 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization
Feb 23, 2023



Effective figure captions are crucial for clear comprehension of scientific figures, yet poor caption writing remains a common issue in scientific articles. Our study of arXiv cs.CL papers found that 53.88% of captions were rated as unhelpful or worse by domain experts, showing the need for better caption generation. Previous efforts in figure caption generation treated it as a vision task, aimed at creating a model to understand visual content and complex contextual information. Our findings, however, demonstrate that over 75% of figure captions' tokens align with corresponding figure-mentioning paragraphs, indicating great potential for language technology to solve this task. In this paper, we present a novel approach for generating figure captions in scientific documents using text summarization techniques. Our approach extracts sentences referencing the target figure, then summarizes them into a concise caption. In the experiments on real-world arXiv papers (81.2% were published at academic conferences), our method, using only text data, outperformed previous approaches in both automatic and human evaluations. We further conducted data-driven investigations into the two core challenges: (i) low-quality author-written captions and (ii) the absence of a standard for good captions. We found that our models could generate improved captions for figures with original captions rated as unhelpful, and the model trained on captions with more than 30 tokens produced higher-quality captions. We also found that good captions often include the high-level takeaway of the figure. Our work proves the effectiveness of text summarization in generating figure captions for scholarly articles, outperforming prior vision-based approaches. Our findings have practical implications for future figure captioning systems, improving scientific communication clarity.
MGDoc: Pre-training with Multi-granular Hierarchy for Document Image Understanding
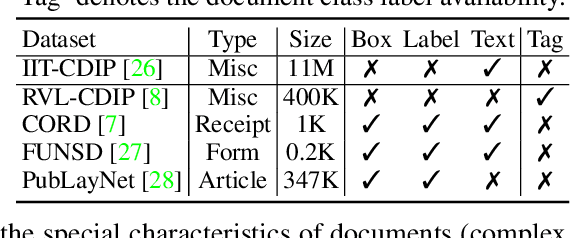
Nov 27, 2022Document images are a ubiquitous source of data where the text is organized in a complex hierarchical structure ranging from fine granularity (e.g., words), medium granularity (e.g., regions such as paragraphs or figures), to coarse granularity (e.g., the whole page). The spatial hierarchical relationships between content at different levels of granularity are crucial for document image understanding tasks. Existing methods learn features from either word-level or region-level but fail to consider both simultaneously. Word-level models are restricted by the fact that they originate from pure-text language models, which only encode the word-level context. In contrast, region-level models attempt to encode regions corresponding to paragraphs or text blocks into a single embedding, but they perform worse with additional word-level features. To deal with these issues, we propose MGDoc, a new multi-modal multi-granular pre-training framework that encodes page-level, region-level, and word-level information at the same time. MGDoc uses a unified text-visual encoder to obtain multi-modal features across different granularities, which makes it possible to project the multi-granular features into the same hyperspace. To model the region-word correlation, we design a cross-granular attention mechanism and specific pre-training tasks for our model to reinforce the model of learning the hierarchy between regions and words. Experiments demonstrate that our proposed model can learn better features that perform well across granularities and lead to improvements in downstream tasks.
Influence Functions for Sequence Tagging Models
Oct 25, 2022



Many language tasks (e.g., Named Entity Recognition, Part-of-Speech tagging, and Semantic Role Labeling) are naturally framed as sequence tagging problems. However, there has been comparatively little work on interpretability methods for sequence tagging models. In this paper, we extend influence functions - which aim to trace predictions back to the training points that informed them - to sequence tagging tasks. We define the influence of a training instance segment as the effect that perturbing the labels within this segment has on a test segment level prediction. We provide an efficient approximation to compute this, and show that it tracks with the true segment influence, measured empirically. We show the practical utility of segment influence by using the method to identify systematic annotation errors in two named entity recognition corpora. Code to reproduce our results is available at https://github.com/successar/Segment_Influence_Functions.
