 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Quality Controlled Analysis of 2D Phase Contrast Cardiovascular Magnetic Resonance Imaging
Sep 28, 2022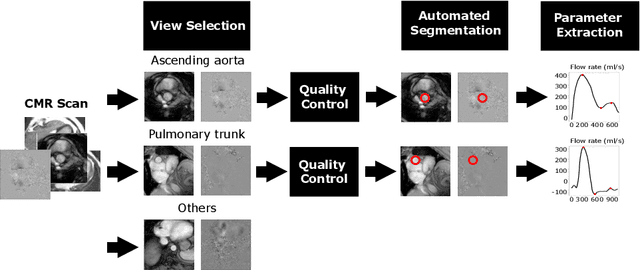
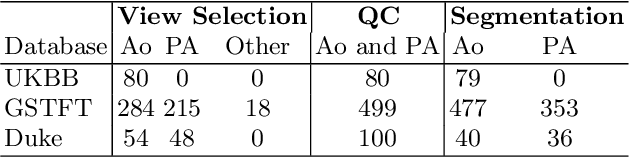
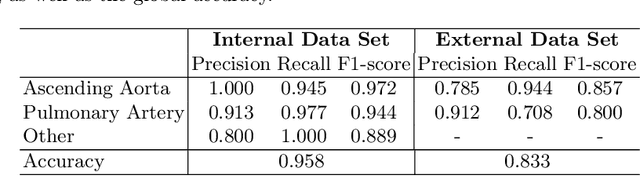
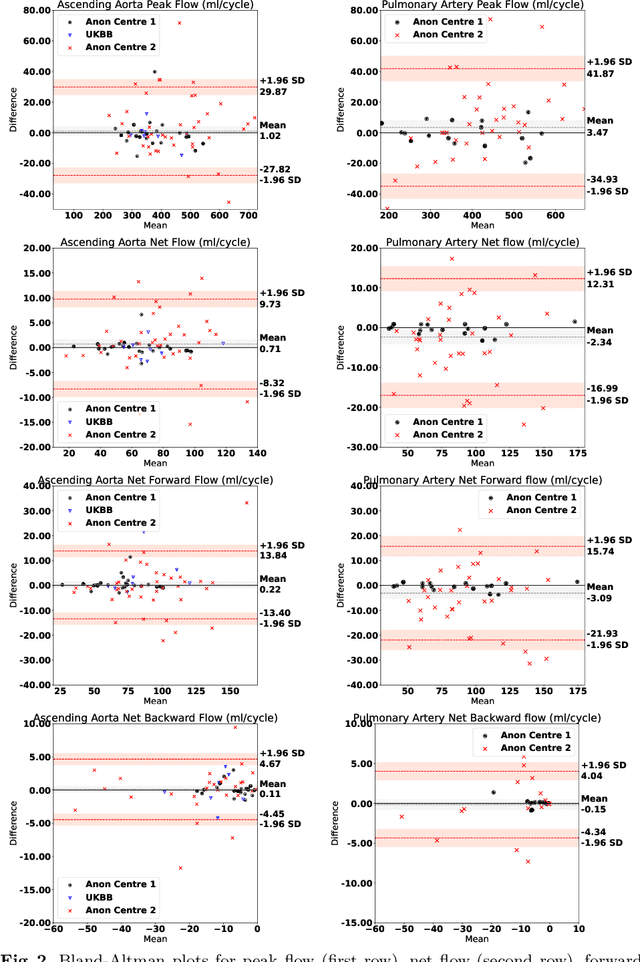
Flow analysis carried out using phase contrast cardiac magnetic resonance imaging (PC-CMR) enables the quantification of important parameters that are used in the assessment of cardiovascular function. An essential part of this analysis is the identification of the correct CMR views and quality control (QC) to detect artefacts that could affect the flow quantification. We propose a novel deep learning based framework for the fully-automated analysis of flow from full CMR scans that first carries out these view selection and QC steps using two sequential convolutional neural networks, followed by automatic aorta and pulmonary artery segmentation to enable the quantification of key flow parameters. Accuracy values of 0.958 and 0.914 were obtained for view classification and QC, respectively. For segmentation, Dice scores were $>$0.969 and the Bland-Altman plots indicated excellent agreement between manual and automatic peak flow values. In addition, we tested our pipeline on an external validation data set, with results indicating good robustness of the pipeline. This work was carried out using multivendor clinical data consisting of 986 cases, indicating the potential for the use of this pipeline in a clinical setting.
