 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Neural Processes
Jan 17, 2019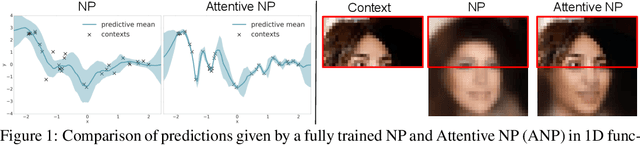
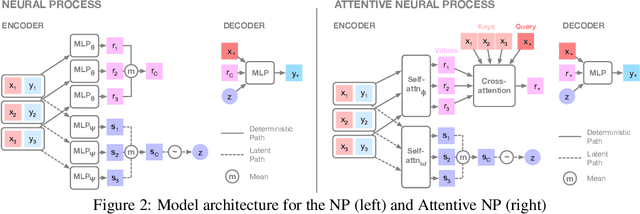
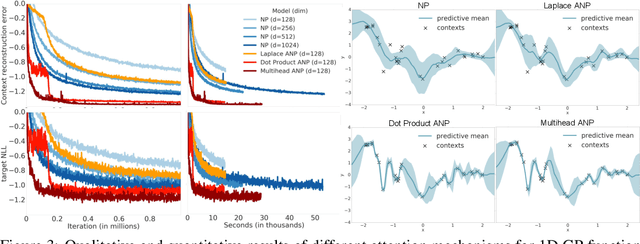
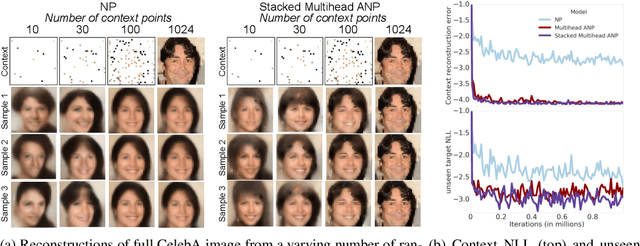
Neural Processes (NPs) (Garnelo et al 2018a;b) approach regression by learning to map a context set of observed input-output pairs to a distribution over regression functions. Each function models the distribution of the output given an input, conditioned on the context. NPs have the benefit of fitting observed data efficiently with linear complexity in the number of context input-output pairs, and can learn a wide family of conditional distributions; they learn predictive distributions conditioned on context sets of arbitrary size. Nonetheless, we show that NPs suffer a fundamental drawback of underfitting, giving inaccurate predictions at the inputs of the observed data they condition on. We address this issue by incorporating attention into NPs, allowing each input location to attend to the relevant context points for the prediction. We show that this greatly improves the accuracy of predictions, results in noticeably faster training, and expands the range of functions that can be modelled.
Implicit Reparameterization Gradients
Nov 01, 2018
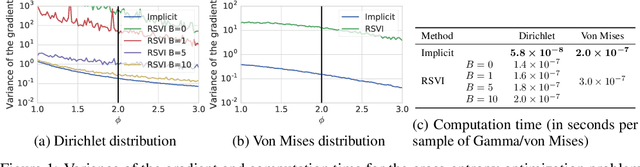
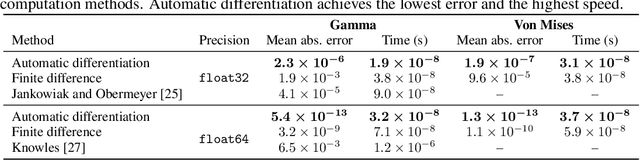
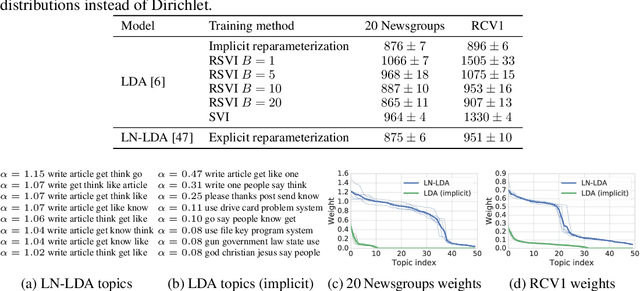
By providing a simple and efficient way of computing low-variance gradients of continuous random variables, the reparameterization trick has become the technique of choice for training a variety of latent variable models. However, it is not applicable to a number of important continuous distributions. We introduce an alternative approach to computing reparameterization gradients based on implicit differentiation and demonstrate its broader applicability by applying it to Gamma, Beta, Dirichlet, and von Mises distributions, which cannot be used with the classic reparameterization trick. Our experiments show that the proposed approach is faster and more accurate than the existing gradient estimators for these distributions.
