 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Text in Hyperbolic Spaces
Jun 12, 2018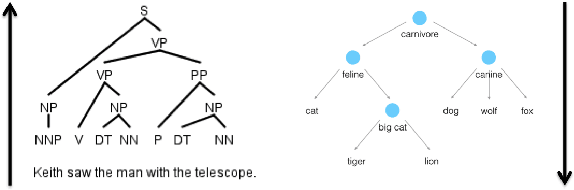
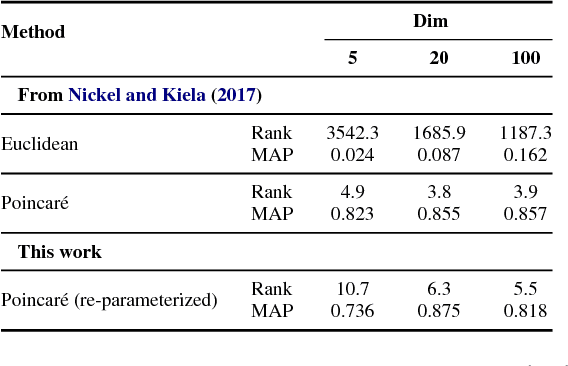
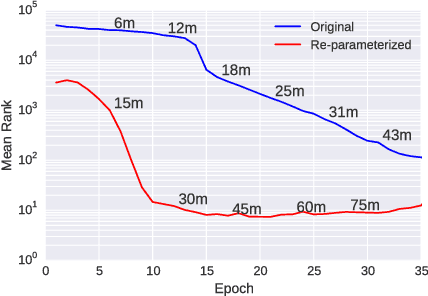

Natural language text exhibits hierarchical structure in a variety of respects. Ideally, we could incorporate our prior knowledge of this hierarchical structure into unsupervised learning algorithms that work on text data. Recent work by Nickel & Kiela (2017) proposed using hyperbolic instead of Euclidean embedding spaces to represent hierarchical data and demonstrated encouraging results when embedding graphs. In this work, we extend their method with a re-parameterization technique that allows us to learn hyperbolic embeddings of arbitrarily parameterized objects. We apply this framework to learn word and sentence embeddings in hyperbolic space in an unsupervised manner from text corpora. The resulting embeddings seem to encode certain intuitive notions of hierarchy, such as word-context frequency and phrase constituency. However, the implicit continuous hierarchy in the learned hyperbolic space makes interrogating the model's learned hierarchies more difficult than for models that learn explicit edges between items. The learned hyperbolic embeddings show improvements over Euclidean embeddings in some -- but not all -- downstream tasks, suggesting that hierarchical organization is more useful for some tasks than others.
Scalable and accurate deep learning for electronic health records
May 11, 2018
Predictive modeling with electronic health record (EHR) data is anticipated to drive personalized medicine and improve healthcare quality. Constructing predictive statistical models typically requires extraction of curated predictor variables from normalized EHR data, a labor-intensive process that discards the vast majority of information in each patient's record. We propose a representation of patients' entire, raw EHR records based on the Fast Healthcare Interoperability Resources (FHIR) format. We demonstrate that deep learning methods using this representation are capable of accurately predicting multiple medical events from multiple centers without site-specific data harmonization. We validated our approach using de-identified EHR data from two U.S. academic medical centers with 216,221 adult patients hospitalized for at least 24 hours. In the sequential format we propose, this volume of EHR data unrolled into a total of 46,864,534,945 data points, including clinical notes. Deep learning models achieved high accuracy for tasks such as predicting in-hospital mortality (AUROC across sites 0.93-0.94), 30-day unplanned readmission (AUROC 0.75-0.76), prolonged length of stay (AUROC 0.85-0.86), and all of a patient's final discharge diagnoses (frequency-weighted AUROC 0.90). These models outperformed state-of-the-art traditional predictive models in all cases. We also present a case-study of a neural-network attribution system, which illustrates how clinicians can gain some transparency into the predictions. We believe that this approach can be used to create accurate and scalable predictions for a variety of clinical scenarios, complete with explanations that directly highlight evidence in the patient's chart.
