 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLEURT: Learning Robust Metrics for Text Generation
May 14, 2020
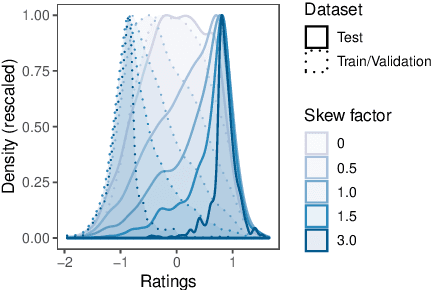
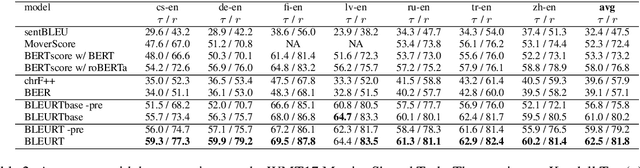
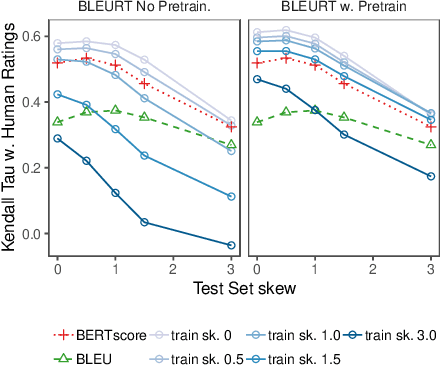
Text generation has made significant advances in the last few years. Yet, evaluation metrics have lagged behind, as the most popular choices (e.g., BLEU and ROUGE) may correlate poorly with human judgments. We propose BLEURT, a learned evaluation metric based on BERT that can model human judgments with a few thousand possibly biased training examples. A key aspect of our approach is a novel pre-training scheme that uses millions of synthetic examples to help the model generalize. BLEURT provides state-of-the-art results on the last three years of the WMT Metrics shared task and the WebNLG Competition dataset. In contrast to a vanilla BERT-based approach, it yields superior results even when the training data is scarce and out-of-distribution.
ToTTo: A Controlled Table-To-Text Generation Dataset
Apr 30, 2020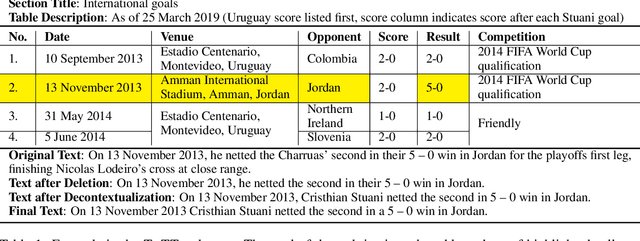

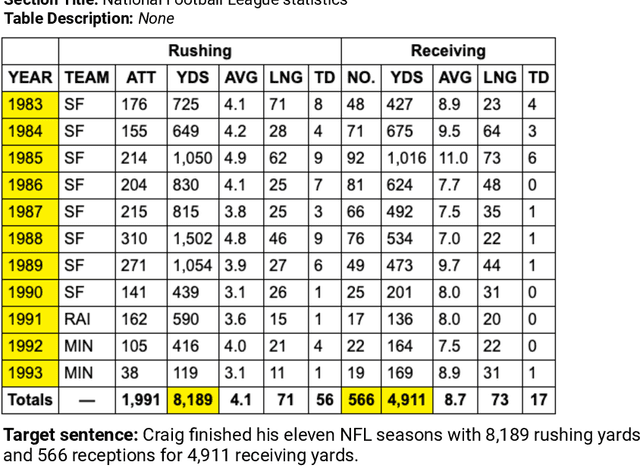
We present ToTTo, an open-domain English table-to-text dataset with over 120,000 training examples that proposes a controlled generation task: given a Wikipedia table and a set of highlighted table cells, produce a one-sentence description. To obtain generated targets that are natural but also faithful to the source table, we introduce a dataset construction process where annotators directly revise existing candidate sentences from Wikipedia. We present systematic analyses of our dataset and annotation process as well as results achieved by several state-of-the-art baselines. While usually fluent, existing methods often hallucinate phrases that are not supported by the table, suggesting that this dataset can serve as a useful research benchmark for high-precision conditional text generation.