Self-Repetition in Abstractive Neural Summarizers
Oct 14, 2022
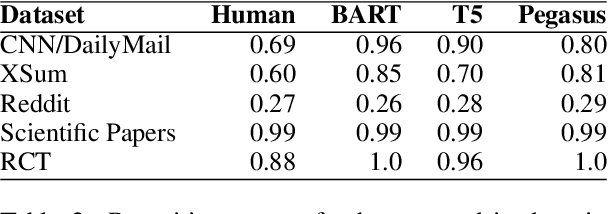
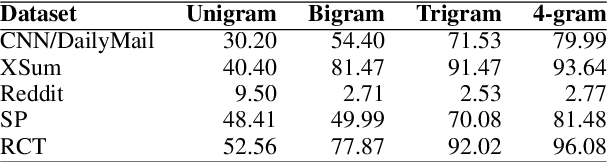

We provide a quantitative and qualitative analysis of self-repetition in the output of neural summarizers. We measure self-repetition as the number of n-grams of length four or longer that appear in multiple outputs of the same system. We analyze the behavior of three popular architectures (BART, T5, and Pegasus), fine-tuned on five datasets. In a regression analysis, we find that the three architectures have different propensities for repeating content across output summaries for inputs, with BART being particularly prone to self-repetition. Fine-tuning on more abstractive data, and on data featuring formulaic language, is associated with a higher rate of self-repetition. In qualitative analysis we find systems produce artefacts such as ads and disclaimers unrelated to the content being summarized, as well as formulaic phrases common in the fine-tuning domain. Our approach to corpus-level analysis of self-repetition may help practitioners clean up training data for summarizers and ultimately support methods for minimizing the amount of self-repetition.
Unified Pretraining Framework for Document Understanding
Apr 28, 2022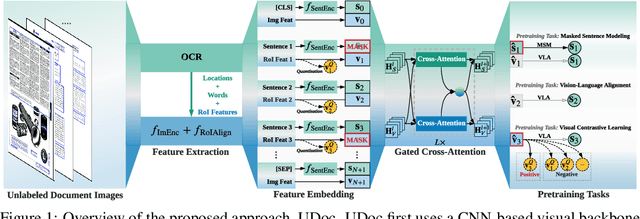
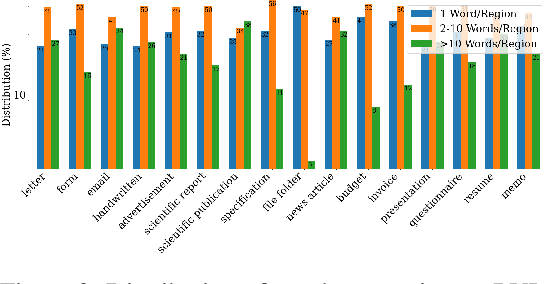
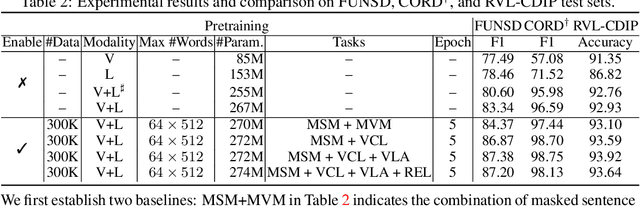
Document intelligence automates the extraction of information from documents and supports many business applications. Recent self-supervised learning methods on large-scale unlabeled document datasets have opened up promising directions towards reducing annotation efforts by training models with self-supervised objectives. However, most of the existing document pretraining methods are still language-dominated. We present UDoc, a new unified pretraining framework for document understanding. UDoc is designed to support most document understanding tasks, extending the Transformer to take multimodal embeddings as input. Each input element is composed of words and visual features from a semantic region of the input document image. An important feature of UDoc is that it learns a generic representation by making use of three self-supervised losses, encouraging the representation to model sentences, learn similarities, and align modalities. Extensive empirical analysis demonstrates that the pretraining procedure learns better joint representations and leads to improvements in downstream tasks.
