 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eighth Dialog System Technology Challenge
Nov 14, 2019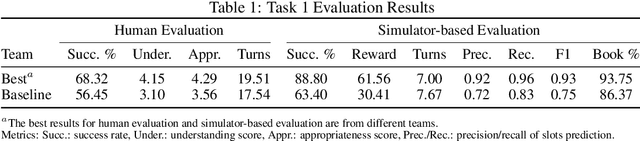
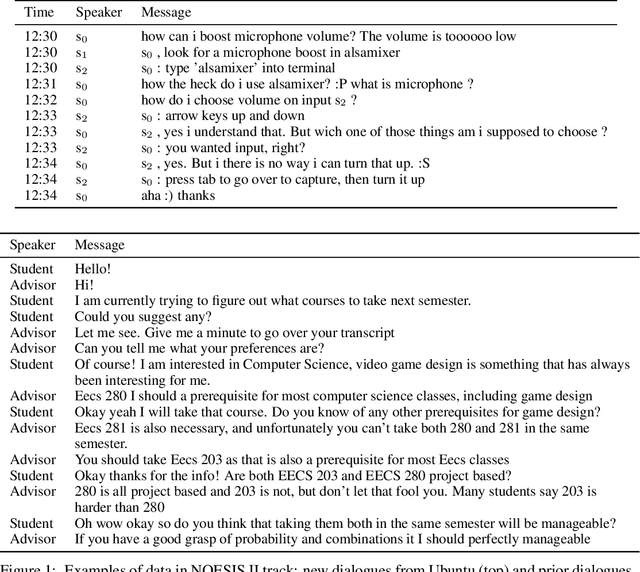
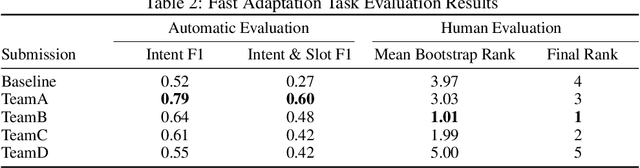
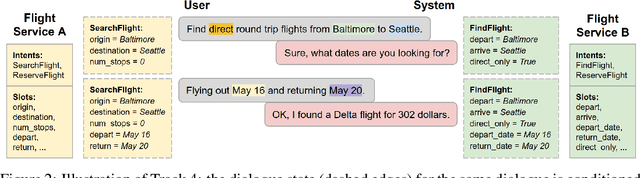
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Discriminative Video Representation Learning Using Support Vector Classifiers
Sep 05, 2019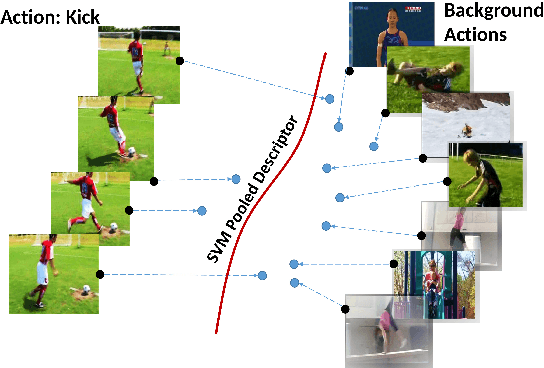

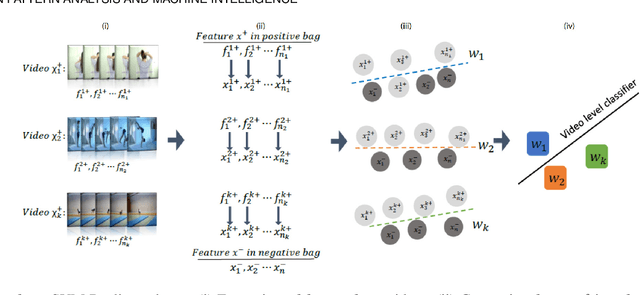
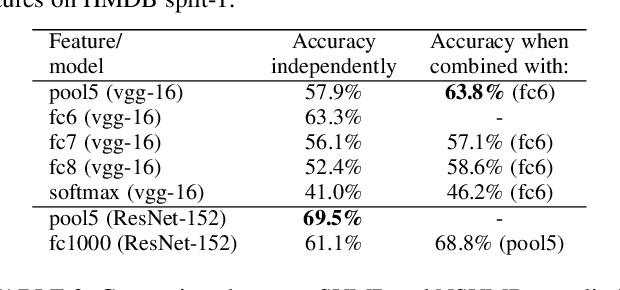
Most popular deep models for action recognition in videos generate independent predictions for short clips, which are then pooled heuristically to assign an action label to the full video segment. As not all frames may characterize the underlying action---many are common across multiple actions---pooling schemes that impose equal importance on all frames might be unfavorable. In an attempt to tackle this problem, we propose discriminative pooling, based on the notion that among the deep features generated on all short clips, there is at least one that characterizes the action. To identify these useful features, we resort to a negative bag consisting of features that are known to be irrelevant, for example, they are sampled either from datasets that are unrelated to our actions of interest or are CNN features produced via random noise as input. With the features from the video as a positive bag and the irrelevant features as the negative bag, we cast an objective to learn a (nonlinear) hyperplane that separates the unknown useful features from the rest in a multiple instance learning formulation within a support vector machine setup. We use the parameters of this separating hyperplane as a descriptor for the full video segment. Since these parameters are directly related to the support vectors in a max-margin framework, they can be treated as a weighted average pooling of the features from the bags, with zero weights given to non-support vectors. Our pooling scheme is end-to-end trainable within a deep learning framework. We report results from experiments on eight computer vision benchmark datasets spanning a variety of video-related tasks and demonstrate state-of-the-art performance across these tasks.