A Multilingual View of Unsupervised Machine Translation
Feb 21, 2020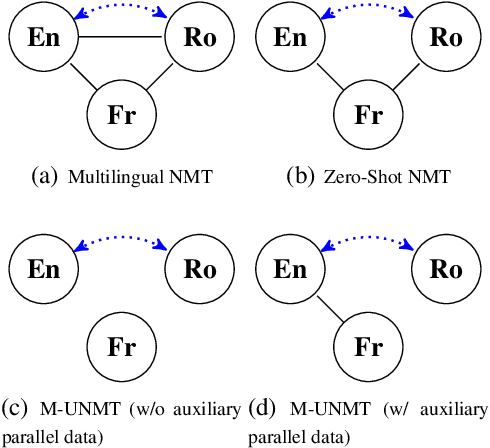
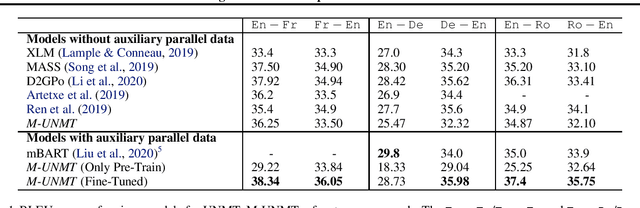
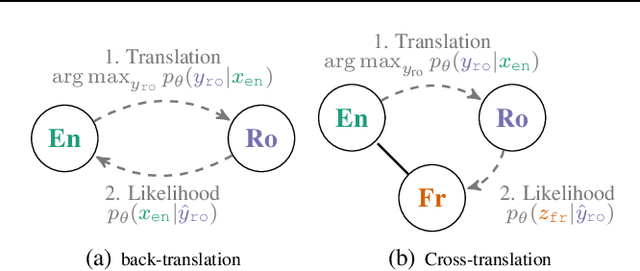
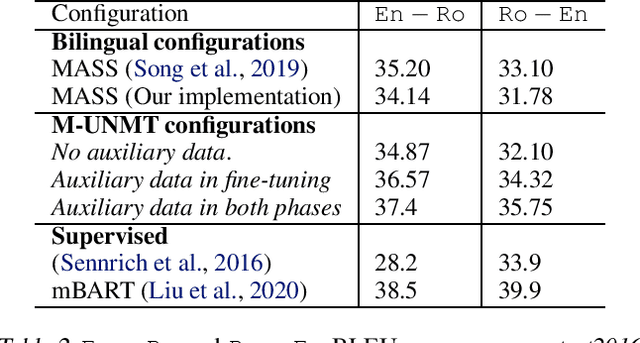
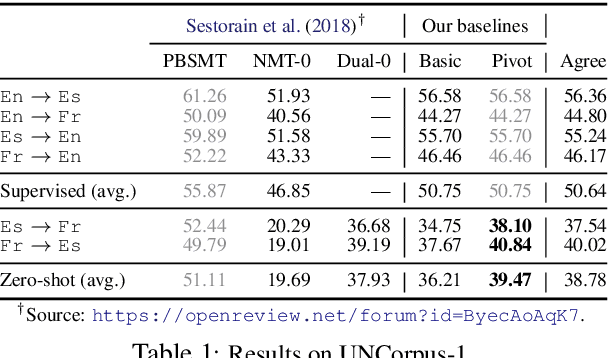
We present a probabilistic framework for multilingual neural machine translation that encompasses supervised and unsupervised setups, focusing on unsupervised translation. In addition to studying the vanilla case where there is only monolingual data available, we propose a novel setup where one language in the (source, target) pair is not associated with any parallel data, but there may exist auxiliary parallel data that contains the other. This auxiliary data can naturally be utilized in our probabilistic framework via a novel cross-translation loss term. Empirically, we show that our approach results in higher BLEU scores over state-of-the-art unsupervised models on the WMT'14 English-French, WMT'16 English-German, and WMT'16 English-Romanian datasets in most directions. In particular, we obtain a +1.65 BLEU advantage over the best-performing unsupervised model in the Romanian-English direction.
