 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLOSS: Generative Latent Optimization of Sentence Representations
Jul 15, 2019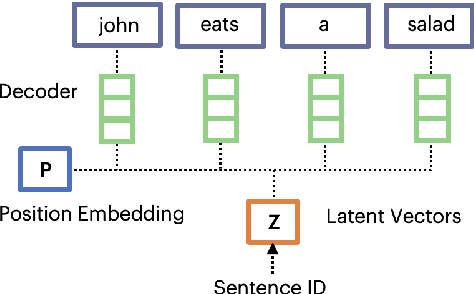
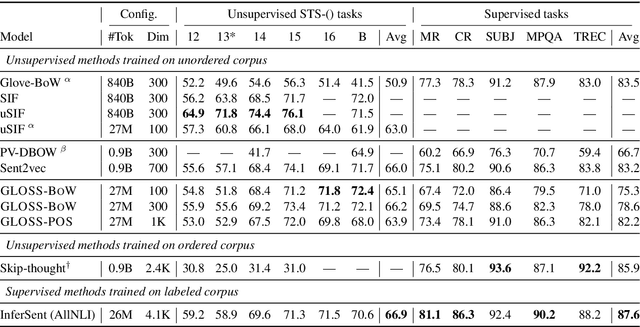
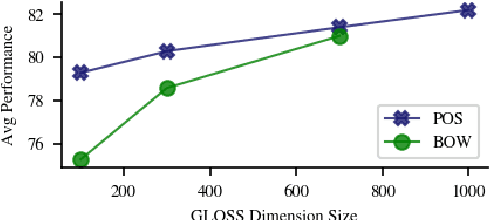

We propose a method to learn unsupervised sentence representations in a non-compositional manner based on Generative Latent Optimization. Our approach does not impose any assumptions on how words are to be combined into a sentence representation. We discuss a simple Bag of Words model as well as a variant that models word positions. Both are trained to reconstruct the sentence based on a latent code and our model can be used to generate text. Experiments show large improvements over the related Paragraph Vectors. Compared to uSIF, we achieve a relative improvement of 5% when trained on the same data and our method performs competitively to Sent2vec while trained on 30 times less data.
fairseq: A Fast, Extensible Toolkit for Sequence Modeling
Apr 01, 2019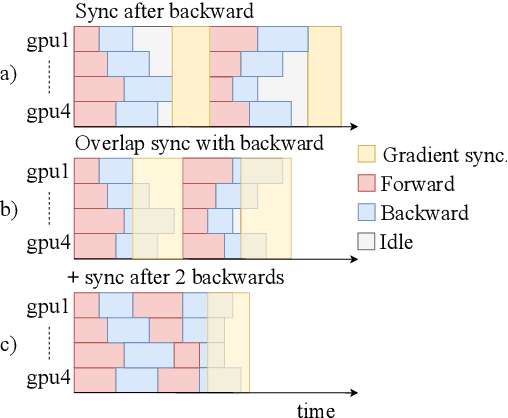

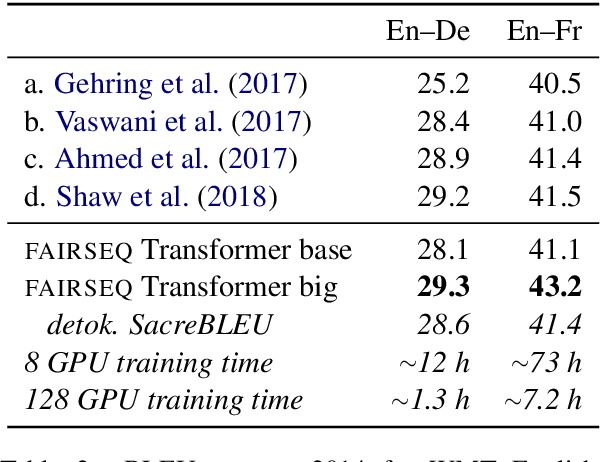
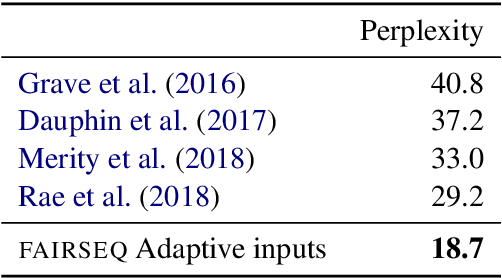
fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs. A demo video can be found at https://www.youtube.com/watch?v=OtgDdWtHvto
