 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Robust Scene Flow Estimation via the Alignment of Probability Density Functions
Mar 23, 2022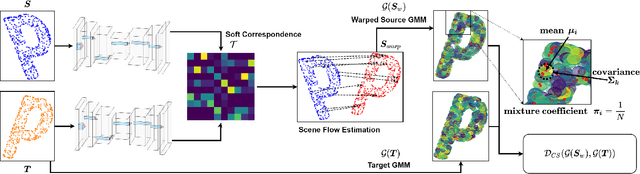
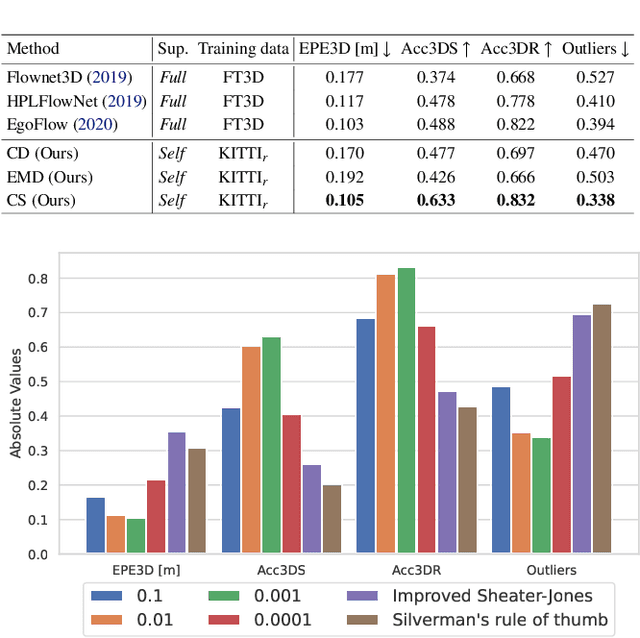
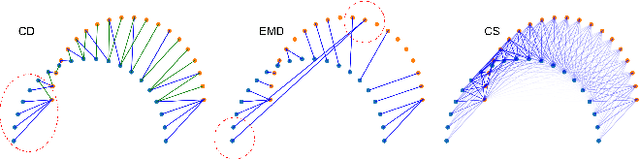
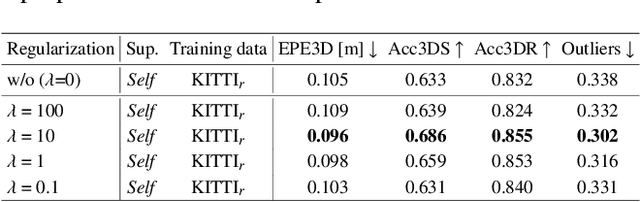
In this paper, we present a new self-supervised scene flow estimation approach for a pair of consecutive point clouds. The key idea of our approach is to represent discrete point clouds as continuous probability density functions using Gaussian mixture models. Scene flow estimation is therefore converted into the problem of recovering motion from the alignment of probability density functions, which we achieve using a closed-form expression of the classic Cauchy-Schwarz divergence. Unlike existing nearest-neighbor-based approaches that use hard pairwise correspondences, our proposed approach establishes soft and implicit point correspondences between point clouds and generates more robust and accurate scene flow in the presence of missing correspondences and outliers. Comprehensive experiments show that our method makes noticeable gains over the Chamfer Distance and the Earth Mover's Distance in real-world environments and achieves state-of-the-art performance among self-supervised learning methods on FlyingThings3D and KITTI, even outperforming some supervised methods with ground truth annotations.