Sticking to the Facts: Confident Decoding for Faithful Data-to-Text Generation
Nov 15, 2019

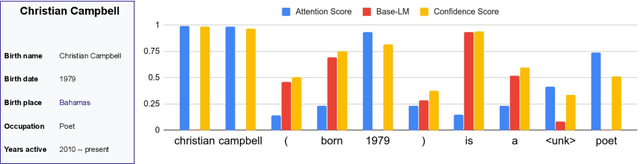
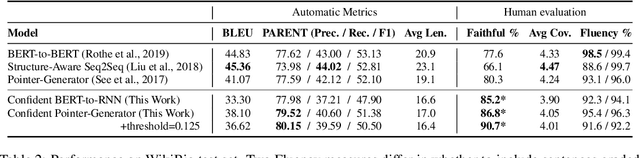
Neural conditional text generation systems have achieved significant progress in recent years, showing the ability to produce highly fluent text. However, the inherent lack of controllability in these systems allows them to hallucinate factually incorrect phrases that are unfaithful to the source, making them often unsuitable for many real world systems that require high degrees of precision. In this work, we propose a novel confidence oriented decoder that assigns a confidence score to each target position. This score is learned in training using a variational Bayes objective, and can be leveraged at inference time using a calibration technique to promote more faithful generation. Experiments on a structured data-to-text dataset -- WikiBio -- show that our approach is more faithful to the source than existing state-of-the-art approaches, according to both automatic metrics and human evaluation.
Thieves on Sesame Street! Model Extraction of BERT-based APIs
Oct 27, 2019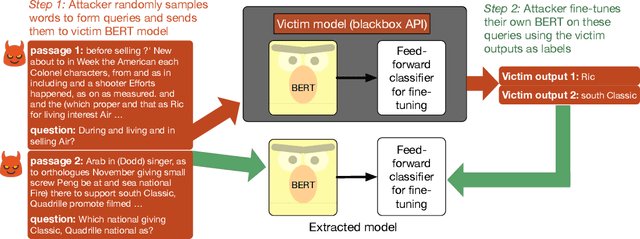

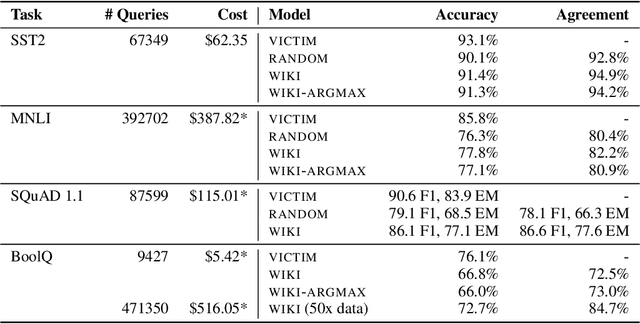
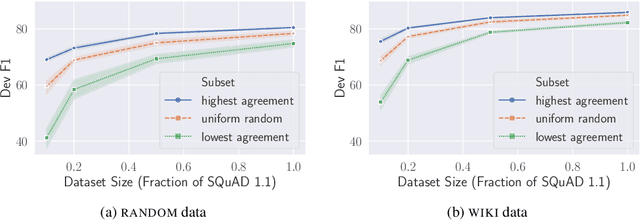
We study the problem of model extraction in natural language processing, in which an adversary with only query access to a victim model attempts to reconstruct a local copy of that model. Assuming that both the adversary and victim model fine-tune a large pretrained language model such as BERT (Devlin et al. 2019), we show that the adversary does not need any real training data to successfully mount the attack. In fact, the attacker need not even use grammatical or semantically meaningful queries: we show that random sequences of words coupled with task-specific heuristics form effective queries for model extraction on a diverse set of NLP tasks including natural language inference and question answering. Our work thus highlights an exploit only made feasible by the shift towards transfer learning methods within the NLP community: for a query budget of a few hundred dollars, an attacker can extract a model that performs only slightly worse than the victim model. Finally, we study two defense strategies against model extraction---membership classification and API watermarking---which while successful against naive adversaries, are ineffective against more sophisticated ones.
Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
Jun 14, 2019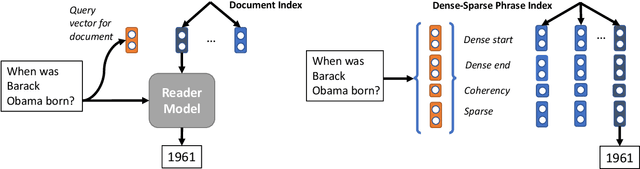
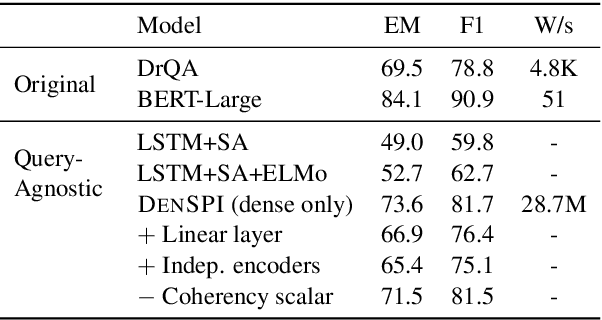
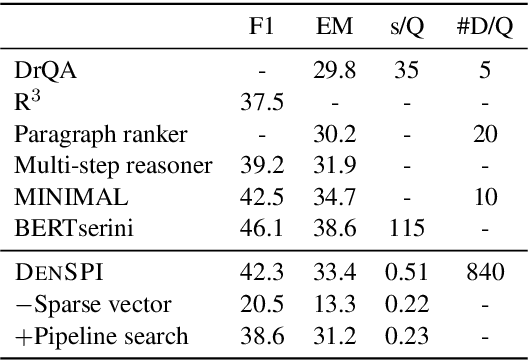

Existing open-domain question answering (QA) models are not suitable for real-time usage because they need to process several long documents on-demand for every input query. In this paper, we introduce the query-agnostic indexable representation of document phrases that can drastically speed up open-domain QA and also allows us to reach long-tail targets. In particular, our dense-sparse phrase encoding effectively captures syntactic, semantic, and lexical information of the phrases and eliminates the pipeline filtering of context documents. Leveraging optimization strategies, our model can be trained in a single 4-GPU server and serve entire Wikipedia (up to 60 billion phrases) under 2TB with CPUs only. Our experiments on SQuAD-Open show that our model is more accurate than DrQA (Chen et al., 2017) with 6000x reduced computational cost, which translates into at least 58x faster end-to-end inference benchmark on CPUs.
Text Generation with Exemplar-based Adaptive Decoding
Apr 10, 2019
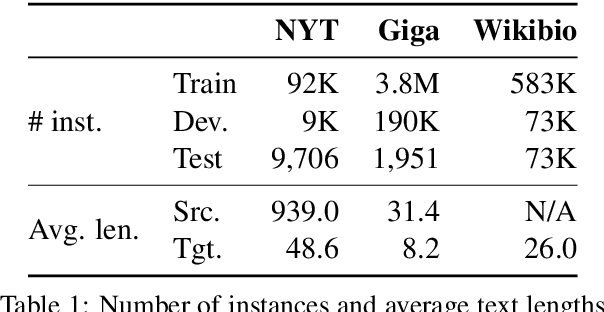
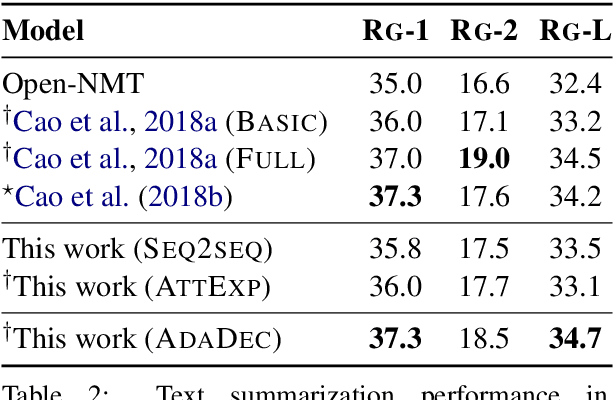
We propose a novel conditioned text generation model. It draws inspiration from traditional template-based text generation techniques, where the source provides the content (i.e., what to say), and the template influences how to say it. Building on the successful encoder-decoder paradigm, it first encodes the content representation from the given input text; to produce the output, it retrieves exemplar text from the training data as "soft templates," which are then used to construct an exemplar-specific decoder. We evaluate the proposed model on abstractive text summarization and data-to-text generation. Empirical results show that this model achieves strong performance and outperforms comparable baselines.