Learning to Speak and Act in a Fantasy Text Adventure Game
Mar 07, 2019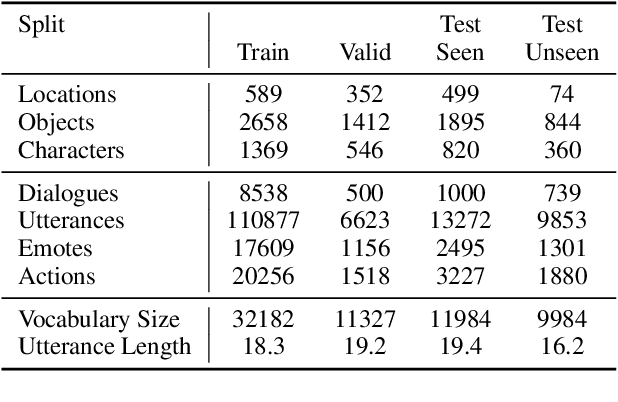
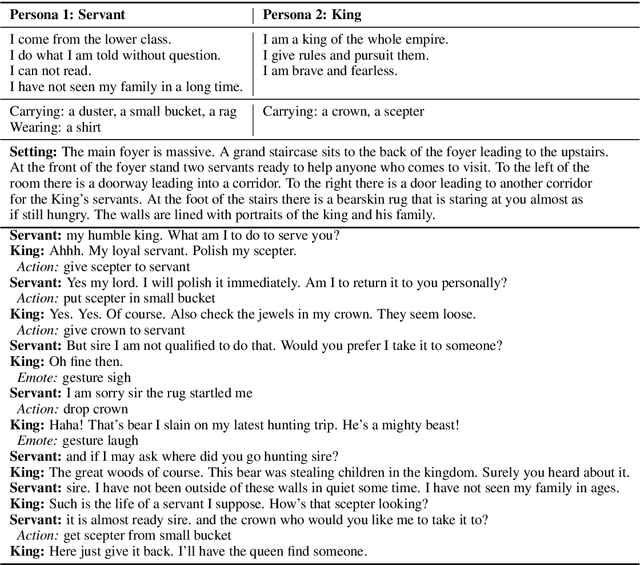
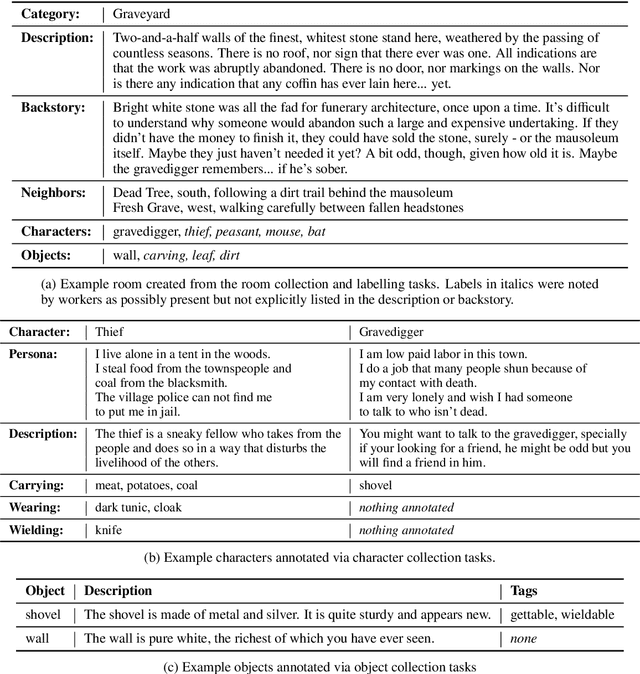

We introduce a large scale crowdsourced text adventure game as a research platform for studying grounded dialogue. In it, agents can perceive, emote, and act whilst conducting dialogue with other agents. Models and humans can both act as characters within the game. We describe the results of training state-of-the-art generative and retrieval models in this setting. We show that in addition to using past dialogue, these models are able to effectively use the state of the underlying world to condition their predictions. In particular, we show that grounding on the details of the local environment, including location descriptions, and the objects (and their affordances) and characters (and their previous actions) present within it allows better predictions of agent behavior and dialogue. We analyze the ingredients necessary for successful grounding in this setting, and how each of these factors relate to agents that can talk and act successfully.