A systematic study of race and sex bias in CNN-based cardiac MR segmentation
Sep 04, 2022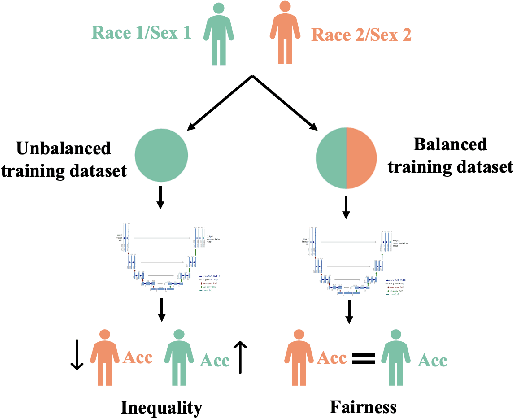
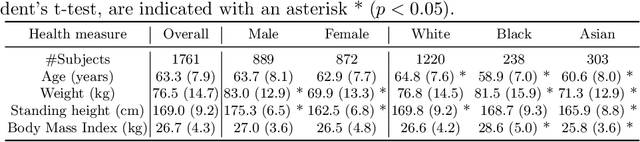
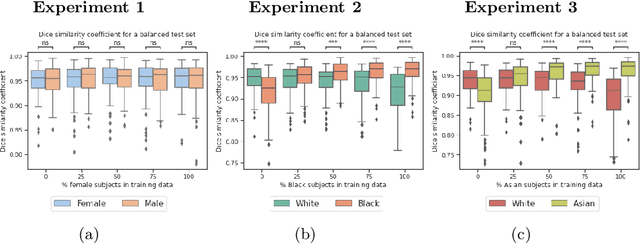
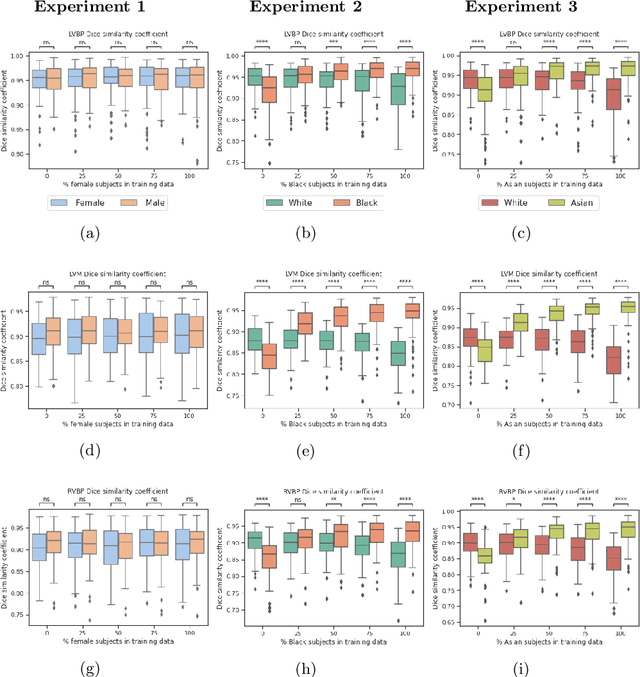
In computer vision there has been significant research interest in assessing potential demographic bias in deep learning models. One of the main causes of such bias is imbalance in the training data. In medical imaging, where the potential impact of bias is arguably much greater, there has been less interest. In medical imaging pipelines, segmentation of structures of interest plays an important role in estimating clinical biomarkers that are subsequently used to inform patient management. Convolutional neural networks (CNNs) are starting to be used to automate this process. We present the first systematic study of the impact of training set imbalance on race and sex bias in CNN-based segmentation. We focus on segmentation of the structures of the heart from short axis cine cardiac magnetic resonance images, and train multiple CNN segmentation models with different levels of race/sex imbalance. We find no significant bias in the sex experiment but significant bias in two separate race experiments, highlighting the need to consider adequate representation of different demographic groups in health datasets.
