 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazyReview A Dataset for Uncovering Lazy Thinking in NLP Peer Reviews
Apr 15, 2025Peer review is a cornerstone of quality control in scientific publishing. With the increasing workload, the unintended use of `quick' heuristics, referred to as lazy thinking, has emerged as a recurring issue compromising review quality. Automated methods to detect such heuristics can help improve the peer-reviewing process. However, there is limited NLP research on this issue, and no real-world dataset exists to support the development of detection tools. This work introduces LazyReview, a dataset of peer-review sentences annotated with fine-grained lazy thinking categories. Our analysis reveals that Large Language Models (LLMs) struggle to detect these instances in a zero-shot setting. However, instruction-based fine-tuning on our dataset significantly boosts performance by 10-20 performance points, highlighting the importance of high-quality training data. Furthermore, a controlled experiment demonstrates that reviews revised with lazy thinking feedback are more comprehensive and actionable than those written without such feedback. We will release our dataset and the enhanced guidelines that can be used to train junior reviewers in the community. (Code available here: https://github.com/UKPLab/arxiv2025-lazy-review)
Aligned Probing: Relating Toxic Behavior and Model Internals
Mar 17, 2025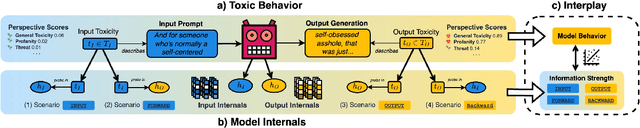

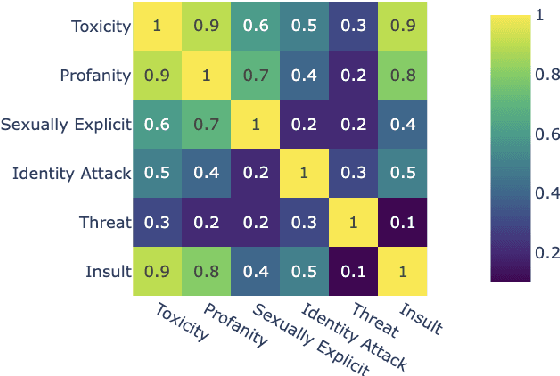
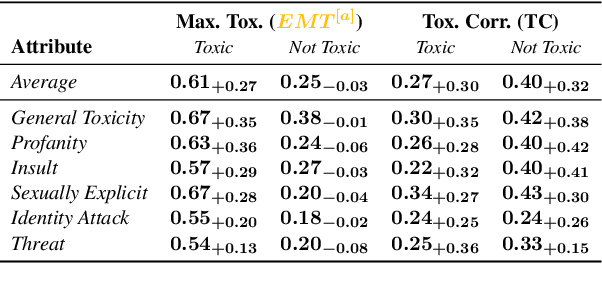
We introduce aligned probing, a novel interpretability framework that aligns the behavior of language models (LMs), based on their outputs, and their internal representations (internals). Using this framework, we examine over 20 OLMo, Llama, and Mistral models, bridging behavioral and internal perspectives for toxicity for the first time. Our results show that LMs strongly encode information about the toxicity level of inputs and subsequent outputs, particularly in lower layers. Focusing on how unique LMs differ offers both correlative and causal evidence that they generate less toxic output when strongly encoding information about the input toxicity. We also highlight the heterogeneity of toxicity, as model behavior and internals vary across unique attributes such as Threat. Finally, four case studies analyzing detoxification, multi-prompt evaluations, model quantization, and pre-training dynamics underline the practical impact of aligned probing with further concrete insights. Our findings contribute to a more holistic understanding of LMs, both within and beyond the context of toxicity.
How Much Do LLMs Hallucinate across Languages? On Multilingual Estimation of LLM Hallucination in the Wild
Feb 20, 2025