Strategies for Structuring Story Generation
Feb 04, 2019
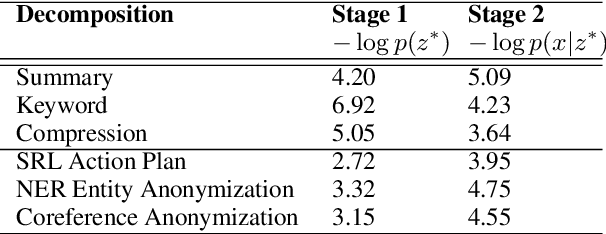
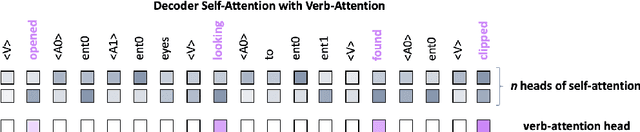
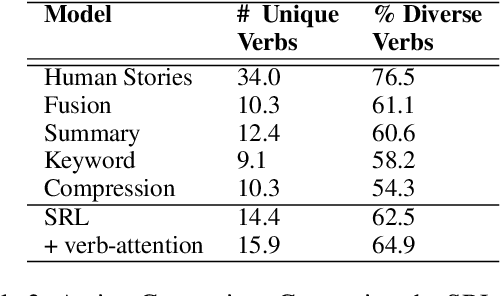
Writers generally rely on plans or sketches to write long stories, but most current language models generate word by word from left to right. We explore coarse-to-fine models for creating narrative texts of several hundred words, and introduce new models which decompose stories by abstracting over actions and entities. The model first generates the predicate-argument structure of the text, where different mentions of the same entity are marked with placeholder tokens. It then generates a surface realization of the predicate-argument structure, and finally replaces the entity placeholders with context-sensitive names and references. Human judges prefer the stories from our models to a wide range of previous approaches to hierarchical text generation. Extensive analysis shows that our methods can help improve the diversity and coherence of events and entities in generated stories.
Pay Less Attention with Lightweight and Dynamic Convolutions
Jan 29, 2019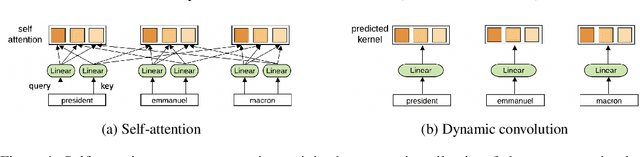
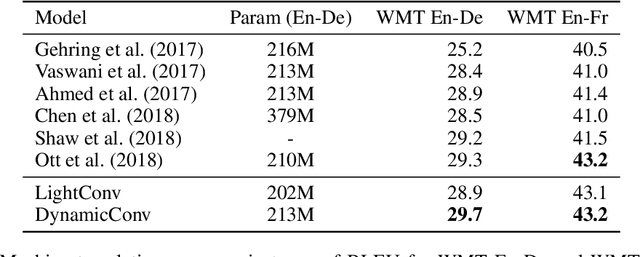
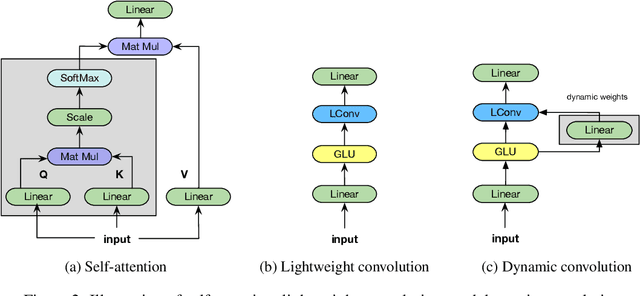
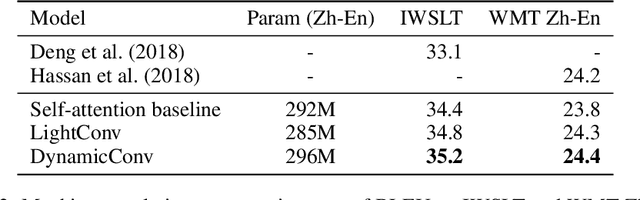
Self-attention is a useful mechanism to build generative models for language and images. It determines the importance of context elements by comparing each element to the current time step. In this paper, we show that a very lightweight convolution can perform competitively to the best reported self-attention results. Next, we introduce dynamic convolutions which are simpler and more efficient than self-attention. We predict separate convolution kernels based solely on the current time-step in order to determine the importance of context elements. The number of operations required by this approach scales linearly in the input length, whereas self-attention is quadratic. Experiments on large-scale machine translation, language modeling and abstractive summarization show that dynamic convolutions improve over strong self-attention models. On the WMT'14 English-German test set dynamic convolutions achieve a new state of the art of 29.7 BLEU.
