 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Fact-checking through Question Answering
Oct 11, 2021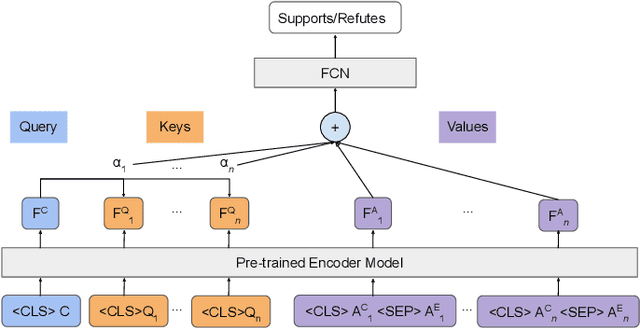
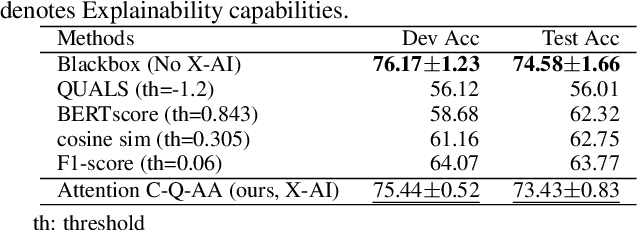

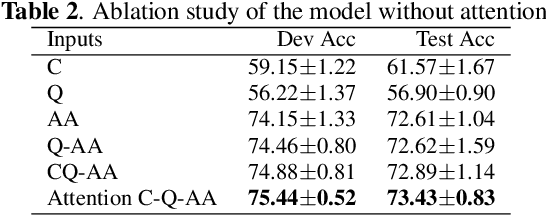
Misleading or false information has been creating chaos in some places around the world. To mitigate this issue, many researchers have proposed automated fact-checking methods to fight the spread of fake news. However, most methods cannot explain the reasoning behind their decisions, failing to build trust between machines and humans using such technology. Trust is essential for fact-checking to be applied in the real world. Here, we address fact-checking explainability through question answering. In particular, we propose generating questions and answers from claims and answering the same questions from evidence. We also propose an answer comparison model with an attention mechanism attached to each question. Leveraging question answering as a proxy, we break down automated fact-checking into several steps -- this separation aids models' explainability as it allows for more detailed analysis of their decision-making processes. Experimental results show that the proposed model can achieve state-of-the-art performance while providing reasonable explainable capabilities.
Scalable Fact-checking with Human-in-the-Loop
Sep 22, 2021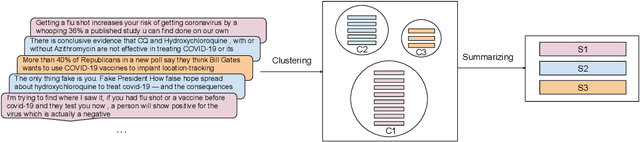
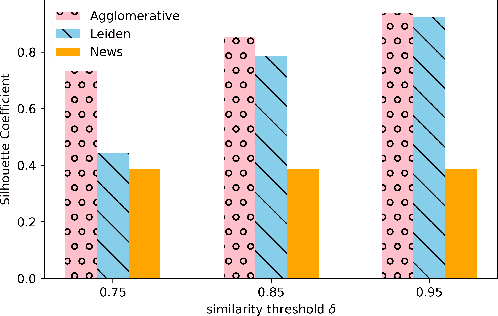
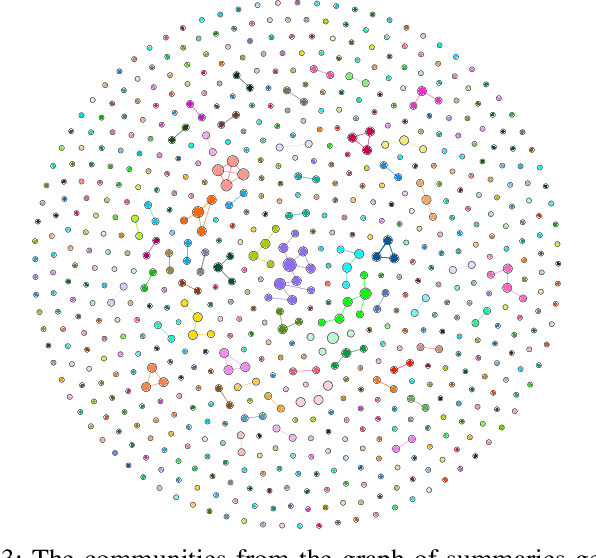
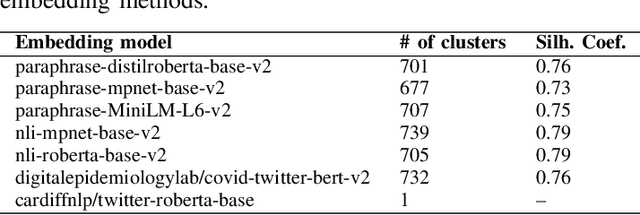
Researchers have been investigating automated solutions for fact-checking in a variety of fronts. However, current approaches often overlook the fact that the amount of information released every day is escalating, and a large amount of them overlap. Intending to accelerate fact-checking, we bridge this gap by grouping similar messages and summarizing them into aggregated claims. Specifically, we first clean a set of social media posts (e.g., tweets) and build a graph of all posts based on their semantics; Then, we perform two clustering methods to group the messages for further claim summarization. We evaluate the summaries both quantitatively with ROUGE scores and qualitatively with human evaluation. We also generate a graph of summaries to verify that there is no significant overlap among them. The results reduced 28,818 original messages to 700 summary claims, showing the potential to speed up the fact-checking process by organizing and selecting representative claims from massive disorganized and redundant messages.