 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Inconsistency Modeling for Image Manipulation Localization
Sep 30, 2023



Digital image forensics plays a crucial role in image authentication and manipulation localization. Despite the progress powered by deep neural networks, existing forgery localization methodologies exhibit limitations when deployed to unseen datasets and perturbed images (i.e., lack of generalization and robustness to real-world applications). To circumvent these problems and aid image integrity, this paper presents a generalized and robust manipulation localization model through the analysis of pixel inconsistency artifacts. The rationale is grounded on the observation that most image signal processors (ISP) involve the demosaicing process, which introduces pixel correlations in pristine images. Moreover, manipulating operations, including splicing, copy-move, and inpainting, directly affect such pixel regularity. We, therefore, first split the input image into several blocks and design masked self-attention mechanisms to model the global pixel dependency in input images. Simultaneously, we optimize another local pixel dependency stream to mine local manipulation clues within input forgery images. In addition, we design novel Learning-to-Weight Modules (LWM) to combine features from the two streams, thereby enhancing the final forgery localization performance. To improve the training process, we propose a novel Pixel-Inconsistency Data Augmentation (PIDA) strategy, driving the model to focus on capturing inherent pixel-level artifacts instead of mining semantic forgery traces. This work establishes a comprehensive benchmark integrating 15 representative detection models across 12 datasets. Extensive experiments show that our method successfully extracts inherent pixel-inconsistency forgery fingerprints and achieve state-of-the-art generalization and robustness performances in image manipulation localization.
Information Forensics and Security: A quarter-century-long journey
Sep 21, 2023Information Forensics and Security (IFS) is an active R&D area whose goal is to ensure that people use devices, data, and intellectual properties for authorized purposes and to facilitate the gathering of solid evidence to hold perpetrators accountable. For over a quarter century since the 1990s, the IFS research area has grown tremendously to address the societal needs of the digital information era. The IEEE Signal Processing Society (SPS) has emerged as an important hub and leader in this area, and the article below celebrates some landmark technical contributions. In particular, we highlight the major technological advances on some selected focus areas in the field developed in the last 25 years from the research community and present future trends.
Large-scale Fully-Unsupervised Re-Identification
Jul 26, 2023



Fully-unsupervised Person and Vehicle Re-Identification have received increasing attention due to their broad applicability in surveillance, forensics, event understanding, and smart cities, without requiring any manual annotation. However, most of the prior art has been evaluated in datasets that have just a couple thousand samples. Such small-data setups often allow the use of costly techniques in time and memory footprints, such as Re-Ranking, to improve clustering results. Moreover, some previous work even pre-selects the best clustering hyper-parameters for each dataset, which is unrealistic in a large-scale fully-unsupervised scenario. In this context, this work tackles a more realistic scenario and proposes two strategies to learn from large-scale unlabeled data. The first strategy performs a local neighborhood sampling to reduce the dataset size in each iteration without violating neighborhood relationships. A second strategy leverages a novel Re-Ranking technique, which has a lower time upper bound complexity and reduces the memory complexity from O(n^2) to O(kn) with k << n. To avoid the pre-selection of specific hyper-parameter values for the clustering algorithm, we also present a novel scheduling algorithm that adjusts the density parameter during training, to leverage the diversity of samples and keep the learning robust to noisy labeling. Finally, due to the complementary knowledge learned by different models, we also introduce a co-training strategy that relies upon the permutation of predicted pseudo-labels, among the backbones, with no need for any hyper-parameters or weighting optimization. The proposed methodology outperforms the state-of-the-art methods in well-known benchmarks and in the challenging large-scale Veri-Wild dataset, with a faster and memory-efficient Re-Ranking strategy, and a large-scale, noisy-robust, and ensemble-based learning approach.
The Age of Synthetic Realities: Challenges and Opportunities
Jun 09, 2023Synthetic realities are digital creations or augmentations that are contextually generated through the use of Artificial Intelligence (AI) methods, leveraging extensive amounts of data to construct new narratives or realities, regardless of the intent to deceive. In this paper, we delve into the concept of synthetic realities and their implications for Digital Forensics and society at large within the rapidly advancing field of AI. We highlight the crucial need for the development of forensic techniques capable of identifying harmful synthetic creations and distinguishing them from reality. This is especially important in scenarios involving the creation and dissemination of fake news, disinformation, and misinformation. Our focus extends to various forms of media, such as images, videos, audio, and text, as we examine how synthetic realities are crafted and explore approaches to detecting these malicious creations. Additionally, we shed light on the key research challenges that lie ahead in this area. This study is of paramount importance due to the rapid progress of AI generative techniques and their impact on the fundamental principles of Forensic Science.
