 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessage-passing algorithms for synchronization problems over compact groups
Oct 14, 2016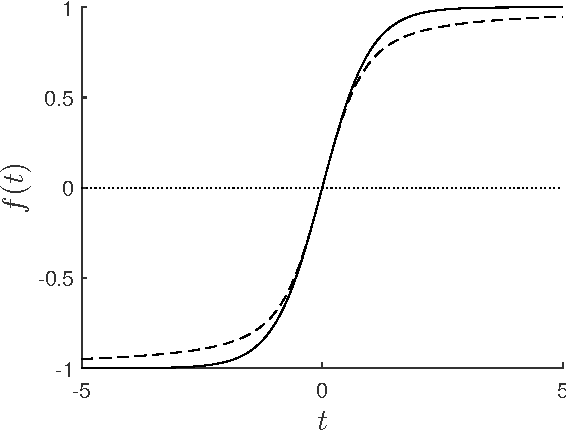
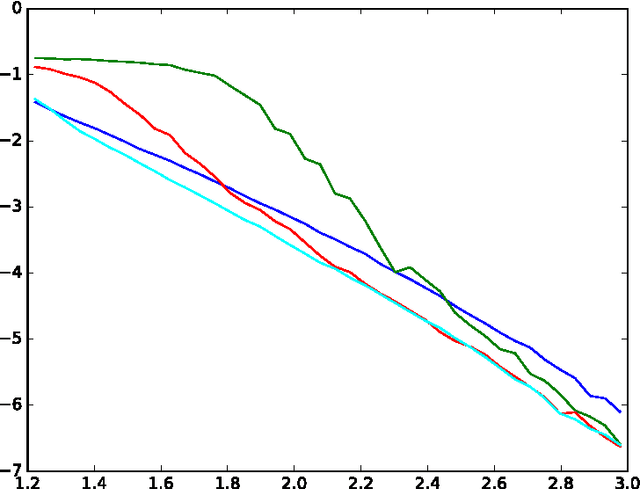
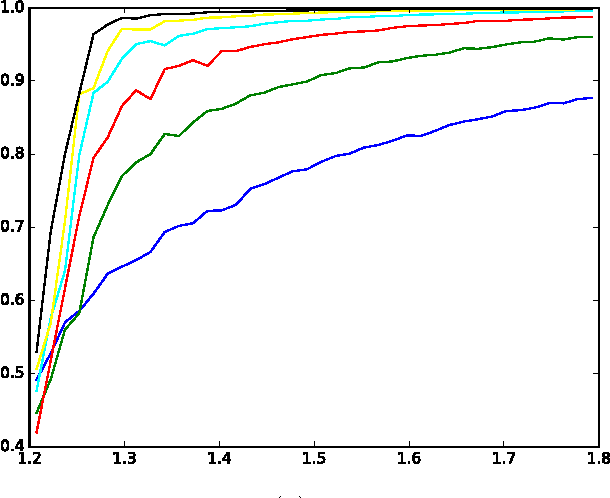
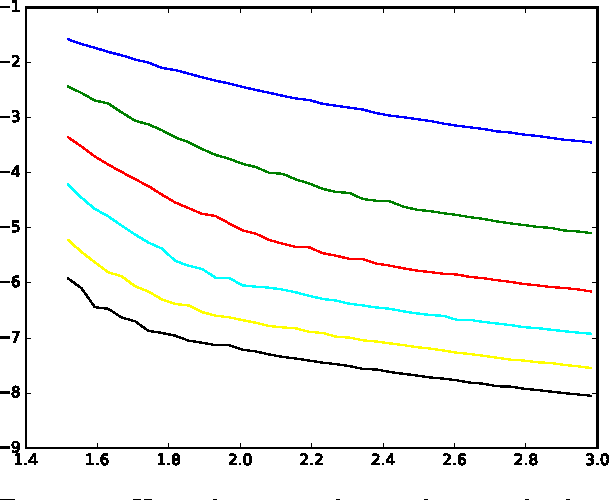
Various alignment problems arising in cryo-electron microscopy, community detection, time synchronization, computer vision, and other fields fall into a common framework of synchronization problems over compact groups such as Z/L, U(1), or SO(3). The goal of such problems is to estimate an unknown vector of group elements given noisy relative observations. We present an efficient iterative algorithm to solve a large class of these problems, allowing for any compact group, with measurements on multiple 'frequency channels' (Fourier modes, or more generally, irreducible representations of the group). Our algorithm is a highly efficient iterative method following the blueprint of approximate message passing (AMP), which has recently arisen as a central technique for inference problems such as structured low-rank estimation and compressed sensing. We augment the standard ideas of AMP with ideas from representation theory so that the algorithm can work with distributions over compact groups. Using standard but non-rigorous methods from statistical physics we analyze the behavior of our algorithm on a Gaussian noise model, identifying phases where the problem is easy, (computationally) hard, and (statistically) impossible. In particular, such evidence predicts that our algorithm is information-theoretically optimal in many cases, and that the remaining cases show evidence of statistical-to-computational gaps.
