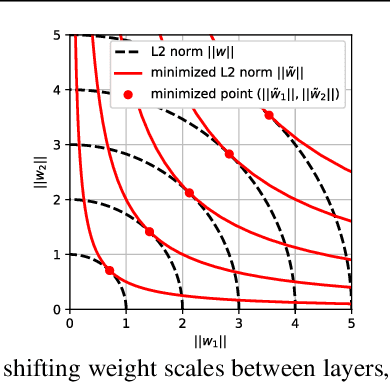
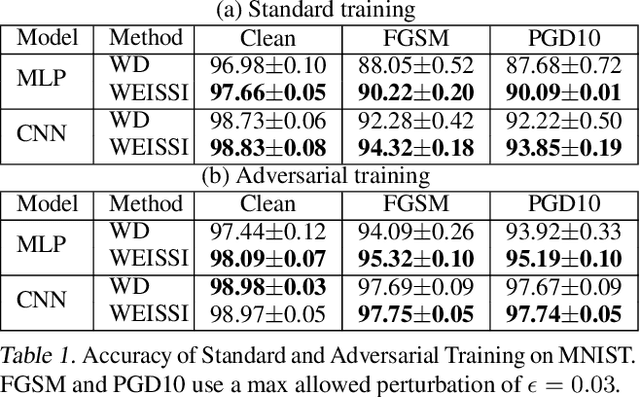
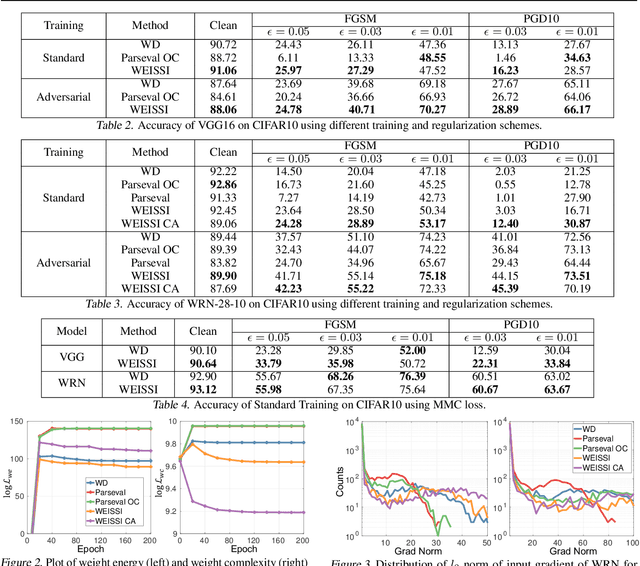
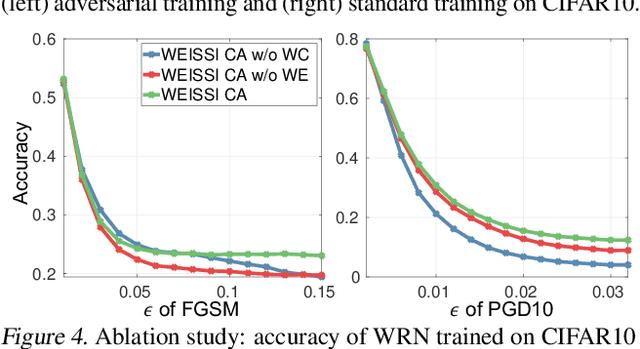
Using weight decay to penalize the L2 norms of weights in neural networks has been a standard training practice to regularize the complexity of networks. In this paper, we show that a family of regularizers, including weight decay, is ineffective at penalizing the intrinsic norms of weights for networks with positively homogeneous activation functions, such as linear, ReLU and max-pooling functions. As a result of homogeneity, functions specified by the networks are invariant to the shifting of weight scales between layers. The ineffective regularizers are sensitive to such shifting and thus poorly regularize the model capacity, leading to overfitting. To address this shortcoming, we propose an improved regularizer that is invariant to weight scale shifting and thus effectively constrains the intrinsic norm of a neural network. The derived regularizer is an upper bound for the input gradient of the network so minimizing the improved regularizer also benefits the adversarial robustness. Residual connections are also considered and we show that our regularizer also forms an upper bound to input gradients of such a residual network. We demonstrate the efficacy of our proposed regularizer on various datasets and neural network architectures at improving generalization and adversarial robustness.