Learning Scene Dynamics from Point Cloud Sequences
Nov 16, 2021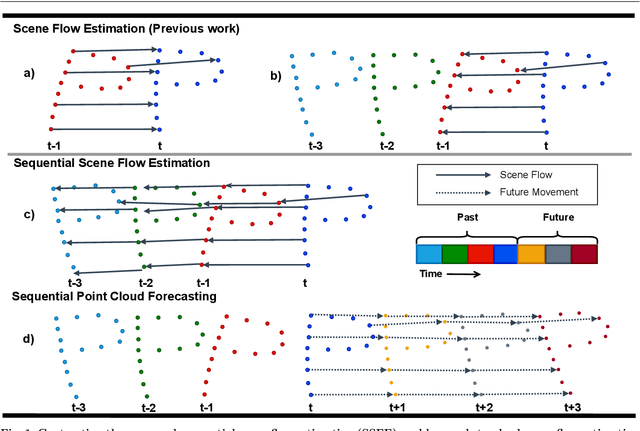

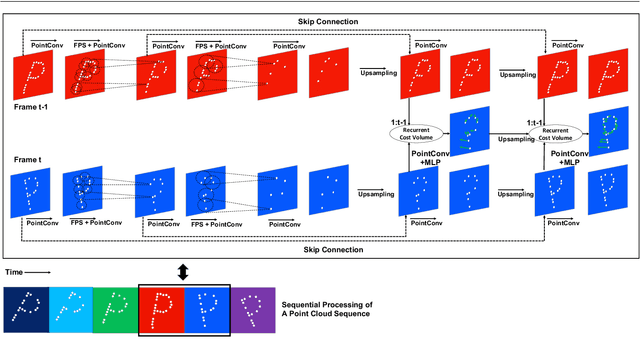
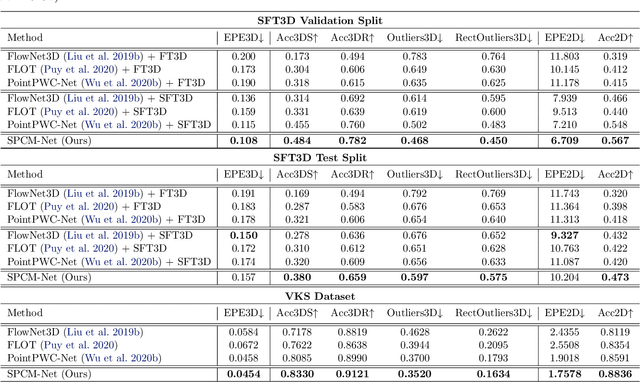
Understanding 3D scenes is a critical prerequisite for autonomous agents. Recently, LiDAR and other sensors have made large amounts of data available in the form of temporal sequences of point cloud frames. In this work, we propose a novel problem -- sequential scene flow estimation (SSFE) -- that aims to predict 3D scene flow for all pairs of point clouds in a given sequence. This is unlike the previously studied problem of scene flow estimation which focuses on two frames. We introduce the SPCM-Net architecture, which solves this problem by computing multi-scale spatiotemporal correlations between neighboring point clouds and then aggregating the correlation across time with an order-invariant recurrent unit. Our experimental evaluation confirms that recurrent processing of point cloud sequences results in significantly better SSFE compared to using only two frames. Additionally, we demonstrate that this approach can be effectively modified for sequential point cloud forecasting (SPF), a related problem that demands forecasting future point cloud frames. Our experimental results are evaluated using a new benchmark for both SSFE and SPF consisting of synthetic and real datasets. Previously, datasets for scene flow estimation have been limited to two frames. We provide non-trivial extensions to these datasets for multi-frame estimation and prediction. Due to the difficulty of obtaining ground truth motion for real-world datasets, we use self-supervised training and evaluation metrics. We believe that this benchmark will be pivotal to future research in this area. All code for benchmark and models will be made accessible.