A Study of Demographic Bias in CNN-based Brain MR Segmentation
Aug 13, 2022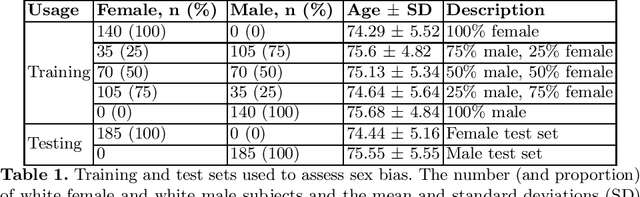
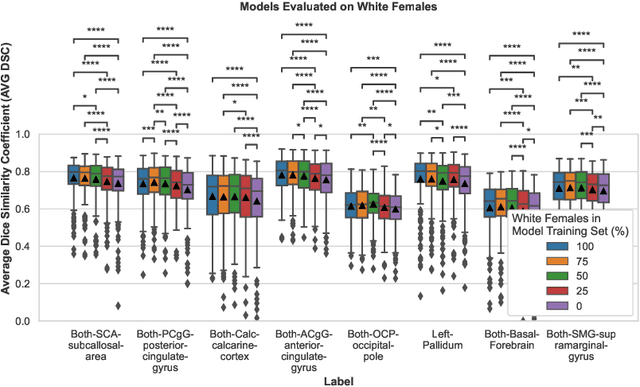
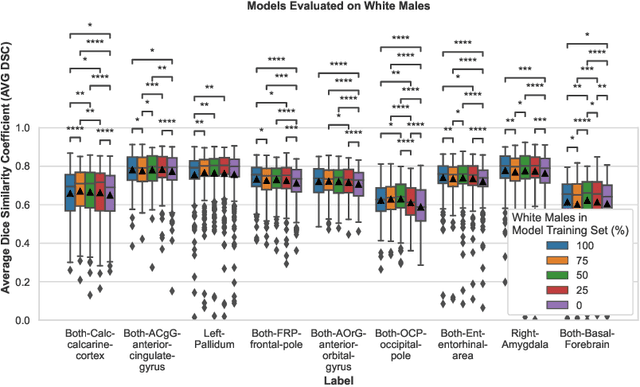
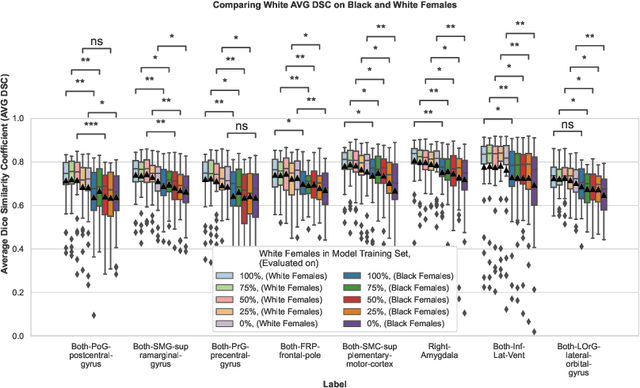
Convolutional neural networks (CNNs) are increasingly being used to automate the segmentation of brain structures in magnetic resonance (MR) images for research studies. In other applications, CNN models have been shown to exhibit bias against certain demographic groups when they are under-represented in the training sets. In this work, we investigate whether CNN models for brain MR segmentation have the potential to contain sex or race bias when trained with imbalanced training sets. We train multiple instances of the FastSurferCNN model using different levels of sex imbalance in white subjects. We evaluate the performance of these models separately for white male and white female test sets to assess sex bias, and furthermore evaluate them on black male and black female test sets to assess potential racial bias. We find significant sex and race bias effects in segmentation model performance. The biases have a strong spatial component, with some brain regions exhibiting much stronger bias than others. Overall, our results suggest that race bias is more significant than sex bias. Our study demonstrates the importance of considering race and sex balance when forming training sets for CNN-based brain MR segmentation, to avoid maintaining or even exacerbating existing health inequalities through biased research study findings.
Deep Learning-based Segmentation of Pleural Effusion From Ultrasound Using Coordinate Convolutions
Aug 05, 2022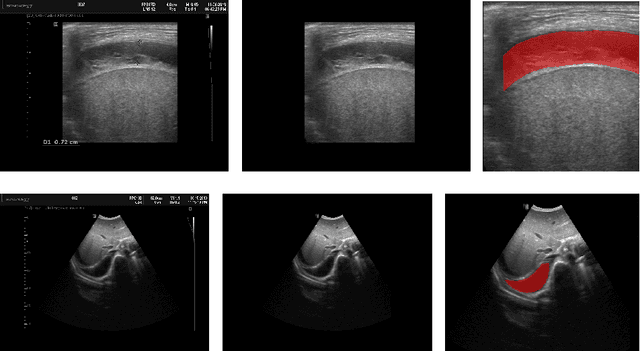


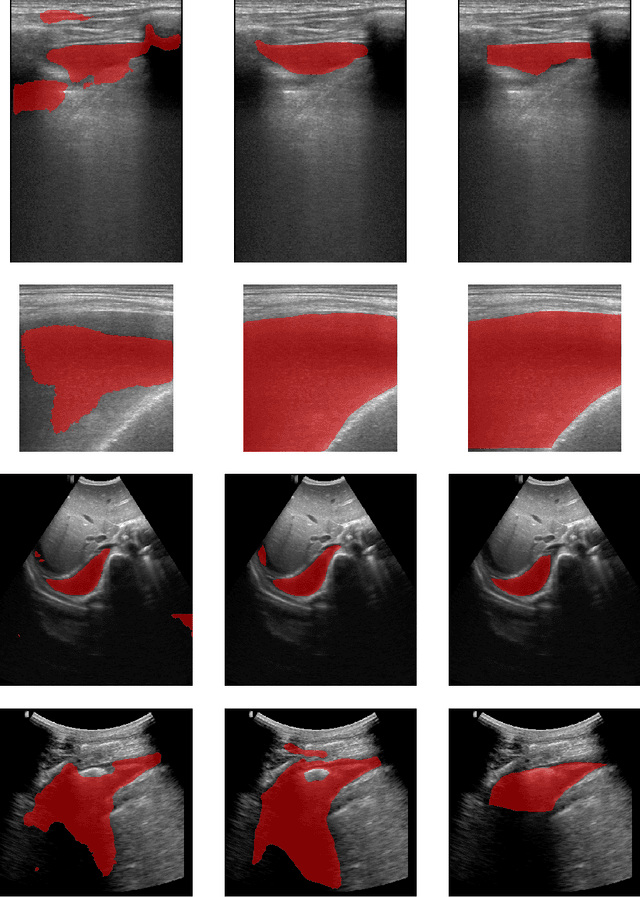
In many low-to-middle income (LMIC) countries, ultrasound is used for assessment of pleural effusion. Typically, the extent of the effusion is manually measured by a sonographer, leading to significant intra-/inter-observer variability. In this work, we investigate the use of deep learning (DL) to automate the process of pleural effusion segmentation from ultrasound images. On two datasets acquired in a