 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Incremental Learning with Pre-trained Vision-Language Models
Oct 31, 2023



With the advent of large-scale pre-trained models, interest in adapting and exploiting them for continual learning scenarios has grown. In this paper, we propose an approach to exploiting pre-trained vision-language models (e.g. CLIP) that enables further adaptation instead of only using zero-shot learning of new tasks. We augment a pre-trained CLIP model with additional layers after the Image Encoder or before the Text Encoder. We investigate three different strategies: a Linear Adapter, a Self-attention Adapter, each operating on the image embedding, and Prompt Tuning which instead modifies prompts input to the CLIP text encoder. We also propose a method for parameter retention in the adapter layers that uses a measure of parameter importance to better maintain stability and plasticity during incremental learning. Our experiments demonstrate that the simplest solution -- a single Linear Adapter layer with parameter retention -- produces the best results. Experiments on several conventional benchmarks consistently show a significant margin of improvement over the current state-of-the-art.
Masked Autoencoders are Efficient Class Incremental Learners
Aug 24, 2023



Class Incremental Learning (CIL) aims to sequentially learn new classes while avoiding catastrophic forgetting of previous knowledge. We propose to use Masked Autoencoders (MAEs) as efficient learners for CIL. MAEs were originally designed to learn useful representations through reconstructive unsupervised learning, and they can be easily integrated with a supervised loss for classification. Moreover, MAEs can reliably reconstruct original input images from randomly selected patches, which we use to store exemplars from past tasks more efficiently for CIL. We also propose a bilateral MAE framework to learn from image-level and embedding-level fusion, which produces better-quality reconstructed images and more stable representations. Our experiments confirm that our approach performs better than the state-of-the-art on CIFAR-100, ImageNet-Subset, and ImageNet-Full. The code is available at https://github.com/scok30/MAE-CIL .
Robust Saliency Guidance for Data-free Class Incremental Learning
Dec 16, 2022



Data-Free Class Incremental Learning (DFCIL) aims to sequentially learn tasks with access only to data from the current one. DFCIL is of interest because it mitigates concerns about privacy and long-term storage of data, while at the same time alleviating the problem of catastrophic forgetting in incremental learning. In this work, we introduce robust saliency guidance for DFCIL and propose a new framework, which we call RObust Saliency Supervision (ROSS), for mitigating the negative effect of saliency drift. Firstly, we use a teacher-student architecture leveraging low-level tasks to supervise the model with global saliency. We also apply boundary-guided saliency to protect it from drifting across object boundaries at intermediate layers. Finally, we introduce a module for injecting and recovering saliency noise to increase robustness of saliency preservation. Our experiments demonstrate that our method can retain better saliency maps across tasks and achieve state-of-the-art results on the CIFAR-100, Tiny-ImageNet and ImageNet-Subset DFCIL benchmarks. Code will be made publicly available.
Gated Class-Attention with Cascaded Feature Drift Compensation for Exemplar-free Continual Learning of Vision Transformers
Nov 22, 2022In this paper we propose a new method for exemplar-free class incremental training of ViTs. The main challenge of exemplar-free continual learning is maintaining plasticity of the learner without causing catastrophic forgetting of previously learned tasks. This is often achieved via exemplar replay which can help recalibrate previous task classifiers to the feature drift which occurs when learning new tasks. Exemplar replay, however, comes at the cost of retaining samples from previous tasks which for some applications may not be possible. To address the problem of continual ViT training, we first propose gated class-attention to minimize the drift in the final ViT transformer block. This mask-based gating is applied to class-attention mechanism of the last transformer block and strongly regulates the weights crucial for previous tasks. Secondly, we propose a new method of feature drift compensation that accommodates feature drift in the backbone when learning new tasks. The combination of gated class-attention and cascaded feature drift compensation allows for plasticity towards new tasks while limiting forgetting of previous ones. Extensive experiments performed on CIFAR-100, Tiny-ImageNet and ImageNet100 demonstrate that our method outperforms existing exemplar-free state-of-the-art methods without the need to store any representative exemplars of past tasks.