Domain-guided Machine Learning for Remotely Sensed In-Season Crop Growth Estimation
Jun 24, 2021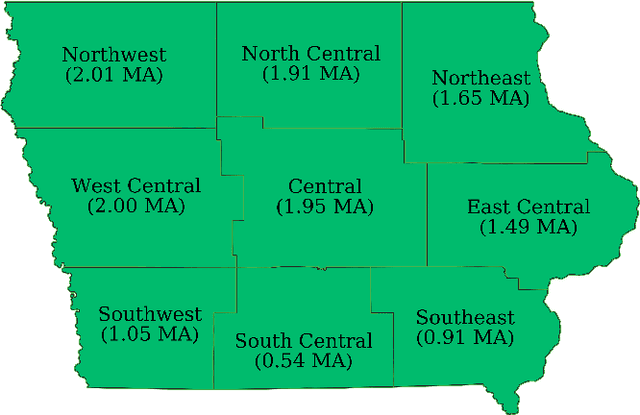
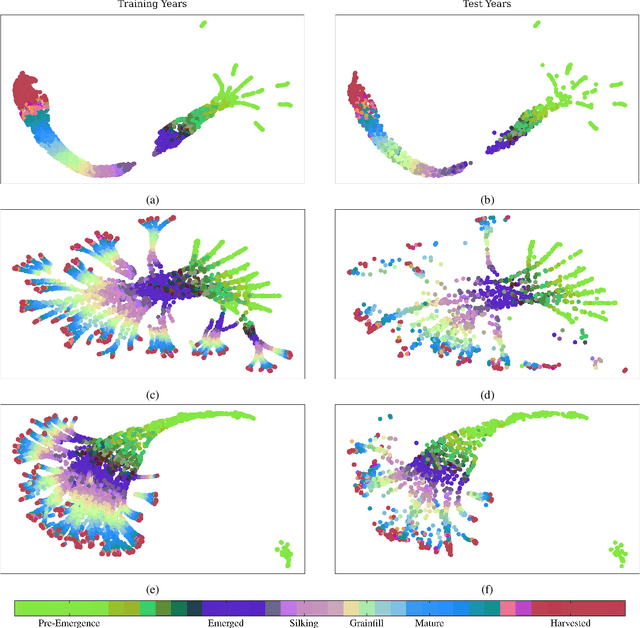
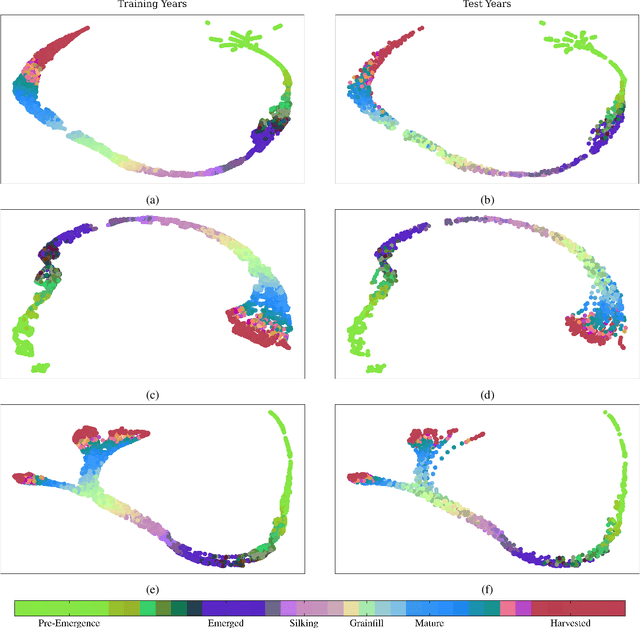
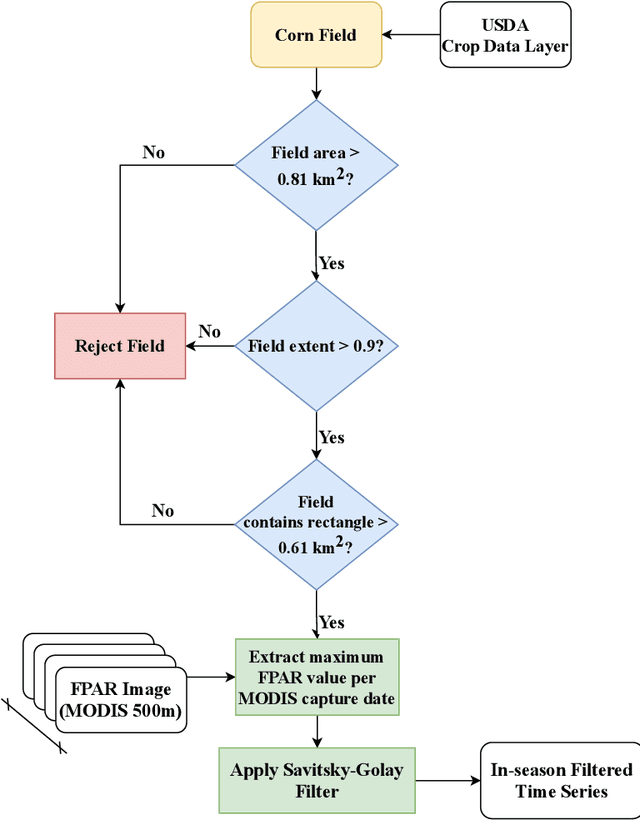
Advanced machine learning techniques have been used in remote sensing (RS) applications such as crop mapping and yield prediction, but remain under-utilized for tracking crop progress. In this study, we demonstrate the use of agronomic knowledge of crop growth drivers in a Long Short-Term Memory-based, Domain-guided neural network (DgNN) for in-season crop progress estimation. The DgNN uses a branched structure and attention to separate independent crop growth drivers and capture their varying importance throughout the growing season. The DgNN is implemented for corn, using RS data in Iowa for the period 2003-2019, with USDA crop progress reports used as ground truth. State-wide DgNN performance shows significant improvement over sequential and dense-only NN structures, and a widely-used Hidden Markov Model method. The DgNN had a 3.5% higher Nash-Sutfliffe efficiency over all growth stages and 33% more weeks with highest cosine similarity than the other NNs during test years. The DgNN and Sequential NN were more robust during periods of abnormal crop progress, though estimating the Silking-Grainfill transition was difficult for all methods. Finally, Uniform Manifold Approximation and Projection visualizations of layer activations showed how LSTM-based NNs separate crop growth time-series differently from a dense-only structure. Results from this study exhibit both the viability of NNs in crop growth stage estimation (CGSE) and the benefits of using domain knowledge. The DgNN methodology presented here can be extended to provide near-real time CGSE of other crops.