Provable Algorithms for Inference in Topic Models
May 27, 2016
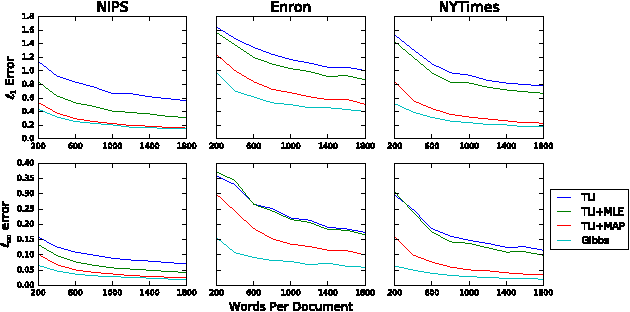
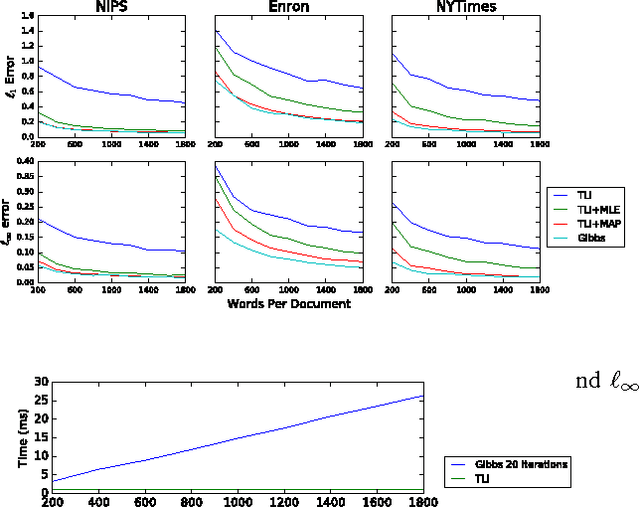
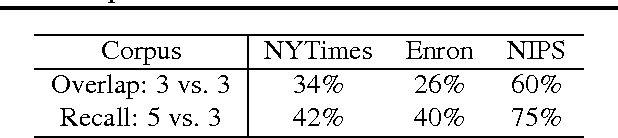
Recently, there has been considerable progress on designing algorithms with provable guarantees -- typically using linear algebraic methods -- for parameter learning in latent variable models. But designing provable algorithms for inference has proven to be more challenging. Here we take a first step towards provable inference in topic models. We leverage a property of topic models that enables us to construct simple linear estimators for the unknown topic proportions that have small variance, and consequently can work with short documents. Our estimators also correspond to finding an estimate around which the posterior is well-concentrated. We show lower bounds that for shorter documents it can be information theoretically impossible to find the hidden topics. Finally, we give empirical results that demonstrate that our algorithm works on realistic topic models. It yields good solutions on synthetic data and runs in time comparable to a {\em single} iteration of Gibbs sampling.
Robust Estimators in High Dimensions without the Computational Intractability
Apr 21, 2016We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.
How Robust are Reconstruction Thresholds for Community Detection?
