 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbe-Geometry Alignment: Erasing the Cross-Sequence Memorization Signature Below Chance
May 06, 2026Recent attacks show that behavioural unlearning of large language models leaves internal traces recoverable by adversarial probes. We characterise where this retention lives and show it can be surgically removed without measurable capability cost. Our central protocol is a leave-one-out cross-sequence probe that tests whether a memorisation signature generalises across held-out sequences. The signature is real and consistent across scale: memorisation-specific gaps of +0.32, +0.19, +0.30 on Pythia-70M, GPT-2 medium, and Mistral-7B; on Pythia-70M, the random-initialisation control collapses to -0.04 at the deepest layer where the pretrained signature peaks. The probe direction is causally separable from recall -- projecting it out collapses the signature locally (+0.44 -> -0.19) while behavioural recall barely changes -- and a probe trained on naturally memorised content does not classify fine-tuning-injected secrets, marking two representationally distinct regimes. We then introduce probe-geometry alignment (PGA), a surgical erasure that aligns activations along the probe's live readout direction at each depth. PGA drives the cross-sequence probe below random chance at all four scales tested (toy depth-4: 0.17; Pythia-70M: 0.07; Mistral-7B: 0.45; GPT-2 medium: 0.06 via MD-PGA k=2) and remains robust to six adversarial probe variants. Against a re-fitting attacker who trains a fresh probe on PGA-treated activations, we extend PGA adversarially, defeating the re-fit probe at every memorisation-relevant depth while preserving five zero-shot capability benchmarks within 2.8 percentage points per task (mean Δacc = +0.2pp). The cross-sequence signature is a real, causally separable, regime-specific property of pretrained representations -- removable below chance with a single rank-one intervention per depth at no measurable capability cost.
An Empirical Study of Many-Shot In-Context Learning for Machine Translation of Low-Resource Languages
Apr 03, 2026In-context learning (ICL) allows large language models (LLMs) to adapt to new tasks from a few examples, making it promising for languages underrepresented in pre-training. Recent work on many-shot ICL suggests that modern LLMs can further benefit from larger ICL examples enabled by their long context windows. However, such gains depend on careful example selection, and the inference cost can be prohibitive for low-resource language communities. In this paper, we present an empirical study of many-shot ICL for machine translation from English into ten truly low-resource languages recently added to FLORES+. We analyze the effects of retrieving more informative examples, using out-of-domain data, and ordering examples by length. Our findings show that many-shot ICL becomes more effective as the number of examples increases. More importantly, we show that BM25-based retrieval substantially improves data efficiency: 50 retrieved examples roughly match 250 many-shot examples, while 250 retrieved examples perform similarly to 1,000 many-shot examples.
Ibom NLP: A Step Toward Inclusive Natural Language Processing for Nigeria's Minority Languages
Nov 09, 2025Nigeria is the most populous country in Africa with a population of more than 200 million people. More than 500 languages are spoken in Nigeria and it is one of the most linguistically diverse countries in the world. Despite this, natural language processing (NLP) research has mostly focused on the following four languages: Hausa, Igbo, Nigerian-Pidgin, and Yoruba (i.e <1% of the languages spoken in Nigeria). This is in part due to the unavailability of textual data in these languages to train and apply NLP algorithms. In this work, we introduce ibom -- a dataset for machine translation and topic classification in four Coastal Nigerian languages from the Akwa Ibom State region: Anaang, Efik, Ibibio, and Oro. These languages are not represented in Google Translate or in major benchmarks such as Flores-200 or SIB-200. We focus on extending Flores-200 benchmark to these languages, and further align the translated texts with topic labels based on SIB-200 classification dataset. Our evaluation shows that current LLMs perform poorly on machine translation for these languages in both zero-and-few shot settings. However, we find the few-shot samples to steadily improve topic classification with more shots.
BiSparse-AAS: Bilinear Sparse Attention and Adaptive Spans Framework for Scalable and Efficient Text Summarization
Oct 31, 2025Transformer-based architectures have advanced text summarization, yet their quadratic complexity limits scalability on long documents. This paper introduces BiSparse-AAS (Bilinear Sparse Attention with Adaptive Spans), a novel framework that combines sparse attention, adaptive spans, and bilinear attention to address these limitations. Sparse attention reduces computational costs by focusing on the most relevant parts of the input, while adaptive spans dynamically adjust the attention ranges. Bilinear attention complements both by modeling complex token interactions within this refined context. BiSparse-AAS consistently outperforms state-of-the-art baselines in both extractive and abstractive summarization tasks, achieving average ROUGE improvements of about 68.1% on CNN/DailyMail and 52.6% on XSum, while maintaining strong performance on OpenWebText and Gigaword datasets. By addressing efficiency, scalability, and long-sequence modeling, BiSparse-AAS provides a unified, practical solution for real-world text summarization applications.