Efficient Iterative Amortized Inference for Learning Symmetric and Disentangled Multi-Object Representations
Jun 07, 2021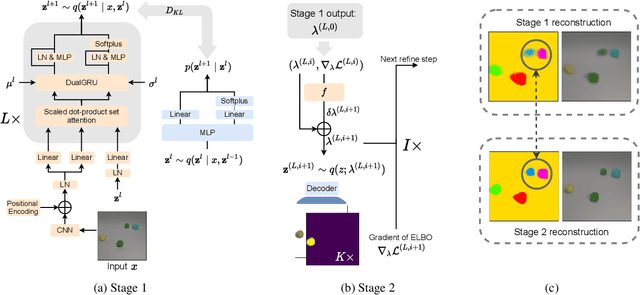
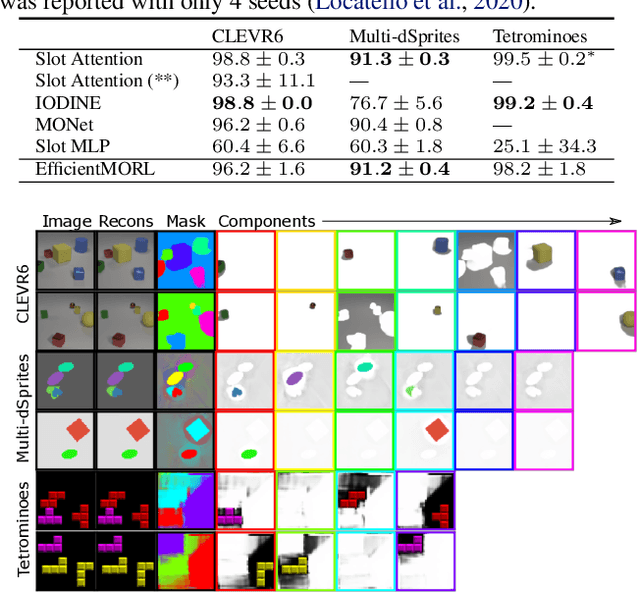
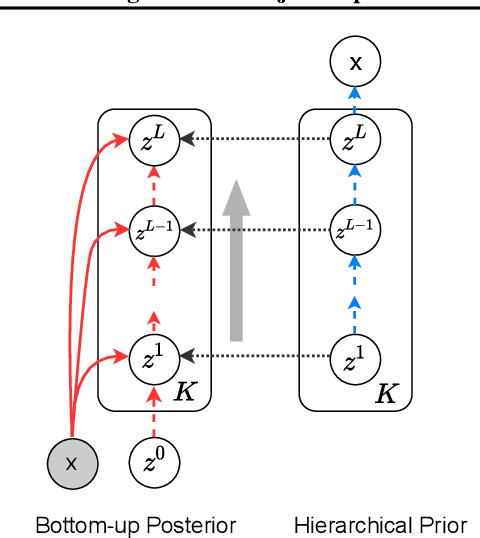
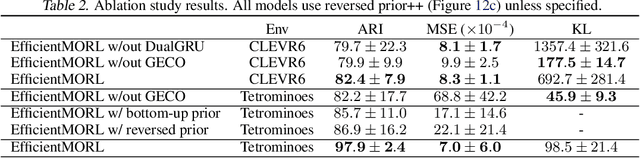
Unsupervised multi-object representation learning depends on inductive biases to guide the discovery of object-centric representations that generalize. However, we observe that methods for learning these representations are either impractical due to long training times and large memory consumption or forego key inductive biases. In this work, we introduce EfficientMORL, an efficient framework for the unsupervised learning of object-centric representations. We show that optimization challenges caused by requiring both symmetry and disentanglement can in fact be addressed by high-cost iterative amortized inference by designing the framework to minimize its dependence on it. We take a two-stage approach to inference: first, a hierarchical variational autoencoder extracts symmetric and disentangled representations through bottom-up inference, and second, a lightweight network refines the representations with top-down feedback. The number of refinement steps taken during training is reduced following a curriculum, so that at test time with zero steps the model achieves 99.1% of the refined decomposition performance. We demonstrate strong object decomposition and disentanglement on the standard multi-object benchmark while achieving nearly an order of magnitude faster training and test time inference over the previous state-of-the-art model.
Hybrid Generative Models for Two-Dimensional Datasets
Jun 01, 2021
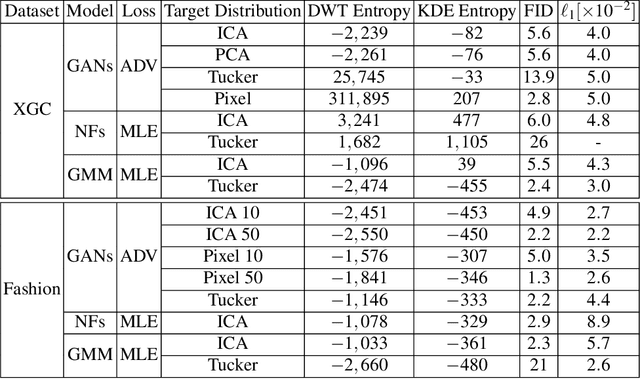

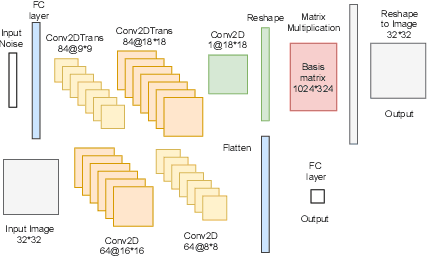
Two-dimensional array-based datasets are pervasive in a variety of domains. Current approaches for generative modeling have typically been limited to conventional image datasets and performed in the pixel domain which do not explicitly capture the correlation between pixels. Additionally, these approaches do not extend to scientific and other applications where each element value is continuous and is not limited to a fixed range. In this paper, we propose a novel approach for generating two-dimensional datasets by moving the computations to the space of representation bases and show its usefulness for two different datasets, one from imaging and another from scientific computing. The proposed approach is general and can be applied to any dataset, representation basis, or generative model. We provide a comprehensive performance comparison of various combinations of generative models and representation basis spaces. We also propose a new evaluation metric which captures the deficiency of generating images in pixel space.