M3FAS: An Accurate and Robust MultiModal Mobile Face Anti-Spoofing System
Feb 03, 2023



Face presentation attacks (FPA), also known as face spoofing, have brought increasing concerns to the public through various malicious applications, such as financial fraud and privacy leakage. Therefore, safeguarding face recognition systems against FPA is of utmost importance. Although existing learning-based face anti-spoofing (FAS) models can achieve outstanding detection performance, they lack generalization capability and suffer significant performance drops in unforeseen environments. Many methodologies seek to use auxiliary modality data (e.g., depth and infrared maps) during the presentation attack detection (PAD) to address this limitation. However, these methods can be limited since (1) they require specific sensors such as depth and infrared cameras for data capture, which are rarely available on commodity mobile devices, and (2) they cannot work properly in practical scenarios when either modality is missing or of poor quality. In this paper, we devise an accurate and robust MultiModal Mobile Face Anti-Spoofing system named M3FAS to overcome the issues above. The innovation of this work mainly lies in the following aspects: (1) To achieve robust PAD, our system combines visual and auditory modalities using three pervasively available sensors: camera, speaker, and microphone; (2) We design a novel two-branch neural network with three hierarchical feature aggregation modules to perform cross-modal feature fusion; (3). We propose a multi-head training strategy. The model outputs three predictions from the vision, acoustic, and fusion heads, enabling a more flexible PAD. Extensive experiments have demonstrated the accuracy, robustness, and flexibility of M3FAS under various challenging experimental settings.
Few-shot Learning for Multi-modal Social Media Event Filtering
Nov 16, 2022



Social media has become an important data source for event analysis. When collecting this type of data, most contain no useful information to a target event. Thus, it is essential to filter out those noisy data at the earliest opportunity for a human expert to perform further inspection. Most existing solutions for event filtering rely on fully supervised methods for training. However, in many real-world scenarios, having access to large number of labeled samples is not possible. To deal with a few labeled sample training problem for event filtering, we propose a graph-based few-shot learning pipeline. We also release the Brazilian Protest Dataset to test our method. To the best of our knowledge, this dataset is the first of its kind in event filtering that focuses on protests in multi-modal social media data, with most of the text in Portuguese. Our experimental results show that our proposed pipeline has comparable performance with only a few labeled samples (60) compared with a fully labeled dataset (3100). To facilitate the research community, we make our dataset and code available at https://github.com/jdnascim/7Set-AL.
Reasoning for Complex Data through Ensemble-based Self-Supervised Learning
Feb 12, 2022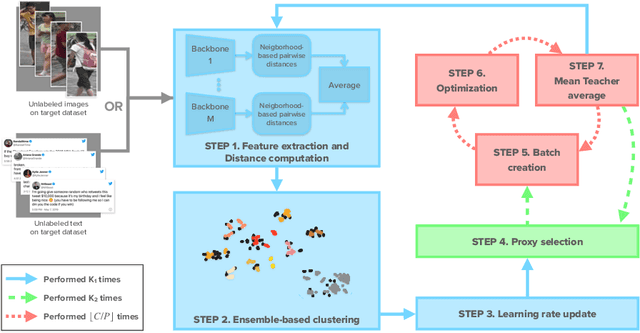
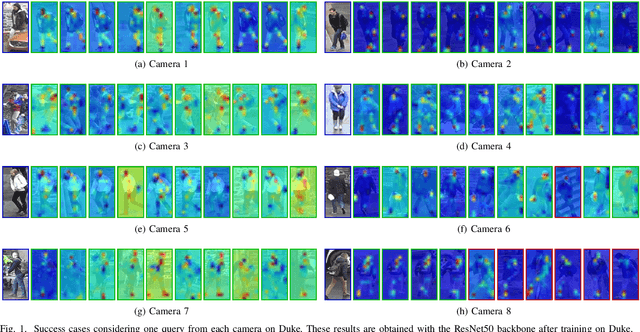
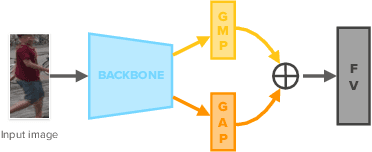
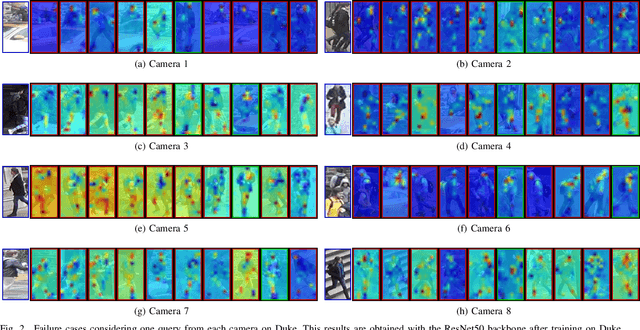
Self-supervised learning deals with problems that have little or no available labeled data. Recent work has shown impressive results when underlying classes have significant semantic differences. One important dataset in which this technique thrives is ImageNet, as intra-class distances are substantially lower than inter-class distances. However, this is not the case for several critical tasks, and general self-supervised learning methods fail to learn discriminative features when classes have closer semantics, thus requiring more robust strategies. We propose a strategy to tackle this problem, and to enable learning from unlabeled data even when samples from different classes are not prominently diverse. We approach the problem by leveraging a novel ensemble-based clustering strategy where clusters derived from different configurations are combined to generate a better grouping for the data samples in a fully-unsupervised way. This strategy allows clusters with different densities and higher variability to emerge, which in turn reduces intra-class discrepancies, without requiring the burden of finding an optimal configuration per dataset. We also consider different Convolutional Neural Networks to compute distances between samples. We refine these distances by performing context analysis and group them to capture complementary information. We consider two applications to validate our pipeline: Person Re-Identification and Text Authorship Verification. These are challenging applications considering that classes are semantically close to each other and that training and test sets have disjoint identities. Our method is robust across different modalities and outperforms state-of-the-art results with a fully-unsupervised solution without any labeling or human intervention.