* Published version from https://www.nature.com/articles/s41746-018-0029-1
MaskGAN: Better Text Generation via Filling in the______
Mar 01, 2018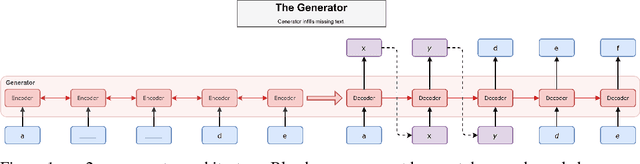

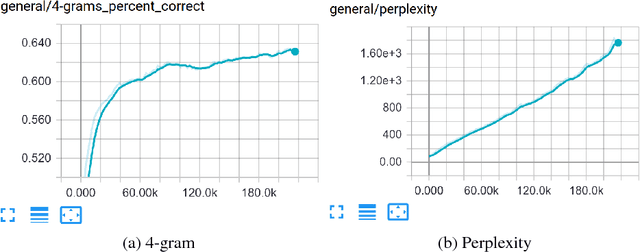

Neural text generation models are often autoregressive language models or seq2seq models. These models generate text by sampling words sequentially, with each word conditioned on the previous word, and are state-of-the-art for several machine translation and summarization benchmarks. These benchmarks are often defined by validation perplexity even though this is not a direct measure of the quality of the generated text. Additionally, these models are typically trained via maxi- mum likelihood and teacher forcing. These methods are well-suited to optimizing perplexity but can result in poor sample quality since generating text requires conditioning on sequences of words that may have never been observed at training time. We propose to improve sample quality using Generative Adversarial Networks (GANs), which explicitly train the generator to produce high quality samples and have shown a lot of success in image generation. GANs were originally designed to output differentiable values, so discrete language generation is challenging for them. We claim that validation perplexity alone is not indicative of the quality of text generated by a model. We introduce an actor-critic conditional GAN that fills in missing text conditioned on the surrounding context. We show qualitatively and quantitatively, evidence that this produces more realistic conditional and unconditional text samples compared to a maximum likelihood trained model.
Many Paths to Equilibrium: GANs Do Not Need to Decrease a Divergence At Every Step
Feb 20, 2018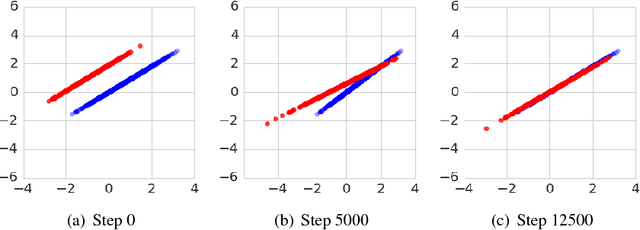
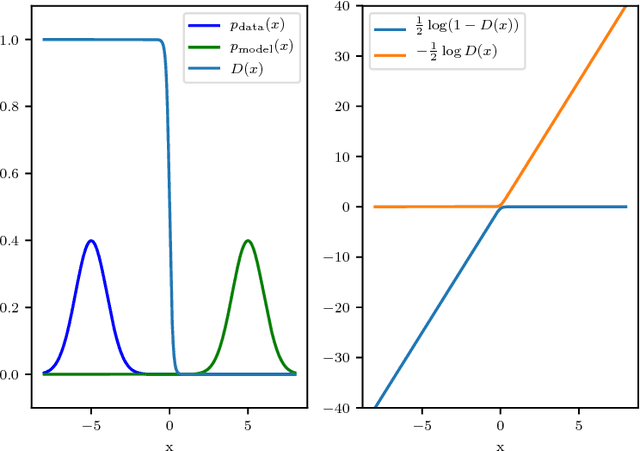
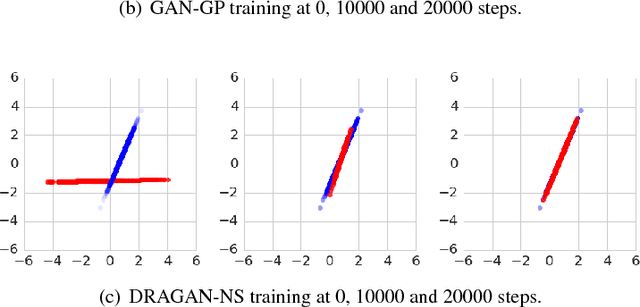
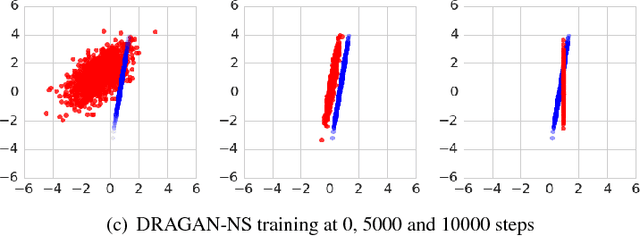