Temporal Effects on Pre-trained Models for Language Processing Tasks
Nov 24, 2021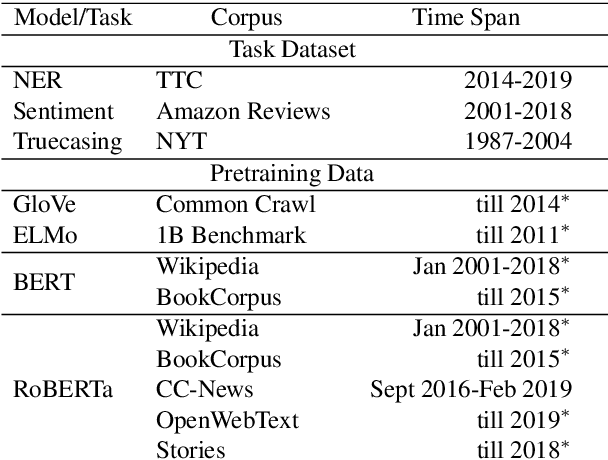
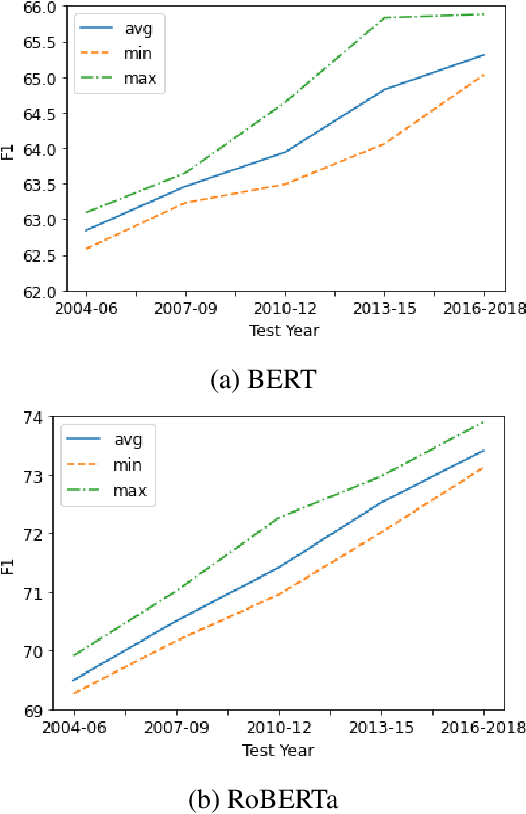
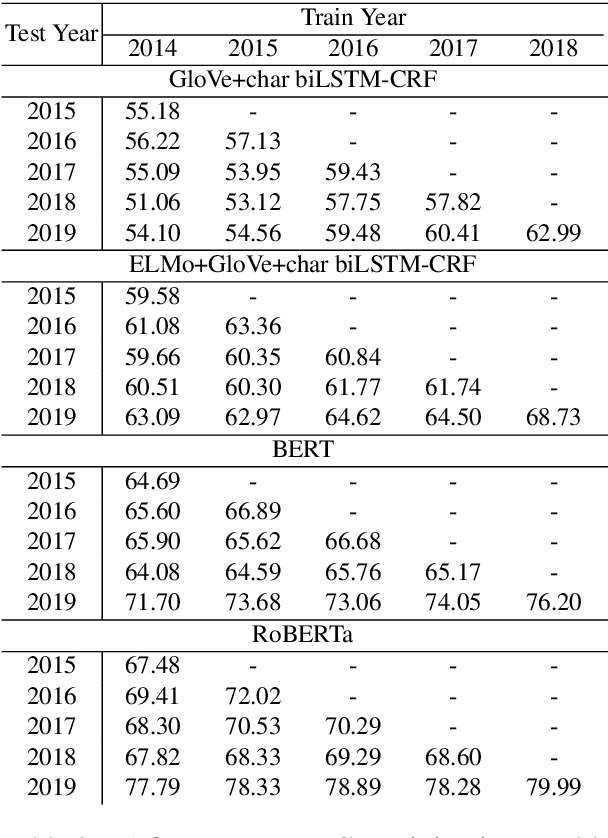
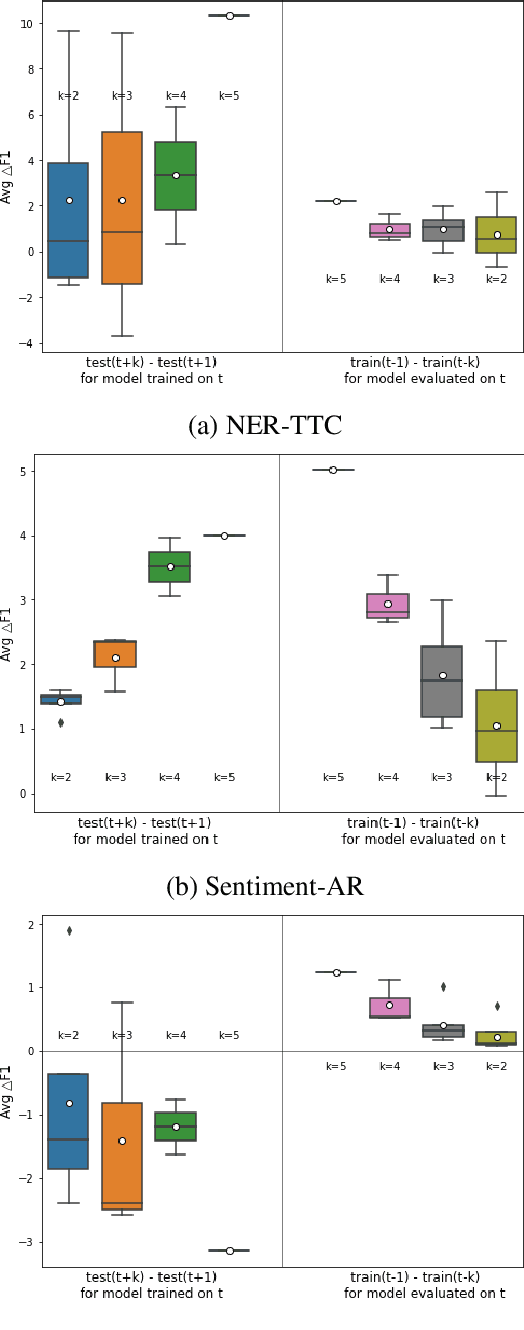
Keeping the performance of language technologies optimal as time passes is of great practical interest. Here we survey prior work concerned with the effect of time on system performance, establishing more nuanced terminology for discussing the topic and proper experimental design to support solid conclusions about the observed phenomena. We present a set of experiments with systems powered by large neural pretrained representations for English to demonstrate that {\em temporal model deterioration} is not as big a concern, with some models in fact improving when tested on data drawn from a later time period. It is however the case that {\em temporal domain adaptation} is beneficial, with better performance for a given time period possible when the system is trained on temporally more recent data. Our experiments reveal that the distinctions between temporal model deterioration and temporal domain adaptation becomes salient for systems built upon pretrained representations. Finally we examine the efficacy of two approaches for temporal domain adaptation without human annotations on new data, with self-labeling proving to be superior to continual pre-training. Notably, for named entity recognition, self-labeling leads to better temporal adaptation than human annotation.