Long-Tailed Class Incremental Learning
Oct 01, 2022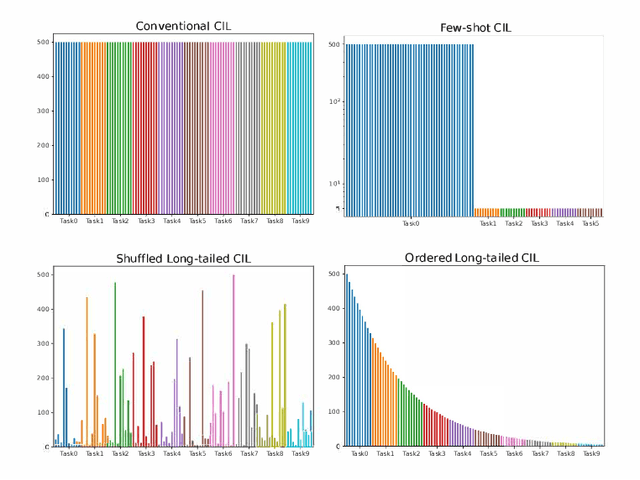
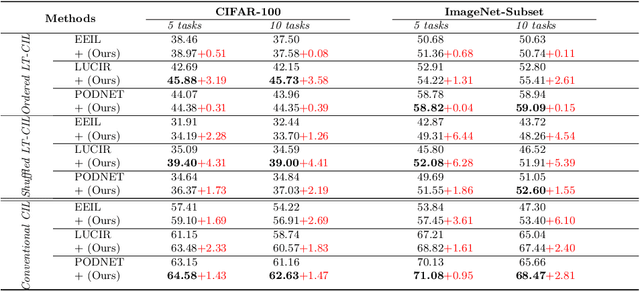
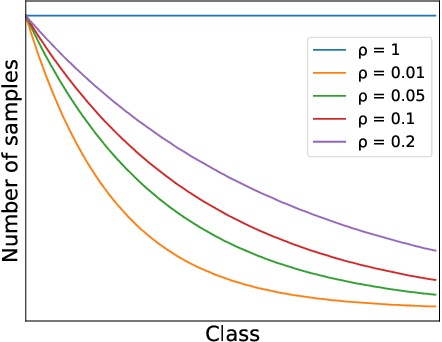
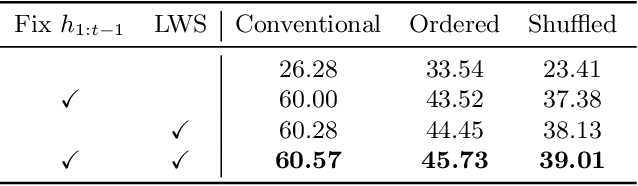
In class incremental learning (CIL) a model must learn new classes in a sequential manner without forgetting old ones. However, conventional CIL methods consider a balanced distribution for each new task, which ignores the prevalence of long-tailed distributions in the real world. In this work we propose two long-tailed CIL scenarios, which we term ordered and shuffled LT-CIL. Ordered LT-CIL considers the scenario where we learn from head classes collected with more samples than tail classes which have few. Shuffled LT-CIL, on the other hand, assumes a completely random long-tailed distribution for each task. We systematically evaluate existing methods in both LT-CIL scenarios and demonstrate very different behaviors compared to conventional CIL scenarios. Additionally, we propose a two-stage learning baseline with a learnable weight scaling layer for reducing the bias caused by long-tailed distribution in LT-CIL and which in turn also improves the performance of conventional CIL due to the limited exemplars. Our results demonstrate the superior performance (up to 6.44 points in average incremental accuracy) of our approach on CIFAR-100 and ImageNet-Subset. The code is available at https://github.com/xialeiliu/Long-Tailed-CIL
Towards Informed Design and Validation Assistance in Computer Games Using Imitation Learning
Aug 19, 2022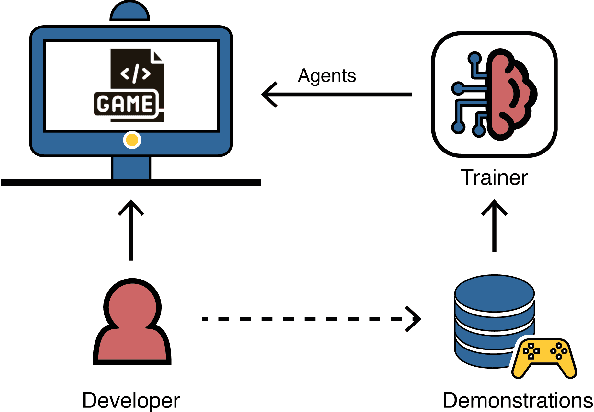

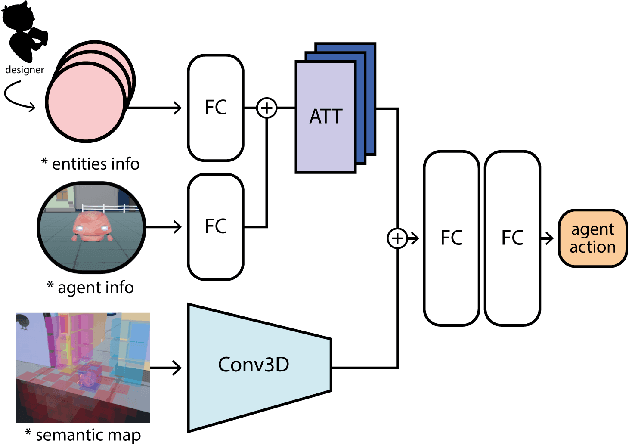
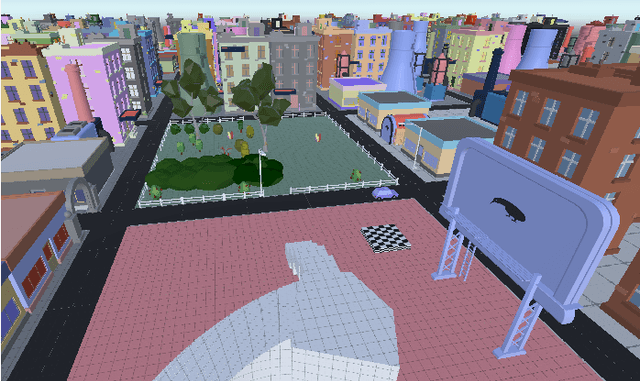
In games, as in and many other domains, design validation and testing is a huge challenge as systems are growing in size and manual testing is becoming infeasible. This paper proposes a new approach to automated game validation and testing. Our method leverages a data-driven imitation learning technique, which requires little effort and time and