 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data
Aug 16, 2023



Advances in large language models (LLMs) have empowered a variety of applications. However, there is still a significant gap in research when it comes to understanding and enhancing the capabilities of LLMs in the field of mental health. In this work, we present the first comprehensive evaluation of multiple LLMs, including Alpaca, Alpaca-LoRA, FLAN-T5, GPT-3.5, and GPT-4, on various mental health prediction tasks via online text data. We conduct a broad range of experiments, covering zero-shot prompting, few-shot prompting, and instruction fine-tuning. The results indicate a promising yet limited performance of LLMs with zero-shot and few-shot prompt designs for the mental health tasks. More importantly, our experiments show that instruction finetuning can significantly boost the performance of LLMs for all tasks simultaneously. Our best-finetuned models, Mental-Alpaca and Mental-FLAN-T5, outperform the best prompt design of GPT-3.5 (25 and 15 times bigger) by 10.9% on balanced accuracy and the best of GPT-4 (250 and 150 times bigger) by 4.8%. They further perform on par with the state-of-the-art task-specific language model. We also conduct an exploratory case study on LLMs' capability on the mental health reasoning tasks, illustrating the promising capability of certain models such as GPT-4. We summarize our findings into a set of action guidelines for potential methods to enhance LLMs' capability for mental health tasks. Meanwhile, we also emphasize the important limitations before achieving deployability in real-world mental health settings, such as known racial and gender bias. We highlight the important ethical risks accompanying this line of research.
GLOBEM Dataset: Multi-Year Datasets for Longitudinal Human Behavior Modeling Generalization
Nov 04, 2022Recent research has demonstrated the capability of behavior signals captured by smartphones and wearables for longitudinal behavior modeling. However, there is a lack of a comprehensive public dataset that serves as an open testbed for fair comparison among algorithms. Moreover, prior studies mainly evaluate algorithms using data from a single population within a short period, without measuring the cross-dataset generalizability of these algorithms. We present the first multi-year passive sensing datasets, containing over 700 user-years and 497 unique users' data collected from mobile and wearable sensors, together with a wide range of well-being metrics. Our datasets can support multiple cross-dataset evaluations of behavior modeling algorithms' generalizability across different users and years. As a starting point, we provide the benchmark results of 18 algorithms on the task of depression detection. Our results indicate that both prior depression detection algorithms and domain generalization techniques show potential but need further research to achieve adequate cross-dataset generalizability. We envision our multi-year datasets can support the ML community in developing generalizable longitudinal behavior modeling algorithms.
Can Smartphone Co-locations Detect Friendship? It Depends How You Model It
Aug 31, 2020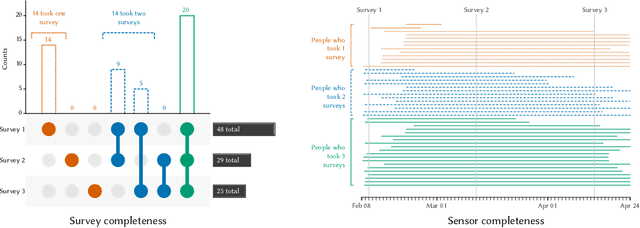
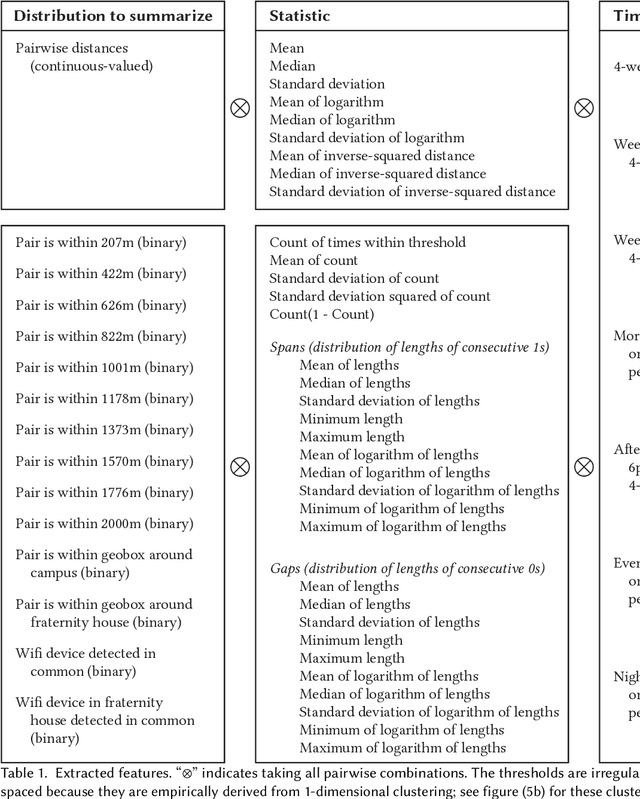
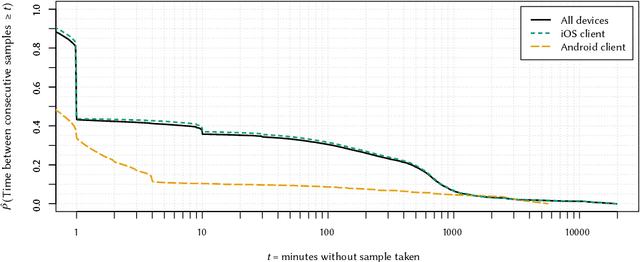
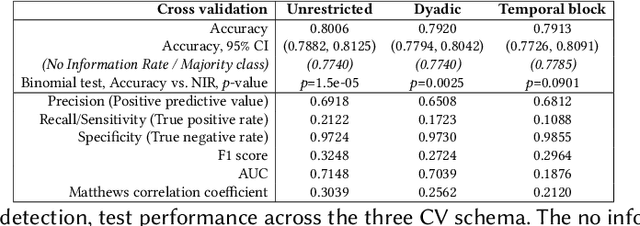
We present a study to detect friendship, its strength, and its change from smartphone location data collectedamong members of a fraternity. We extract a rich set of co-location features and build classifiers that detectfriendships and close friendship at 30% above a random baseline. We design cross-validation schema to testour model performance in specific application settings, finding it robust to seeing new dyads and to temporalvariance.
