 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain Tumor Radiogenomic Classification
Jan 11, 2024The RSNA-MICCAI brain tumor radiogenomic classification challenge aimed to predict MGMT biomarker status in glioblastoma through binary classification on Multi parameter mpMRI scans: T1w, T1wCE, T2w and FLAIR. The dataset is splitted into three main cohorts: training set, validation set which were used during training, and the testing were only used during final evaluation. Images were either in a DICOM format or in Png format. different architectures were used to investigate the problem including the 3D version of Vision Transformer (ViT3D), ResNet50, Xception and EfficientNet-B3. AUC was used as the main evaluation metric and the results showed an advantage for both the ViT3D and the Xception models achieving 0.6015 and 0.61745 respectively on the testing set. compared to other results, our results proved to be valid given the complexity of the task. further improvements can be made through exploring different strategies, different architectures and more diverse datasets.
Intelligent DRL-Based Adaptive Region of Interest for Delay-sensitive Telemedicine Applications
Oct 08, 2023



Telemedicine applications have recently received substantial potential and interest, especially after the COVID-19 pandemic. Remote experience will help people get their complex surgery done or transfer knowledge to local surgeons, without the need to travel abroad. Even with breakthrough improvements in internet speeds, the delay in video streaming is still a hurdle in telemedicine applications. This imposes using image compression and region of interest (ROI) techniques to reduce the data size and transmission needs. This paper proposes a Deep Reinforcement Learning (DRL) model that intelligently adapts the ROI size and non-ROI quality depending on the estimated throughput. The delay and structural similarity index measure (SSIM) comparison are used to assess the DRL model. The comparison findings and the practical application reveal that DRL is capable of reducing the delay by 13% and keeping the overall quality in an acceptable range. Since the latency has been significantly reduced, these findings are a valuable enhancement to telemedicine applications.
Zero-touch realization of Pervasive Artificial Intelligence-as-a-service in 6G networks
Jul 21, 2023



The vision of the upcoming 6G technologies, characterized by ultra-dense network, low latency, and fast data rate is to support Pervasive AI (PAI) using zero-touch solutions enabling self-X (e.g., self-configuration, self-monitoring, and self-healing) services. However, the research on 6G is still in its infancy, and only the first steps have been taken to conceptualize its design, investigate its implementation, and plan for use cases. Toward this end, academia and industry communities have gradually shifted from theoretical studies of AI distribution to real-world deployment and standardization. Still, designing an end-to-end framework that systematizes the AI distribution by allowing easier access to the service using a third-party application assisted by a zero-touch service provisioning has not been well explored. In this context, we introduce a novel platform architecture to deploy a zero-touch PAI-as-a-Service (PAIaaS) in 6G networks supported by a blockchain-based smart system. This platform aims to standardize the pervasive AI at all levels of the architecture and unify the interfaces in order to facilitate the service deployment across application and infrastructure domains, relieve the users worries about cost, security, and resource allocation, and at the same time, respect the 6G stringent performance requirements. As a proof of concept, we present a Federated Learning-as-a-service use case where we evaluate the ability of our proposed system to self-optimize and self-adapt to the dynamics of 6G networks in addition to minimizing the users' perceived costs.
* IEEE Communications Magazine
Optimal Resource Management for Hierarchical Federated Learning over HetNets with Wireless Energy Transfer
May 03, 2023



Remote monitoring systems analyze the environment dynamics in different smart industrial applications, such as occupational health and safety, and environmental monitoring. Specifically, in industrial Internet of Things (IoT) systems, the huge number of devices and the expected performance put pressure on resources, such as computational, network, and device energy. Distributed training of Machine and Deep Learning (ML/DL) models for intelligent industrial IoT applications is very challenging for resource limited devices over heterogeneous wireless networks (HetNets). Hierarchical Federated Learning (HFL) performs training at multiple layers offloading the tasks to nearby Multi-Access Edge Computing (MEC) units. In this paper, we propose a novel energy-efficient HFL framework enabled by Wireless Energy Transfer (WET) and designed for heterogeneous networks with massive Multiple-Input Multiple-Output (MIMO) wireless backhaul. Our energy-efficiency approach is formulated as a Mixed-Integer Non-Linear Programming (MINLP) problem, where we optimize the HFL device association and manage the wireless transmitted energy. However due to its high complexity, we design a Heuristic Resource Management Algorithm, namely H2RMA, that respects energy, channel quality, and accuracy constraints, while presenting a low computational complexity. We also improve the energy consumption of the network using an efficient device scheduling scheme. Finally, we investigate device mobility and its impact on the HFL performance. Our extensive experiments confirm the high performance of the proposed resource management approach in HFL over HetNets, in terms of training loss and grid energy costs.
RL-DistPrivacy: Privacy-Aware Distributed Deep Inference for low latency IoT systems
Aug 27, 2022


