 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Regularization for Conditional Density Estimation
Jul 21, 2019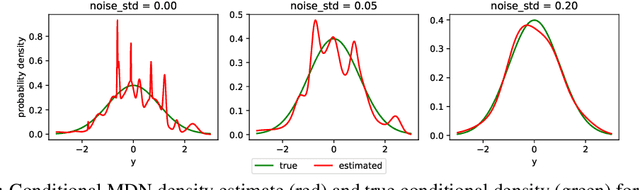
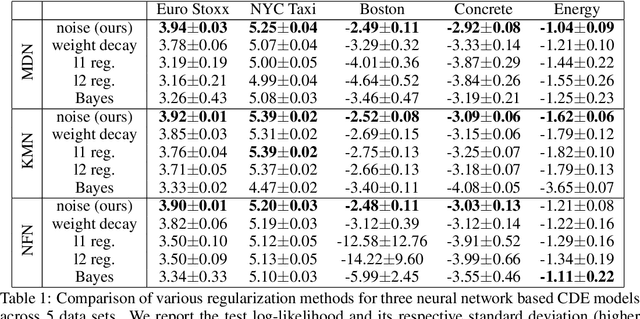
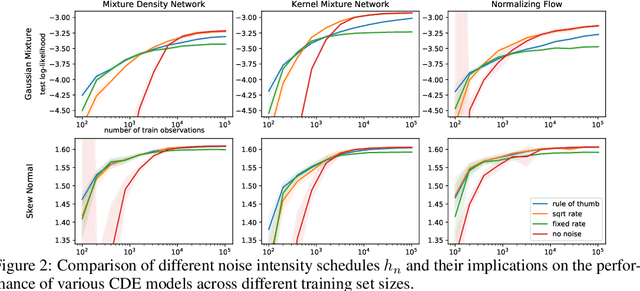
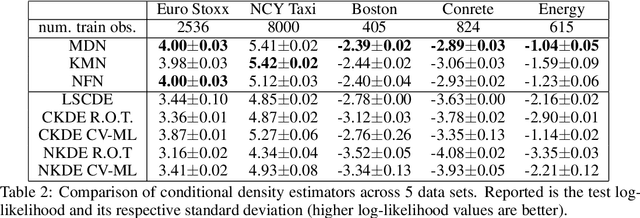
Modelling statistical relationships beyond the conditional mean is crucial in many settings. Conditional density estimation (CDE) aims to learn the full conditional probability density from data. Though highly expressive, neural network based CDE models can suffer from severe over-fitting when trained with the maximum likelihood objective. Due to the inherent structure of such models, classical regularization approaches in the parameter space are rendered ineffective. To address this issue, we develop a model-agnostic noise regularization method for CDE that adds random perturbations to the data during training. We demonstrate that the proposed approach corresponds to a smoothness regularization and prove its asymptotic consistency. In our experiments, noise regularization significantly and consistently outperforms other regularization methods across seven data sets and three CDE models. The effectiveness of noise regularization makes neural network based CDE the preferable method over previous non- and semi-parametric approaches, even when training data is scarce.