From Toxicity in Online Comments to Incivility in American News: Proceed with Caution
Feb 06, 2021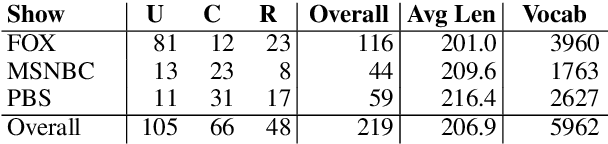

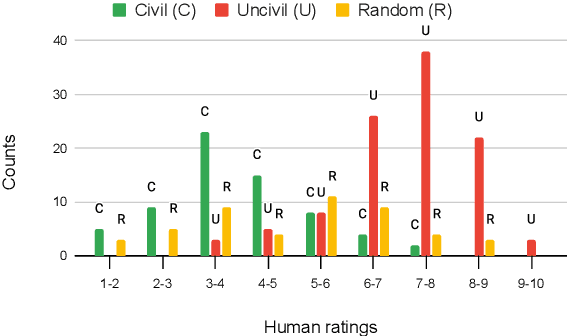

The ability to quantify incivility online, in news and in congressional debates, is of great interest to political scientists. Computational tools for detecting online incivility for English are now fairly accessible and potentially could be applied more broadly. We test the Jigsaw Perspective API for its ability to detect the degree of incivility on a corpus that we developed, consisting of manual annotations of civility in American news. We demonstrate that toxicity models, as exemplified by Perspective, are inadequate for the analysis of incivility in news. We carry out error analysis that points to the need to develop methods to remove spurious correlations between words often mentioned in the news, especially identity descriptors and incivility. Without such improvements, applying Perspective or similar models on news is likely to lead to wrong conclusions, that are not aligned with the human perception of incivility.
Understanding Clinical Trial Reports: Extracting Medical Entities and Their Relations
Oct 08, 2020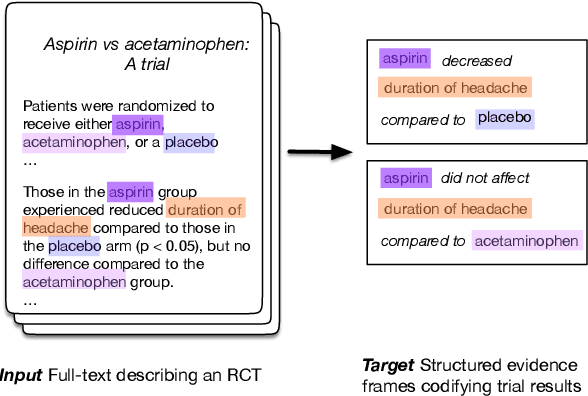

The best evidence concerning comparative treatment effectiveness comes from clinical trials, the results of which are reported in unstructured articles. Medical experts must manually extract information from articles to inform decision-making, which is time-consuming and expensive. Here we consider the end-to-end task of both (a) extracting treatments and outcomes from full-text articles describing clinical trials (entity identification) and, (b) inferring the reported results for the former with respect to the latter (relation extraction). We introduce new data for this task, and evaluate models that have recently achieved state-of-the-art results on similar tasks in Natural Language Processing. We then propose a new method motivated by how trial results are typically presented that outperforms these purely data-driven baselines. Finally, we run a fielded evaluation of the model with a non-profit seeking to identify existing drugs that might be re-purposed for cancer, showing the potential utility of end-to-end evidence extraction systems.
Trialstreamer: Mapping and Browsing Medical Evidence in Real-Time
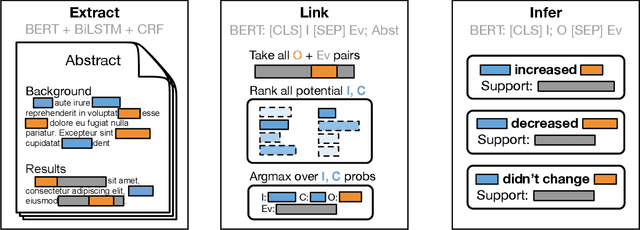
May 21, 2020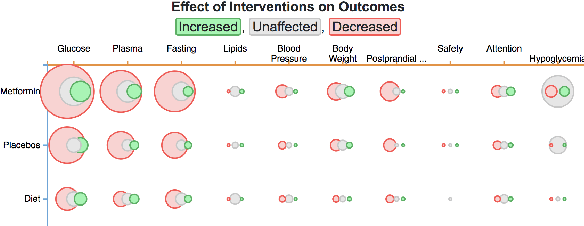
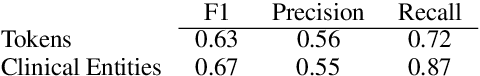
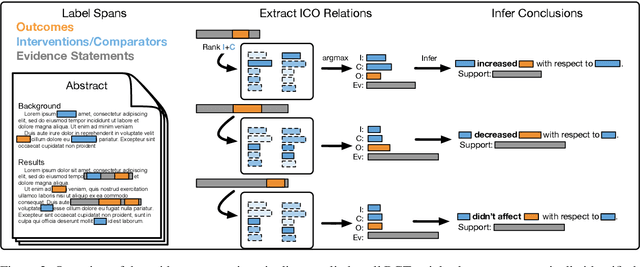
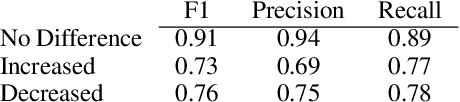
