 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching People LLM's Errors and Getting it Right
Dec 24, 2025
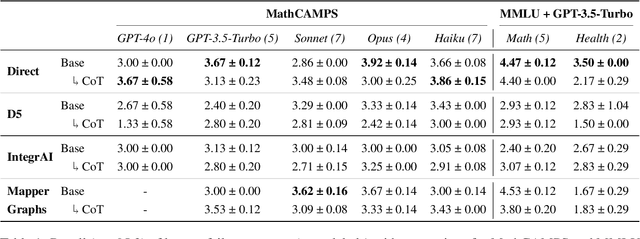
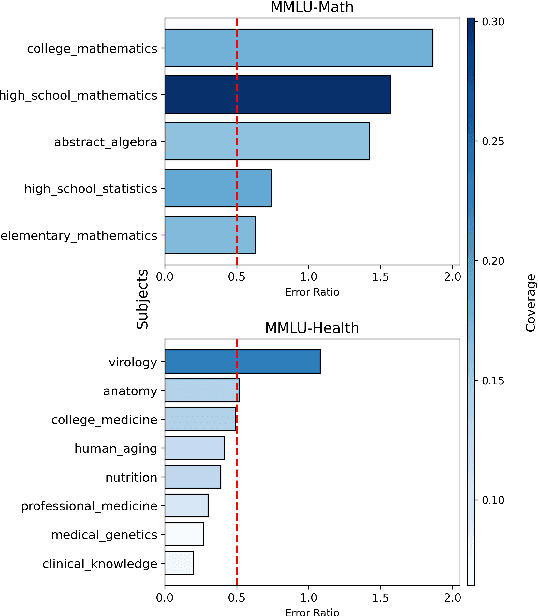
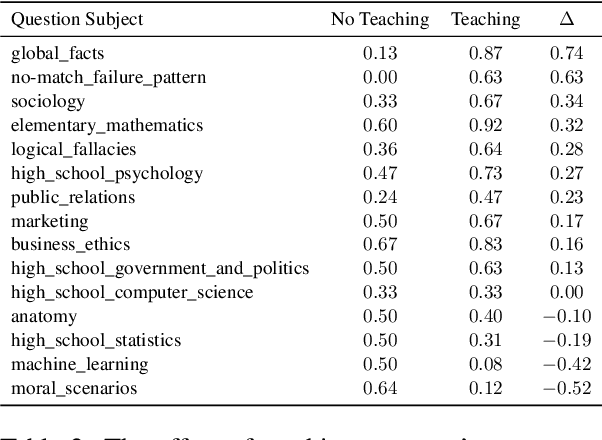
People use large language models (LLMs) when they should not. This is partly because they see LLMs compose poems and answer intricate questions, so they understandably, but incorrectly, assume LLMs won't stumble on basic tasks like simple arithmetic. Prior work has tried to address this by clustering instance embeddings into regions where an LLM is likely to fail and automatically describing patterns in these regions. The found failure patterns are taught to users to mitigate their overreliance. Yet, this approach has not fully succeeded. In this analysis paper, we aim to understand why. We first examine whether the negative result stems from the absence of failure patterns. We group instances in two datasets by their meta-labels and evaluate an LLM's predictions on these groups. We then define criteria to flag groups that are sizable and where the LLM is error-prone, and find meta-label groups that meet these criteria. Their meta-labels are the LLM's failure patterns that could be taught to users, so they do exist. We next test whether prompting and embedding-based approaches can surface these known failures. Without this, users cannot be taught about them to reduce their overreliance. We find mixed results across methods, which could explain the negative result. Finally, we revisit the final metric that measures teaching effectiveness. We propose to assess a user's ability to effectively use the given failure patterns to anticipate when an LLM is error-prone. A user study shows a positive effect from teaching with this metric, unlike the human-AI team accuracy. Our findings show that teaching failure patterns could be a viable approach to mitigating overreliance, but success depends on better automated failure-discovery methods and using metrics like ours.
BriefMe: A Legal NLP Benchmark for Assisting with Legal Briefs
Jun 07, 2025A core part of legal work that has been under-explored in Legal NLP is the writing and editing of legal briefs. This requires not only a thorough understanding of the law of a jurisdiction, from judgments to statutes, but also the ability to make new arguments to try to expand the law in a new direction and make novel and creative arguments that are persuasive to judges. To capture and evaluate these legal skills in language models, we introduce BRIEFME, a new dataset focused on legal briefs. It contains three tasks for language models to assist legal professionals in writing briefs: argument summarization, argument completion, and case retrieval. In this work, we describe the creation of these tasks, analyze them, and show how current models perform. We see that today's large language models (LLMs) are already quite good at the summarization and guided completion tasks, even beating human-generated headings. Yet, they perform poorly on other tasks in our benchmark: realistic argument completion and retrieving relevant legal cases. We hope this dataset encourages more development in Legal NLP in ways that will specifically aid people in performing legal work.
Measuring Faithfulness of Chains of Thought by Unlearning Reasoning Steps
Feb 20, 2025When prompted to think step-by-step, language models (LMs) produce a chain of thought (CoT), a sequence of reasoning steps that the model supposedly used to produce its prediction. However, despite much work on CoT prompting, it is unclear if CoT reasoning is faithful to the models' parameteric beliefs. We introduce a framework for measuring parametric faithfulness of generated reasoning, and propose Faithfulness by Unlearning Reasoning steps (FUR), an instance of this framework. FUR erases information contained in reasoning steps from model parameters. We perform experiments unlearning CoTs of four LMs prompted on four multi-choice question answering (MCQA) datasets. Our experiments show that FUR is frequently able to change the underlying models' prediction by unlearning key steps, indicating when a CoT is parametrically faithful. Further analysis shows that CoTs generated by models post-unlearning support different answers, hinting at a deeper effect of unlearning. Importantly, CoT steps identified as important by FUR do not align well with human notions of plausbility, emphasizing the need for specialized alignment
On Evaluating Explanation Utility for Human-AI Decision Making in NLP
Jul 03, 2024Is explainability a false promise? This debate has emerged from the insufficient evidence that explanations aid people in situations they are introduced for. More human-centered, application-grounded evaluations of explanations are needed to settle this. Yet, with no established guidelines for such studies in NLP, researchers accustomed to standardized proxy evaluations must discover appropriate measurements, tasks, datasets, and sensible models for human-AI teams in their studies. To help with this, we first review fitting existing metrics. We then establish requirements for datasets to be suitable for application-grounded evaluations. Among over 50 datasets available for explainability research in NLP, we find that 4 meet our criteria. By finetuning Flan-T5-3B, we demonstrate the importance of reassessing the state of the art to form and study human-AI teams. Finally, we present the exemplar studies of human-AI decision-making for one of the identified suitable tasks -- verifying the correctness of a legal claim given a contract.