LMIC setting, we achieve median Dice Similarity Coefficients (DSCs) of 0.82 and 0.74 respectively using the nnU-net DL model. We also investigate the use of coordinate convolutions in the DL model and find that this results in a statistically significant improvement in the median DSC on the first dataset to 0.85, with no significant change on the second dataset. This work showcases, for the first time, the potential of DL in automating the process of effusion assessment from ultrasound in LMIC settings where there is often a lack of experienced radiologists to perform such tasks.
A Deep Learning-based Integrated Framework for Quality-aware Undersampled Cine Cardiac MRI Reconstruction and Analysis
May 02, 2022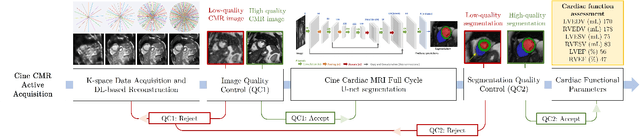

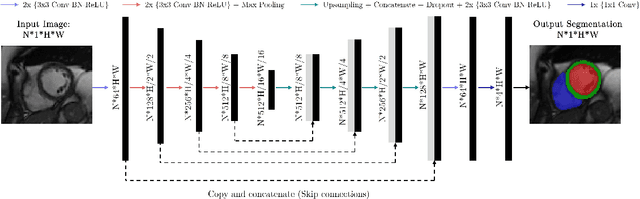
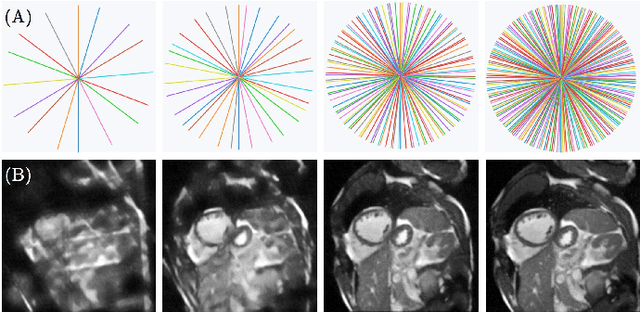
Cine cardiac magnetic resonance (CMR) imaging is considered the gold standard for cardiac function evaluation. However, cine CMR acquisition is inherently slow and in recent decades considerable effort has been put into accelerating scan times without compromising image quality or the accuracy of derived results. In this paper, we present a fully-automated, quality-controlled integrated framework for reconstruction, segmentation and downstream analysis of undersampled cine CMR data. The framework enables active acquisition of radial k-space data, in which acquisition can be stopped as soon as acquired data are sufficient to produce high quality reconstructions and segmentations. This results in reduced scan times and automated analysis, enabling robust and accurate estimation of functional biomarkers. To demonstrate the feasibility of the proposed approach, we perform realistic simulations of radial k-space acquisitions on a dataset of subjects from the UK Biobank and present results on in-vivo cine CMR k-space data collected from healthy subjects. The results demonstrate that our method can produce quality-controlled images in a mean scan time reduced from 12 to 4 seconds per slice, and that image quality is sufficient to allow clinically relevant parameters to be automatically estimated to within 5% mean absolute difference.