Forensic Analysis of Synthetically Generated Scientific Images
Dec 16, 2021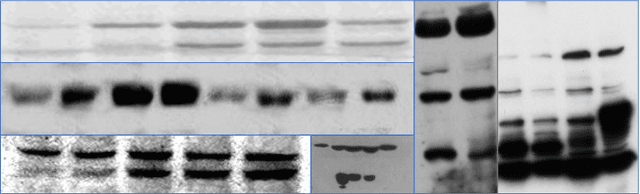
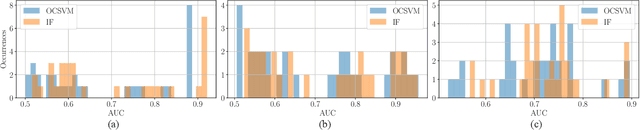
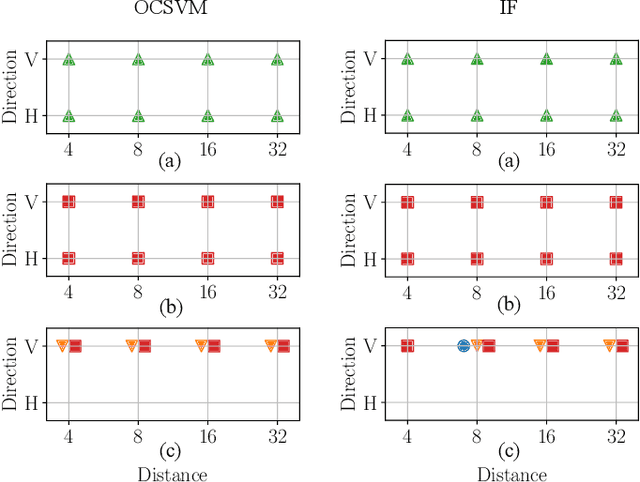

The widespread diffusion of synthetically generated content is a serious threat that needs urgent countermeasures. The generation of synthetic content is not restricted to multimedia data like videos, photographs, or audio sequences, but covers a significantly vast area that can include biological images as well, such as western-blot and microscopic images. In this paper, we focus on the detection of synthetically generated western-blot images. Western-blot images are largely explored in the biomedical literature and it has been already shown how these images can be easily counterfeited with few hope to spot manipulations by visual inspection or by standard forensics detectors. To overcome the absence of a publicly available dataset, we create a new dataset comprising more than 14K original western-blot images and 18K synthetic western-blot images, generated by three different state-of-the-art generation methods. Then, we investigate different strategies to detect synthetic western blots, exploring binary classification methods as well as one-class detectors. In both scenarios, we never exploit synthetic western-blot images at training stage. The achieved results show that synthetically generated western-blot images can be spot with good accuracy, even though the exploited detectors are not optimized over synthetic versions of these scientific images.