Generative adversarial networks (GANs) are a family of generative models that do not minimize a single training criterion. Unlike other generative models, the data distribution is learned via a game between a generator (the generative model) and a discriminator (a teacher providing training signal) that each minimize their own cost. GANs are designed to reach a Nash equilibrium at which each player cannot reduce their cost without changing the other players' parameters. One useful approach for the theory of GANs is to show that a divergence between the training distribution and the model distribution obtains its minimum value at equilibrium. Several recent research directions have been motivated by the idea that this divergence is the primary guide for the learning process and that every step of learning should decrease the divergence. We show that this view is overly restrictive. During GAN training, the discriminator provides learning signal in situations where the gradients of the divergences between distributions would not be useful. We provide empirical counterexamples to the view of GAN training as divergence minimization. Specifically, we demonstrate that GANs are able to learn distributions in situations where the divergence minimization point of view predicts they would fail. We also show that gradient penalties motivated from the divergence minimization perspective are equally helpful when applied in other contexts in which the divergence minimization perspective does not predict they would be helpful. This contributes to a growing body of evidence that GAN training may be more usefully viewed as approaching Nash equilibria via trajectories that do not necessarily minimize a specific divergence at each step.
Who Said What: Modeling Individual Labelers Improves Classification
Jan 04, 2018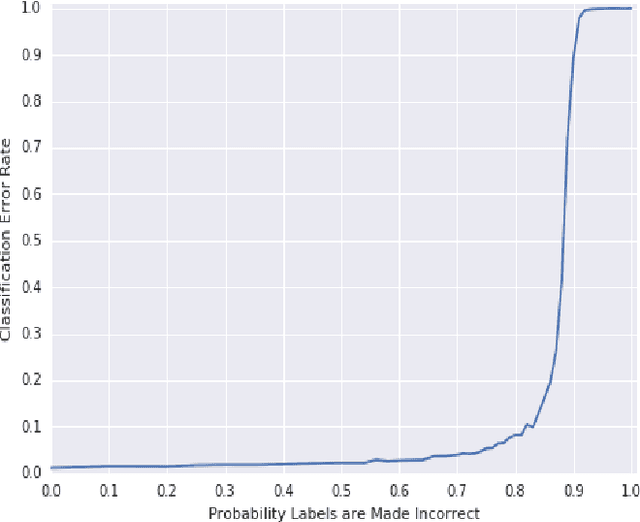
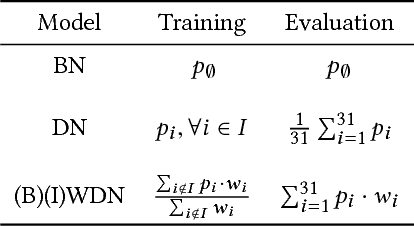
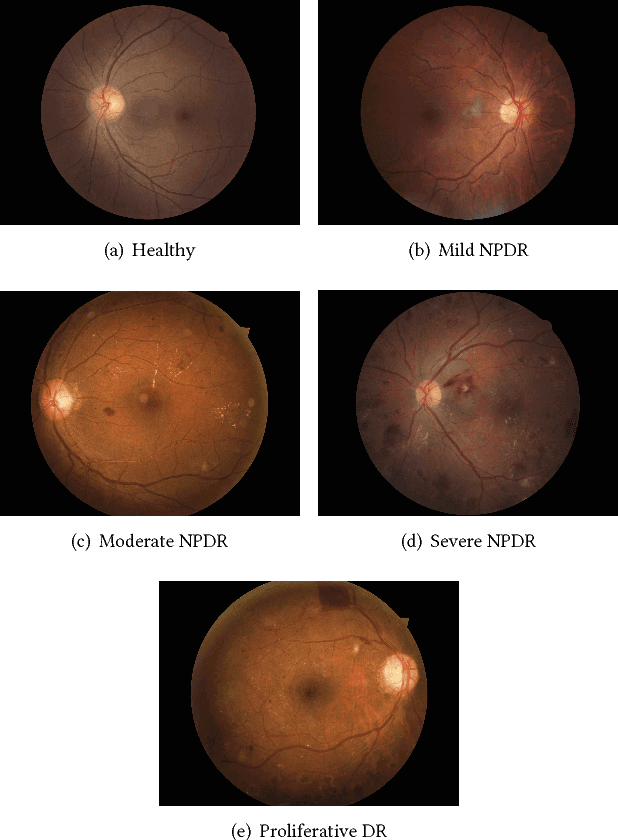
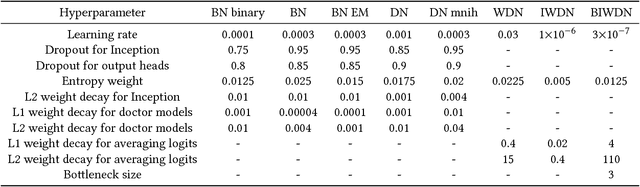