no knowledge of machine learning or programming, that designers can use to efficiently train game testing agents. We investigate the validity of our approach through a user study with industry experts. The survey results show that our method is indeed a valid approach to game validation and that data-driven programming would be a useful aid to reducing effort and increasing quality of modern playtesting. The survey also highlights several open challenges. With the help of the most recent literature, we analyze the identified challenges and propose future research directions suitable for supporting and maximizing the utility of our approach.
CCPT: Automatic Gameplay Testing and Validation with Curiosity-Conditioned Proximal Trajectories
Feb 21, 2022



This paper proposes a novel deep reinforcement learning algorithm to perform automatic analysis and detection of gameplay issues in complex 3D navigation environments. The Curiosity-Conditioned Proximal Trajectories (CCPT) method combines curiosity and imitation learning to train agents to methodically explore in the proximity of known trajectories derived from expert demonstrations. We show how CCPT can explore complex environments, discover gameplay issues and design oversights in the process, and recognize and highlight them directly to game designers. We further demonstrate the effectiveness of the algorithm in a novel 3D navigation environment which reflects the complexity of modern AAA video games. Our results show a higher level of coverage and bug discovery than baselines methods, and it hence can provide a valuable tool for game designers to identify issues in game design automatically.
Continually Learning Self-Supervised Representations with Projected Functional Regularization
Dec 30, 2021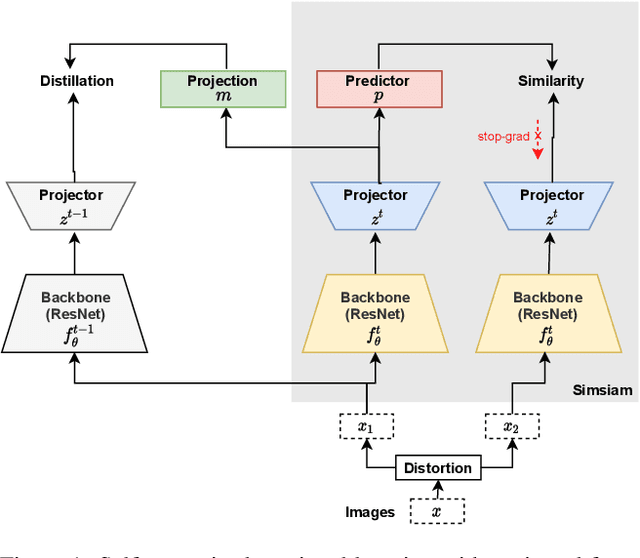
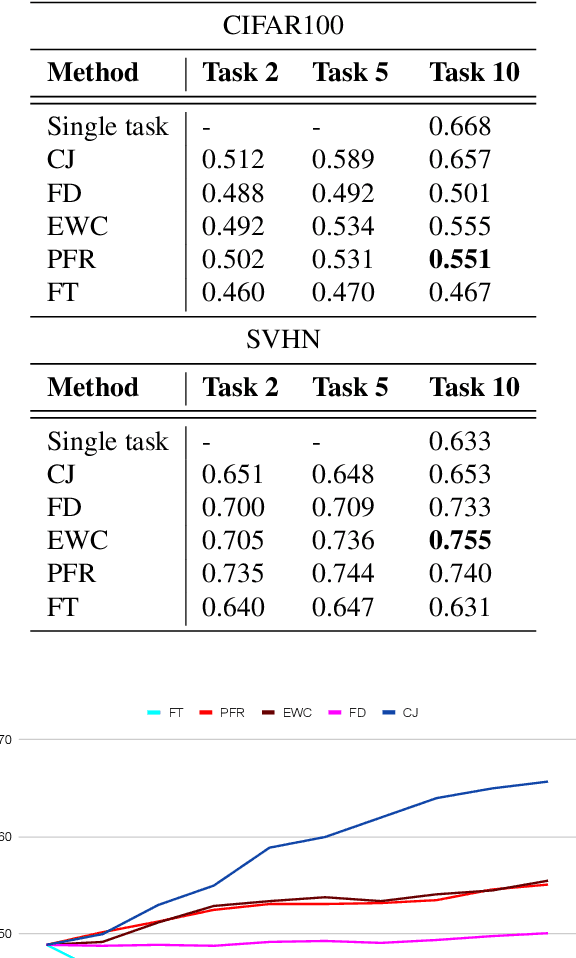
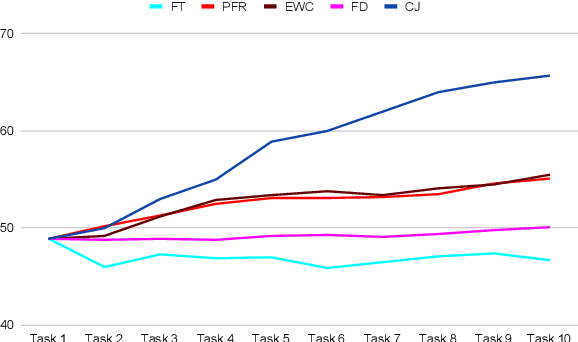
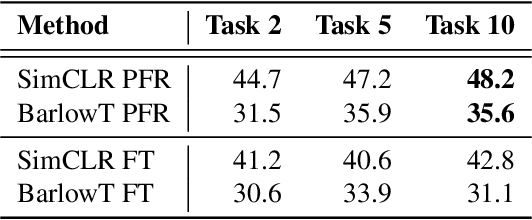
