 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Video Labelling: Identifying Faces by Corroborative Evidence
Feb 10, 2021
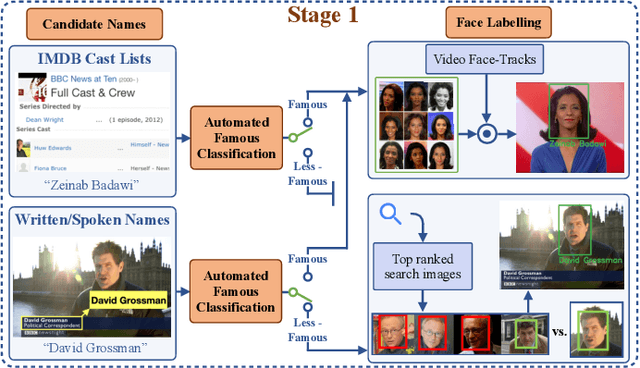
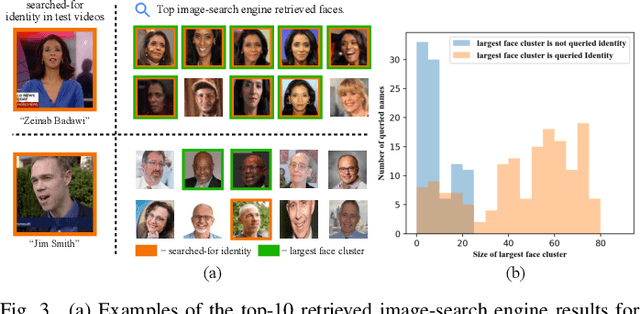

We present a method for automatically labelling all faces in video archives, such as TV broadcasts, by combining multiple evidence sources and multiple modalities (visual and audio). We target the problem of ever-growing online video archives, where an effective, scalable indexing solution cannot require a user to provide manual annotation or supervision. To this end, we make three key contributions: (1) We provide a novel, simple, method for determining if a person is famous or not using image-search engines. In turn this enables a face-identity model to be built reliably and robustly, and used for high precision automatic labelling; (2) We show that even for less-famous people, image-search engines can then be used for corroborative evidence to accurately label faces that are named in the scene or the speech; (3) Finally, we quantitatively demonstrate the benefits of our approach on different video domains and test settings, such as TV shows and news broadcasts. Our method works across three disparate datasets without any explicit domain adaptation, and sets new state-of-the-art results on all the public benchmarks.
LAEO-Net++: revisiting people Looking At Each Other in videos
Jan 06, 2021
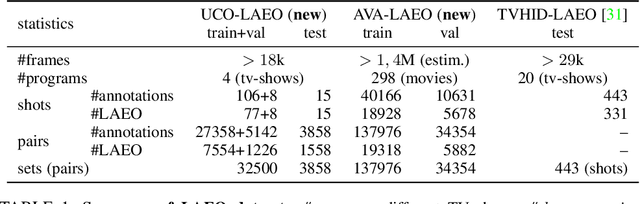
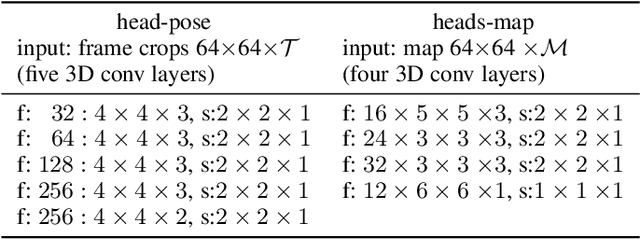
Capturing the 'mutual gaze' of people is essential for understanding and interpreting the social interactions between them. To this end, this paper addresses the problem of detecting people Looking At Each Other (LAEO) in video sequences. For this purpose, we propose LAEO-Net++, a new deep CNN for determining LAEO in videos. In contrast to previous works, LAEO-Net++ takes spatio-temporal tracks as input and reasons about the whole track. It consists of three branches, one for each character's tracked head and one for their relative position. Moreover, we introduce two new LAEO datasets: UCO-LAEO and AVA-LAEO. A thorough experimental evaluation demonstrates the ability of LAEO-Net++ to successfully determine if two people are LAEO and the temporal window where it happens. Our model achieves state-of-the-art results on the existing TVHID-LAEO video dataset, significantly outperforming previous approaches. Finally, we apply LAEO-Net++ to a social network, where we automatically infer the social relationship between pairs of people based on the frequency and duration that they LAEO, and show that LAEO can be a useful tool for guided search of human interactions in videos. The code is available at https://github.com/AVAuco/laeonetplus.