Structured Variational Inference in Unstable Gaussian Process State Space Models
Jul 16, 2019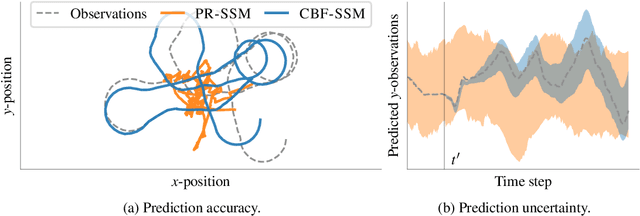
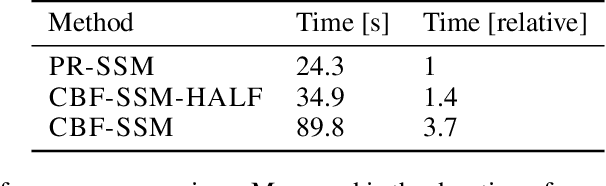
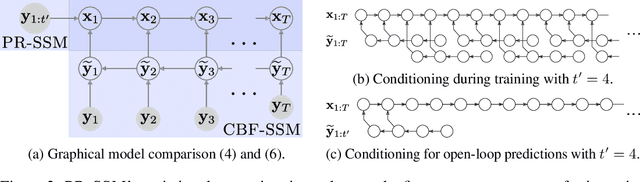
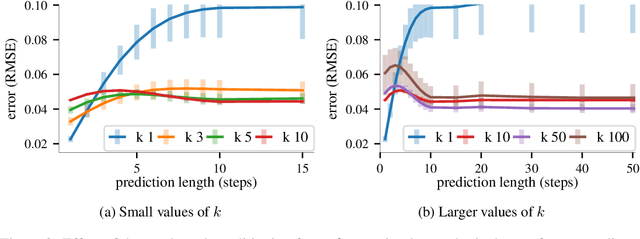
Gaussian processes are expressive, non-parametric statistical models that are well-suited to learn nonlinear dynamical systems. However, large-scale inference in these state space models is a challenging problem. In this paper, we propose CBF-SSM a scalable model that employs a structured variational approximation to maintain temporal correlations. In contrast to prior work, our approach applies to the important class of unstable systems, where state uncertainty grows unbounded over time. For these systems, our method contains a probabilistic, model-based backward pass that infers latent states during training. We demonstrate state-of-the-art performance in our experiments. Moreover, we show that CBF-SSM can be combined with physical models in the form of ordinary differential equations to learn a reliable model of a physical flying robotic vehicle.
Mixed-Variable Bayesian Optimization
Jul 02, 2019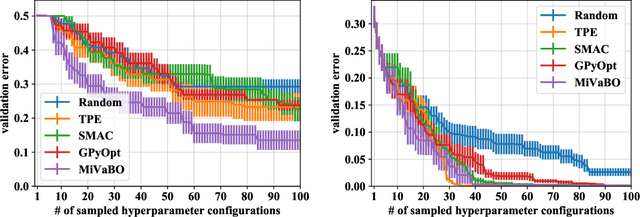
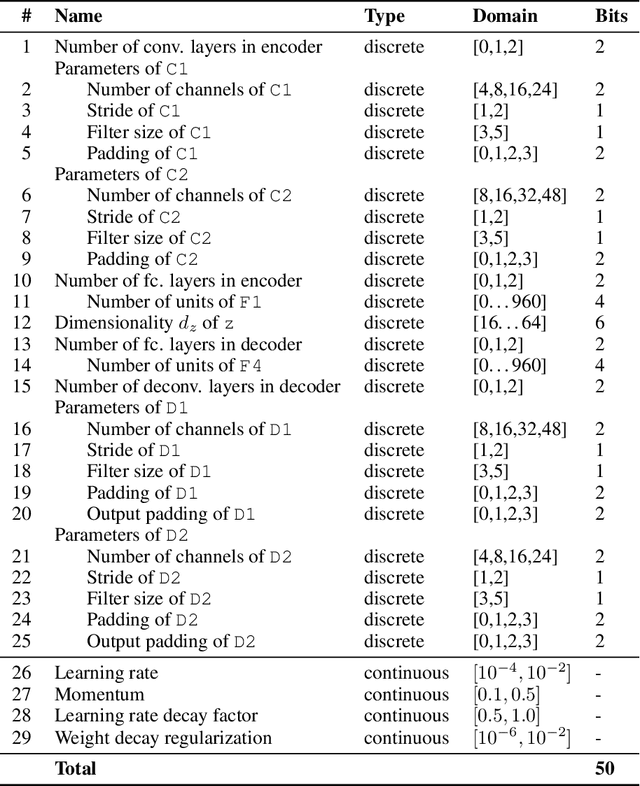
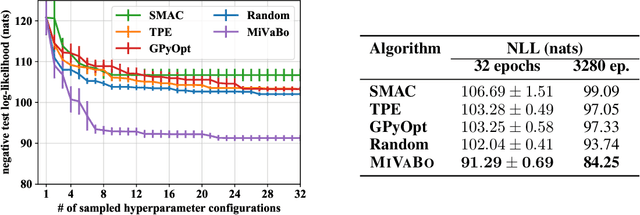
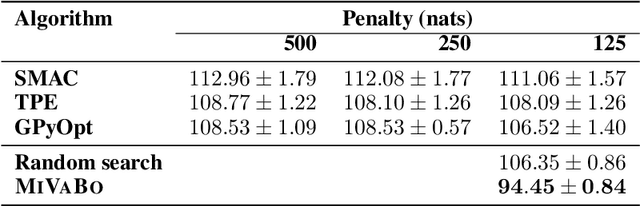
The optimization of expensive to evaluate, black-box, mixed-variable functions, i.e. functions that have continuous and discrete inputs, is a difficult and yet pervasive problem in science and engineering. In Bayesian optimization (BO), special cases of this problem that consider fully continuous or fully discrete domains have been widely studied. However, few methods exist for mixed-variable domains. In this paper, we introduce MiVaBo, a novel BO algorithm for the efficient optimization of mixed-variable functions that combines a linear surrogate model based on expressive feature representations with Thompson sampling. We propose two methods to