Tracking-by-Counting: Using Network Flows on Crowd Density Maps for Tracking Multiple Targets
Jul 18, 2020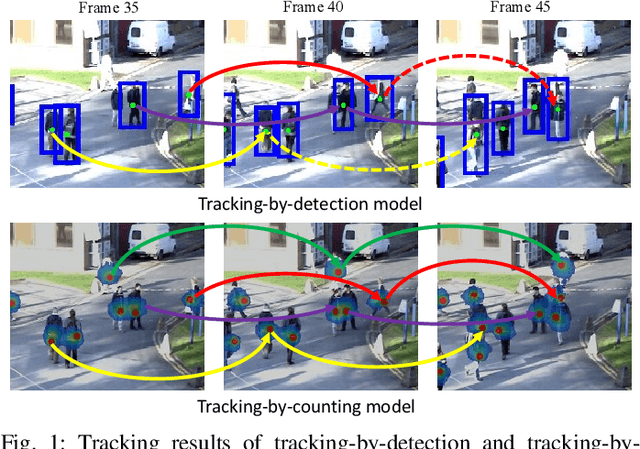
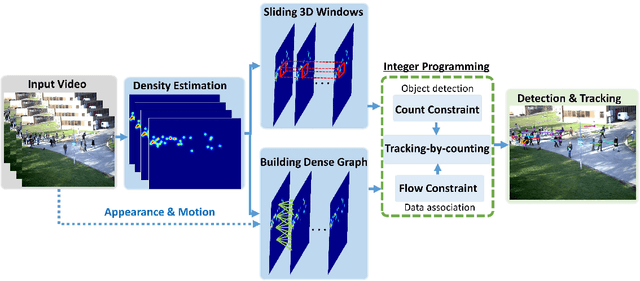
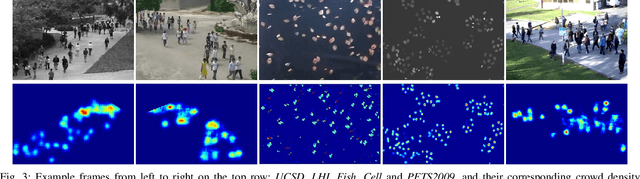

State-of-the-art multi-object tracking~(MOT) methods follow the tracking-by-detection paradigm, where object trajectories are obtained by associating per-frame outputs of object detectors. In crowded scenes, however, detectors often fail to obtain accurate detections due to heavy occlusions and high crowd density. In this paper, we propose a new MOT paradigm, tracking-by-counting, tailored for crowded scenes. Using crowd density maps, we jointly model detection, counting, and tracking of multiple targets as a network flow program, which simultaneously finds the global optimal detections and trajectories of multiple targets over the whole video. This is in contrast to prior MOT methods that either ignore the crowd density and thus are prone to errors in crowded scenes, or rely on a suboptimal two-step process using heuristic density-aware point-tracks for matching targets.Our approach yields promising results on public benchmarks of various domains including people tracking, cell tracking, and fish tracking.