Explainable Fact-checking through Question Answering
Oct 11, 2021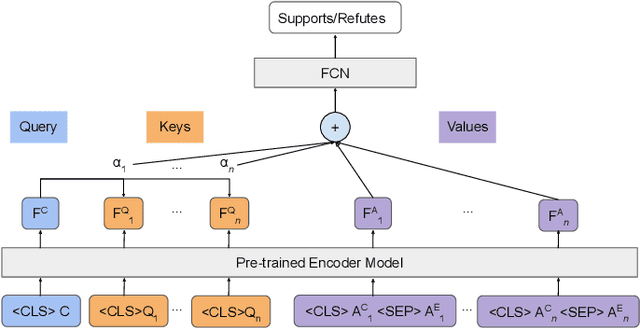
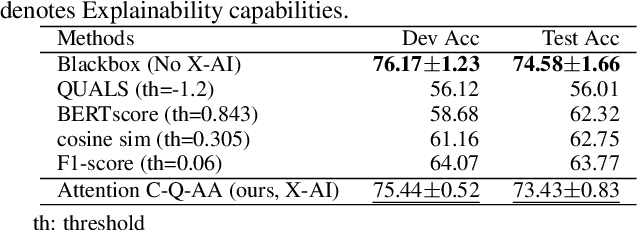

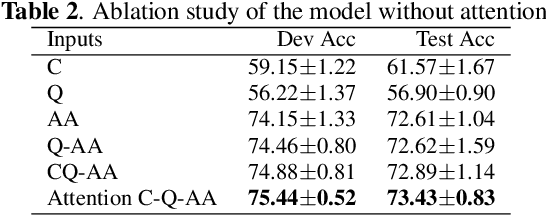
Misleading or false information has been creating chaos in some places around the world. To mitigate this issue, many researchers have proposed automated fact-checking methods to fight the spread of fake news. However, most methods cannot explain the reasoning behind their decisions, failing to build trust between machines and humans using such technology. Trust is essential for fact-checking to be applied in the real world. Here, we address fact-checking explainability through question answering. In particular, we propose generating questions and answers from claims and answering the same questions from evidence. We also propose an answer comparison model with an attention mechanism attached to each question. Leveraging question answering as a proxy, we break down automated fact-checking into several steps -- this separation aids models' explainability as it allows for more detailed analysis of their decision-making processes. Experimental results show that the proposed model can achieve state-of-the-art performance while providing reasonable explainable capabilities.
Scalable Fact-checking with Human-in-the-Loop
Sep 22, 2021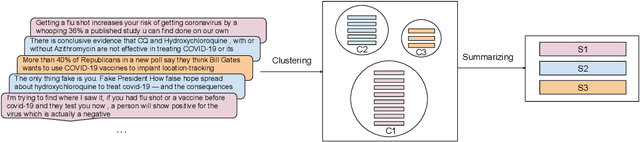
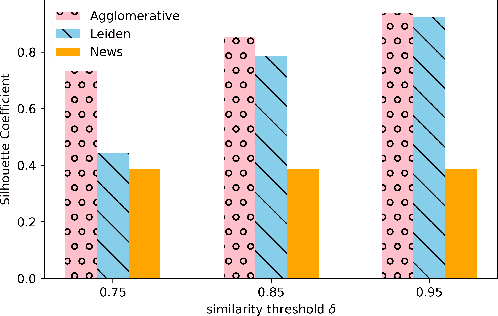
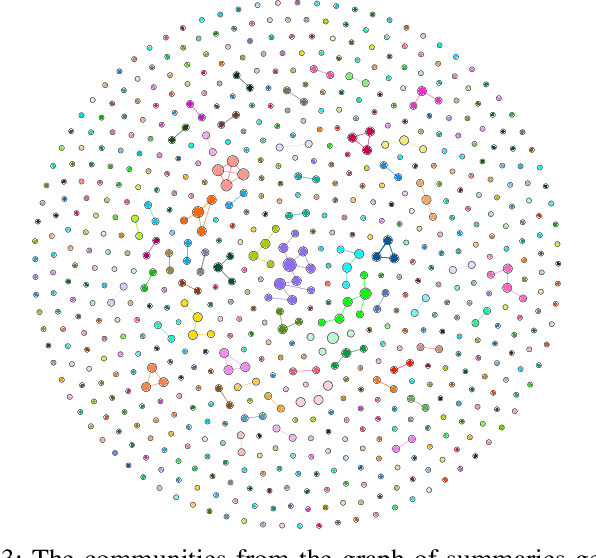
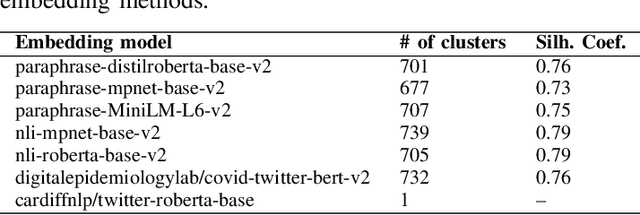
Researchers have been investigating automated solutions for fact-checking in a variety of fronts. However, current approaches often overlook the fact that the amount of information released every day is escalating, and a large amount of them overlap. Intending to accelerate fact-checking, we bridge this gap by grouping similar messages and summarizing them into aggregated claims. Specifically, we first clean a set of social media posts (e.g., tweets) and build a graph of all posts based on their semantics; Then, we perform two clustering methods to group the messages for further claim summarization. We evaluate the summaries both quantitatively with ROUGE scores and qualitatively with human evaluation. We also generate a graph of summaries to verify that there is no significant overlap among them. The results reduced 28,818 original messages to 700 summary claims, showing the potential to speed up the fact-checking process by organizing and selecting representative claims from massive disorganized and redundant messages.