SparsePipe: Parallel Deep Learning for 3D Point Clouds
Dec 27, 2020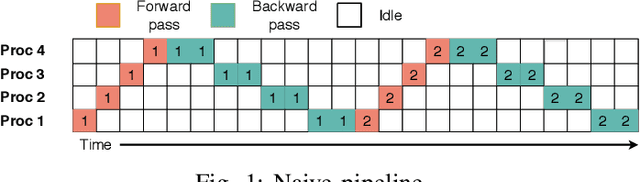
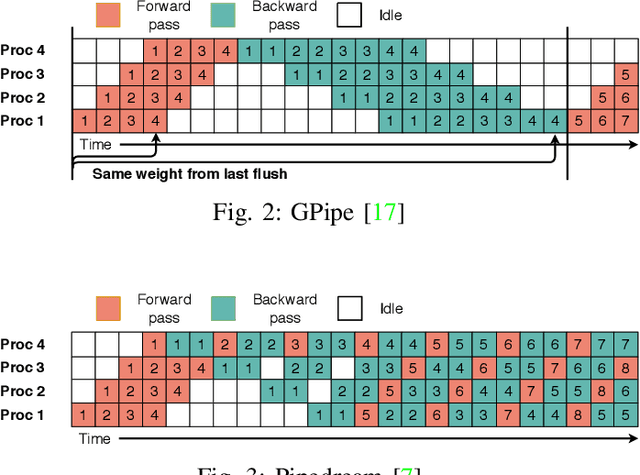
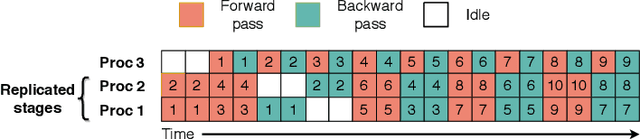
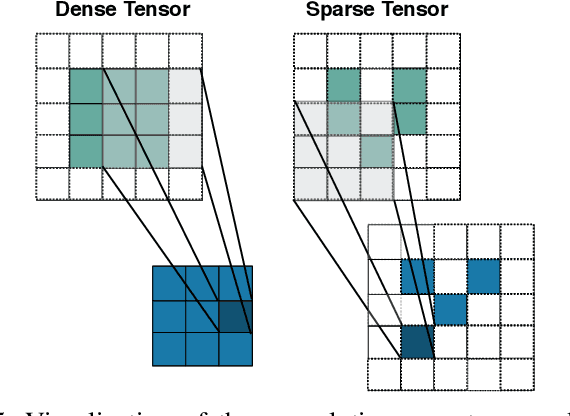
We propose SparsePipe, an efficient and asynchronous parallelism approach for handling 3D point clouds with multi-GPU training. SparsePipe is built to support 3D sparse data such as point clouds. It achieves this by adopting generalized convolutions with sparse tensor representation to build expressive high-dimensional convolutional neural networks. Compared to dense solutions, the new models can efficiently process irregular point clouds without densely sliding over the entire space, significantly reducing the memory requirements and allowing higher resolutions of the underlying 3D volumes for better performance. SparsePipe exploits intra-batch parallelism that partitions input data into multiple processors and further improves the training throughput with inter-batch pipelining to overlap communication and computing. Besides, it suitably partitions the model when the GPUs are heterogeneous such that the computing is load-balanced with reduced communication overhead. Using experimental results on an eight-GPU platform, we show that SparsePipe can parallelize effectively and obtain better performance on current point cloud benchmarks for both training and inference, compared to its dense solutions.