* 16 pages, 16 Figures. arXiv admin note: substantial text overlap with arXiv:1906.05261
VoxSRC 2020: The Second VoxCeleb Speaker Recognition Challenge
Dec 12, 2020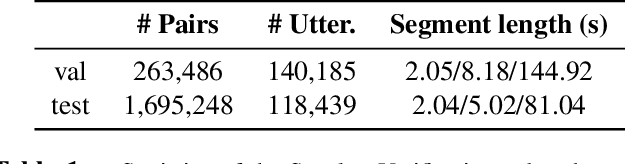
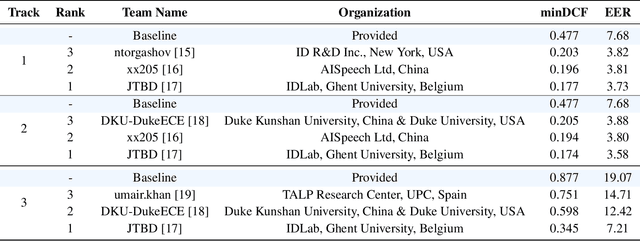

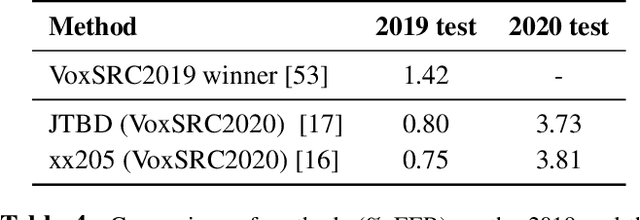
We held the second installment of the VoxCeleb Speaker Recognition Challenge in conjunction with Interspeech 2020. The goal of this challenge was to assess how well current speaker recognition technology is able to diarise and recognize speakers in unconstrained or `in the wild' data. It consisted of: (i) a publicly available speaker recognition and diarisation dataset from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2020. This paper outlines the challenge, and describes the baselines, methods used, and results. We conclude with a discussion of the progress over the first installment of the challenge.
Betrayed by Motion: Camouflaged Object Discovery via Motion Segmentation
Nov 23, 2020
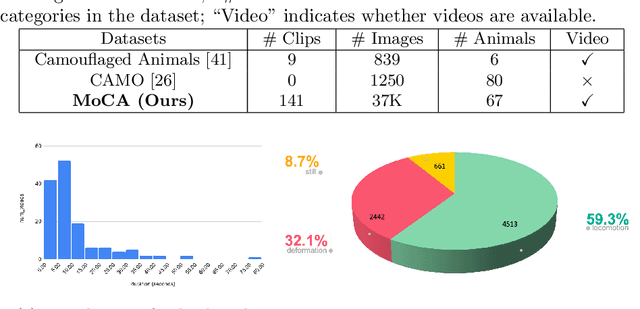
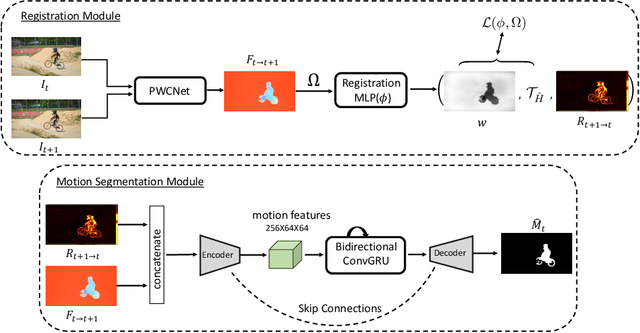
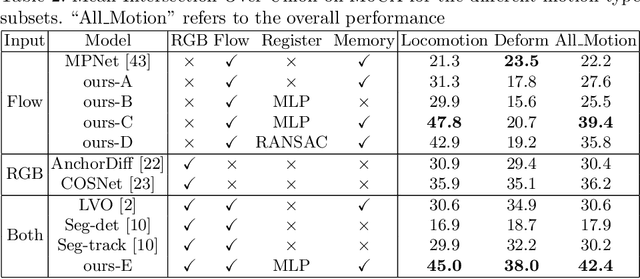
The objective of this paper is to design a computational architecture that discovers camouflaged objects in videos, specifically by exploiting motion information to perform object segmentation. We make the following three contributions: (i) We propose a novel architecture that consists of two essential components for breaking camouflage, namely, a differentiable registration module to align consecutive frames based on the background, which effectively emphasises the object boundary in the difference image, and a motion segmentation module with memory that discovers the moving objects, while maintaining the object permanence even when motion is absent at some point. (ii) We collect the first large-scale Moving Camouflaged Animals (MoCA) video dataset, which consists of over 140 clips across a diverse range of animals (67 categories). (iii) We demonstrate the effectiveness of the proposed model on MoCA, and achieve competitive performance on the unsupervised segmentation protocol on DAVIS2016 by only relying on motion.