optimize its acquisition function, a challenging problem for mixed-variable domains, and we show that MiVaBo can handle complex constraints over the discrete part of the domain that other methods cannot take into account. Moreover, we provide the first convergence analysis of a mixed-variable BO algorithm. Finally, we show that MiVaBo is significantly more sample efficient than state-of-the-art mixed-variable BO algorithms on hyperparameter tuning tasks.
Safe Contextual Bayesian Optimization for Sustainable Room Temperature PID Control Tuning
Jun 28, 2019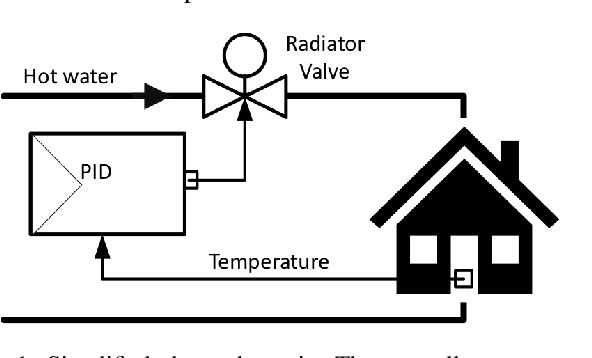

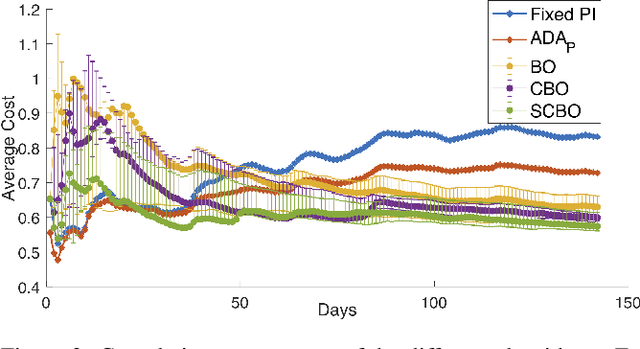
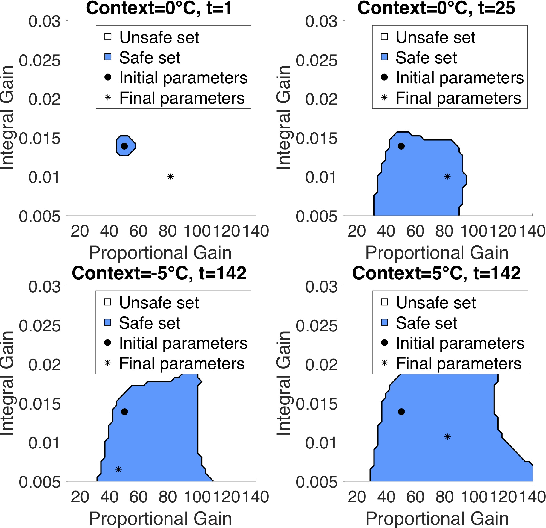
We tune one of the most common heating, ventilation, and air conditioning (HVAC) control loops, namely the temperature control of a room. For economical and environmental reasons, it is of prime importance to optimize the performance of this system. Buildings account from 20 to 40% of a country energy consumption, and almost 50% of it comes from HVAC systems. Scenario projections predict a 30% decrease in heating consumption by 2050 due to efficiency increase. Advanced control techniques can improve performance; however, the proportional-integral-derivative (PID) control is typically used due to its simplicity and overall performance. We use Safe Contextual Bayesian Optimization to optimize the PID parameters without human intervention. We reduce costs by 32% compared to the current PID controller setting while assuring safety and comfort to people in the room. The results of this work have an immediate impact on the room control loop performances and its related commissioning costs. Furthermore, this successful attempt paves the way for further use at different levels of HVAC systems, with promising energy, operational, and commissioning costs savings, and it is a practical demonstration of the positive effects that Artificial Intelligence can have on environmental sustainability.