Compare and Reweight: Distinctive Image Captioning Using Similar Images Sets
Jul 14, 2020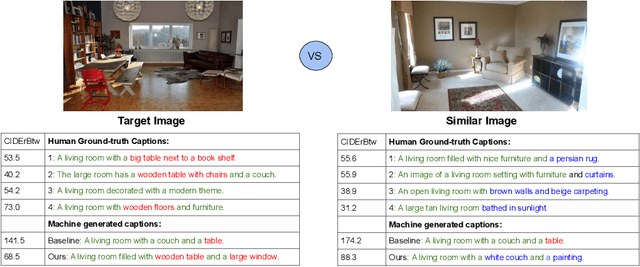
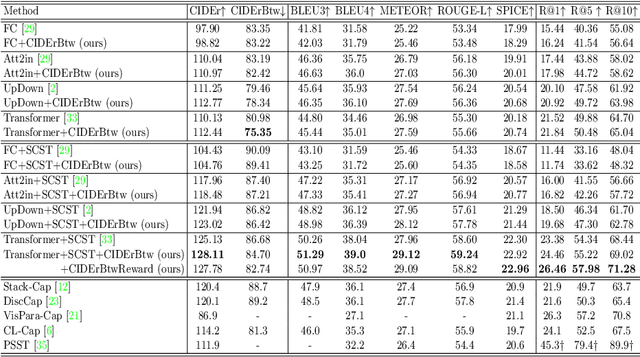
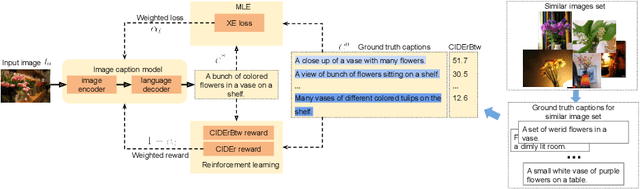
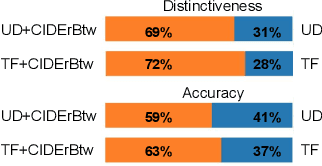
A wide range of image captioning models has been developed, achieving significant improvement based on popular metrics, such as BLEU, CIDEr, and SPICE. However, although the generated captions can accurately describe the image, they are generic for similar images and lack distinctiveness, i.e., cannot properly describe the uniqueness of each image. In this paper, we aim to improve the distinctiveness of image captions through training with sets of similar images. First, we propose a distinctiveness metric -- between-set CIDEr (CIDErBtw) to evaluate the distinctiveness of a caption with respect to those of similar images. Our metric shows that the human annotations of each image are not equivalent based on distinctiveness. Thus we propose several new training strategies to encourage the distinctiveness of the generated caption for each image, which are based on using CIDErBtw in a weighted loss function or as a reinforcement learning reward. Finally, extensive experiments are conducted, showing that our proposed approach significantly improves both distinctiveness (as measured by CIDErBtw and retrieval metrics) and accuracy (e.g., as measured by CIDEr) for a wide variety of image captioning baselines. These results are further confirmed through a user study.
Fine-Grained Crowd Counting
Jul 13, 2020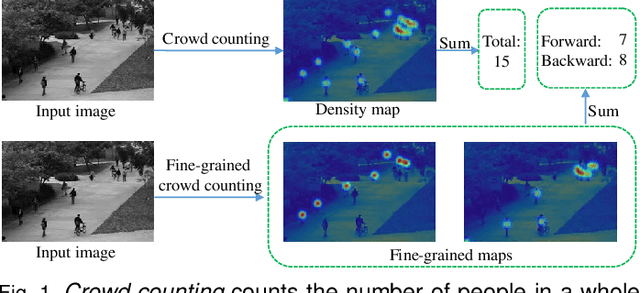


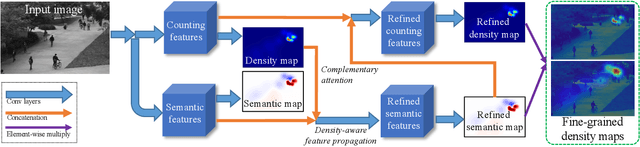
Current crowd counting algorithms are only concerned about the number of people in an image, which lacks low-level fine-grained information of the crowd. For many practical applications, the total number of people in an image is not as useful as the number of people in each sub-category. E.g., knowing the number of people waiting inline or browsing can help retail stores; knowing the number of people standing/sitting can help restaurants/cafeterias; knowing the number of violent/non-violent people can help police in crowd management. In this paper, we propose fine-grained crowd counting, which differentiates a crowd into categories based on the low-level behavior attributes of the individuals (e.g. standing/sitting or violent behavior) and then counts the number of people in each category. To enable research in this area, we construct a new dataset of four real-world fine-grained counting tasks: traveling direction on a sidewalk, standing or sitting, waiting in line or not, and exhibiting violent behavior or not. Since the appearance features of different crowd categories are similar, the challenge of fine-grained crowd counting is to effectively utilize contextual information to distinguish between categories. We propose a two branch architecture, consisting of a density map estimation branch and a semantic segmentation branch. We propose two refinement strategies for improving the predictions of the two branches. First, to encode contextual information, we propose feature propagation guided by the density map prediction, which eliminates the effect of background features during propagation. Second, we propose a complementary attention model to share information between the two branches. Experiment results confirm the effectiveness of our method.