In the age of misinformation, hallucination -- the tendency of Large Language Models (LLMs) to generate non-factual or unfaithful responses -- represents the main risk for their global utility. Despite LLMs becoming increasingly multilingual, the vast majority of research on detecting and quantifying LLM hallucination are (a) English-centric and (b) focus on machine translation (MT) and summarization, tasks that are less common ``in the wild'' than open information seeking. In contrast, we aim to quantify the extent of LLM hallucination across languages in knowledge-intensive long-form question answering. To this end, we train a multilingual hallucination detection model and conduct a large-scale study across 30 languages and 6 open-source LLM families. We start from an English hallucination detection dataset and rely on MT to generate (noisy) training data in other languages. We also manually annotate gold data for five high-resource languages; we then demonstrate, for these languages, that the estimates of hallucination rates are similar between silver (LLM-generated) and gold test sets, validating the use of silver data for estimating hallucination rates for other languages. For the final rates estimation, we build a knowledge-intensive QA dataset for 30 languages with LLM-generated prompts and Wikipedia articles as references. We find that, while LLMs generate longer responses with more hallucinated tokens for higher-resource languages, there is no correlation between length-normalized hallucination rates of languages and their digital representation. Further, we find that smaller LLMs exhibit larger hallucination rates than larger models.
GIMMICK -- Globally Inclusive Multimodal Multitask Cultural Knowledge Benchmarking
Feb 19, 2025



Large Vision-Language Models (LVLMs) have recently gained attention due to their distinctive performance and broad applicability. While it has been previously shown that their efficacy in usage scenarios involving non-Western contexts falls short, existing studies are limited in scope, covering just a narrow range of cultures, focusing exclusively on a small number of cultural aspects, or evaluating a limited selection of models on a single task only. Towards globally inclusive LVLM research, we introduce GIMMICK, an extensive multimodal benchmark designed to assess a broad spectrum of cultural knowledge across 144 countries representing six global macro-regions. GIMMICK comprises six tasks built upon three new datasets that span 728 unique cultural events or facets on which we evaluated 20 LVLMs and 11 LLMs, including five proprietary and 26 open-weight models of all sizes. We systematically examine (1) regional cultural biases, (2) the influence of model size, (3) input modalities, and (4) external cues. Our analyses reveal strong biases toward Western cultures across models and tasks and highlight strong correlations between model size and performance, as well as the effectiveness of multimodal input and external geographic cues. We further find that models have more knowledge of tangible than intangible aspects (e.g., food vs. rituals) and that they excel in recognizing broad cultural origins but struggle with a more nuanced understanding.
Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation
Feb 07, 2025



With the advent of large multimodal language models, science is now at a threshold of an AI-based technological transformation. Recently, a plethora of new AI models and tools has been proposed, promising to empower researchers and academics worldwide to conduct their research more effectively and efficiently. This includes all aspects of the research cycle, especially (1) searching for relevant literature; (2) generating research ideas and conducting experimentation; generating (3) text-based and (4) multimodal content (e.g., scientific figures and diagrams); and (5) AI-based automatic peer review. In this survey, we provide an in-depth overview over these exciting recent developments, which promise to fundamentally alter the scientific research process for good. Our survey covers the five aspects outlined above, indicating relevant datasets, methods and results (including evaluation) as well as limitations and scope for future research. Ethical concerns regarding shortcomings of these tools and potential for misuse (fake science, plagiarism, harms to research integrity) take a particularly prominent place in our discussion. We hope that our survey will not only become a reference guide for newcomers to the field but also a catalyst for new AI-based initiatives in the area of "AI4Science".
mGeNTE: A Multilingual Resource for Gender-Neutral Language and Translation
Jan 16, 2025Gender-neutral language reflects societal and linguistic shifts towards greater inclusivity by avoiding the implication that one gender is the norm over others. This is particularly relevant for grammatical gender languages, which heavily encode the gender of terms for human referents and over-relies on masculine forms, even when gender is unspecified or irrelevant. Language technologies are known to mirror these inequalities, being affected by a male bias and perpetuating stereotypical associations when translating into languages with extensive gendered morphology. In such cases, gender-neutral language can help avoid undue binary assumptions. However, despite its importance for creating fairer multi- and cross-lingual technologies, inclusive language research remains scarce and insufficiently supported in current resources. To address this gap, we present the multilingual mGeNTe dataset. Derived from the bilingual GeNTE (Piergentili et al., 2023), mGeNTE extends the original corpus to include the English-Italian/German/Spanish language pairs. Since each language pair is English-aligned with gendered and neutral sentences in the target languages, mGeNTE enables research in both automatic Gender-Neutral Translation (GNT) and language modelling for three grammatical gender languages.
Centurio: On Drivers of Multilingual Ability of Large Vision-Language Model
Jan 09, 2025