Extraction of Behavioral Features from Smartphone and Wearable Data
Jan 09, 2019The rich set of sensors in smartphones and wearable devices provides the possibility to passively collect streams of data in the wild. The raw data streams, however, can rarely be directly used in the modeling pipeline. We provide a generic framework that can process raw data streams and extract useful features related to non-verbal human behavior. This framework can be used by researchers in the field who are interested in processing data from smartphones and Wearable devices.
Learning Selectively Conditioned Forest Structures with Applications to DBNs and Classification
Jun 20, 2012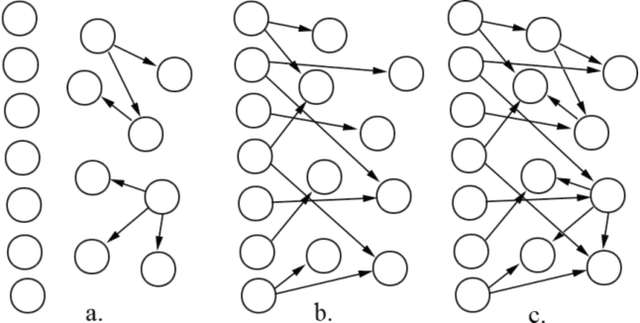
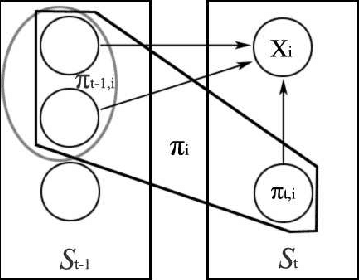
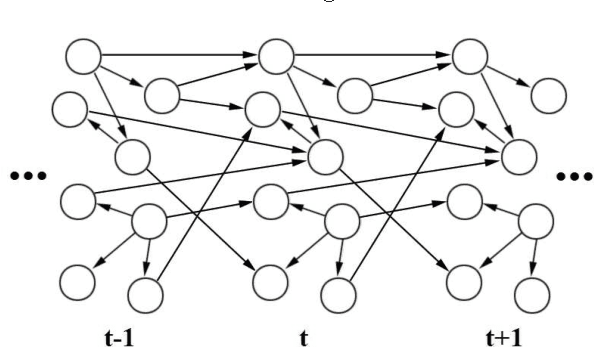
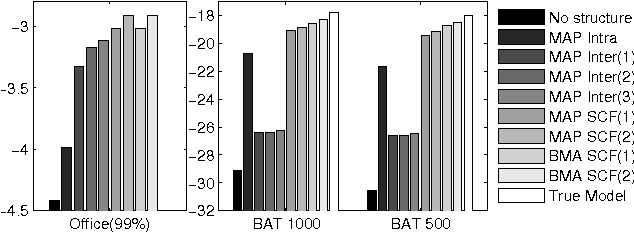
Dealing with uncertainty in Bayesian Network structures using maximum a posteriori (MAP) estimation or Bayesian Model Averaging (BMA) is often intractable due to the superexponential number of possible directed, acyclic graphs. When the prior is decomposable, two classes of graphs where efficient learning can take place are tree structures, and fixed-orderings with limited in-degree. We show how MAP estimates and BMA for selectively conditioned forests (SCF), a combination of these two classes, can be computed efficiently for ordered sets of variables. We apply SCFs to temporal data to learn Dynamic Bayesian Networks having an intra-timestep forest and inter-timestep limited in-degree structure, improving model accuracy over DBNs without the combination of structures. We also apply SCFs to Bayes Net classification to learn selective forest augmented Naive Bayes classifiers. We argue that the built-in feature selection of selective augmented Bayes classifiers makes them preferable to similar non-selective classifiers based on empirical evidence.