Recent self-supervised learning methods are able to learn high-quality image representations and are closing the gap with supervised methods. However, these methods are unable to acquire new knowledge incrementally -- they are, in fact, mostly used only as a pre-training phase with IID data. In this work we investigate self-supervised methods in continual learning regimes without additional memory or replay. To prevent forgetting of previous knowledge, we propose the usage of functional regularization. We will show that naive functional regularization, also known as feature distillation, leads to low plasticity and therefore seriously limits continual learning performance. To address this problem, we propose Projected Functional Regularization where a separate projection network ensures that the newly learned feature space preserves information of the previous feature space, while allowing for the learning of new features. This allows us to prevent forgetting while maintaining the plasticity of the learner. Evaluation against other incremental learning approaches applied to self-supervision demonstrates that our method obtains competitive performance in different scenarios and on multiple datasets.
Policy Fusion for Adaptive and Customizable Reinforcement Learning Agents
Apr 21, 2021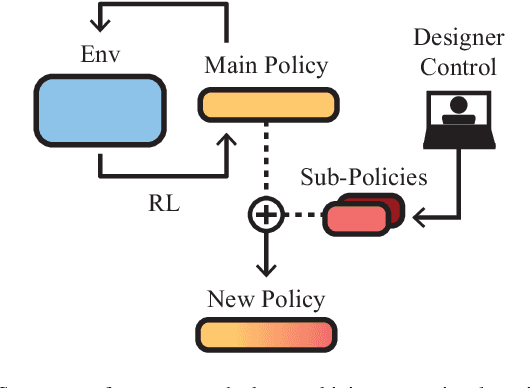
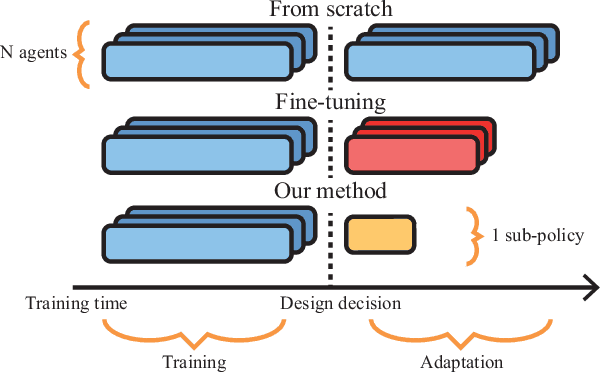
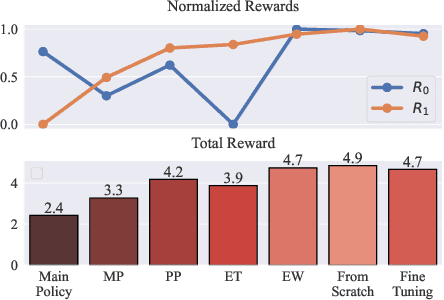
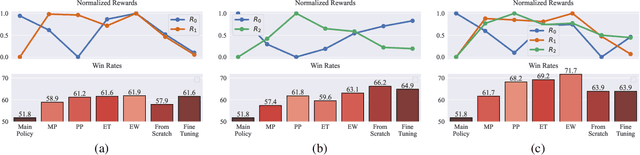
In this article we study the problem of training intelligent agents using Reinforcement Learning for the purpose of game development. Unlike systems built to replace human players and to achieve super-human performance, our agents aim to produce meaningful interactions with the player, and at the same time demonstrate behavioral traits as desired by game designers. We show how to combine distinct behavioral policies to obtain a meaningful "fusion" policy which comprises all these behaviors. To this end, we propose four different policy fusion methods for combining pre-trained policies. We further demonstrate how these methods can be used in combination with