QuerYD: A video dataset with high-quality textual and audio narrations
Nov 22, 2020
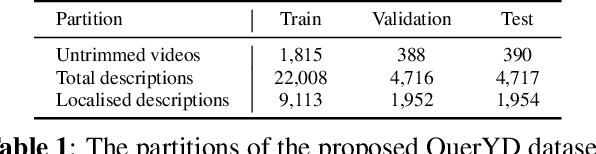


We introduce QuerYD, a new large-scale dataset for retrieval and event localisation in video. A unique feature of our dataset is the availability of two audio tracks for each video: the original audio, and a high-quality spoken description of the visual content. The dataset is based on YouDescribe, a volunteer project that assists visually-impaired people by attaching voiced narrations to existing YouTube videos. This ever-growing collection of videos contains highly detailed, temporally aligned audio and text annotations. The content descriptions are more relevant than dialogue, and more detailed than previous description attempts, which can be observed to contain many superficial or uninformative descriptions. To demonstrate the utility of the QuerYD dataset, we show that it can be used to train and benchmark strong models for retrieval and event localisation. All data, code and models will be made available, and we hope that QuerYD inspires further research on video understanding with written and spoken natural language.
A Short Note on the Kinetics-700-2020 Human Action Dataset
Oct 21, 2020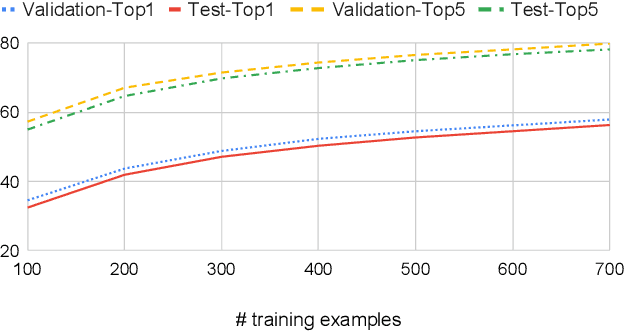
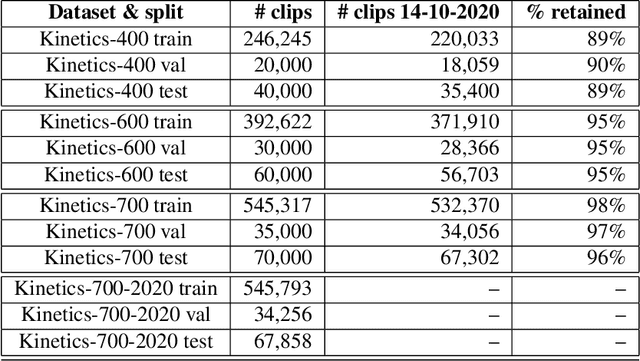
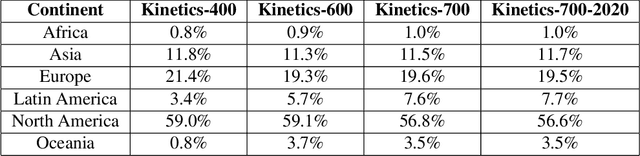
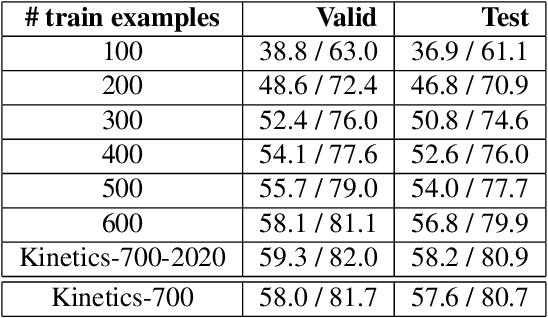
We describe the 2020 edition of the DeepMind Kinetics human action dataset, which replenishes and extends the Kinetics-700 dataset. In this new version, there are at least 700 video clips from different YouTube videos for each of the 700 classes. This paper details the changes introduced for this new release of the dataset and includes a comprehensive set of statistics as well as baseline results using the I3D network.