Resampled Priors for Variational Autoencoders
Oct 26, 2018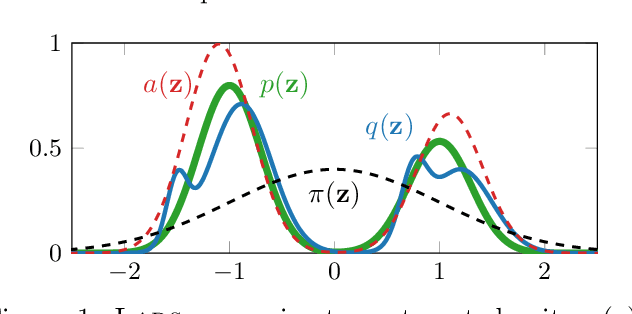
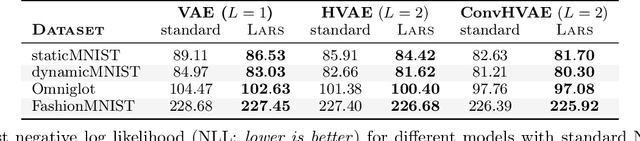
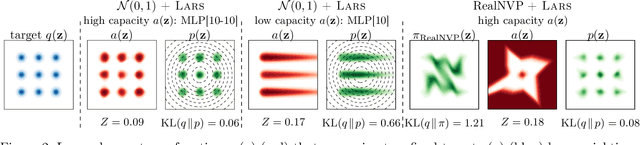

We propose Learned Accept/Reject Sampling (LARS), a method for constructing richer priors using rejection sampling with a learned acceptance function. This work is motivated by recent analyses of the VAE objective, which pointed out that commonly used simple priors can lead to underfitting. As the distribution induced by LARS involves an intractable normalizing constant, we show how to estimate it and its gradients efficiently. We demonstrate that LARS priors improve VAE performance on several standard datasets both when they are learned jointly with the rest of the model and when they are fitted to a pretrained model. Finally, we show that LARS can be combined with existing methods for defining flexible priors for an additional boost in performance.
Disentangling by Factorising
Jun 06, 2018
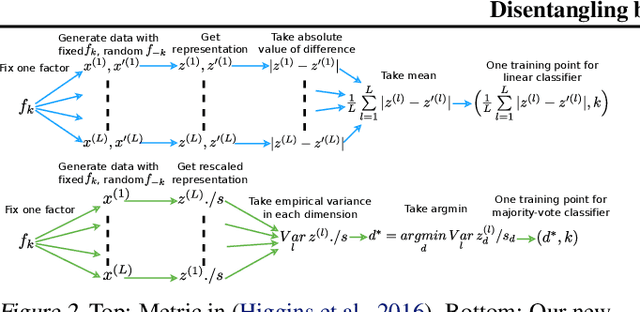

We define and address the problem of unsupervised learning of disentangled representations on data generated from independent factors of variation. We propose FactorVAE, a method that disentangles by encouraging the distribution of representations to be factorial and hence independent across the dimensions. We show that it improves upon $\beta$-VAE by providing a better trade-off between disentanglement and reconstruction quality. Moreover, we highlight the problems of a commonly used disentanglement metric and introduce a new metric that does not suffer from them.
Filtering Variational Objectives
Nov 12, 2017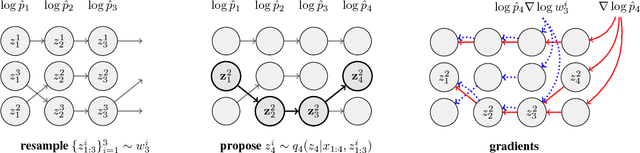
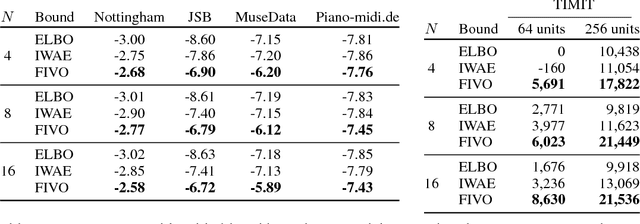
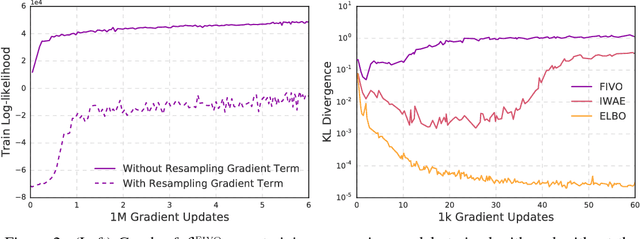
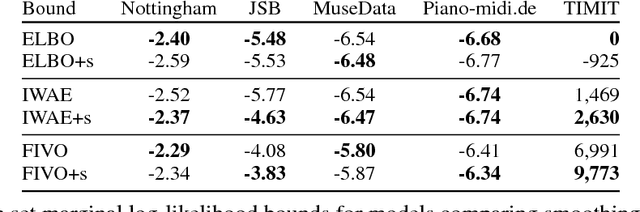
When used as a surrogate objective for maximum likelihood estimation in latent variable models, the evidence lower bound (ELBO) produces state-of-the-art results. Inspired by this, we consider the extension of the ELBO to a family of lower bounds defined by a particle filter's estimator of the marginal likelihood, the filtering variational objectives (FIVOs). FIVOs take the same arguments as the ELBO, but can exploit a model's sequential structure to form tighter bounds. We present results that relate the tightness of FIVO's bound to the variance of the particle filter's estimator by considering the generic case of bounds defined as log-transformed likelihood estimators. Experimentally, we show that training with FIVO results in substantial improvements over training the same model architecture with the ELBO on sequential data.