Consistency by Agreement in Zero-shot Neural Machine Translation
Apr 10, 2019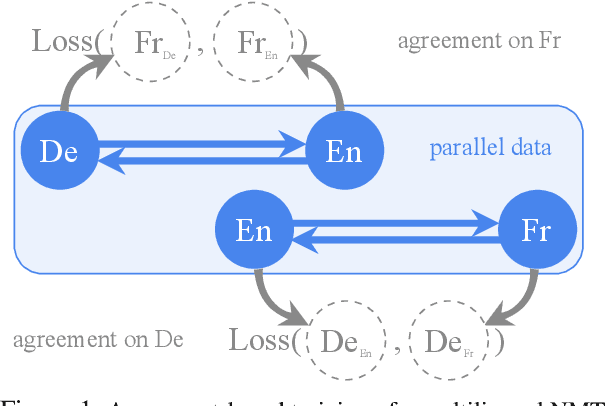
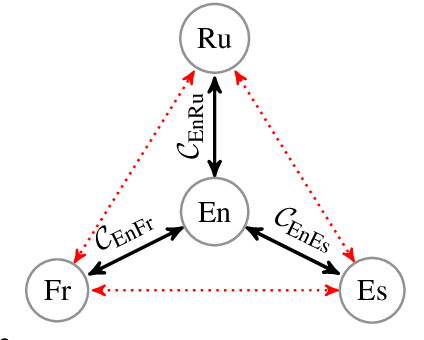
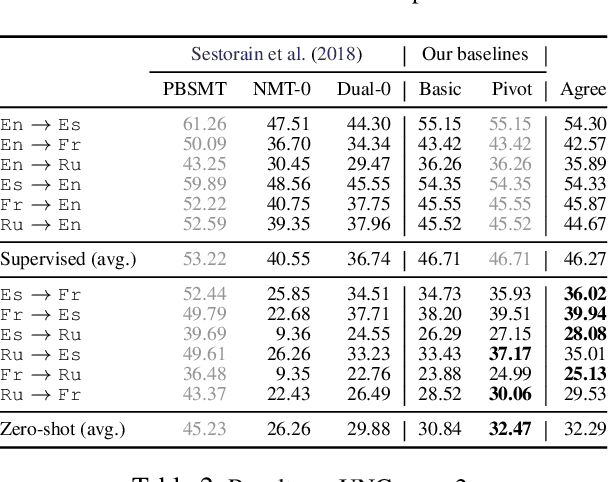
Generalization and reliability of multilingual translation often highly depend on the amount of available parallel data for each language pair of interest. In this paper, we focus on zero-shot generalization---a challenging setup that tests models on translation directions they have not been optimized for at training time. To solve the problem, we (i) reformulate multilingual translation as probabilistic inference, (ii) define the notion of zero-shot consistency and show why standard training often results in models unsuitable for zero-shot tasks, and (iii) introduce a consistent agreement-based training method that encourages the model to produce equivalent translations of parallel sentences in auxiliary languages. We test our multilingual NMT models on multiple public zero-shot translation benchmarks (IWSLT17, UN corpus, Europarl) and show that agreement-based learning often results in 2-3 BLEU zero-shot improvement over strong baselines without any loss in performance on supervised translation directions.
Phrase-Indexed Question Answering: A New Challenge for Scalable Document Comprehension
Sep 26, 2018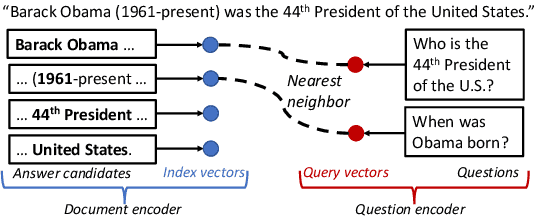
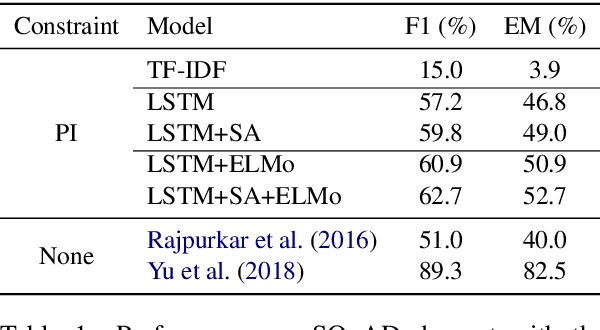

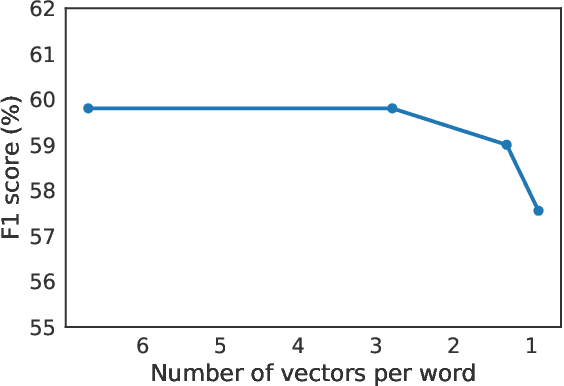
We formalize a new modular variant of current question answering tasks by enforcing complete independence of the document encoder from the question encoder. This formulation addresses a key challenge in machine comprehension by requiring a standalone representation of the document discourse. It additionally leads to a significant scalability advantage since the encoding of the answer candidate phrases in the document can be pre-computed and indexed offline for efficient