Wizard of Wikipedia: Knowledge-Powered Conversational agents
Nov 03, 2018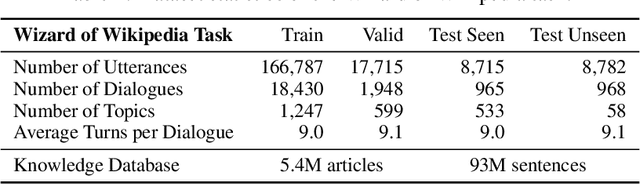
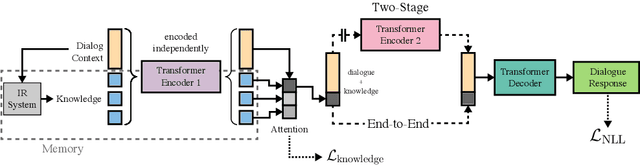

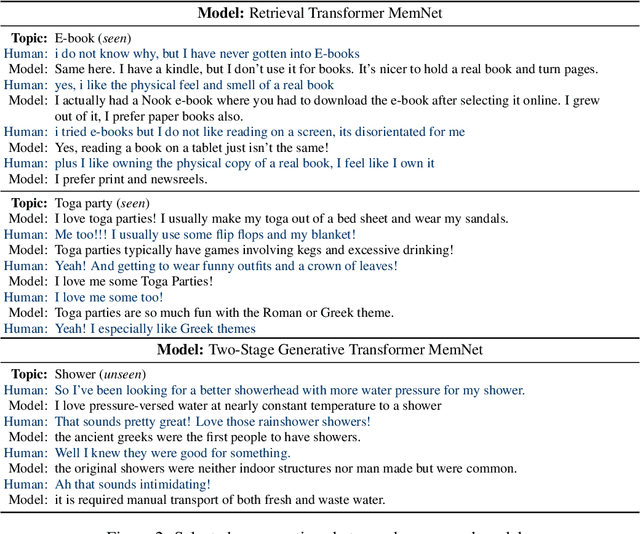
In open-domain dialogue intelligent agents should exhibit the use of knowledge, however there are few convincing demonstrations of this to date. The most popular sequence to sequence models typically "generate and hope" generic utterances that can be memorized in the weights of the model when mapping from input utterance(s) to output, rather than employing recalled knowledge as context. Use of knowledge has so far proved difficult, in part because of the lack of a supervised learning benchmark task which exhibits knowledgeable open dialogue with clear grounding. To that end we collect and release a large dataset with conversations directly grounded with knowledge retrieved from Wikipedia. We then design architectures capable of retrieving knowledge, reading and conditioning on it, and finally generating natural responses. Our best performing dialogue models are able to conduct knowledgeable discussions on open-domain topics as evaluated by automatic metrics and human evaluations, while our new benchmark allows for measuring further improvements in this important research direction.
