 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution generalization of quantile regression with heavy tailed inputs: an SVM approach
May 29, 2026We study quantile regression in an extrapolation regime where the covariate takes unusually large values. Under regular variation assumptions, extreme observations can be effectively characterized through their angular components, enabling learning strategies that focus on the angle of the most extreme observations. This approach is formalized through the minimization of an asymptotic conditional risk that localizes learning in the tail of the covariate distribution. We propose a novel Support Vector Machine (SVM) framework for extreme quantile regression, leveraging reproducing kernel Hilbert spaces to handle high-dimensional and nonlinear settings. Our method also accommodates unbounded response variables and avoids restrictive transformations. We establish finite-sample learning guarantees under mild regularity assumptions. The proposed framework unifies ideas from statistical learning and multivariate extremes, providing a tractable and theoretically grounded approach to extrapolation. We complement our theoretical findings with an empirical study on river flow data from the Danube, demonstrating the practical relevance of our methods.
Polar Depth for Potentially Heavy-Tailed Data
May 29, 2026Motivated by the analysis of the behaviour of extremes from multivariate heavy-tailed distributions, we introduce a novel notion of statistical depth, referred to as Polar Depth. The polar depth function is naturally expressed in polar coordinates, as is the limiting distribution of a regularly varying random variable, beyond asymptotically large thresholds, once its marginals have been appropriately normalized. Not only does the polar depth function make it easy to order the extreme values taken by a heavy-tailed random variable X and finds natural applications in anomaly detection, but it is also possible to show, as we prove it under appropriate assumptions in this article, that the polar depth of the largest observations, i.e. observations X which norm is larger than t>0, converges to the polar depth of the limiting distribution as t converges to infinity. Although designed to quantify the depth of multivariate extremes, the polar depth is interesting in its own right, insofar as this notion is more relevant for distributions whose support is included in a halfspace than the alternatives proposed in the literature, the halfspace depth in particular. Here, we demonstrate its properties and analyze statistical issues related to its estimation from both finite-sample and asymptotic points of view. We present numerical results to empirically demonstrate its relevance, particularly for the statistical analysis of extreme observations and more specifically for the identification of anomalies among them.
Extrapolation in Statistical Learning with Extreme Value Theory
May 03, 2026Extreme value theory provides rigorous theory and statistical tools for extrapolation in machine learning, particularly in settings where traditional methods struggle due to data scarcity in the tails. A broad range of tasks benefit from these advances, including regression and classification beyond the training data, extreme quantile regression, supervised and unsupervised dimension reduction, generative artificial intelligence and anomaly detection. This review synthesizes recent developments in these fields at the intersection of statistical learning and extreme value theory, with a focus on principled methods based on asymptotically motivated representations of the tail of univariate and multivariate distributions. We consider different theoretical frameworks for both asymptotically dependent and independent data and discuss how they translate into efficient statistical methods for extrapolation to extreme regions. By addressing both theoretical and practical aspects, we offer a comprehensive overview of the state-of-the-art in this quickly evolving field, and identify promising directions for future research.
Multi-site modelling and reconstruction of past extreme skew surges along the French Atlantic coast
May 01, 2025



Appropriate modelling of extreme skew surges is crucial, particularly for coastal risk management. Our study focuses on modelling extreme skew surges along the French Atlantic coast, with a particular emphasis on investigating the extremal dependence structure between stations. We employ the peak-over-threshold framework, where a multivariate extreme event is defined whenever at least one location records a large value, though not necessarily all stations simultaneously. A novel method for determining an appropriate level (threshold) above which observations can be classified as extreme is proposed. Two complementary approaches are explored. First, the multivariate generalized Pareto distribution is employed to model extremes, leveraging its properties to derive a generative model that predicts extreme skew surges at one station based on observed extremes at nearby stations. Second, a novel extreme regression framework is assessed for point predictions. This specific regression framework enables accurate point predictions using only the "angle" of input variables, i.e. input variables divided by their norms. The ultimate objective is to reconstruct historical skew surge time series at stations with limited data. This is achieved by integrating extreme skew surge data from stations with longer records, such as Brest and Saint-Nazaire, which provide over 150 years of observations.
Sharp error bounds for imbalanced classification: how many examples in the minority class?
Oct 23, 2023



