 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiled AI: Deterministic Code Generation for LLM-Based Workflow Automation
Apr 06, 2026We study compiled AI, a paradigm in which large language models generate executable code artifacts during a compilation phase, after which workflows execute deterministically without further model invocation. This paradigm has antecedents in prior work on declarative pipeline optimization (DSPy) and hybrid neural-symbolic planning (LLM+P); our contribution is a systems-oriented study of its application to high-stakes enterprise workflows, with particular emphasis on healthcare settings where reliability and auditability are critical. By constraining generation to narrow business-logic functions embedded in validated templates, compiled AI trades runtime flexibility for predictability, auditability, cost efficiency, and reduced security exposure. We introduce (i) a system architecture for constrained LLM-based code generation, (ii) a four-stage generation-and-validation pipeline that converts probabilistic model output into production-ready code artifacts, and (iii) an evaluation framework measuring operational metrics including token amortization, determinism, reliability, security, and cost. We evaluate on two task types: function-calling (BFCL, n=400) and document intelligence (DocILE, n=5,680 invoices). On function-calling, compiled AI achieves 96% task completion with zero execution tokens, breaking even with runtime inference at approximately 17 transactions and reducing token consumption by 57x at 1,000 transactions. On document intelligence, our Code Factory variant matches Direct LLM on key field extraction (KILE: 80.0%) while achieving the highest line item recognition accuracy (LIR: 80.4%). Security evaluation across 135 test cases demonstrates 96.7% accuracy on prompt injection detection and 87.5% on static code safety analysis with zero false positives.
Missing MRI Pulse Sequence Synthesis using Multi-Modal Generative Adversarial Network
Apr 27, 2019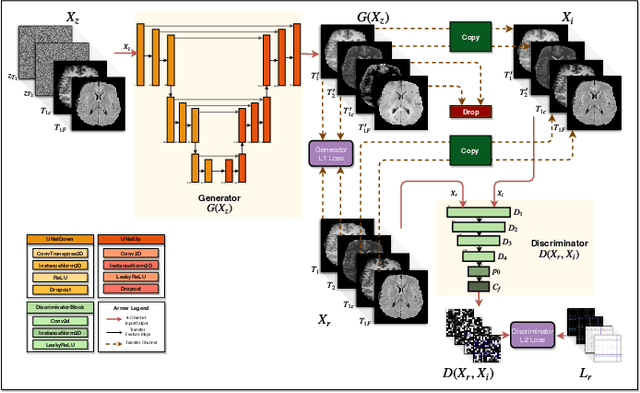
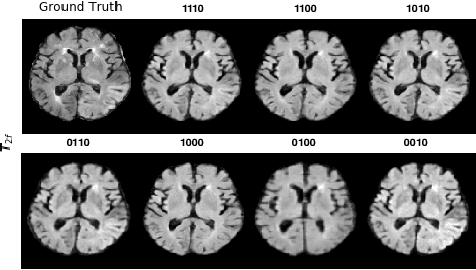
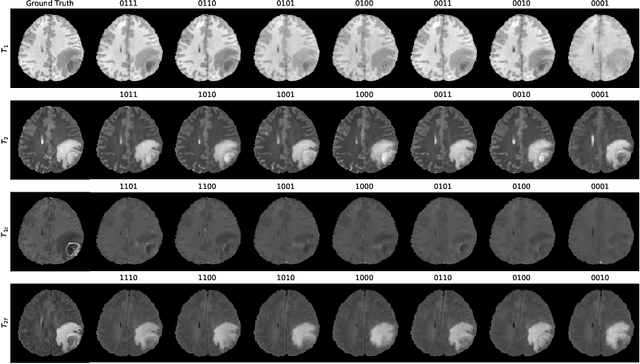
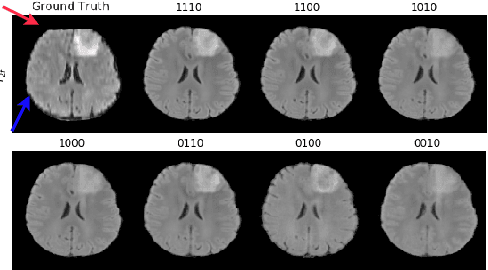
Magnetic resonance imaging (MRI) is being increasingly utilized to assess, diagnose, and plan treatment for a variety of diseases. The ability to visualize tissue in varied contrasts in the form of MR pulse sequences in a single scan provides valuable insights to physicians, as well as enabling automated systems performing downstream analysis. However many issues like prohibitive scan time, image corruption, different acquisition protocols, or allergies to certain contrast materials may hinder the process of acquiring multiple sequences for a patient. This poses challenges to both physicians and automated systems since complementary information provided by the missing sequences is lost. In this paper, we propose a variant of generative adversarial network (GAN) capable of leveraging redundant information contained within multiple available sequences in order to generate one or more missing sequences for a patient scan. The proposed network is designed as a multi-input, multi-output network which combines information from all the available pulse sequences, implicitly infers which sequences are missing, and synthesizes the missing ones in a single forward pass. We demonstrate and validate our method on two brain MRI datasets each with four sequences, and show the applicability of the proposed method in simultaneously synthesizing all missing sequences in any possible scenario where either one, two, or three of the four sequences may be missing. We compare our approach with competing unimodal and multi-modal methods, and show that we outperform both quantitatively and qualitatively.