A Unified Framework for Multiclass and Multilabel Support Vector Machines
Mar 25, 2020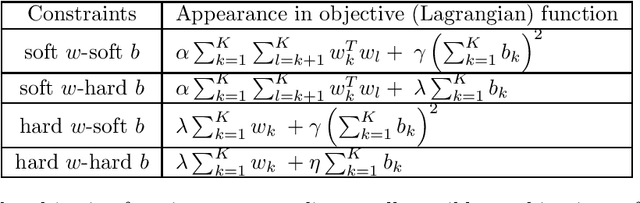
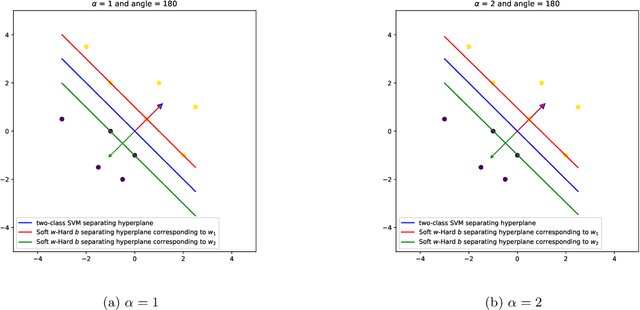

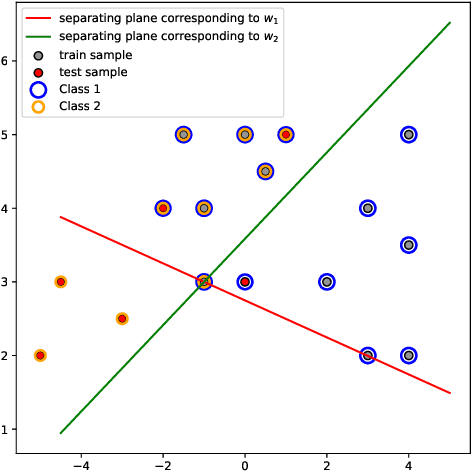
We propose a novel integrated formulation for multiclass and multilabel support vector machines (SVMs). A number of approaches have been proposed to extend the original binary SVM to an all-in-one multiclass SVM. However, its direct extension to a unified multilabel SVM has not been widely investigated. We propose a straightforward extension to the SVM to cope with multiclass and multilabel classification problems within a unified framework. Our framework deviates from the conventional soft margin SVM framework with its direct oppositional structure. In our formulation, class-specific weight vectors (normal vectors) are learned by maximizing their margin with respect to an origin and penalizing patterns when they get too close to this origin. As a result, each weight vector chooses an orientation and a magnitude with respect to this origin in such a way that it best represents the patterns belonging to its corresponding class. Opposition between classes is introduced into the formulation via the minimization of pairwise inner products of weight vectors. We also extend our framework to cope with nonlinear separability via standard reproducing kernel Hilbert spaces (RKHS). Biases which are closely related to the origin need to be treated properly in both the original feature space and Hilbert space. We have the flexibility to incorporate constraints into the formulation (if they better reflect the underlying geometry) and improve the performance of the classifier. To this end, specifics and technicalities such as the origin in RKHS are addressed. Results demonstrates a competitive classifier for both multiclass and multilabel classification problems.
Intelligent Intersection: Two-Stream Convolutional Networks for Real-time Near Accident Detection in Traffic Video