REBAR: Low-variance, unbiased gradient estimates for discrete latent variable models
Nov 06, 2017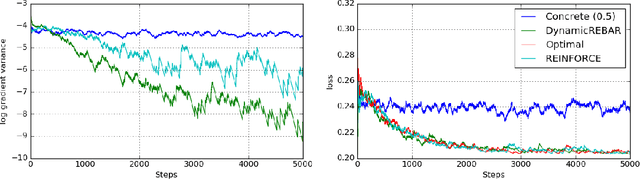
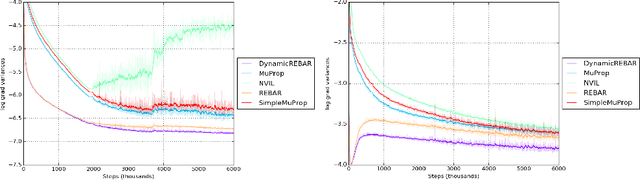
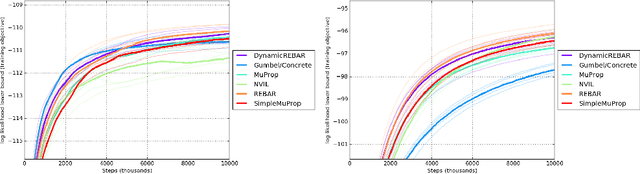
Learning in models with discrete latent variables is challenging due to high variance gradient estimators. Generally, approaches have relied on control variates to reduce the variance of the REINFORCE estimator. Recent work (Jang et al. 2016, Maddison et al. 2016) has taken a different approach, introducing a continuous relaxation of discrete variables to produce low-variance, but biased, gradient estimates. In this work, we combine the two approaches through a novel control variate that produces low-variance, \emph{unbiased} gradient estimates. Then, we introduce a modification to the continuous relaxation and show that the tightness of the relaxation can be adapted online, removing it as a hyperparameter. We show state-of-the-art variance reduction on several benchmark generative modeling tasks, generally leading to faster convergence to a better final log-likelihood.
Variational Memory Addressing in Generative Models
Sep 21, 2017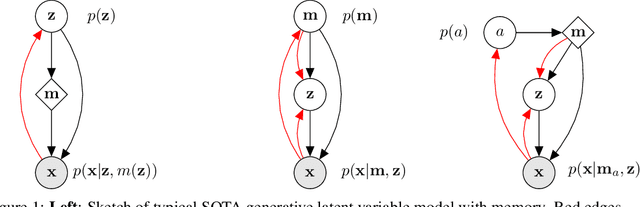
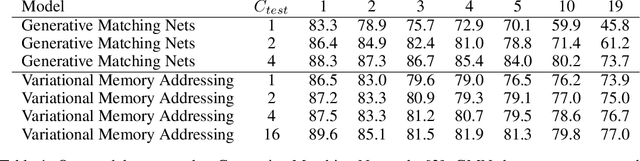
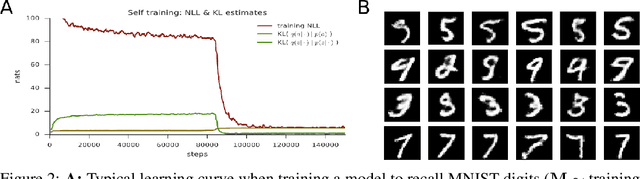
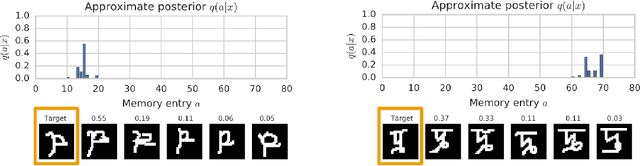
Aiming to augment generative models with external memory, we interpret the output of a memory module with stochastic addressing as a conditional mixture distribution, where a read operation corresponds to sampling a discrete memory address and retrieving the corresponding content from memory. This perspective allows us to apply variational inference to memory addressing, which enables effective training of the memory module by using the target information to guide memory lookups. Stochastic addressing is particularly well-suited for generative models as it naturally encourages multimodality which is a prominent aspect of most high-dimensional datasets. Treating the chosen address as a latent variable also allows us to quantify the amount of information gained with a memory lookup and measure the contribution of the memory module to the generative process. To illustrate the advantages of this approach we incorporate it into a variational autoencoder and apply the resulting model to the task of generative few-shot learning. The intuition behind this architecture is that the memory module can pick a relevant template from memory and the continuous part of the model can concentrate on modeling remaining variations. We demonstrate empirically that our model is able to identify and access the relevant memory contents even with hundreds of unseen Omniglot characters in memory