Learning-based Model Predictive Control for Safe Exploration and Reinforcement Learning
Jun 27, 2019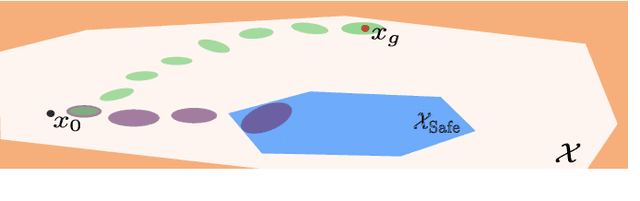

Reinforcement learning has been successfully used to solve difficult tasks in complex unknown environments. However, these methods typically do not provide any safety guarantees during the learning process. This is particularly problematic, since reinforcement learning agent actively explore their environment. This prevents their use in safety-critical, real-world applications. In this paper, we present a learning-based model predictive control scheme that provides high-probability safety guarantees throughout the learning process. Based on a reliable statistical model, we construct provably accurate confidence intervals on predicted trajectories. Unlike previous approaches, we allow for input-dependent uncertainties. Based on these reliable predictions, we guarantee that trajectories satisfy safety constraints. Moreover, we use a terminal set constraint to recursively guarantee the existence of safe control actions at every iteration. We evaluate the resulting algorithm to safely explore the dynamics of an inverted pendulum and to solve a reinforcement learning task on a cart-pole system with safety constraints.
Stochastic Bandits with Context Distributions
Jun 06, 2019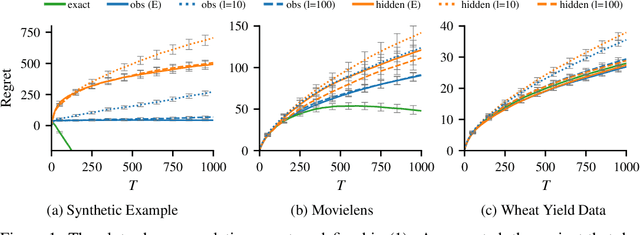
We introduce a novel stochastic contextual bandit model, where at each step the adversary chooses a distribution over a context set. The learner observes only the context distribution while the exact context realization remains hidden. This allows for a broader range of applications, for instance when the context itself is based on predictions. By leveraging the UCB algorithm to this setting, we propose an algorithm that achieves a $\tilde{\mathcal{O}}(d\sqrt{T})$ high-probability regret bound for linearly parametrized reward functions. Our results strictly generalize previous work in the sense that both our model and the algorithm reduce to the standard setting when the environment chooses only Dirac delta distributions and therefore provides the exact context to the learner. We further obtain similar results for a variant where the learner observes the realized context after choosing the action, and we extend the results to the kernelized setting. Finally, we demonstrate the proposed method on synthetic and real-world datasets.