Single-Frame based Deep View Synchronization for Unsynchronized Multi-Camera Surveillance
Jul 08, 2020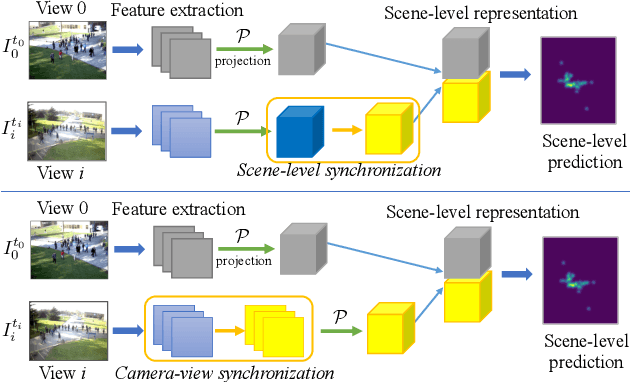
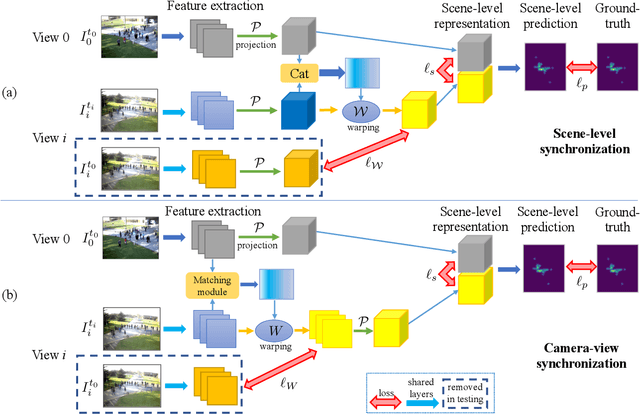

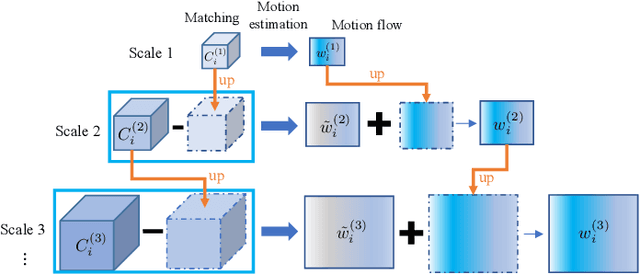
Multi-camera surveillance has been an active research topic for understanding and modeling scenes. Compared to a single camera, multi-cameras provide larger field-of-view and more object cues, and the related applications are multi-view counting, multi-view tracking, 3D pose estimation or 3D reconstruction, etc. It is usually assumed that the cameras are all temporally synchronized when designing models for these multi-camera based tasks. However, this assumption is not always valid,especially for multi-camera systems with network transmission delay and low frame-rates due to limited network bandwidth, resulting in desynchronization of the captured frames across cameras. To handle the issue of unsynchronized multi-cameras, in this paper, we propose a synchronization model that works in conjunction with existing DNN-based multi-view models, thus avoiding the redesign of the whole model. Under the low-fps regime, we assume that only a single relevant frame is available from each view, and synchronization is achieved by matching together image contents guided by epipolar geometry. We consider two variants of the model, based on where in the pipeline the synchronization occurs, scene-level synchronization and camera-level synchronization. The view synchronization step and the task-specific view fusion and prediction step are unified in the same framework and trained in an end-to-end fashion. Our view synchronization models are applied to different DNNs-based multi-camera vision tasks under the unsynchronized setting, including multi-view counting and 3D pose estimation, and achieve good performance compared to baselines.