When dealing with imbalanced classification data, reweighting the loss function is a standard procedure allowing to equilibrate between the true positive and true negative rates within the risk measure. Despite significant theoretical work in this area, existing results do not adequately address a main challenge within the imbalanced classification framework, which is the negligible size of one class in relation to the full sample size and the need to rescale the risk function by a probability tending to zero. To address this gap, we present two novel contributions in the setting where the rare class probability approaches zero: (1) a non asymptotic fast rate probability bound for constrained balanced empirical risk minimization, and (2) a consistent upper bound for balanced nearest neighbors estimates. Our findings provide a clearer understanding of the benefits of class-weighting in realistic settings, opening new avenues for further research in this field.
Regular Variation in Hilbert Spaces and Principal Component Analysis for Functional Extremes
Aug 02, 2023



Motivated by the increasing availability of data of functional nature, we develop a general probabilistic and statistical framework for extremes of regularly varying random elements $X$ in $L^2[0,1]$. We place ourselves in a Peaks-Over-Threshold framework where a functional extreme is defined as an observation $X$ whose $L^2$-norm $\|X\|$ is comparatively large. Our goal is to propose a dimension reduction framework resulting into finite dimensional projections for such extreme observations. Our contribution is double. First, we investigate the notion of Regular Variation for random quantities valued in a general separable Hilbert space, for which we propose a novel concrete characterization involving solely stochastic convergence of real-valued random variables. Second, we propose a notion of functional Principal Component Analysis (PCA) accounting for the principal `directions' of functional extremes. We investigate the statistical properties of the empirical covariance operator of the angular component of extreme functions, by upper-bounding the Hilbert-Schmidt norm of the estimation error for finite sample sizes. Numerical experiments with simulated and real data illustrate this work.
On Regression in Extreme Regions
Mar 06, 2023