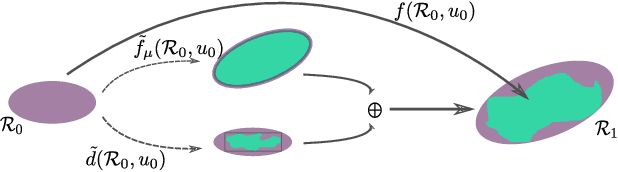
Learning Generative Models across Incomparable Spaces
May 15, 2019

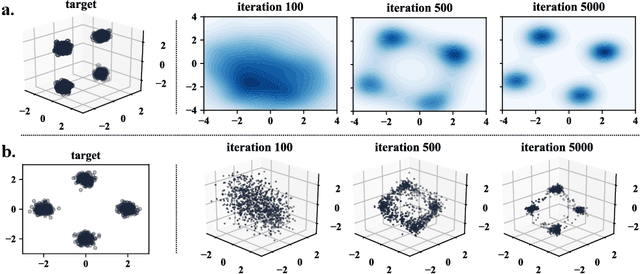

Generative Adversarial Networks have shown remarkable success in learning a distribution that faithfully recovers a reference distribution in its entirety. However, in some cases, we may want to only learn some aspects (e.g., cluster or manifold structure), while modifying others (e.g., style, orientation or dimension). In this work, we propose an approach to learn generative models across such incomparable spaces, and demonstrate how to steer the learned distribution towards target properties. A key component of our model is the Gromov-Wasserstein distance, a notion of discrepancy that compares distributions relationally rather than absolutely. While this framework subsumes current generative models in identically reproducing distributions, its inherent flexibility allows application to tasks in manifold learning, relational learning and cross-domain learning.
* International Conference on Machine Learning (ICML)
Online Variance Reduction with Mixtures
Mar 29, 2019
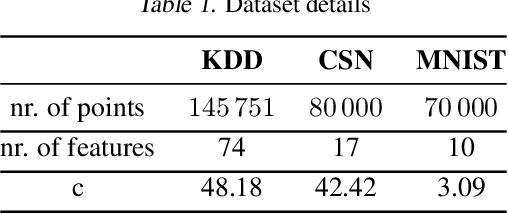

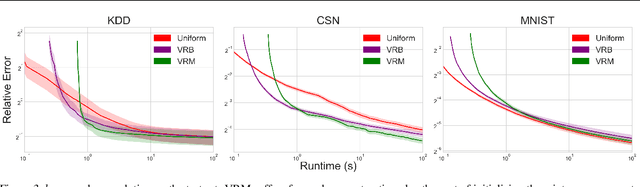
Adaptive importance sampling for stochastic optimization is a promising approach that offers improved convergence through variance reduction. In this work, we propose a new framework for variance reduction that enables the use of mixtures over predefined sampling distributions, which can naturally encode prior knowledge about the data. While these sampling distributions are fixed, the mixture weights are adapted during the optimization process. We propose VRM, a novel and efficient adaptive scheme that asymptotically recovers the best mixture weights in hindsight and can also accommodate sampling distributions over sets of points. We empirically demonstrate the versatility of VRM in a range of applications.
AReS and MaRS - Adversarial and MMD-Minimizing Regression for SDEs
Feb 22, 2019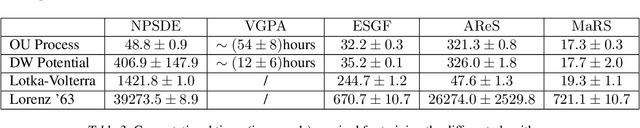
Stochastic differential equations are an important modeling class in many disciplines. Consequently, there exist many methods relying on various discretization and numerical integration schemes. In this paper, we propose a novel, probabilistic model for estimating the drift and diffusion given noisy observations of the underlying stochastic system. Using state-of-the-art adversarial and moment matching inference techniques, we circumvent the use of the discretization schemes as seen in classical approaches. This yields significant improvements in parameter estimation accuracy and robustness given random initial guesses. On four commonly used benchmark systems, we demonstrate the performance of our algorithms compared to state-of-the-art solutions based on extended Kalman filtering and Gaussian processes.