Over-crowdedness Alert! Forecasting the Future Crowd Distribution
Jun 09, 2020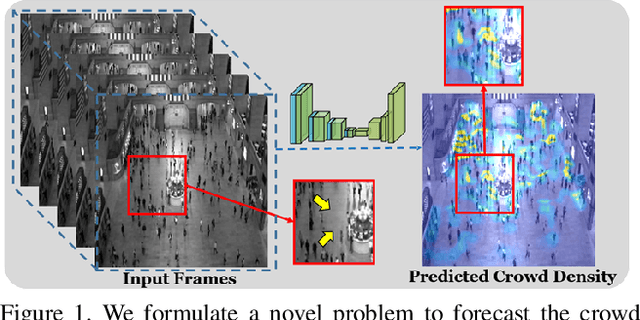
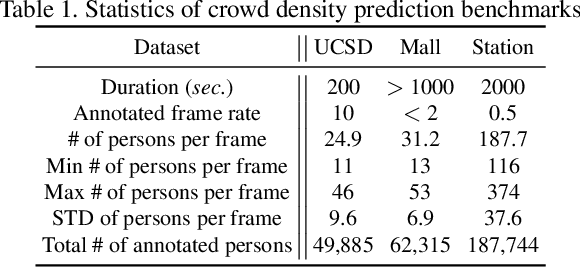
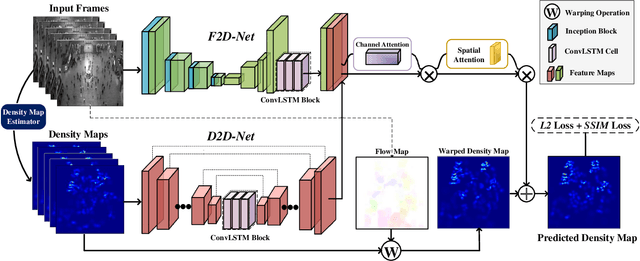

In recent years, vision-based crowd analysis has been studied extensively due to its practical applications in real world. In this paper, we formulate a novel crowd analysis problem, in which we aim to predict the crowd distribution in the near future given sequential frames of a crowd video without any identity annotations. Studying this research problem will benefit applications concerned with forecasting crowd dynamics. To solve this problem, we propose a global-residual two-stream recurrent network, which leverages the consecutive crowd video frames as inputs and their corresponding density maps as auxiliary information to predict the future crowd distribution. Moreover, to strengthen the capability of our network, we synthesize scene-specific crowd density maps using simulated data for pretraining. Finally, we demonstrate that our framework is able to predict the crowd distribution for different crowd scenarios and we delve into applications including predicting future crowd count, forecasting high-density region, etc.
3D Crowd Counting via Multi-View Fusion with 3D Gaussian Kernels
Mar 18, 2020

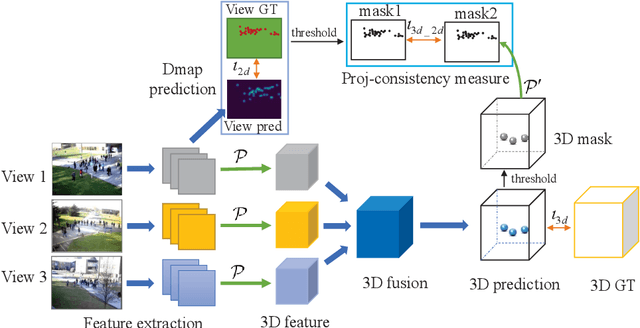
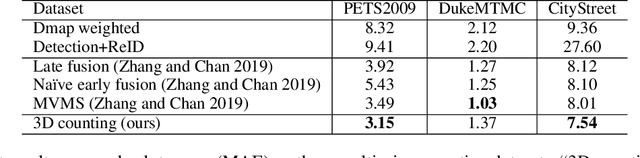
Crowd counting has been studied for decades and a lot of works have achieved good performance, especially the DNNs-based density map estimation methods. Most existing crowd counting works focus on single-view counting, while few works have studied multi-view counting for large and wide scenes, where multiple cameras are used. Recently, an end-to-end multi-view crowd counting method called multi-view multi-scale (MVMS) has been proposed, which fuses multiple camera views using a CNN to predict a 2D scene-level density map on the ground-plane. Unlike MVMS, we propose to solve the multi-view crowd counting task through 3D feature fusion with 3D scene-level density maps, instead of the 2D ground-plane ones. Compared to 2D fusion, the 3D fusion extracts more information of the people along z-dimension (height), which helps to solve the scale variations across multiple views. The 3D density maps still preserve the 2D density maps property that the sum is the count, while also providing 3D information about the crowd density. We also explore the projection consistency among the 3D prediction and the ground-truth in the 2D views to further enhance the counting performance. The proposed method is tested on 3 multi-view counting datasets and achieves better or comparable counting performance to the state-of-the-art.