AI-enabled Assessment of Cardiac Systolic and Diastolic Function from Echocardiography
Mar 21, 2022
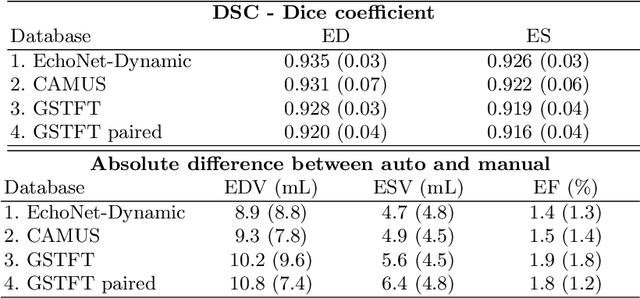
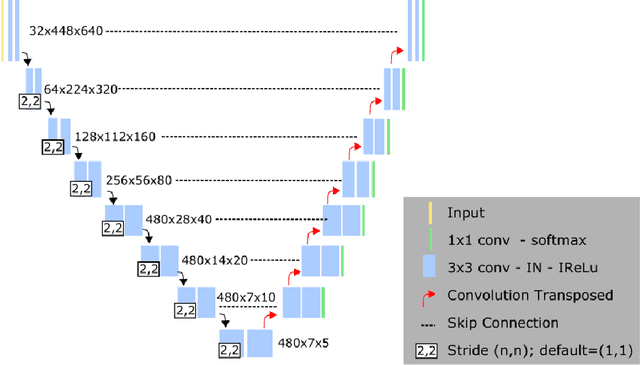

Left ventricular (LV) function is an important factor in terms of patient management, outcome, and long-term survival of patients with heart disease. The most recently published clinical guidelines for heart failure recognise that over reliance on only one measure of cardiac function (LV ejection fraction) as a diagnostic and treatment stratification biomarker is suboptimal. Recent advances in AI-based echocardiography analysis have shown excellent results on automated estimation of LV volumes and LV ejection fraction. However, from time-varying 2-D echocardiography acquisition, a richer description of cardiac function can be obtained by estimating functional biomarkers from the complete cardiac cycle. In this work we propose for the first time an AI approach for deriving advanced biomarkers of systolic and diastolic LV function from 2-D echocardiography based on segmentations of the full cardiac cycle. These biomarkers will allow clinicians to obtain a much richer picture of the heart in health and disease. The AI model is based on the 'nn-Unet' framework and was trained and tested using four different databases. Results show excellent agreement between manual and automated analysis and showcase the potential of the advanced systolic and diastolic biomarkers for patient stratification. Finally, for a subset of 50 cases, we perform a correlation analysis between clinical biomarkers derived from echocardiography and CMR and we show excellent agreement between the two modalities.
The Impact of Domain Shift on Left and Right Ventricle Segmentation in Short Axis Cardiac MR Images
Sep 22, 2021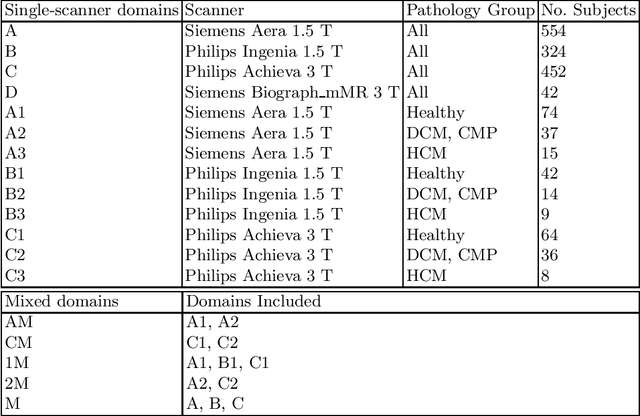
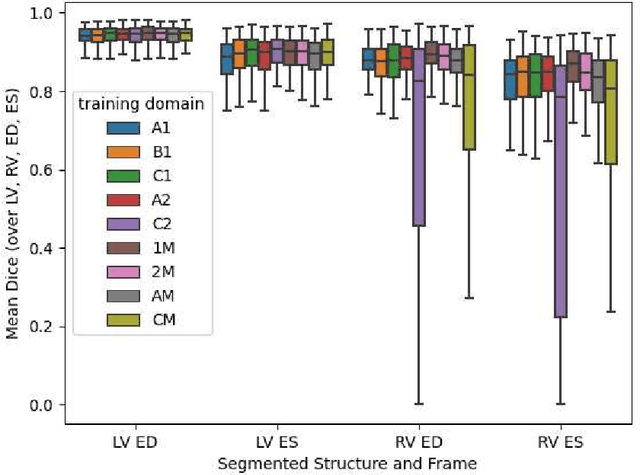
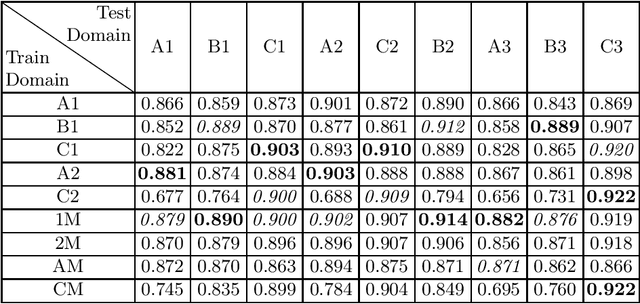
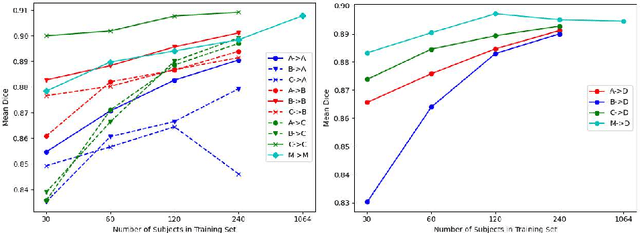
Domain shift refers to the difference in the data distribution of two datasets, normally between the training set and the test set for machine learning algorithms. Domain shift is a serious problem for generalization of machine learning models and it is well-established that a domain shift between the training and test sets may cause a drastic drop in the model's performance. In medical imaging, there can be many sources of domain shift such as different scanners or scan protocols, different pathologies in the patient population, anatomical differences in the