Multi-Player Bandits: The Adversarial Case
Feb 21, 2019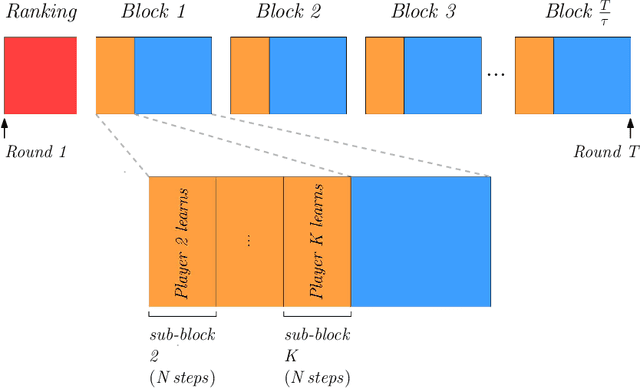
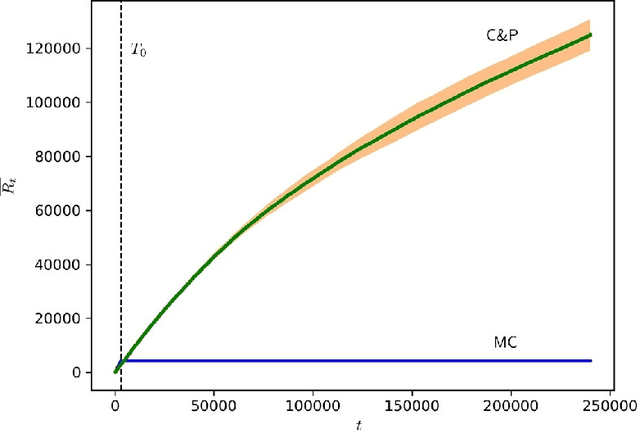
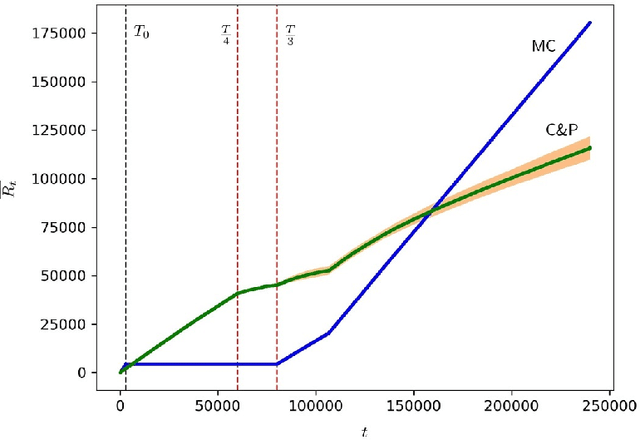
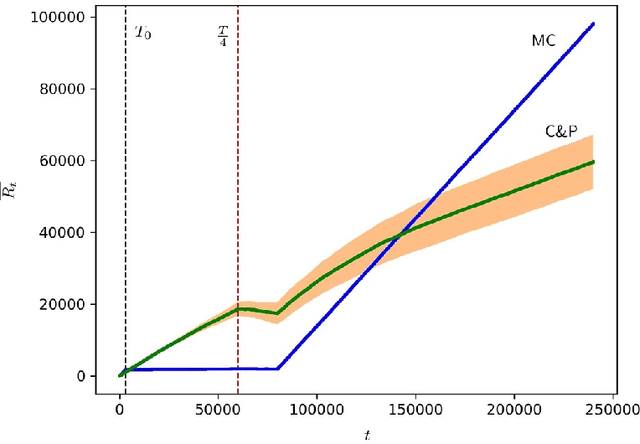
We consider a setting where multiple players sequentially choose among a common set of actions (arms). Motivated by a cognitive radio networks application, we assume that players incur a loss upon colliding, and that communication between players is not possible. Existing approaches assume that the system is stationary. Yet this assumption is often violated in practice, e.g., due to signal strength fluctuations. In this work, we design the first Multi-player Bandit algorithm that provably works in arbitrarily changing environments, where the losses of the arms may even be chosen by an adversary. This resolves an open problem posed by Rosenski, Shamir, and Szlak (2016).