Towards Diverse and Accurate Image Captions via Reinforcing Determinantal Point Process
Aug 14, 2019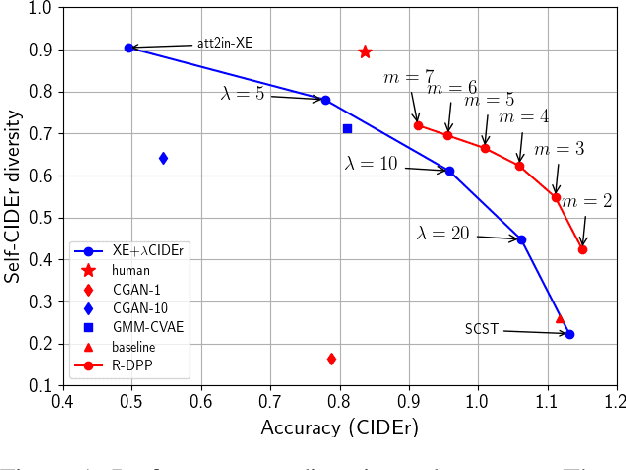
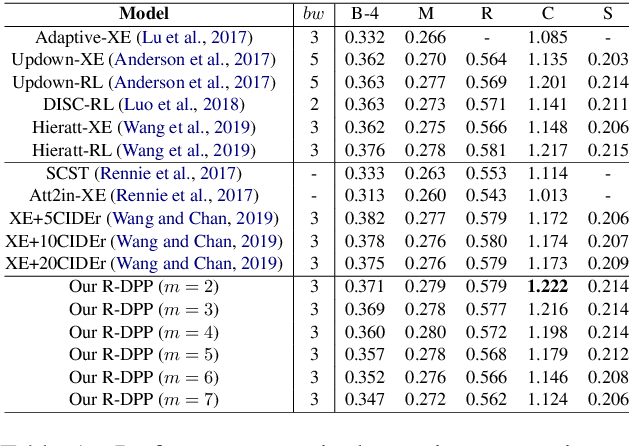
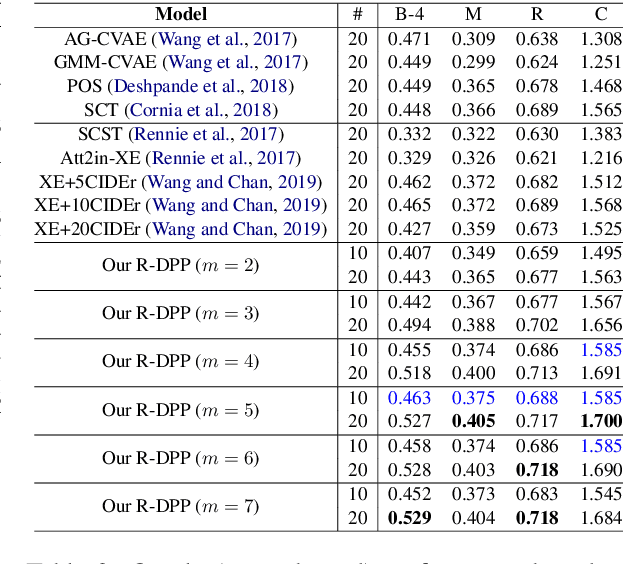

Although significant progress has been made in the field of automatic image captioning, it is still a challenging task. Previous works normally pay much attention to improving the quality of the generated captions but ignore the diversity of captions. In this paper, we combine determinantal point process (DPP) and reinforcement learning (RL) and propose a novel reinforcing DPP (R-DPP) approach to generate a set of captions with high quality and diversity for an image. We show that R-DPP performs better on accuracy and diversity than using noise as a control signal (GANs, VAEs). Moreover, R-DPP is able to preserve the modes of the learned distribution. Hence, beam search algorithm can be applied to generate a single accurate caption, which performs better than other RL-based models.