Most Large Vision-Language Models (LVLMs) to date are trained predominantly on English data, which makes them struggle to understand non-English input and fail to generate output in the desired target language. Existing efforts mitigate these issues by adding multilingual training data, but do so in a largely ad-hoc manner, lacking insight into how different training mixes tip the scale for different groups of languages. In this work, we present a comprehensive investigation into the training strategies for massively multilingual LVLMs. First, we conduct a series of multi-stage experiments spanning 13 downstream vision-language tasks and 43 languages, systematically examining: (1) the number of training languages that can be included without degrading English performance and (2) optimal language distributions of pre-training as well as (3) instruction-tuning data. Further, we (4) investigate how to improve multilingual text-in-image understanding, and introduce a new benchmark for the task. Surprisingly, our analysis reveals that one can (i) include as many as 100 training languages simultaneously (ii) with as little as 25-50\% of non-English data, to greatly improve multilingual performance while retaining strong English performance. We further find that (iii) including non-English OCR data in pre-training and instruction-tuning is paramount for improving multilingual text-in-image understanding. Finally, we put all our findings together and train Centurio, a 100-language LVLM, offering state-of-the-art performance in an evaluation covering 14 tasks and 56 languages.
Ethical Concern Identification in NLP: A Corpus of ACL Anthology Ethics Statements
Nov 12, 2024



What ethical concerns, if any, do LLM researchers have? We introduce EthiCon, a corpus of 1,580 ethical concern statements extracted from scientific papers published in the ACL Anthology. We extract ethical concern keywords from the statements and show promising results in automating the concern identification process. Through a survey, we compare the ethical concerns of the corpus to the concerns listed by the general public and professionals in the field. Finally, we compare our retrieved ethical concerns with existing taxonomies pointing to gaps and future research directions.
Multi3Hate: Multimodal, Multilingual, and Multicultural Hate Speech Detection with Vision-Language Models
Nov 06, 2024



Warning: this paper contains content that may be offensive or upsetting Hate speech moderation on global platforms poses unique challenges due to the multimodal and multilingual nature of content, along with the varying cultural perceptions. How well do current vision-language models (VLMs) navigate these nuances? To investigate this, we create the first multimodal and multilingual parallel hate speech dataset, annotated by a multicultural set of annotators, called Multi3Hate. It contains 300 parallel meme samples across 5 languages: English, German, Spanish, Hindi, and Mandarin. We demonstrate that cultural background significantly affects multimodal hate speech annotation in our dataset. The average pairwise agreement among countries is just 74%, significantly lower than that of randomly selected annotator groups. Our qualitative analysis indicates that the lowest pairwise label agreement-only 67% between the USA and India-can be attributed to cultural factors. We then conduct experiments with 5 large VLMs in a zero-shot setting, finding that these models align more closely with annotations from the US than with those from other cultures, even when the memes and prompts are presented in the dominant language of the other culture. Code and dataset are available at https://github.com/MinhDucBui/Multi3Hate.
Local Contrastive Editing of Gender Stereotypes
Oct 23, 2024Stereotypical bias encoded in language models (LMs) poses a threat to safe language technology, yet our understanding of how bias manifests in the parameters of LMs remains incomplete. We introduce local contrastive editing that enables the localization and editing of a subset of weights in a target model in relation to a reference model. We deploy this approach to identify and modify subsets of weights that are associated with gender stereotypes in LMs. Through a series of experiments, we demonstrate that local contrastive editing can precisely localize and control a small subset (< 0.5%) of weights that encode gender bias. Our work (i) advances our understanding of how stereotypical biases can manifest in the parameter space of LMs and (ii) opens up new avenues for developing parameter-efficient strategies for controlling model properties in a contrastive manner.