patient population (e.g. men vs women) etc. Therefore, in order to train models that have good generalization performance, it is important to be aware of the domain shift problem, its potential causes and to devise ways to address it. In this paper, we study the effect of domain shift on left and right ventricle blood pool segmentation in short axis cardiac MR images. Our dataset contains short axis images from 4 different MR scanners and 3 different pathology groups. The training is performed with nnUNet. The results show that scanner differences cause a greater drop in performance compared to changing the pathology group, and that the impact of domain shift is greater on right ventricle segmentation compared to left ventricle segmentation. Increasing the number of training subjects increased cross-scanner performance more than in-scanner performance at small training set sizes, but this difference in improvement decreased with larger training set sizes. Training models using data from multiple scanners improved cross-domain performance.
Uncertainty-Aware Training for Cardiac Resynchronisation Therapy Response Prediction
Sep 22, 2021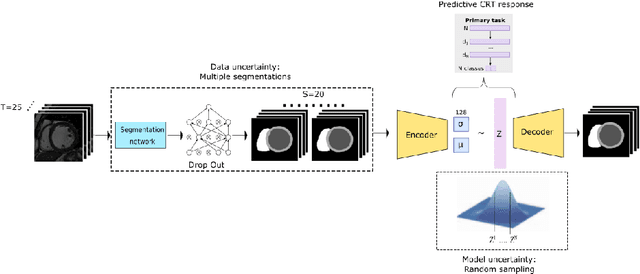
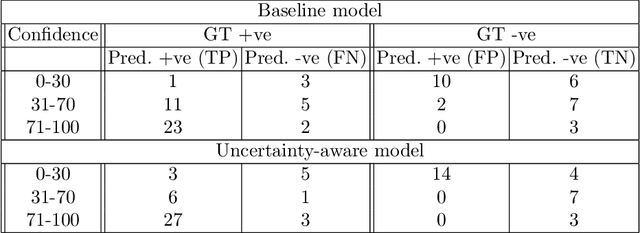
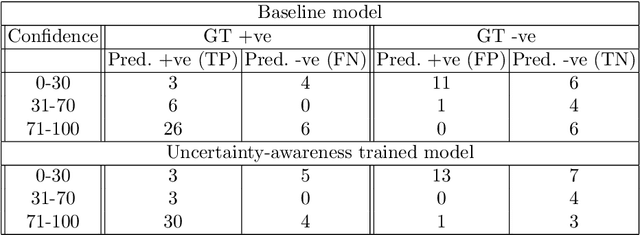
Evaluation of predictive deep learning (DL) models beyond conventional performance metrics has become increasingly important for applications in sensitive environments like healthcare. Such models might have the capability to encode and analyse large sets of data but they often lack comprehensive interpretability methods, preventing clinical trust in predictive outcomes. Quantifying uncertainty of a prediction is one way to provide such interpretability and promote trust. However, relatively little attention has been paid to how to include such requirements into the training of the model. In this paper we: (i) quantify the data (aleatoric) and model (epistemic) uncertainty of a DL model for Cardiac Resynchronisation Therapy response prediction from cardiac magnetic resonance images, and (ii) propose and perform a preliminary investigation of an uncertainty-aware loss function that can be used to retrain an existing DL image-based classification model to encourage confidence in correct predictions and reduce confidence in incorrect predictions. Our initial results are promising, showing a significant increase in the (epistemic) confidence of true positive predictions, with some evidence of a reduction in false negative confidence.