Inverse Reinforcement Learning in order to create intelligent agents with specific behavioral styles as chosen by game designers, without having to define many and possibly poorly-designed reward functions. Experiments on two different environments indicate that entropy-weighted policy fusion significantly outperforms all others. We provide several practical examples and use-cases for how these methods are indeed useful for video game production and designers.
Robust pedestrian detection in thermal imagery using synthesized images
Feb 03, 2021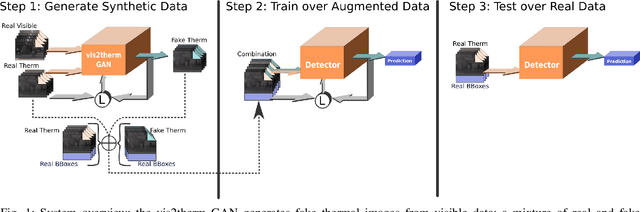
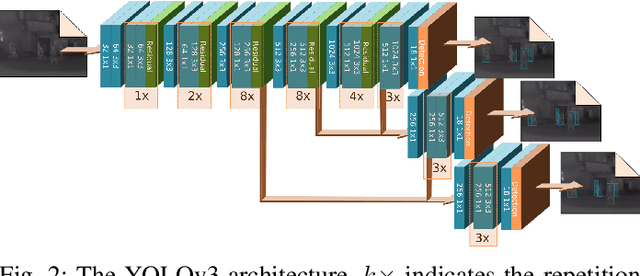
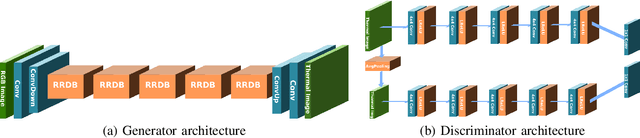
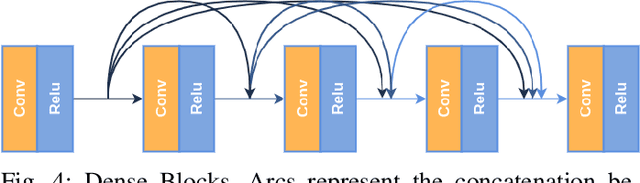
In this paper we propose a method for improving pedestrian detection in the thermal domain using two stages: first, a generative data augmentation approach is used, then a domain adaptation method using generated data adapts an RGB pedestrian detector. Our model, based on the Least-Squares Generative Adversarial Network, is trained to synthesize realistic thermal versions of input RGB images which are then used to augment the limited amount of labeled thermal pedestrian images available for training. We apply our generative data augmentation strategy in order to adapt a pretrained YOLOv3 pedestrian detector to detection in the thermal-only domain. Experimental results demonstrate the effectiveness of our approach: using less than 50\% of available real thermal training data, and relying on synthesized data generated by our model in the domain adaptation phase, our detector achieves state-of-the-art results on the KAIST Multispectral Pedestrian Detection Benchmark; even if more real thermal data is available adding GAN generated images to the training data results in improved performance, thus showing that these images act as an effective form of data augmentation. To the best of our knowledge, our detector achieves the best single-modality detection results on KAIST with respect to the state-of-the-art.