A CADe System for Gliomas in Brain MRI using Convolutional Neural Networks
Jun 20, 2018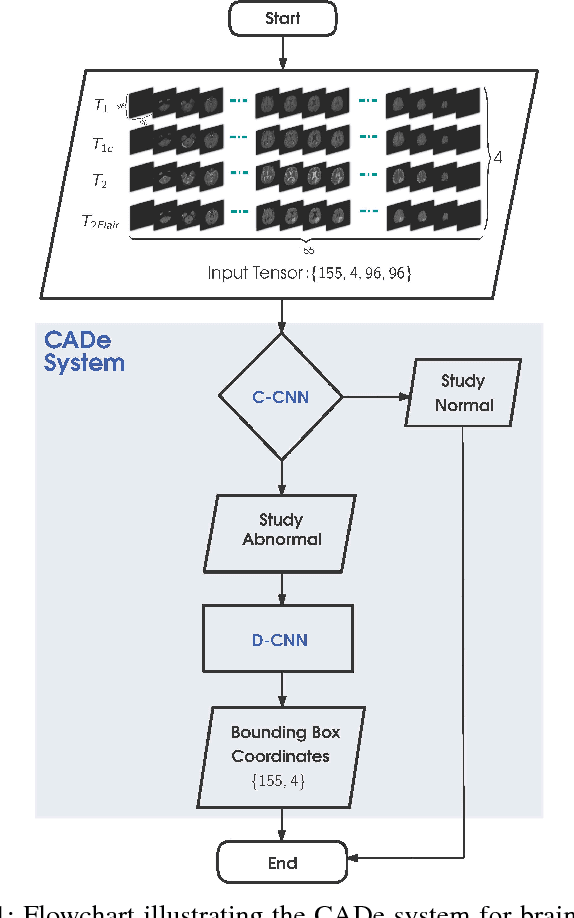
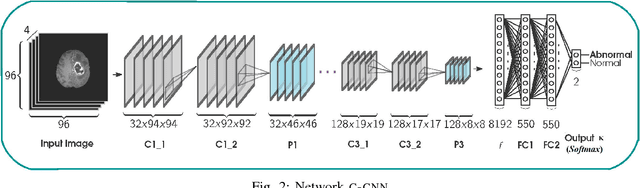
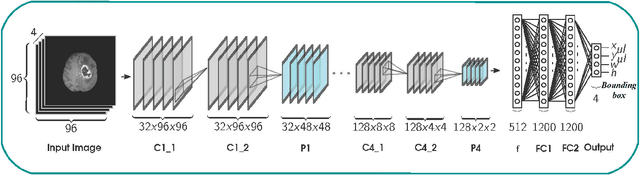
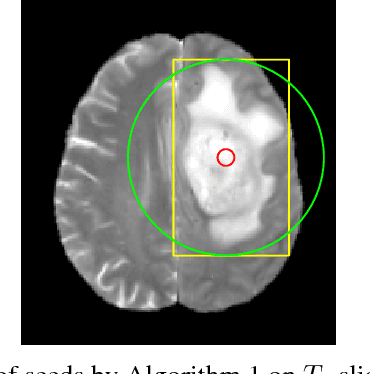
Inspired by the success of Convolutional Neural Networks (CNN), we develop a novel Computer Aided Detection (CADe) system using CNN for Glioblastoma Multiforme (GBM) detection and segmentation from multi channel MRI data. A two-stage approach first identifies the presence of GBM. This is followed by a GBM localization in each "abnormal" MR slice. As part of the CADe system, two CNN architectures viz. Classification CNN (C-CNN) and Detection CNN (D-CNN) are employed. The CADe system considers MRI data consisting of four sequences ($T_1$, $T_{1c},$ $T_2$, and $T_{2FLAIR}$) as input, and automatically generates the bounding boxes encompassing the tumor regions in each slice which is deemed abnormal. Experimental results demonstrate that the proposed CADe system, when used as a preliminary step before segmentation, can allow improved delineation of tumor region while reducing false positives arising in normal areas of the brain. The GrowCut method, employed for tumor segmentation, typically requires a foreground and background seed region for initialization. Here the algorithm is initialized with seeds automatically generated from the output of the proposed CADe system, thereby resulting in improved performance as compared to that using random seeds.