Jan 04, 2019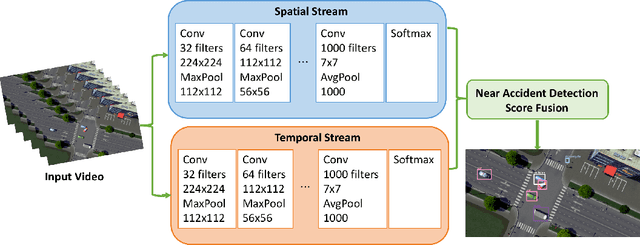
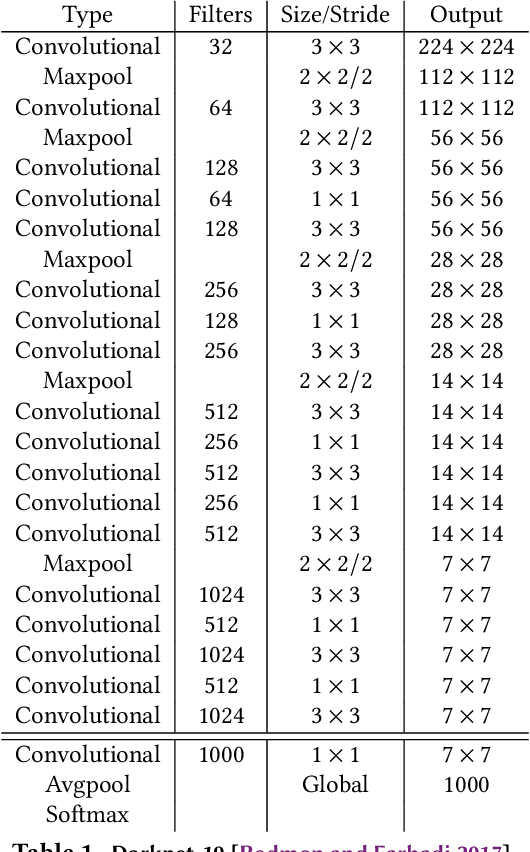
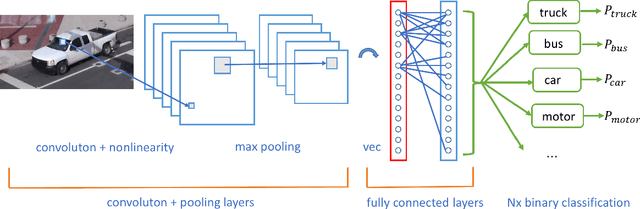
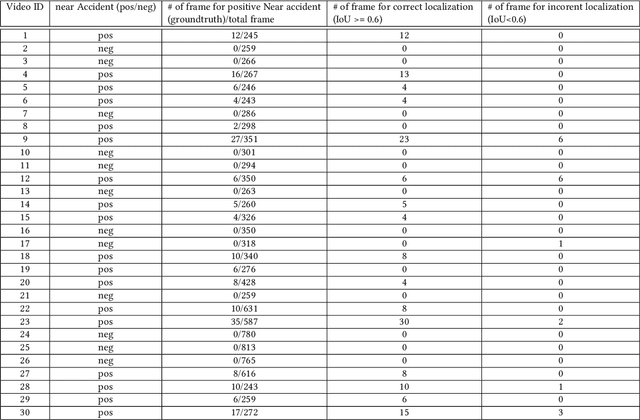
In Intelligent Transportation System, real-time systems that monitor and analyze road users become increasingly critical as we march toward the smart city era. Vision-based frameworks for Object Detection, Multiple Object Tracking, and Traffic Near Accident Detection are important applications of Intelligent Transportation System, particularly in video surveillance and etc. Although deep neural networks have recently achieved great success in many computer vision tasks, a uniformed framework for all the three tasks is still challenging where the challenges multiply from demand for real-time performance, complex urban setting, highly dynamic traffic event, and many traffic movements. In this paper, we propose a two-stream Convolutional Network architecture that performs real-time detection, tracking, and near accident detection of road users in traffic video data. The two-stream model consists of a spatial stream network for Object Detection and a temporal stream network to leverage motion features for Multiple Object Tracking. We detect near accidents by incorporating appearance features and motion features from two-stream networks. Using aerial videos, we propose a Traffic Near Accident Dataset (TNAD) covering various types of traffic interactions that is suitable for vision-based traffic analysis tasks. Our experiments demonstrate the advantage of our framework with an overall competitive qualitative and quantitative performance at high frame rates on the TNAD dataset.
Visual Explanations From Deep 3D Convolutional Neural Networks for Alzheimer's Disease Classification
Jul 06, 2018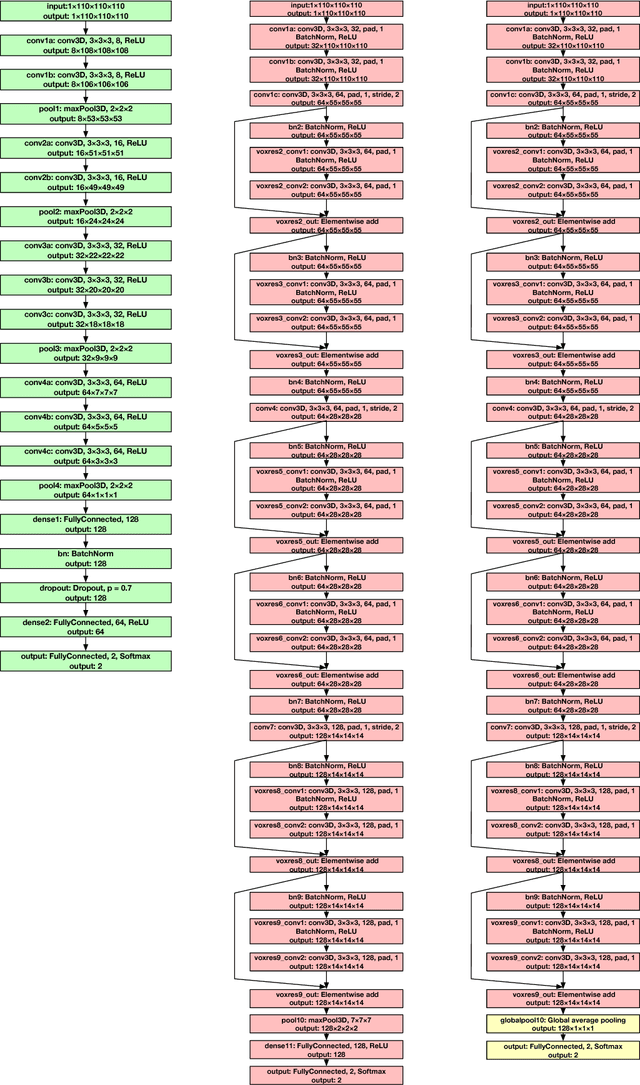

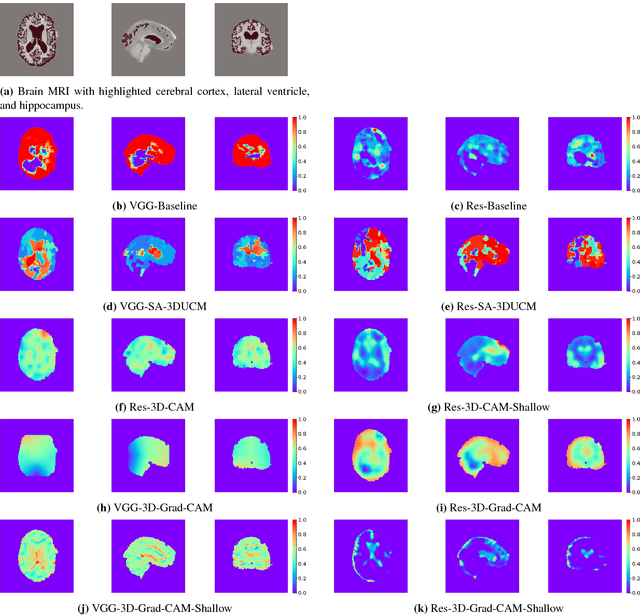
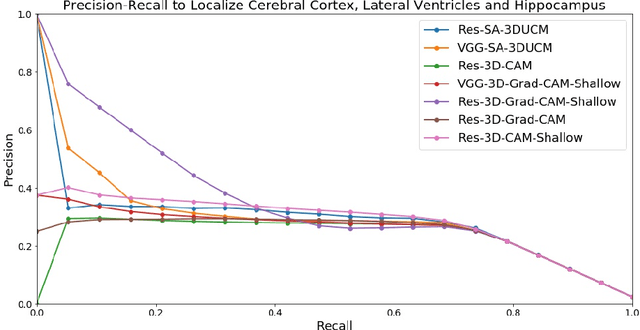