GODS: Generalized One-class Discriminative Subspaces for Anomaly Detection
Aug 16, 2019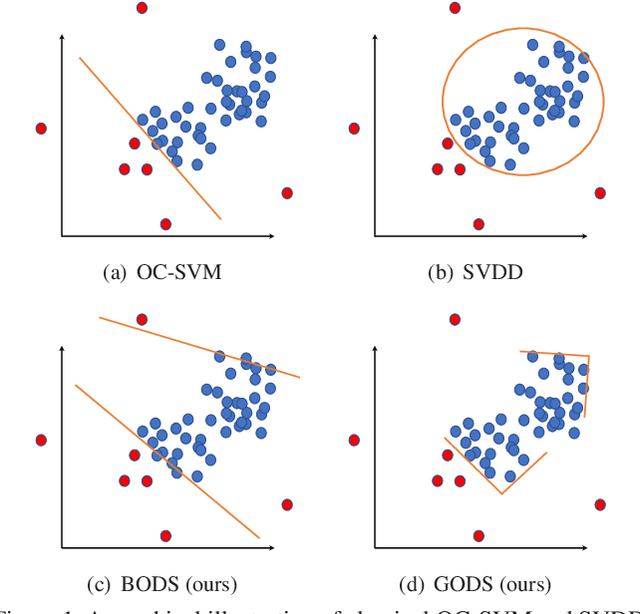


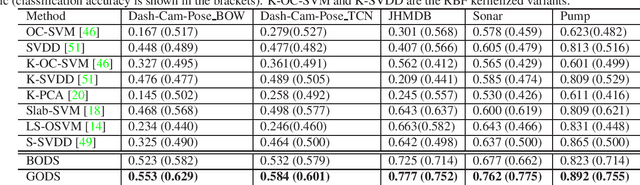
One-class learning is the classic problem of fitting a model to data for which annotations are available only for a single class. In this paper, we propose a novel objective for one-class learning. Our key idea is to use a pair of orthonormal frames -- as subspaces -- to "sandwich" the labeled data via optimizing for two objectives jointly: i) minimize the distance between the origins of the two subspaces, and ii) to maximize the margin between the hyperplanes and the data, either subspace demanding the data to be in its positive and negative orthant respectively. Our proposed objective however leads to a non-convex optimization problem, to which we resort to Riemannian optimization schemes and derive an efficient conjugate gradient scheme on the Stiefel manifold. To study the effectiveness of our scheme, we propose a new dataset~\emph{Dash-Cam-Pose}, consisting of clips with skeleton poses of humans seated in a car, the task being to classify the clips as normal or abnormal; the latter is when any human pose is out-of-position with regard to say an airbag deployment. Our experiments on the proposed Dash-Cam-Pose dataset, as well as several other standard anomaly/novelty detection benchmarks demonstrate the benefits of our scheme, achieving state-of-the-art one-class accuracy.