Self-supervised Co-training for Video Representation Learning
Oct 19, 2020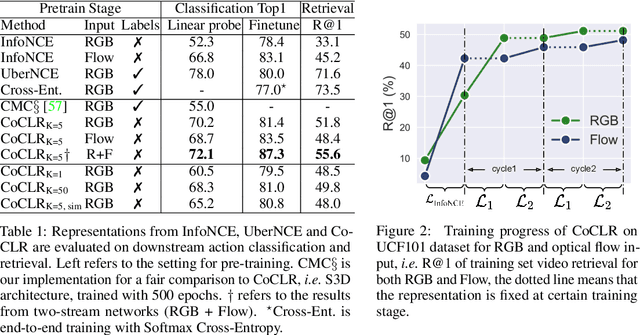
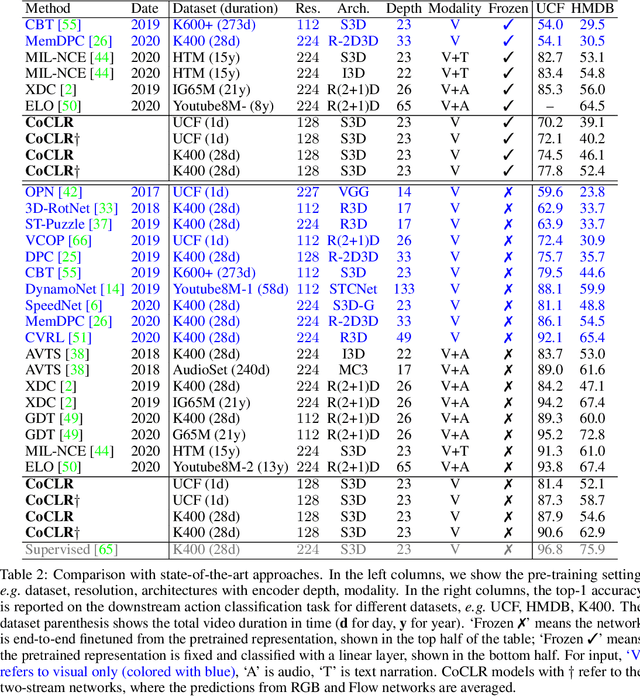
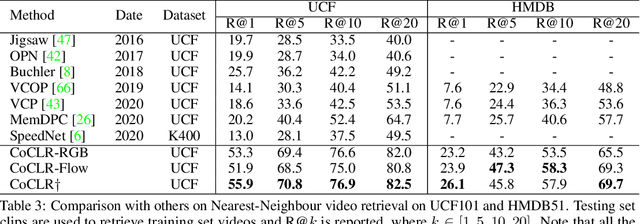

The objective of this paper is visual-only self-supervised video representation learning. We make the following contributions: (i) we investigate the benefit of adding semantic-class positives to instance-based Info Noise Contrastive Estimation (InfoNCE) training, showing that this form of supervised contrastive learning leads to a clear improvement in performance; (ii) we propose a novel self-supervised co-training scheme to improve the popular infoNCE loss, exploiting the complementary information from different views, RGB streams and optical flow, of the same data source by using one view to obtain positive class samples for the other; (iii) we thoroughly evaluate the quality of the learnt representation on two different downstream tasks: action recognition and video retrieval. In both cases, the proposed approach demonstrates state-of-the-art or comparable performance with other self-supervised approaches, whilst being significantly more efficient to train, i.e. requiring far less training data to achieve similar performance.
Watch, read and lookup: learning to spot signs from multiple supervisors
Oct 08, 2020
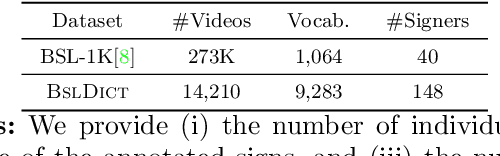

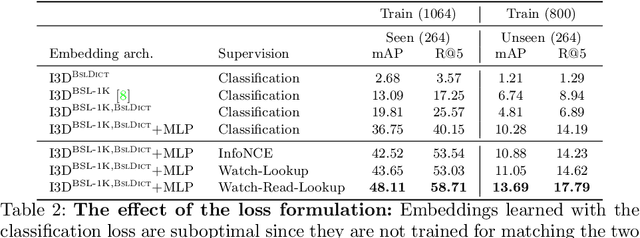
The focus of this work is sign spotting - given a video of an isolated sign, our task is to identify whether and where it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) watching existing sparsely labelled footage; (2) reading associated subtitles (readily available translations of the signed content) which provide additional weak-supervision; (3) looking up words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page.