retrieval. We experiment with baseline models for the new task, which achieve a reasonable accuracy but significantly underperform unconstrained QA models. We invite the QA research community to engage in Phrase-Indexed Question Answering (PIQA, pika) for closing the gap. The leaderboard is at: nlp.cs.washington.edu/piqa
Hybrid Subspace Learning for High-Dimensional Data
Aug 05, 2018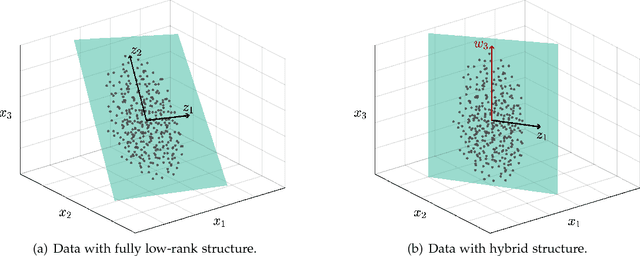
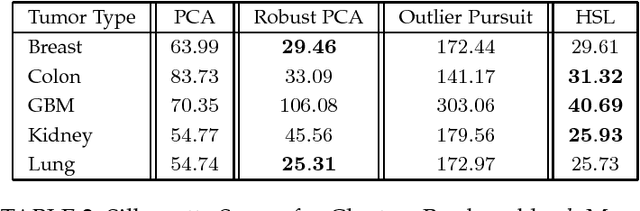
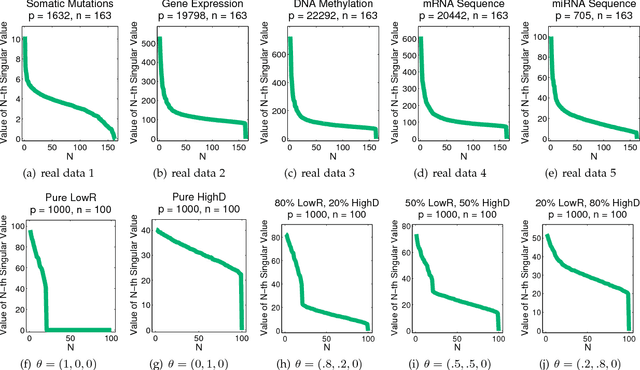
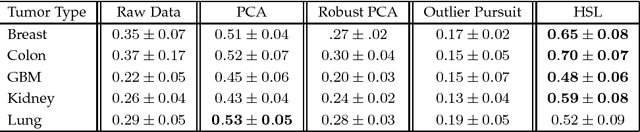
The high-dimensional data setting, in which p >> n, is a challenging statistical paradigm that appears in many real-world problems. In this setting, learning a compact, low-dimensional representation of the data can substantially help distinguish signal from noise. One way to achieve this goal is to perform subspace learning to estimate a small set of latent features that capture the majority of the variance in the original data. Most existing subspace learning models, such as PCA, assume that the data can be fully represented by its embedding in one or more latent subspaces. However, in this work, we argue that this assumption is not suitable for many high-dimensional datasets; often only some variables can easily be projected to a low-dimensional space. We propose a hybrid dimensionality reduction technique in which some features are mapped to a low-dimensional subspace while others remain in the original space. Our model leads to more accurate estimation of the latent space and lower reconstruction error. We present a simple optimization procedure for the resulting biconvex problem and show synthetic data results that demonstrate the advantages of our approach over existing methods. Finally, we demonstrate the effectiveness of this method for extracting meaningful features from both gene expression and video background subtraction datasets.