Mar 21, 2016The stochastic block model is one of the oldest and most ubiquitous models for studying clustering and community detection. In an exciting sequence of developments, motivated by deep but non-rigorous ideas from statistical physics, Decelle et al. conjectured a sharp threshold for when community detection is possible in the sparse regime. Mossel, Neeman and Sly and Massoulie proved the conjecture and gave matching algorithms and lower bounds. Here we revisit the stochastic block model from the perspective of semirandom models where we allow an adversary to make `helpful' changes that strengthen ties within each community and break ties between them. We show a surprising result that these `helpful' changes can shift the information-theoretic threshold, making the community detection problem strictly harder. We complement this by showing that an algorithm based on semidefinite programming (which was known to get close to the threshold) continues to work in the semirandom model (even for partial recovery). This suggests that algorithms based on semidefinite programming are robust in ways that any algorithm meeting the information-theoretic threshold cannot be. These results point to an interesting new direction: Can we find robust, semirandom analogues to some of the classical, average-case thresholds in statistics? We also explore this question in the broadcast tree model, and we show that the viewpoint of semirandom models can help explain why some algorithms are preferred to others in practice, in spite of the gaps in their statistical performance on random models.
Noisy Tensor Completion via the Sum-of-Squares Hierarchy
Feb 18, 2016In the noisy tensor completion problem we observe $m$ entries (whose location is chosen uniformly at random) from an unknown $n_1 \times n_2 \times n_3$ tensor $T$. We assume that $T$ is entry-wise close to being rank $r$. Our goal is to fill in its missing entries using as few observations as possible. Let $n = \max(n_1, n_2, n_3)$. We show that if $m = n^{3/2} r$ then there is a polynomial time algorithm based on the sixth level of the sum-of-squares hierarchy for completing it. Our estimate agrees with almost all of $T$'s entries almost exactly and works even when our observations are corrupted by noise. This is also the first algorithm for tensor completion that works in the overcomplete case when $r > n$, and in fact it works all the way up to $r = n^{3/2-\epsilon}$. Our proofs are short and simple and are based on establishing a new connection between noisy tensor completion (through the language of Rademacher complexity) and the task of refuting random constant satisfaction problems. This connection seems to have gone unnoticed even in the context of matrix completion. Furthermore, we use this connection to show matching lower bounds. Our main technical result is in characterizing the Rademacher complexity of the sequence of norms that arise in the sum-of-squares relaxations to the tensor nuclear norm. These results point to an interesting new direction: Can we explore computational vs. sample complexity tradeoffs through the sum-of-squares hierarchy?
Simple, Efficient, and Neural Algorithms for Sparse Coding
Mar 02, 2015
Sparse coding is a basic task in many fields including signal processing, neuroscience and machine learning where the goal is to learn a basis that enables a sparse representation of a given set of data, if one exists. Its standard formulation is as a non-convex optimization problem which is solved in practice by heuristics based on alternating minimization. Re- cent work has resulted in several algorithms for sparse coding with provable guarantees, but somewhat surprisingly these are outperformed by the simple alternating minimization heuristics. Here we give a general framework for understanding alternating minimization which we leverage to analyze existing heuristics and to design new ones also with provable guarantees. Some of these algorithms seem implementable on simple neural architectures, which was the original motivation of Olshausen and Field (1997a) in introducing sparse coding. We also give the first efficient algorithm for sparse coding that works almost up to the information theoretic limit for sparse recovery on incoherent dictionaries. All previous algorithms that approached or surpassed this limit run in time exponential in some natural parameter. Finally, our algorithms improve upon the sample complexity of existing approaches. We believe that our analysis framework will have applications in other settings where simple iterative algorithms are used.
New Algorithms for Learning Incoherent and Overcomplete Dictionaries
May 26, 2014In sparse recovery we are given a matrix $A$ (the dictionary) and a vector of the form $A X$ where $X$ is sparse, and the goal is to recover $X$. This is a central notion in signal processing, statistics and machine learning. But in applications such as sparse coding, edge detection, compression and super resolution, the dictionary $A$ is unknown and has to be learned from random examples of the form $Y = AX$ where $X$ is drawn from an appropriate distribution --- this is the dictionary learning problem. In most settings, $A$ is overcomplete: it has more columns than rows. This paper presents a polynomial-time algorithm for learning overcomplete dictionaries; the only previously known algorithm with provable guarantees is the recent work of Spielman, Wang and Wright who gave an algorithm for the full-rank case, which is rarely the case in applications. Our algorithm applies to incoherent dictionaries which have been a central object of study since they were introduced in seminal work of Donoho and Huo. In particular, a dictionary is $\mu$-incoherent if each pair of columns has inner product at most $\mu / \sqrt{n}$. The algorithm makes natural stochastic assumptions about the unknown sparse vector $X$, which can contain $k \leq c \min(\sqrt{n}/\mu \log n, m^{1/2 -\eta})$ non-zero entries (for any $\eta > 0$). This is close to the best $k$ allowable by the best sparse recovery algorithms even if one knows the dictionary $A$ exactly. Moreover, both the running time and sample complexity depend on $\log 1/\epsilon$, where $\epsilon$ is the target accuracy, and so our algorithms converge very quickly to the true dictionary. Our algorithm can also tolerate substantial amounts of noise provided it is incoherent with respect to the dictionary (e.g., Gaussian). In the noisy setting, our running time and sample complexity depend polynomially on $1/\epsilon$, and this is necessary.