Layered Neural Rendering for Retiming People in Video
Sep 16, 2020
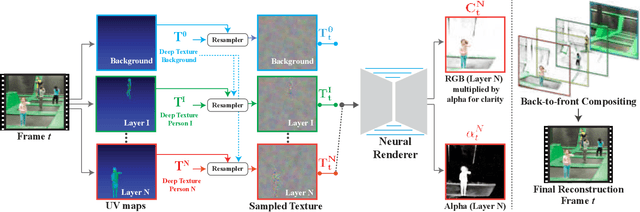

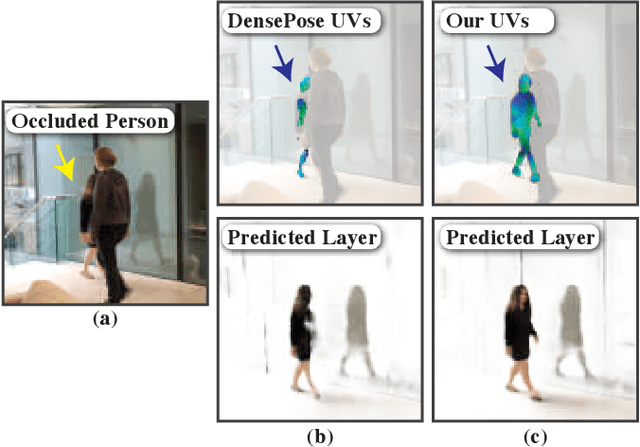
We present a method for retiming people in an ordinary, natural video---manipulating and editing the time in which different motions of individuals in the video occur. We can temporally align different motions, change the speed of certain actions (speeding up/slowing down, or entirely "freezing" people), or "erase" selected people from the video altogether. We achieve these effects computationally via a dedicated learning-based layered video representation, where each frame in the video is decomposed into separate RGBA layers, representing the appearance of different people in the video. A key property of our model is that it not only disentangles the direct motions of each person in the input video, but also correlates each person automatically with the scene changes they generate---e.g., shadows, reflections, and motion of loose clothing. The layers can be individually retimed and recombined into a new video, allowing us to achieve realistic, high-quality renderings of retiming effects for real-world videos depicting complex actions and involving multiple individuals, including dancing, trampoline jumping, or group running.
Adaptive Text Recognition through Visual Matching
Sep 14, 2020
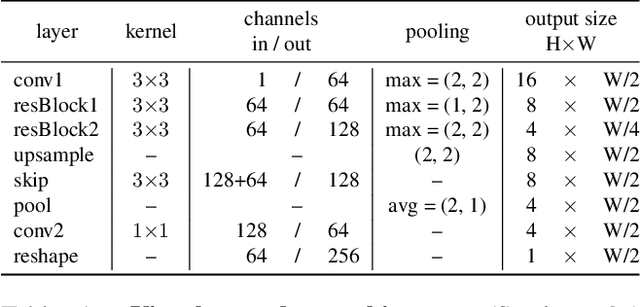
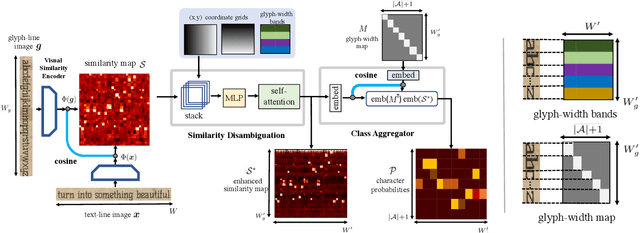
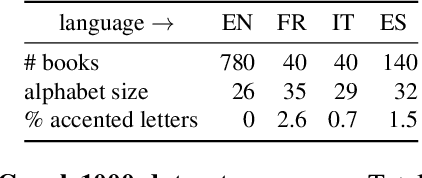
In this work, our objective is to address the problems of generalization and flexibility for text recognition in documents. We introduce a new model that exploits the repetitive nature of characters in languages, and decouples the visual representation learning and linguistic modelling stages. By doing this, we turn text recognition into a shape matching problem, and thereby achieve generalization in appearance and flexibility in classes. We evaluate the new model on both synthetic and real datasets across different alphabets and show that it can handle challenges that traditional architectures are not able to solve without expensive retraining, including: (i) it can generalize to unseen fonts without new exemplars from them; (ii) it can flexibly change the number of classes, simply by changing the exemplars provided; and (iii) it can generalize to new languages and new characters that it has not been trained for by providing a new glyph set. We show significant improvements over state-of-the-art models for all these cases.