Data are often labeled by many different experts with each expert only labeling a small fraction of the data and each data point being labeled by several experts. This reduces the workload on individual experts and also gives a better estimate of the unobserved ground truth. When experts disagree, the standard approaches are to treat the majority opinion as the correct label or to model the correct label as a distribution. These approaches, however, do not make any use of potentially valuable information about which expert produced which label. To make use of this extra information, we propose modeling the experts individually and then learning averaging weights for combining them, possibly in sample-specific ways. This allows us to give more weight to more reliable experts and take advantage of the unique strengths of individual experts at classifying certain types of data. Here we show that our approach leads to improvements in computer-aided diagnosis of diabetic retinopathy. We also show that our method performs better than competing algorithms by Welinder and Perona (2010), and by Mnih and Hinton (2012). Our work offers an innovative approach for dealing with the myriad real-world settings that use expert opinions to define labels for training.
Adversarial Training Methods for Semi-Supervised Text Classification
May 06, 2017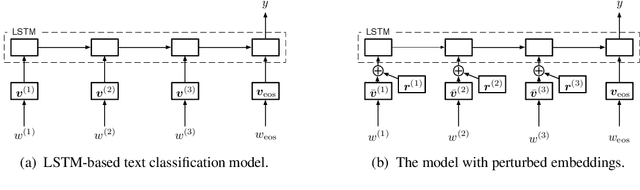
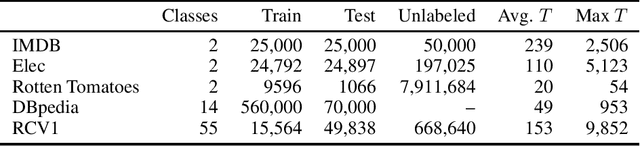
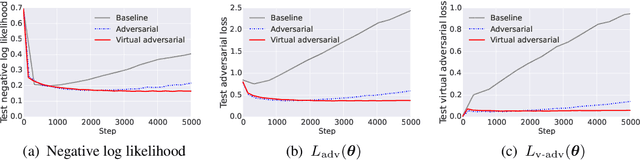

Adversarial training provides a means of regularizing supervised learning algorithms while virtual adversarial training is able to extend supervised learning algorithms to the semi-supervised setting. However, both methods require making small perturbations to numerous entries of the input vector, which is inappropriate for sparse high-dimensional inputs such as one-hot word representations. We extend adversarial and virtual adversarial training to the text domain by applying perturbations to the word embeddings in a recurrent neural network rather than to the original input itself. The proposed method achieves state of the art results on multiple benchmark semi-supervised and purely supervised tasks. We provide visualizations and analysis showing that the learned word embeddings have improved in quality and that while training, the model is less prone to overfitting.