ROAM: Recurrently Optimizing Tracking Model
Jul 31, 2019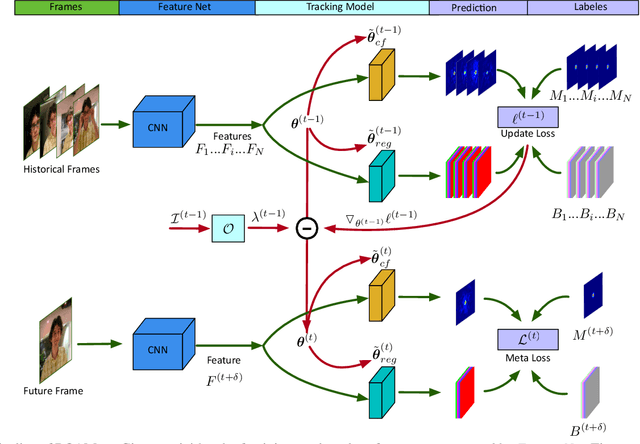
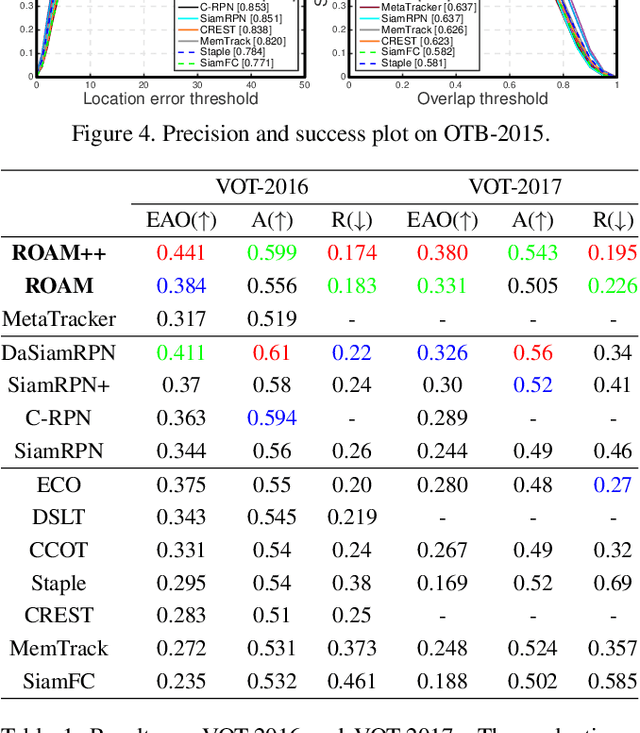
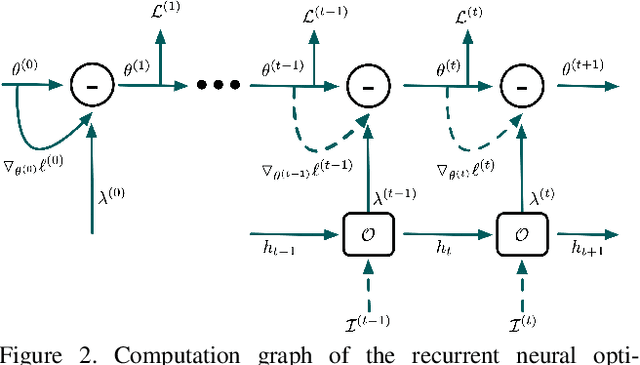
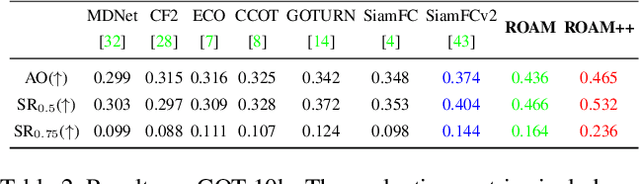
In this paper, we design a tracking model consisting of response generation and bounding box regression, where the first component produces a heat map to indicate the presence of the object at different positions and the second part regresses the relative bounding box shifts to anchors mounted on sliding-window locations. Thanks to the resizable convolutional filters used in both components to adapt to the shape changes of objects, our tracking model does not need to enumerate different sized anchors, thus saving model parameters. To effectively adapt the model to appearance variations, we propose to offline train a recurrent neural optimizer to update tracking model in a meta-learning setting, which can converge the model in a few gradient steps. This improves the convergence speed of updating the tracking model while achieving better performance. Moreover, we also propose a simple yet effective training trick called Random Filter Scaling to prevent overfitting, which boosts the generalization performance greatly. Finally, we extensively evaluate our trackers, ROAM and ROAM++, on the OTB, VOT, LaSOT, GOT-10K and TrackingNet benchmark and our methods perform favorably against state-of-the-art algorithms.