Particle Value Functions
Mar 16, 2017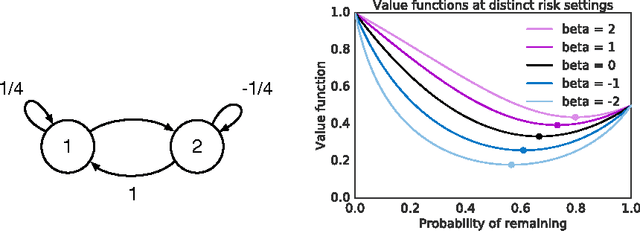
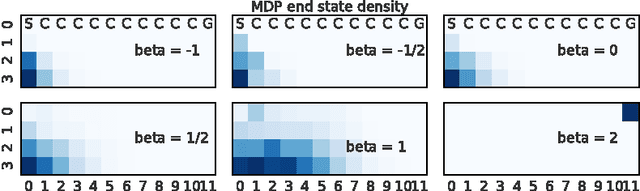
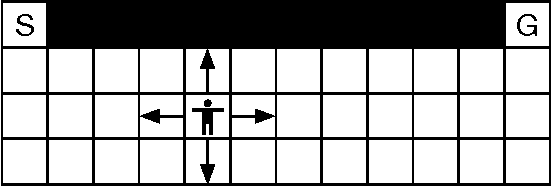
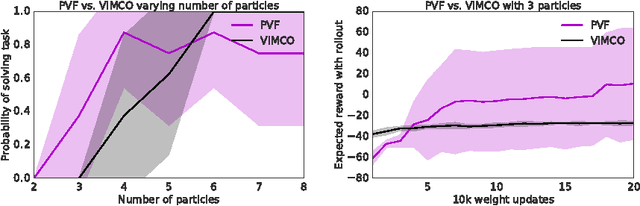
The policy gradients of the expected return objective can react slowly to rare rewards. Yet, in some cases agents may wish to emphasize the low or high returns regardless of their probability. Borrowing from the economics and control literature, we review the risk-sensitive value function that arises from an exponential utility and illustrate its effects on an example. This risk-sensitive value function is not always applicable to reinforcement learning problems, so we introduce the particle value function defined by a particle filter over the distributions of an agent's experience, which bounds the risk-sensitive one. We illustrate the benefit of the policy gradients of this objective in Cliffworld.
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
Mar 05, 2017
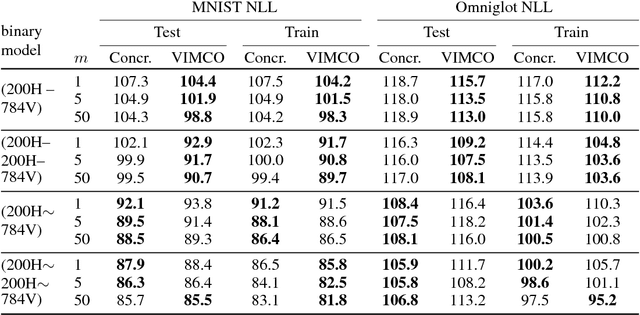
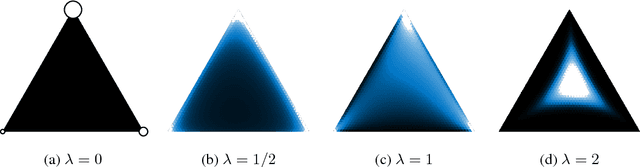
The reparameterization trick enables optimizing large scale stochastic computation graphs via gradient descent. The essence of the trick is to refactor each stochastic node into a differentiable function of its parameters and a random variable with fixed distribution. After refactoring, the gradients of the loss propagated by the chain rule through the graph are low variance unbiased estimators of the gradients of the expected loss. While many continuous random variables have such reparameterizations, discrete random variables lack useful reparameterizations due to the discontinuous nature of discrete states. In this work we introduce Concrete random variables---continuous relaxations of discrete random variables. The Concrete distribution is a new family of distributions with closed form densities and a simple reparameterization. Whenever a discrete stochastic node of a computation graph can be refactored into a one-hot bit representation that is treated continuously, Concrete stochastic nodes can be used with automatic differentiation to produce low-variance biased gradients of objectives (including objectives that depend on the log-probability of latent stochastic nodes) on the corresponding discrete graph. We demonstrate the effectiveness of Concrete relaxations on density estimation and structured prediction tasks using neural networks.