Smoothed Analysis of Tensor Decompositions
Jan 20, 2014Low rank tensor decompositions are a powerful tool for learning generative models, and uniqueness results give them a significant advantage over matrix decomposition methods. However, tensors pose significant algorithmic challenges and tensors analogs of much of the matrix algebra toolkit are unlikely to exist because of hardness results. Efficient decomposition in the overcomplete case (where rank exceeds dimension) is particularly challenging. We introduce a smoothed analysis model for studying these questions and develop an efficient algorithm for tensor decomposition in the highly overcomplete case (rank polynomial in the dimension). In this setting, we show that our algorithm is robust to inverse polynomial error -- a crucial property for applications in learning since we are only allowed a polynomial number of samples. While algorithms are known for exact tensor decomposition in some overcomplete settings, our main contribution is in analyzing their stability in the framework of smoothed analysis. Our main technical contribution is to show that tensor products of perturbed vectors are linearly independent in a robust sense (i.e. the associated matrix has singular values that are at least an inverse polynomial). This key result paves the way for applying tensor methods to learning problems in the smoothed setting. In particular, we use it to obtain results for learning multi-view models and mixtures of axis-aligned Gaussians where there are many more "components" than dimensions. The assumption here is that the model is not adversarially chosen, formalized by a perturbation of model parameters. We believe this an appealing way to analyze realistic instances of learning problems, since this framework allows us to overcome many of the usual limitations of using tensor methods.
Algorithms and Hardness for Robust Subspace Recovery
Dec 03, 2013We consider a fundamental problem in unsupervised learning called \emph{subspace recovery}: given a collection of $m$ points in $\mathbb{R}^n$, if many but not necessarily all of these points are contained in a $d$-dimensional subspace $T$ can we find it? The points contained in $T$ are called {\em inliers} and the remaining points are {\em outliers}. This problem has received considerable attention in computer science and in statistics. Yet efficient algorithms from computer science are not robust to {\em adversarial} outliers, and the estimators from robust statistics are hard to compute in high dimensions. Are there algorithms for subspace recovery that are both robust to outliers and efficient? We give an algorithm that finds $T$ when it contains more than a $\frac{d}{n}$ fraction of the points. Hence, for say $d = n/2$ this estimator is both easy to compute and well-behaved when there are a constant fraction of outliers. We prove that it is Small Set Expansion hard to find $T$ when the fraction of errors is any larger, thus giving evidence that our estimator is an {\em optimal} compromise between efficiency and robustness. As it turns out, this basic problem has a surprising number of connections to other areas including small set expansion, matroid theory and functional analysis that we make use of here.
A Polynomial Time Algorithm for Lossy Population Recovery
Jul 10, 2013We give a polynomial time algorithm for the lossy population recovery problem. In this problem, the goal is to approximately learn an unknown distribution on binary strings of length $n$ from lossy samples: for some parameter $\mu$ each coordinate of the sample is preserved with probability $\mu$ and otherwise is replaced by a `?'. The running time and number of samples needed for our algorithm is polynomial in $n$ and $1/\varepsilon$ for each fixed $\mu>0$. This improves on algorithm of Wigderson and Yehudayoff that runs in quasi-polynomial time for any $\mu > 0$ and the polynomial time algorithm of Dvir et al which was shown to work for $\mu \gtrapprox 0.30$ by Batman et al. In fact, our algorithm also works in the more general framework of Batman et al. in which there is no a priori bound on the size of the support of the distribution. The algorithm we analyze is implicit in previous work; our main contribution is to analyze the algorithm by showing (via linear programming duality and connections to complex analysis) that a certain matrix associated with the problem has a robust local inverse even though its condition number is exponentially small. A corollary of our result is the first polynomial time algorithm for learning DNFs in the restriction access model of Dvir et al.