Improved AI-based segmentation of apical and basal slices from clinical cine CMR
Sep 20, 2021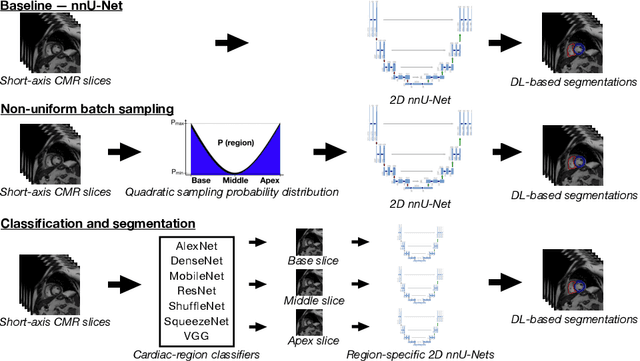
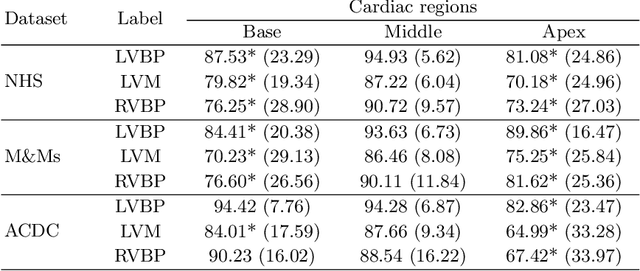
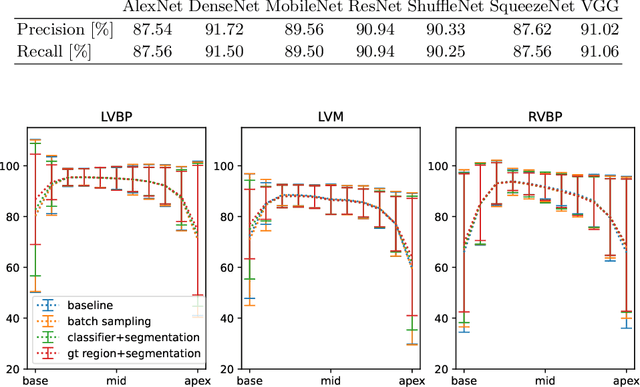
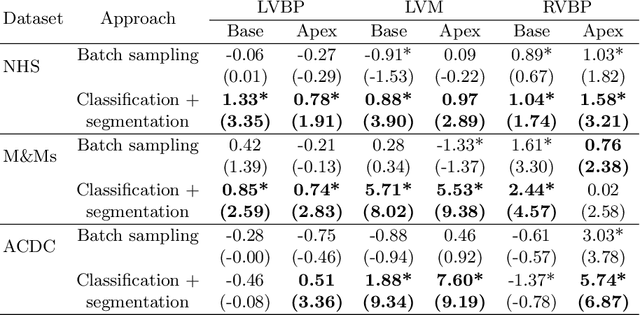
Current artificial intelligence (AI) algorithms for short-axis cardiac magnetic resonance (CMR) segmentation achieve human performance for slices situated in the middle of the heart. However, an often-overlooked fact is that segmentation of the basal and apical slices is more difficult. During manual analysis, differences in the basal segmentations have been reported as one of the major sources of disagreement in human interobserver variability. In this work, we aim to investigate the performance of AI algorithms in segmenting basal and apical slices and design strategies to improve their segmentation. We trained all our models on a large dataset of clinical CMR studies obtained from two NHS hospitals (n=4,228) and evaluated them against two external datasets: ACDC (n=100) and M&Ms (n=321). Using manual segmentations as a reference, CMR slices were assigned to one of four regions: non-cardiac, base, middle, and apex. Using the nnU-Net framework as a baseline, we investigated two different approaches to reduce the segmentation performance gap between cardiac regions: (1) non-uniform batch sampling, which allows us to choose how often images from different regions are seen during training; and (2) a cardiac-region classification model followed by three (i.e. base, middle, and apex) region-specific segmentation models. We show that the classification and segmentation approach was best at reducing the performance gap across all datasets. We also show that improvements in the classification performance can subsequently lead to a significantly better performance in the segmentation task.