Controllable Abstractive Summarization
May 18, 2018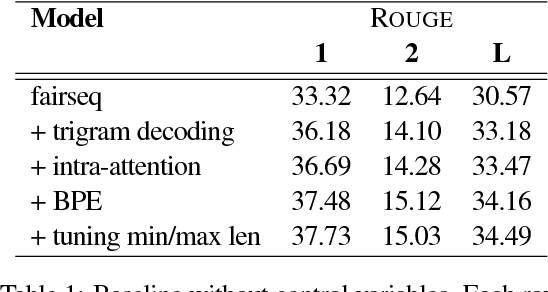

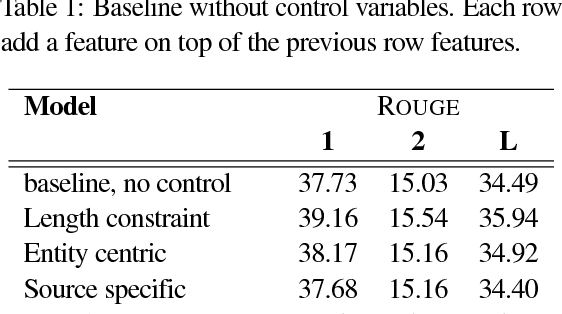
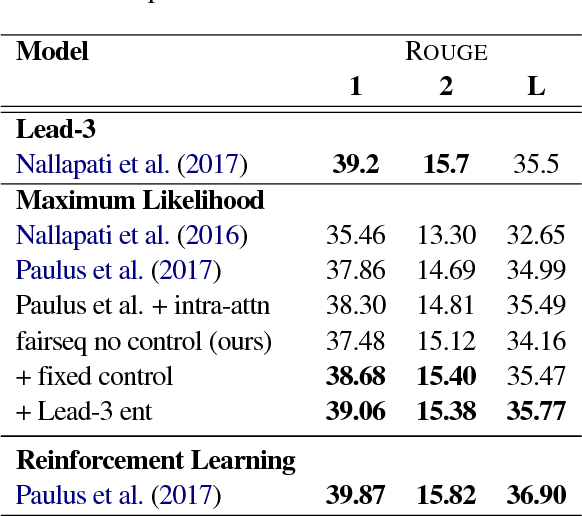
Current models for document summarization disregard user preferences such as the desired length, style, the entities that the user might be interested in, or how much of the document the user has already read. We present a neural summarization model with a simple but effective mechanism to enable users to specify these high level attributes in order to control the shape of the final summaries to better suit their needs. With user input, our system can produce high quality summaries that follow user preferences. Without user input, we set the control variables automatically. On the full text CNN-Dailymail dataset, we outperform state of the art abstractive systems (both in terms of F1-ROUGE1 40.38 vs. 39.53 and human evaluation).
Hierarchical Neural Story Generation
May 13, 2018
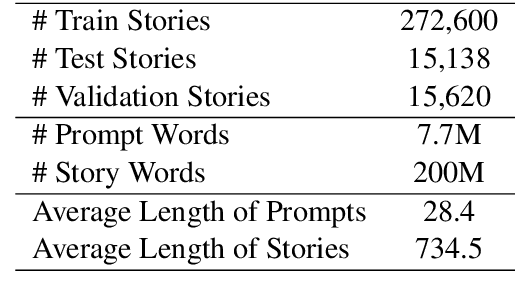
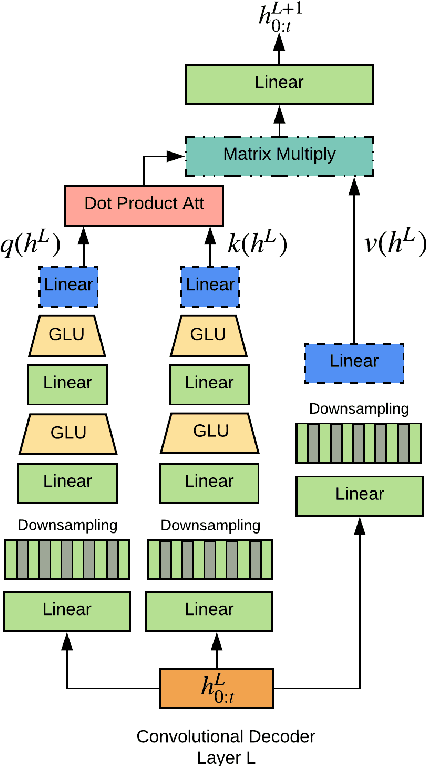
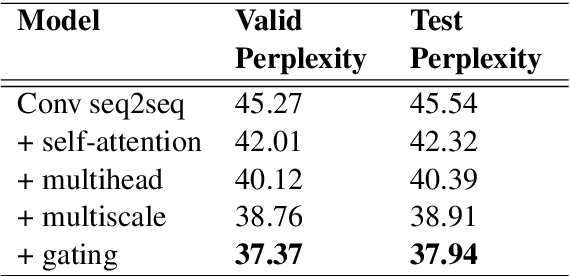
We explore story generation: creative systems that can build coherent and fluent passages of text about a topic. We collect a large dataset of 300K human-written stories paired with writing prompts from an online forum. Our dataset enables hierarchical story generation, where the model first generates a premise, and then transforms it into a passage of text. We gain further improvements with a novel form of model fusion that improves the relevance of the story to the prompt, and adding a new gated multi-scale self-attention mechanism to model long-range context. Experiments show large improvements over strong baselines on both automated and human evaluations. Human judges prefer stories generated by our approach to those from a strong non-hierarchical model by a factor of two to one.