Select, Attend, and Transfer: Light, Learnable Skip Connections
May 03, 2018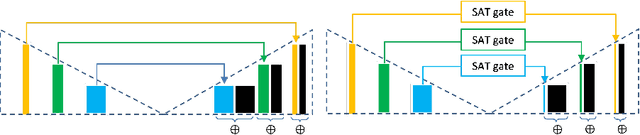
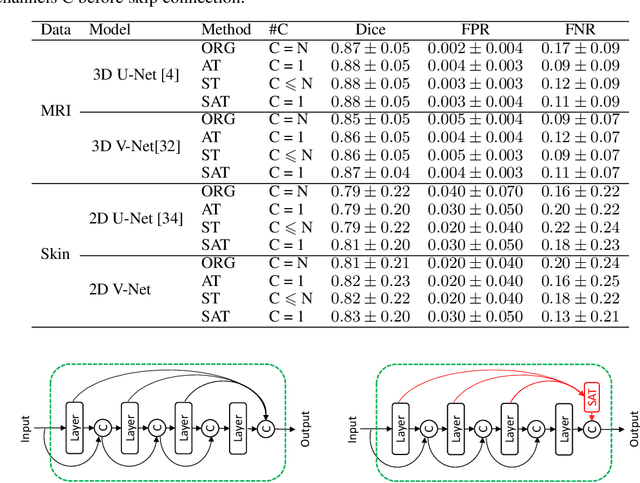
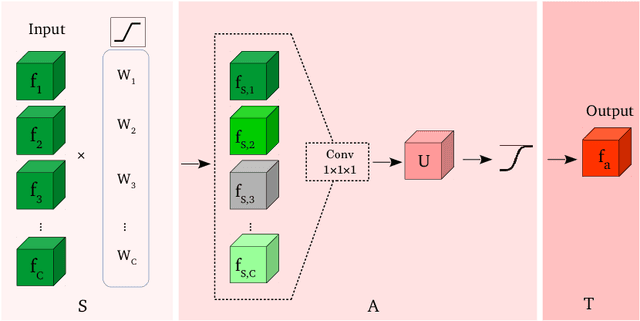
Skip connections in deep networks have improved both segmentation and classification performance by facilitating the training of deeper network architectures, and reducing the risks for vanishing gradients. They equip encoder-decoder-like networks with richer feature representations, but at the cost of higher memory usage, computation, and possibly resulting in transferring non-discriminative feature maps. In this paper, we focus on improving skip connections used in segmentation networks (e.g., U-Net, V-Net, and The One Hundred Layers Tiramisu (DensNet) architectures). We propose light, learnable skip connections which learn to first select the most discriminative channels and then attend to the most discriminative regions of the selected feature maps. The output of the proposed skip connections is a unique feature map which not only reduces the memory usage and network parameters to a high extent, but also improves segmentation accuracy. We evaluate the proposed method on three different 2D and volumetric datasets and demonstrate that the proposed light, learnable skip connections can outperform the traditional heavy skip connections in terms of segmentation accuracy, memory usage, and number of network parameters.