Game Theoretic Optimization via Gradient-based Nikaido-Isoda Function
May 15, 2019
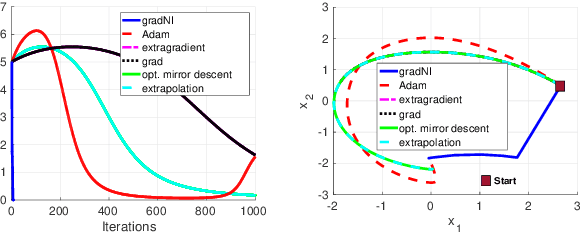
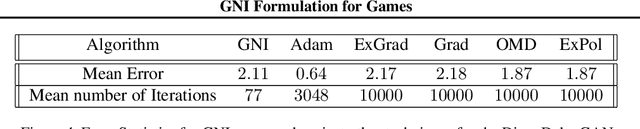
Computing Nash equilibrium (NE) of multi-player games has witnessed renewed interest due to recent advances in generative adversarial networks. However, computing equilibrium efficiently is challenging. To this end, we introduce the Gradient-based Nikaido-Isoda (GNI) function which serves: (i) as a merit function, vanishing only at the first-order stationary points of each player's optimization problem, and (ii) provides error bounds to a stationary Nash point. Gradient descent is shown to converge sublinearly to a first-order stationary point of the GNI function. For the particular case of bilinear min-max games and multi-player quadratic games, the GNI function is convex. Hence, the application of gradient descent in this case yields linear convergence to an NE (when one exists). In our numerical experiments, we observe that the GNI formulation always converges to the first-order stationary point of each player's optimization problem.
Audio-Visual Scene-Aware Dialog
Jan 25, 2019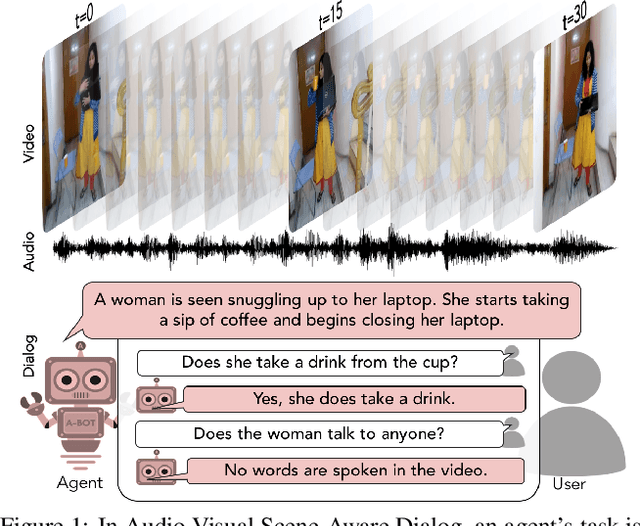
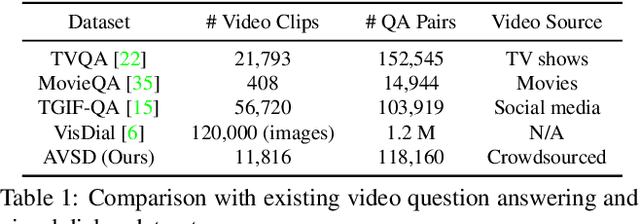


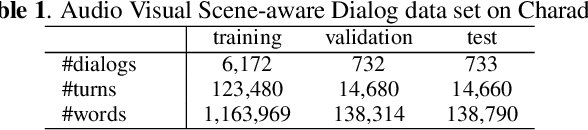
We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
Second-order Temporal Pooling for Action Recognition
Aug 07, 2018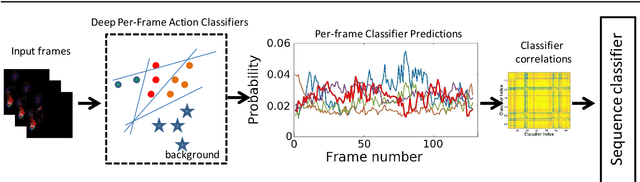
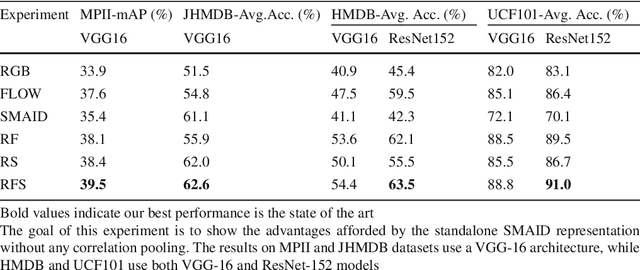
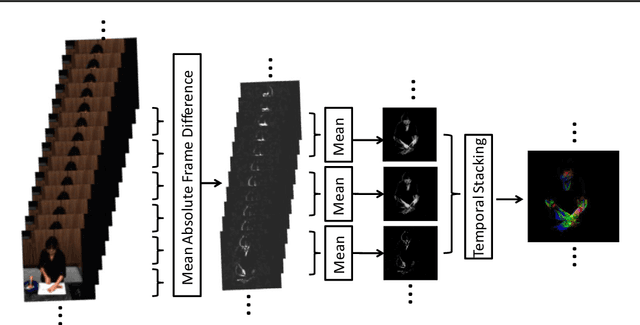
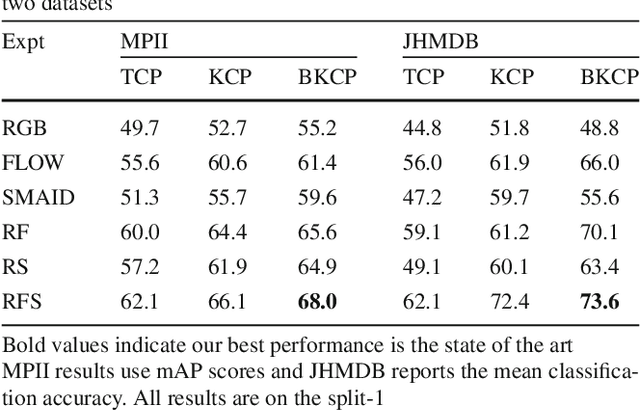
Deep learning models for video-based action recognition usually generate features for short clips (consisting of a few frames); such clip-level features are aggregated to video-level representations by computing statistics on these features. Typically zero-th (max) or the first-order (average) statistics are used. In this paper, we explore the benefits of using second-order statistics. Specifically, we propose a novel end-to-end learnable feature aggregation scheme, dubbed temporal correlation pooling that generates an action descriptor for a video sequence by capturing the similarities between the temporal evolution of clip-level CNN features computed across