Prior matters: simple and general methods for evaluating and improving topic quality in topic modeling
Oct 14, 2017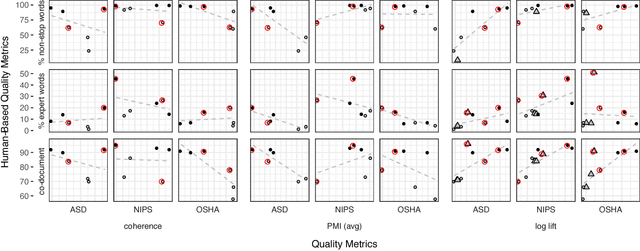
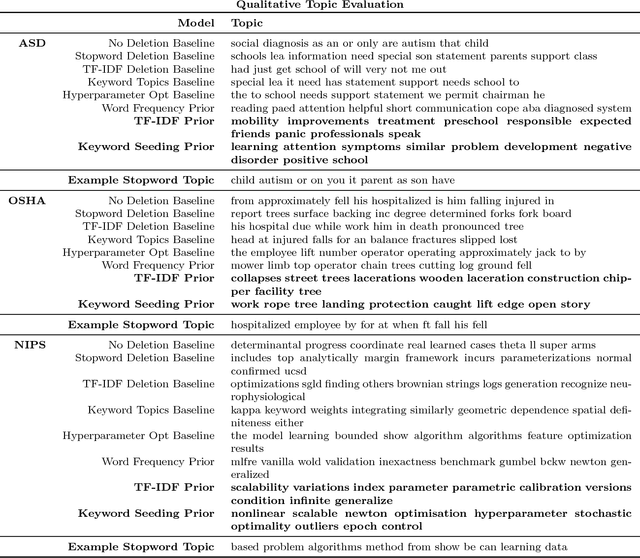

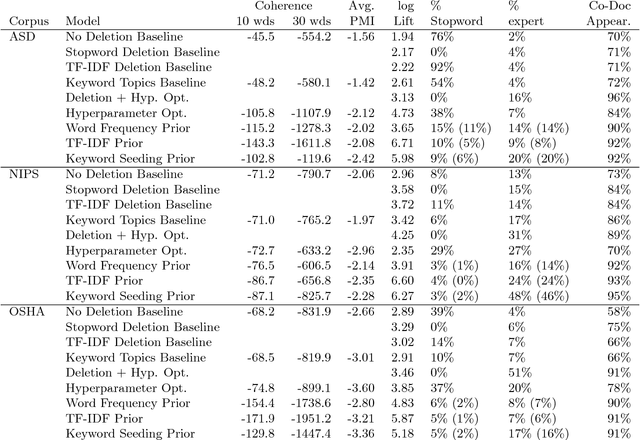
Latent Dirichlet Allocation (LDA) models trained without stopword removal often produce topics with high posterior probabilities on uninformative words, obscuring the underlying corpus content. Even when canonical stopwords are manually removed, uninformative words common in that corpus will still dominate the most probable words in a topic. In this work, we first show how the standard topic quality measures of coherence and pointwise mutual information act counter-intuitively in the presence of common but irrelevant words, making it difficult to even quantitatively identify situations in which topics may be dominated by stopwords. We propose an additional topic quality metric that targets the stopword problem, and show that it, unlike the standard measures, correctly correlates with human judgements of quality. We also propose a simple-to-implement strategy for generating topics that are evaluated to be of much higher quality by both human assessment and our new metric. This approach, a collection of informative priors easily introduced into most LDA-style inference methods, automatically promotes terms with domain relevance and demotes domain-specific stop words. We demonstrate this approach's effectiveness in three very different domains: Department of Labor accident reports, online health forum posts, and NIPS abstracts. Overall we find that current practices thought to solve this problem do not do so adequately, and that our proposal offers a substantial improvement for those interested in interpreting their topics as objects in their own right.