Generating Sentences from a Continuous Space
May 12, 2016
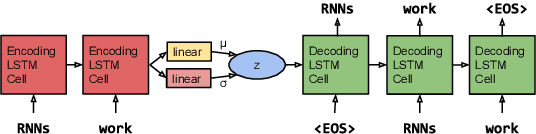
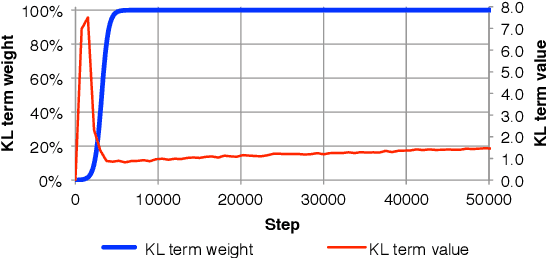

The standard recurrent neural network language model (RNNLM) generates sentences one word at a time and does not work from an explicit global sentence representation. In this work, we introduce and study an RNN-based variational autoencoder generative model that incorporates distributed latent representations of entire sentences. This factorization allows it to explicitly model holistic properties of sentences such as style, topic, and high-level syntactic features. Samples from the prior over these sentence representations remarkably produce diverse and well-formed sentences through simple deterministic decoding. By examining paths through this latent space, we are able to generate coherent novel sentences that interpolate between known sentences. We present techniques for solving the difficult learning problem presented by this model, demonstrate its effectiveness in imputing missing words, explore many interesting properties of the model's latent sentence space, and present negative results on the use of the model in language modeling.
* First two authors contributed equally. Work was done when all authors were at Google, Inc
Semi-supervised Sequence Learning
Nov 04, 2015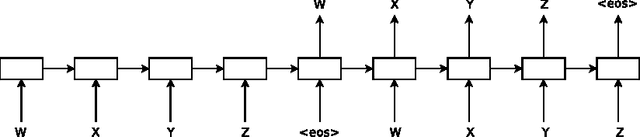



We present two approaches that use unlabeled data to improve sequence learning with recurrent networks. The first approach is to predict what comes next in a sequence, which is a conventional language model in natural language processing. The second approach is to use a sequence autoencoder, which reads the input sequence into a vector and predicts the input sequence again. These two algorithms can be used as a "pretraining" step for a later supervised sequence learning algorithm. In other words, the parameters obtained from the unsupervised step can be used as a starting point for other supervised training models. In our experiments, we find that long short term memory recurrent networks after being pretrained with the two approaches are more stable and generalize better. With pretraining, we are able to train long short term memory recurrent networks up to a few hundred timesteps, thereby achieving strong performance in many text classification tasks, such as IMDB, DBpedia and 20 Newsgroups.
Document Embedding with Paragraph Vectors