the video. Such a descriptor, while being computationally cheap, also naturally encodes the co-activations of multiple CNN features, thereby providing a richer characterization of actions than their first-order counterparts. We also propose higher-order extensions of this scheme by computing correlations after embedding the CNN features in a reproducing kernel Hilbert space. We provide experiments on benchmark datasets such as HMDB-51 and UCF-101, fine-grained datasets such as MPII Cooking activities and JHMDB, as well as the recent Kinetics-600. Our results demonstrate the advantages of higher-order pooling schemes that when combined with hand-crafted features (as is standard practice) achieves state-of-the-art accuracy.
Learning Discriminative Video Representations Using Adversarial Perturbations
Jul 26, 2018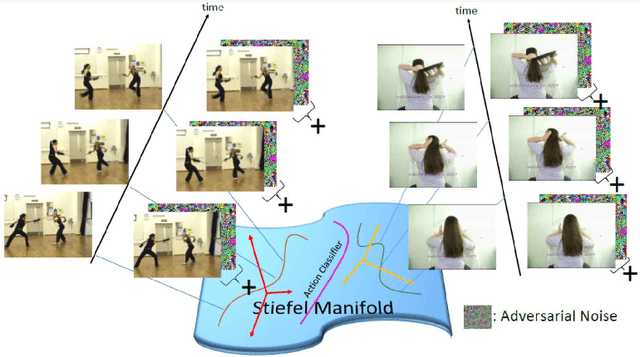

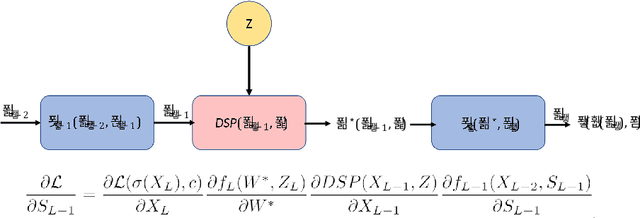
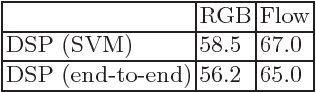
Adversarial perturbations are noise-like patterns that can subtly change the data, while failing an otherwise accurate classifier. In this paper, we propose to use such perturbations for improving the robustness of video representations. To this end, given a well-trained deep model for per-frame video recognition, we first generate adversarial noise adapted to this model. Using the original data features from the full video sequence and their perturbed counterparts, as two separate bags, we develop a binary classification problem that learns a set of discriminative hyperplanes -- as a subspace -- that will separate the two bags from each other. This subspace is then used as a descriptor for the video, dubbed discriminative subspace pooling. As the perturbed features belong to data classes that are likely to be confused with the original features, the discriminative subspace will characterize parts of the feature space that are more representative of the original data, and thus may provide robust video representations. To learn such descriptors, we formulate a subspace learning objective on the Stiefel manifold and resort to Riemannian optimization methods for solving it efficiently. We provide experiments on several video datasets and demonstrate state-of-the-art results.