Language Modeling with Gated Convolutional Networks
Sep 08, 2017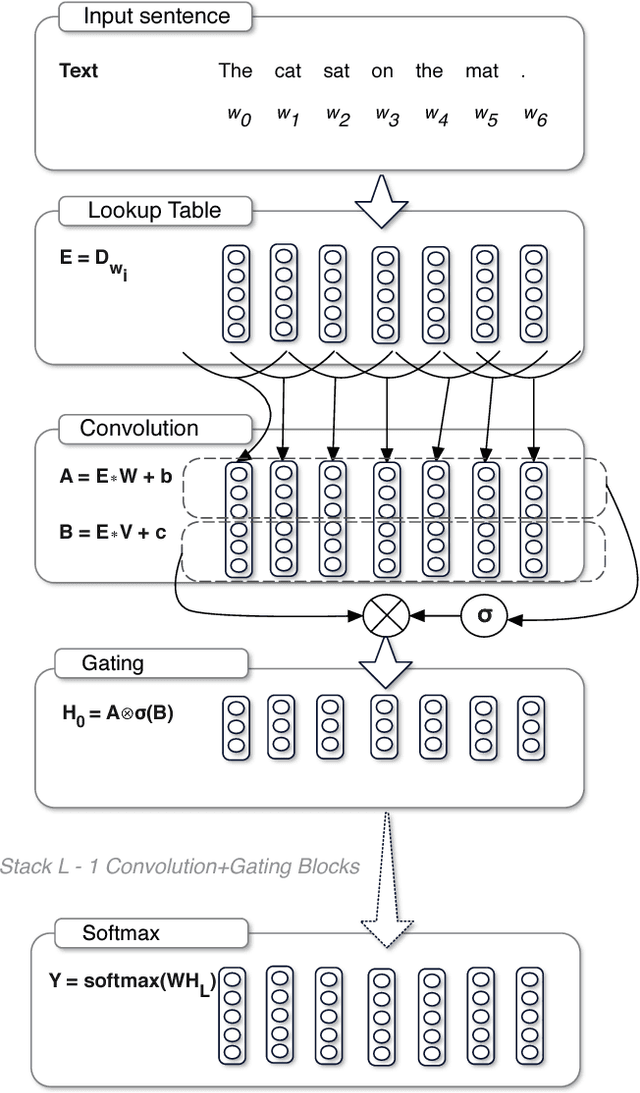
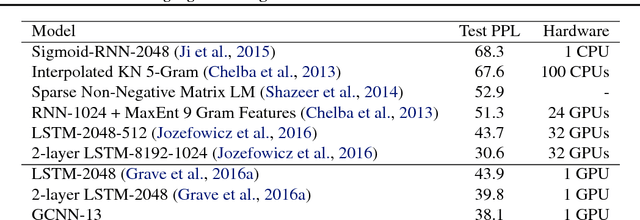

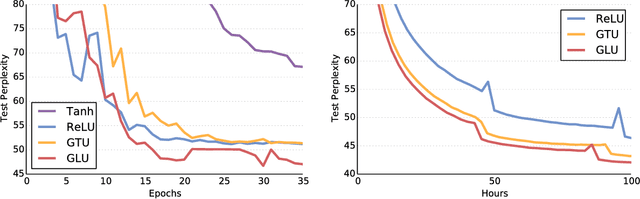
The pre-dominant approach to language modeling to date is based on recurrent neural networks. Their success on this task is often linked to their ability to capture unbounded context. In this paper we develop a finite context approach through stacked convolutions, which can be more efficient since they allow parallelization over sequential tokens. We propose a novel simplified gating mechanism that outperforms Oord et al (2016) and investigate the impact of key architectural decisions. The proposed approach achieves state-of-the-art on the WikiText-103 benchmark, even though it features long-term dependencies, as well as competitive results on the Google Billion Words benchmark. Our model reduces the latency to score a sentence by an order of magnitude compared to a recurrent baseline. To our knowledge, this is the first time a non-recurrent approach is competitive with strong recurrent models on these large scale language tasks.