We develop three efficient approaches for generating visual explanations from 3D convolutional neural networks (3D-CNNs) for Alzheimer's disease classification. One approach conducts sensitivity analysis on hierarchical 3D image segmentation, and the other two visualize network activations on a spatial map. Visual checks and a quantitative localization benchmark indicate that all approaches identify important brain parts for Alzheimer's disease diagnosis. Comparative analysis show that the sensitivity analysis based approach has difficulty handling loosely distributed cerebral cortex, and approaches based on visualization of activations are constrained by the resolution of the convolutional layer. The complementarity of these methods improves the understanding of 3D-CNNs in Alzheimer's disease classification from different perspectives.
Global Model Interpretation via Recursive Partitioning
May 23, 2018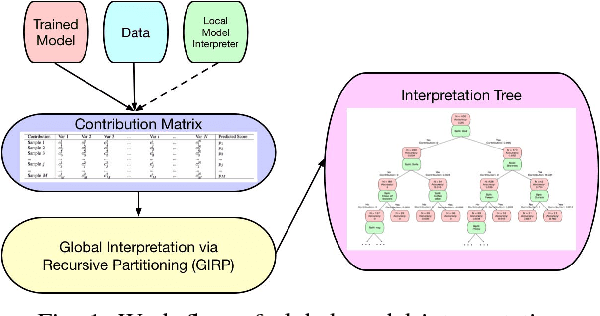

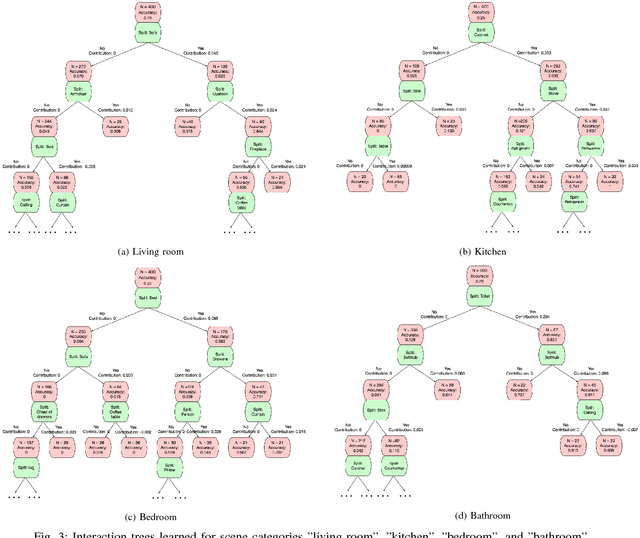
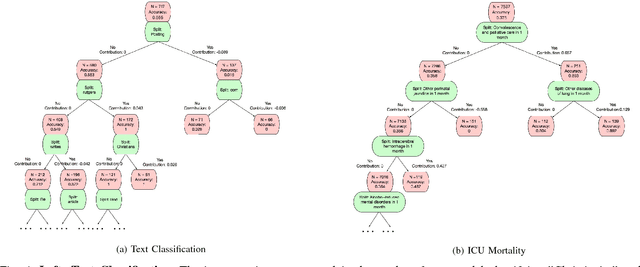
In this work, we propose a simple but effective method to interpret black-box machine learning models globally. That is, we use a compact binary tree, the interpretation tree, to explicitly represent the most important decision rules that are implicitly contained in the black-box machine learning models. This tree is learned from the contribution matrix which consists of the contributions of input variables to predicted scores for each single prediction. To generate the interpretation tree, a unified process recursively partitions the input variable space by maximizing the difference in the average contribution of the split variable between the divided spaces. We demonstrate the effectiveness of our method in diagnosing machine learning models on multiple tasks. Also, it is useful for new knowledge discovery as such insights are not easily identifiable when only looking at single predictions. In general, our work makes it easier and more efficient for human beings to understand machine learning models.