Sem-GAN: Semantically-Consistent Image-to-Image Translation
Jul 12, 2018
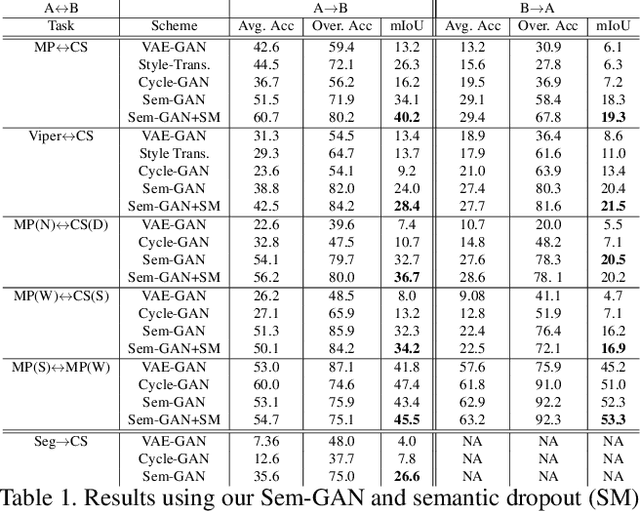
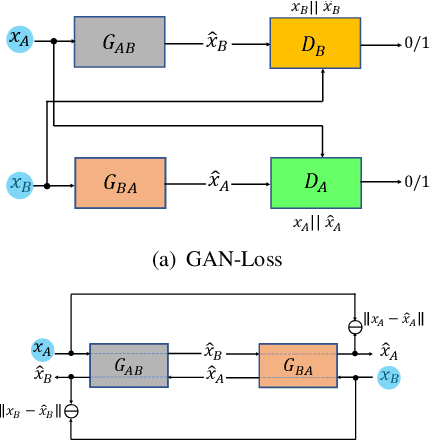
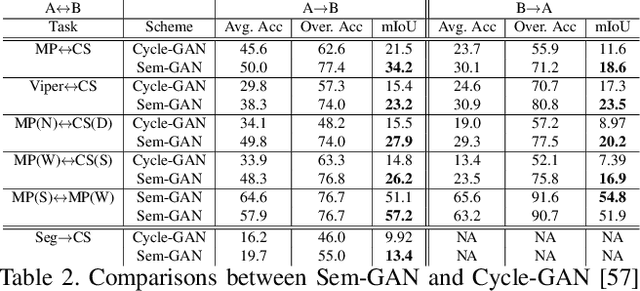
Unpaired image-to-image translation is the problem of mapping an image in the source domain to one in the target domain, without requiring corresponding image pairs. To ensure the translated images are realistically plausible, recent works, such as Cycle-GAN, demands this mapping to be invertible. While, this requirement demonstrates promising results when the domains are unimodal, its performance is unpredictable in a multi-modal scenario such as in an image segmentation task. This is because, invertibility does not necessarily enforce semantic correctness. To this end, we present a semantically-consistent GAN framework, dubbed Sem-GAN, in which the semantics are defined by the class identities of image segments in the source domain as produced by a semantic segmentation algorithm. Our proposed framework includes consistency constraints on the translation task that, together with the GAN loss and the cycle-constraints, enforces that the images when translated will inherit the appearances of the target domain, while (approximately) maintaining their identities from the source domain. We present experiments on several image-to-image translation tasks and demonstrate that Sem-GAN improves the quality of the translated images significantly, sometimes by more than 20% on the FCN score. Further, we show that semantic segmentation models, trained with synthetic images translated via Sem-GAN, leads to significantly better segmentation results than other variants.