Jul 29, 2015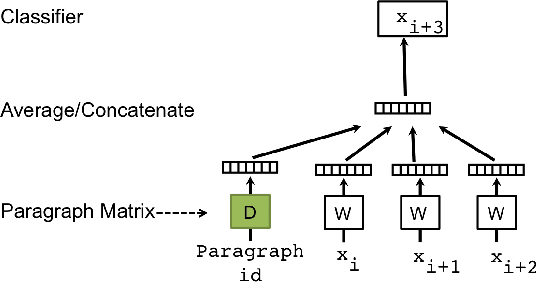
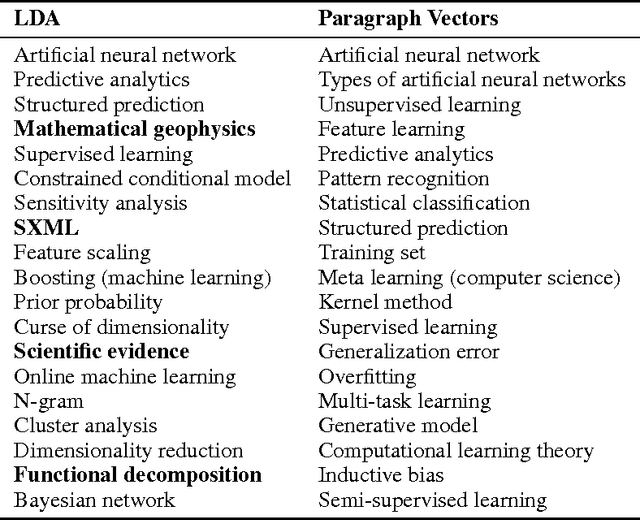
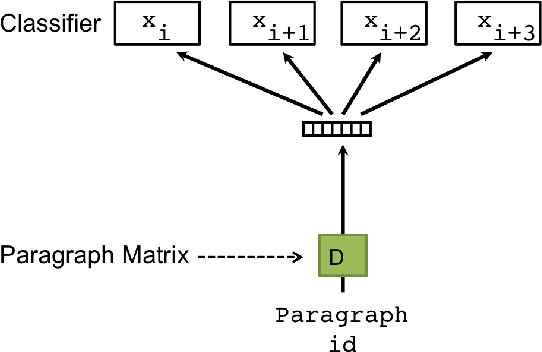
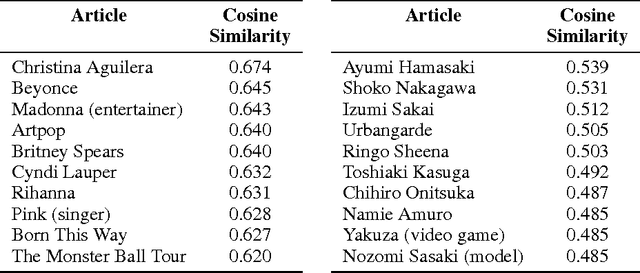
Paragraph Vectors has been recently proposed as an unsupervised method for learning distributed representations for pieces of texts. In their work, the authors showed that the method can learn an embedding of movie review texts which can be leveraged for sentiment analysis. That proof of concept, while encouraging, was rather narrow. Here we consider tasks other than sentiment analysis, provide a more thorough comparison of Paragraph Vectors to other document modelling algorithms such as Latent Dirichlet Allocation, and evaluate performance of the method as we vary the dimensionality of the learned representation. We benchmarked the models on two document similarity data sets, one from Wikipedia, one from arXiv. We observe that the Paragraph Vector method performs significantly better than other methods, and propose a simple improvement to enhance embedding quality. Somewhat surprisingly, we also show that much like word embeddings, vector operations on Paragraph Vectors can perform useful semantic results.
The supervised hierarchical Dirichlet process
Dec 17, 2014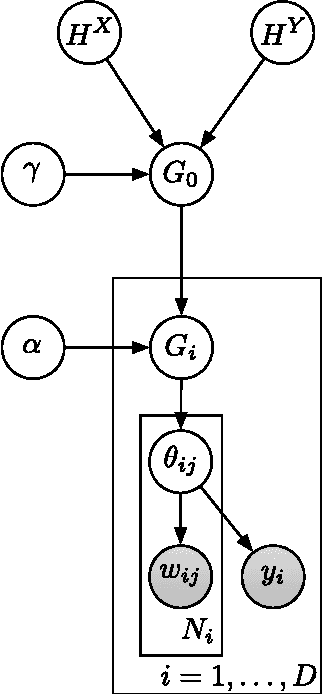

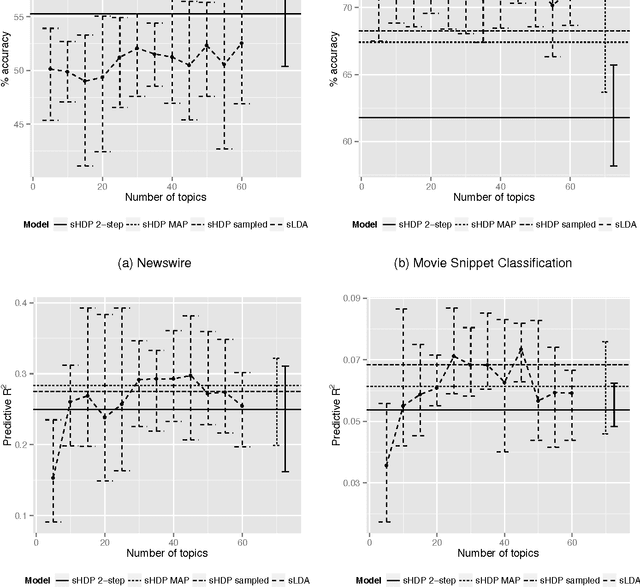

We propose the supervised hierarchical Dirichlet process (sHDP), a nonparametric generative model for the joint distribution of a group of observations and a response variable directly associated with that whole group. We compare the sHDP with another leading method for regression on grouped data, the supervised latent Dirichlet allocation (sLDA) model. We evaluate our method on two real-world classification problems and two real-world regression problems. Bayesian nonparametric regression models based on the Dirichlet process, such as the Dirichlet process-generalised linear models (DP-GLM) have previously been explored; these models allow flexibility in modelling nonlinear relationships. However, until now, Hierarchical Dirichlet Process (HDP) mixtures have not seen significant use in supervised problems with grouped data since a straightforward application of the HDP on the grouped data results in learnt clusters that are not predictive of the responses. The sHDP solves this problem by allowing for clusters to be learnt jointly from the group structure and from the label assigned to each group.