We introduce Trialstreamer, a living database of clinical trial reports. Here we mainly describe the evidence extraction component; this extracts from biomedical abstracts key pieces of information that clinicians need when appraising the literature, and also the relations between these. Specifically, the system extracts descriptions of trial participants, the treatments compared in each arm (the interventions), and which outcomes were measured. The system then attempts to infer which interventions were reported to work best by determining their relationship with identified trial outcome measures. In addition to summarizing individual trials, these extracted data elements allow automatic synthesis of results across many trials on the same topic. We apply the system at scale to all reports of randomized controlled trials indexed in MEDLINE, powering the automatic generation of evidence maps, which provide a global view of the efficacy of different interventions combining data from all relevant clinical trials on a topic. We make all code and models freely available alongside a demonstration of the web interface.
Interpretability Analysis for Named Entity Recognition to Understand System Predictions and How They Can Improve
Apr 09, 2020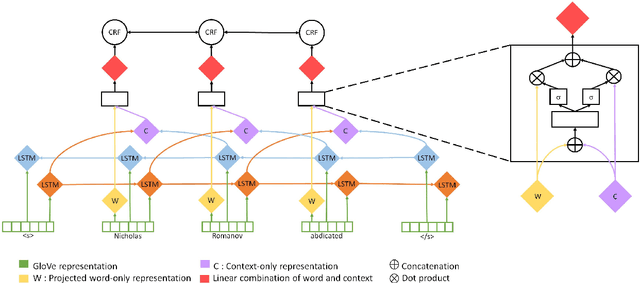
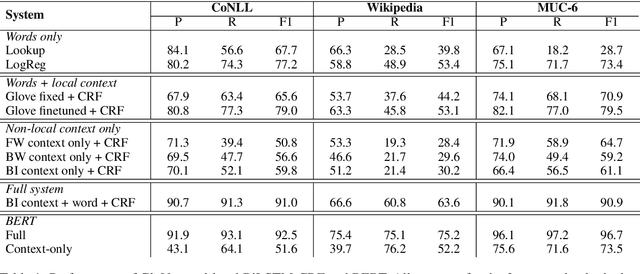
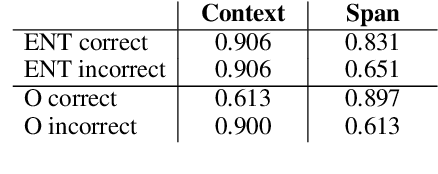

Named Entity Recognition systems achieve remarkable performance on domains such as English news. It is natural to ask: What are these models actually learning to achieve this? Are they merely memorizing the names themselves? Or are they capable of interpreting the text and inferring the correct entity type from the linguistic context? We examine these questions by contrasting the performance of several variants of LSTM-CRF architectures for named entity recognition, with some provided only representations of the context as features. We also perform similar experiments for BERT. We find that context representations do contribute to system performance, but that the main factor driving high performance is learning the name tokens themselves. We enlist human annotators to evaluate the feasibility of inferring entity types from the context alone and find that, while people are not able to infer the entity type either for the majority of the errors made by the context-only system, there is some room for improvement. A system should be able to recognize any name in a predictive context correctly and our experiments indicate that current systems may be further improved by such capability.