Mitigating Translationese in Low-resource Languages: The Storyboard Approach
Jul 14, 2024Low-resource languages often face challenges in acquiring high-quality language data due to the reliance on translation-based methods, which can introduce the translationese effect. This phenomenon results in translated sentences that lack fluency and naturalness in the target language. In this paper, we propose a novel approach for data collection by leveraging storyboards to elicit more fluent and natural sentences. Our method involves presenting native speakers with visual stimuli in the form of storyboards and collecting their descriptions without direct exposure to the source text. We conducted a comprehensive evaluation comparing our storyboard-based approach with traditional text translation-based methods in terms of accuracy and fluency. Human annotators and quantitative metrics were used to assess translation quality. The results indicate a preference for text translation in terms of accuracy, while our method demonstrates worse accuracy but better fluency in the language focused.
* published at LREC-COLING 2024
Creating Multimedia Summaries Using Tweets and Videos
Mar 16, 2022

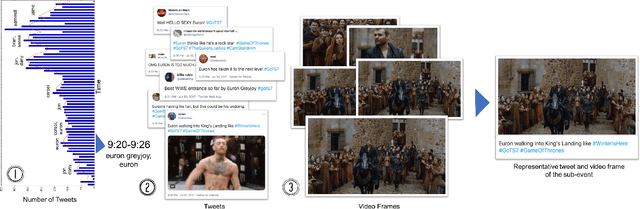
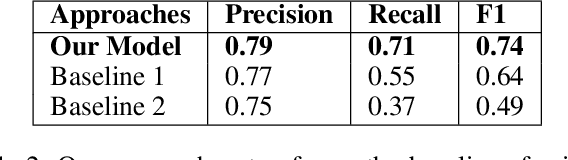
While popular televised events such as presidential debates or TV shows are airing, people provide commentary on them in real-time. In this paper, we propose a simple yet effective approach to combine social media commentary and videos to create a multimedia summary of televised events. Our approach identifies scenes from these events based on spikes of mentions of people involved in the event and automatically selects tweets and frames from the videos that occur during the time period of the spike that talk about and show the people being discussed.
Does Social Support Expressed in Post Titles Elicit Comments in Online Substance Use Recovery Forums?
Nov 10, 2020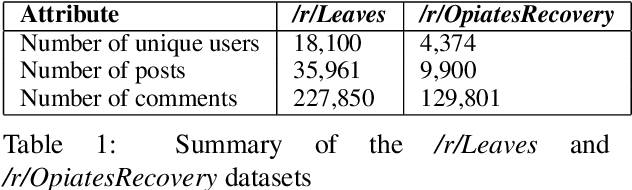
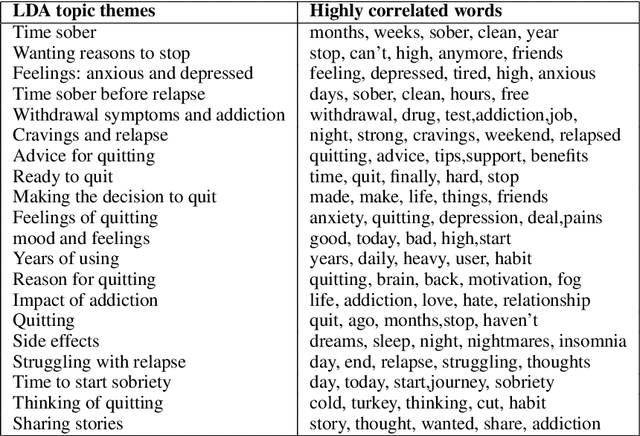

Individuals recovering from substance use often seek social support (emotional and informational) on online recovery forums, where they can both write and comment on posts, expressing their struggles and successes. A common challenge in these forums is that certain posts (some of which may be support seeking) receive no comments. In this work, we use data from two Reddit substance recovery forums:/r/Leaves and/r/OpiatesRecovery, to determine the relationship between the social supports expressed in the titles of posts and the number of comments they receive. We show that the types of social support expressed in post titles that elicit comments vary from one substance use recovery forum to the other.