In the classic regression problem, the value of a real-valued random variable $Y$ is to be predicted based on the observation of a random vector $X$, taking its values in $\mathbb{R}^d$ with $d\geq 1$ say. The statistical learning problem consists in building a predictive function $\hat{f}:\mathbb{R}^d\to \mathbb{R}$ based on independent copies of the pair $(X,Y)$ so that $Y$ is approximated by $\hat{f}(X)$ with minimum error in the mean-squared sense. Motivated by various applications, ranging from environmental sciences to finance or insurance, special attention is paid here to the case of extreme (i.e. very large) observations $X$. Because of their rarity, they contribute in a negligible manner to the (empirical) error and the predictive performance of empirical quadratic risk minimizers can be consequently very poor in extreme regions. In this paper, we develop a general framework for regression in the extremes. It is assumed that $X$'s conditional distribution given $Y$ belongs to a non parametric class of heavy-tailed probability distributions. It is then shown that an asymptotic notion of risk can be tailored to summarize appropriately predictive performance in extreme regions of the input space. It is also proved that minimization of an empirical and non asymptotic version of this 'extreme risk', based on a fraction of the largest observations solely, yields regression functions with good generalization capacity. In addition, numerical results providing strong empirical evidence of the relevance of the approach proposed are displayed.
Concentration bounds for the empirical angular measure with statistical learning applications
Apr 07, 2021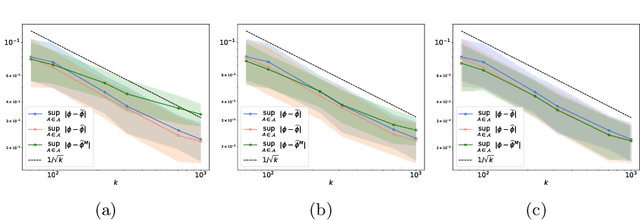
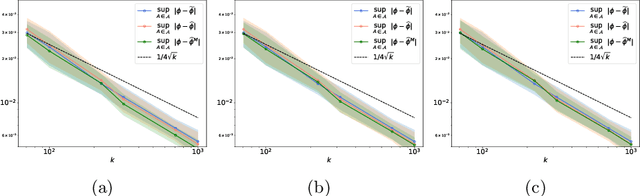
The angular measure on the unit sphere characterizes the first-order dependence structure of the components of a random vector in extreme regions and is defined in terms of standardized margins. Its statistical recovery is an important step in learning problems involving observations far away from the center. In the common situation when the components of the vector have different distributions, the rank transformation offers a convenient and robust way of standardizing data in order to build an empirical version of the angular measure based on the most extreme observations. However, the study of the sampling distribution of the resulting empirical angular measure is challenging. It is the purpose of the paper to establish finite-sample bounds for the maximal deviations between the empirical and true angular measures, uniformly over classes of Borel sets of controlled combinatorial complexity. The bounds are valid with high probability and scale essentially as the square root of the effective sample size, up to a logarithmic factor. Discarding the most extreme observations yields a truncated version of the empirical angular measure for which the logarithmic factor in the concentration bound is replaced by a factor depending on the truncation level. The bounds are applied to provide performance guarantees for two statistical learning procedures tailored to extreme regions of the input space and built upon the empirical angular measure: binary classification in extreme regions through empirical risk minimization and unsupervised anomaly detection through minimum-volume sets of the sphere.
Heavy-tailed Representations, Text Polarity Classification & Data Augmentation
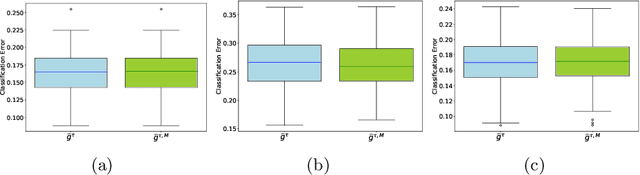
Mar 25, 2020
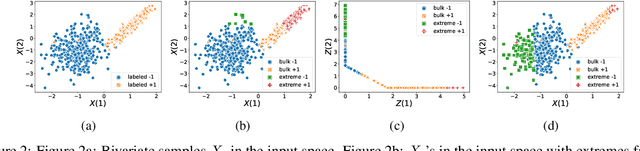
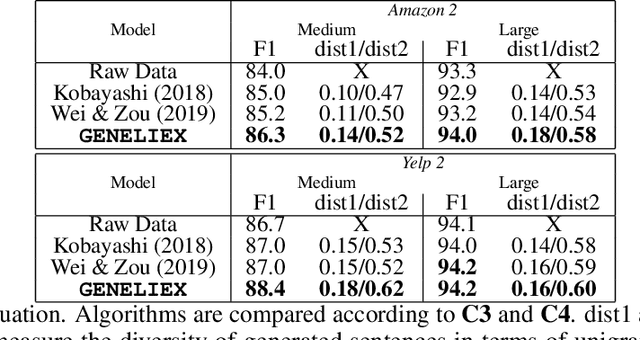
The dominant approaches to text representation in natural language rely on learning embeddings on massive corpora which have convenient properties such as compositionality and distance preservation. In this paper, we develop a novel method to learn a heavy-tailed embedding with desirable regularity properties regarding the distributional tails, which allows to analyze the points far away from the distribution bulk using the framework of multivariate extreme value theory. In particular, a classifier dedicated to the tails of the proposed embedding is obtained which performance outperforms the baseline. This classifier exhibits a scale invariance property which we leverage by introducing a novel text generation method for label preserving dataset augmentation. Numerical experiments on synthetic and real text data demonstrate the relevance of the proposed framework and confirm that this method generates meaningful sentences with controllable attribute, e.g. positive or negative sentiment.
A Multivariate Extreme Value Theory Approach to Anomaly Clustering and Visualization
Jul 17, 2019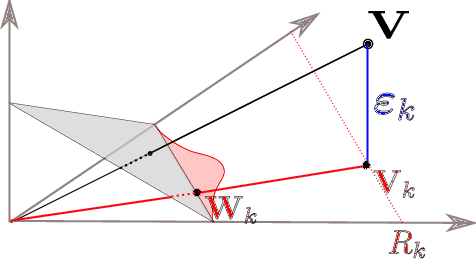



In a wide variety of situations, anomalies in the behaviour of a complex system, whose health is monitored through the observation of a random vector X = (X1,. .. , X d) valued in R d , correspond to the simultaneous occurrence of extreme values for certain subgroups $\alpha$ $\subset$ {1,. .. , d} of variables Xj. Under the heavy-tail assumption, which is precisely appropriate for modeling these phenomena, statistical methods relying on multivariate extreme value theory have been developed in the past few years for identifying such events/subgroups. This paper exploits this approach much further by means of a novel mixture model that permits to describe the distribution of extremal observations and where the anomaly type $\alpha$ is viewed as a latent variable. One may then take advantage of the model by assigning to any extreme point a posterior probability for each anomaly type $\alpha$, defining implicitly a similarity measure between anomalies. It is explained at length how the latter permits to cluster extreme observations and obtain an informative planar representation of anomalies using standard graph-mining tools. The relevance and usefulness of the clustering and 2-d visual display thus designed is illustrated on simulated datasets and on real observations as well, in the aeronautics application domain.