Quality-aware Cine Cardiac MRI Reconstruction and Analysis from Undersampled k-space Data
Sep 16, 2021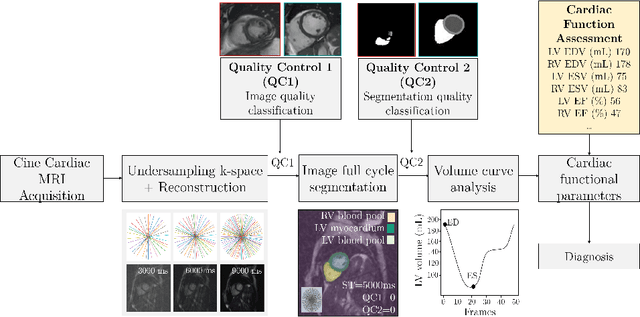
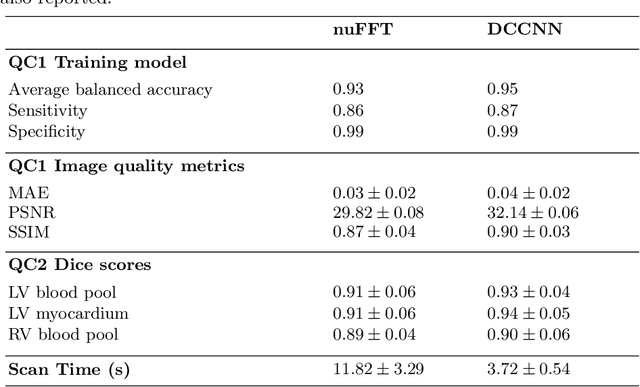
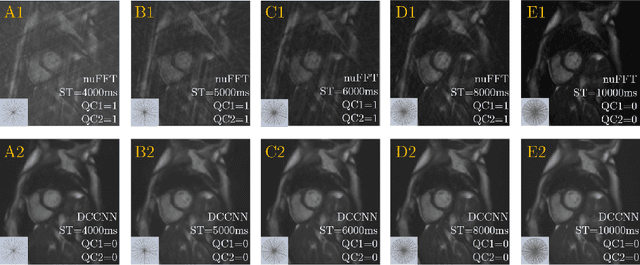
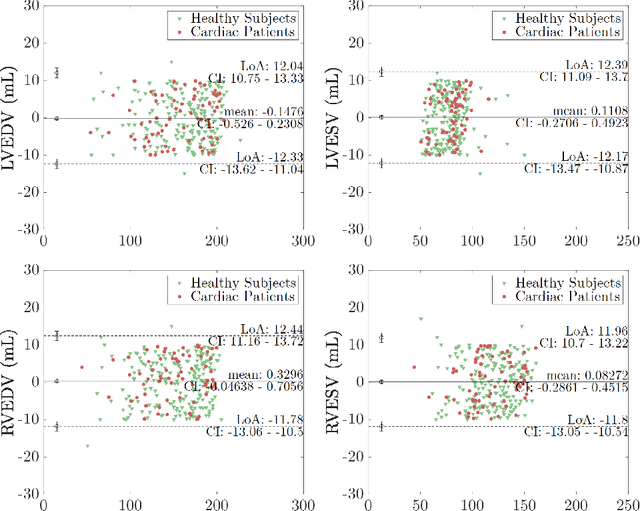
Cine cardiac MRI is routinely acquired for the assessment of cardiac health, but the imaging process is slow and typically requires several breath-holds to acquire sufficient k-space profiles to ensure good image quality. Several undersampling-based reconstruction techniques have been proposed during the last decades to speed up cine cardiac MRI acquisition. However, the undersampling factor is commonly fixed to conservative values before acquisition to ensure diagnostic image quality, potentially leading to unnecessarily long scan times. In this paper, we propose an end-to-end quality-aware cine short-axis cardiac MRI framework that combines image acquisition and reconstruction with downstream tasks such as segmentation, volume curve analysis and estimation of cardiac functional parameters. The goal is to reduce scan time by acquiring only a fraction of k-space data to enable the reconstruction of images that can pass quality control checks and produce reliable estimates of cardiac functional parameters. The framework consists of a deep learning model for the reconstruction of 2D+t cardiac cine MRI images from undersampled data, an image quality-control step to detect good quality reconstructions, followed by a deep learning model for bi-ventricular segmentation, a quality-control step to detect good quality segmentations and automated calculation of cardiac functional parameters. To demonstrate the feasibility of the proposed approach, we perform simulations using a cohort of selected participants from the UK Biobank (n=270), 200 healthy subjects and 70 patients with cardiomyopathies. Our results show that we can produce quality-controlled images in a scan time reduced from 12 to 4 seconds per slice, enabling reliable estimates of cardiac functional parameters such as ejection fraction within 5% mean absolute error.