End-to-End Audio Visual Scene-Aware Dialog using Multimodal Attention-Based Video Features
Jun 30, 2018
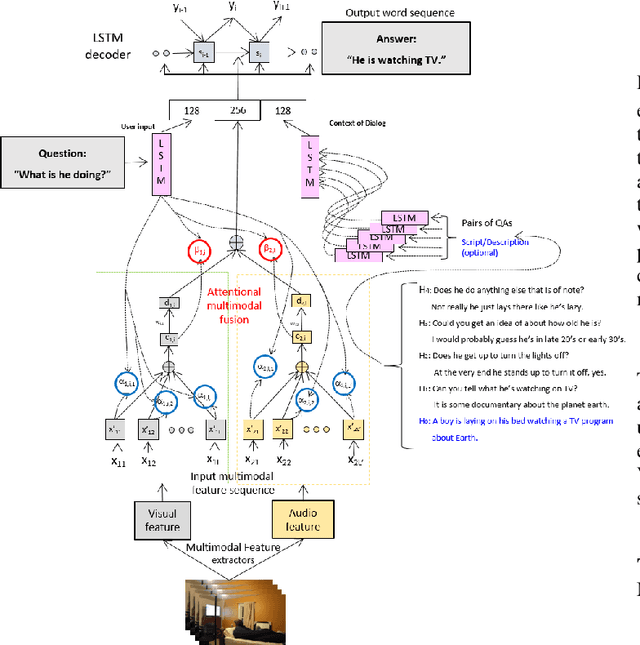
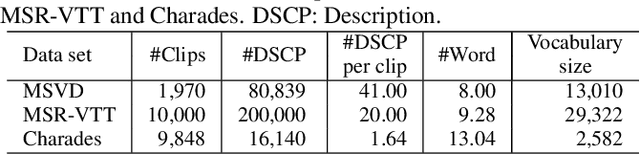
Dialog systems need to understand dynamic visual scenes in order to have conversations with users about the objects and events around them. Scene-aware dialog systems for real-world applications could be developed by integrating state-of-the-art technologies from multiple research areas, including: end-to-end dialog technologies, which generate system responses using models trained from dialog data; visual question answering (VQA) technologies, which answer questions about images using learned image features; and video description technologies, in which descriptions/captions are generated from videos using multimodal information. We introduce a new dataset of dialogs about videos of human behaviors. Each dialog is a typed conversation that consists of a sequence of 10 question-and-answer(QA) pairs between two Amazon Mechanical Turk (AMT) workers. In total, we collected dialogs on roughly 9,000 videos. Using this new dataset for Audio Visual Scene-aware dialog (AVSD), we trained an end-to-end conversation model that generates responses in a dialog about a video. Our experiments demonstrate that using multimodal features that were developed for multimodal attention-based video description enhances the quality of generated dialog about dynamic scenes (videos). Our dataset, model code and pretrained models will be publicly available for a new Video Scene-Aware Dialog challenge.
Audio Visual Scene-Aware Dialog Challenge at DSTC7
Jun 01, 2018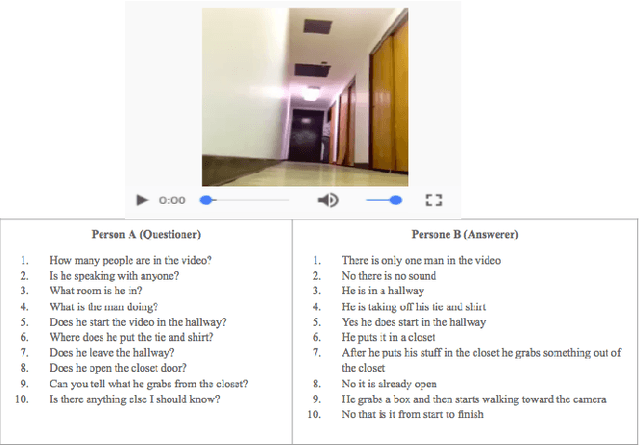
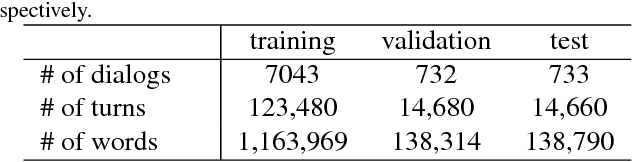
Scene-aware dialog systems will be able to have conversations with users about the objects and events around them. Progress on such systems can be made by integrating state-of-the-art technologies from multiple research areas including end-to-end dialog systems visual dialog, and video description. We introduce the Audio Visual Scene Aware Dialog (AVSD) challenge and dataset. In this challenge, which is one track of the 7th Dialog System Technology Challenges (DSTC7) workshop1, the task is to build a system that generates responses in a dialog about an input video