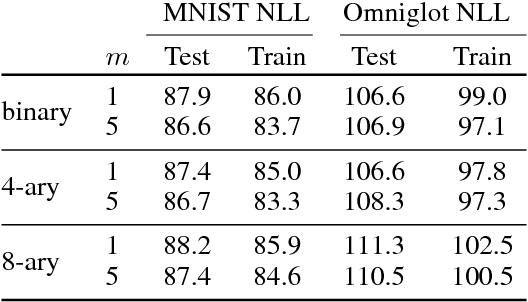
Variational inference for Monte Carlo objectives
Jun 01, 2016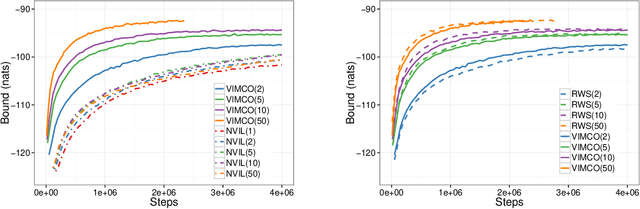
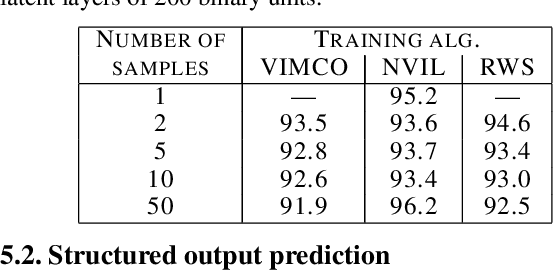
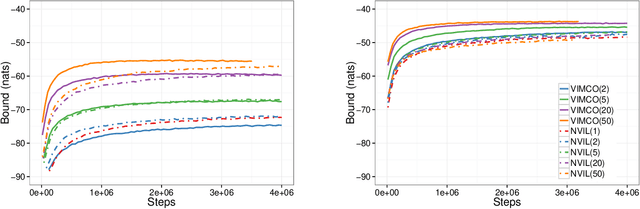
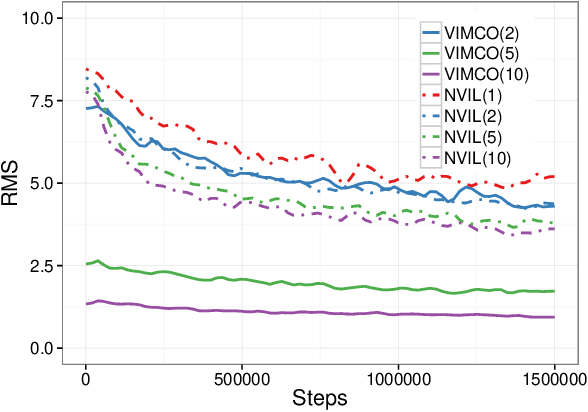
Recent progress in deep latent variable models has largely been driven by the development of flexible and scalable variational inference methods. Variational training of this type involves maximizing a lower bound on the log-likelihood, using samples from the variational posterior to compute the required gradients. Recently, Burda et al. (2016) have derived a tighter lower bound using a multi-sample importance sampling estimate of the likelihood and showed that optimizing it yields models that use more of their capacity and achieve higher likelihoods. This development showed the importance of such multi-sample objectives and explained the success of several related approaches. We extend the multi-sample approach to discrete latent variables and analyze the difficulty encountered when estimating the gradients involved. We then develop the first unbiased gradient estimator designed for importance-sampled objectives and evaluate it at training generative and structured output prediction models. The resulting estimator, which is based on low-variance per-sample learning signals, is both simpler and more effective than the NVIL estimator proposed for the single-sample variational objective, and is competitive with the currently used biased estimators.