Although Deep Neural Networks (DNN) have become the backbone technology of several ubiquitous applications, their deployment in resource-constrained machines, e.g., Internet of Things (IoT) devices, is still challenging. To satisfy the resource requirements of such a paradigm, collaborative deep inference with IoT synergy was introduced. However, the distribution of DNN networks suffers from severe data leakage. Various threats have been presented, including black-box attacks, where malicious participants can recover arbitrary inputs fed into their devices. Although many countermeasures were designed to achieve privacy-preserving DNN, most of them result in additional computation and lower accuracy. In this paper, we present an approach that targets the security of collaborative deep inference via re-thinking the distribution strategy, without sacrificing the model performance. Particularly, we examine different DNN partitions that make the model susceptible to black-box threats and we derive the amount of data that should be allocated per device to hide proprieties of the original input. We formulate this methodology, as an optimization, where we establish a trade-off between the latency of co-inference and the privacy-level of data. Next, to relax the optimal solution, we shape our approach as a Reinforcement Learning (RL) design that supports heterogeneous devices as well as multiple DNNs/datasets.
* Published in IEEE Transactions on Network Science and Engineering
Motivating Learners in Multi-Orchestrator Mobile Edge Learning: A Stackelberg Game Approach
Sep 25, 2021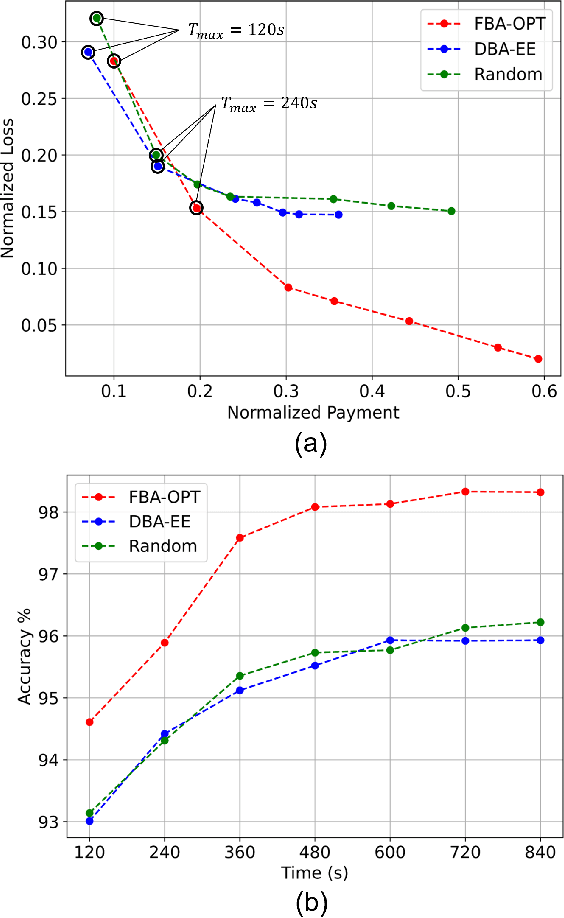
Mobile Edge Learning (MEL) is a learning paradigm that enables distributed training of Machine Learning models over heterogeneous edge devices (e.g., IoT devices). Multi-orchestrator MEL refers to the coexistence of multiple learning tasks with different datasets, each of which being governed by an orchestrator to facilitate the distributed training process. In MEL, the training performance deteriorates without the availability of sufficient training data or computing resources. Therefore, it is crucial to motivate edge devices to become learners and offer their computing resources, and either offer their private data or receive the needed data from the orchestrator and participate in the training process of a learning task. In this work, we propose an incentive mechanism, where we formulate the orchestrators-learners interactions as a 2-round Stackelberg game to motivate the participation of the learners. In the first round, the learners decide which learning task to get engaged in, and then in the second round, the amount of data for training in case of participation such that their utility is maximized. We then study the game analytically and derive the learners' optimal strategy. Finally, numerical experiments have been conducted to evaluate the performance of the proposed incentive mechanism.
Energy-Efficient Multi-Orchestrator Mobile Edge Learning
Sep 02, 2021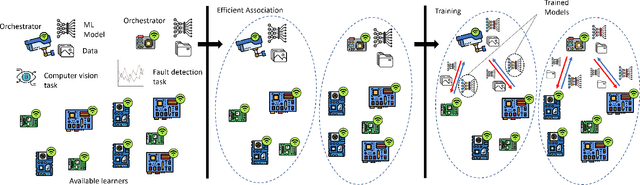
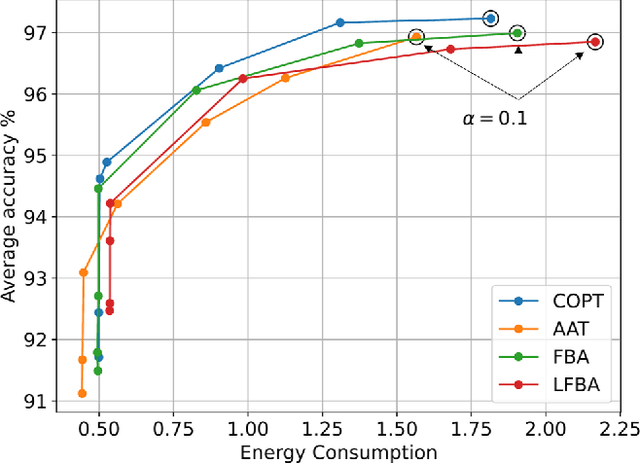
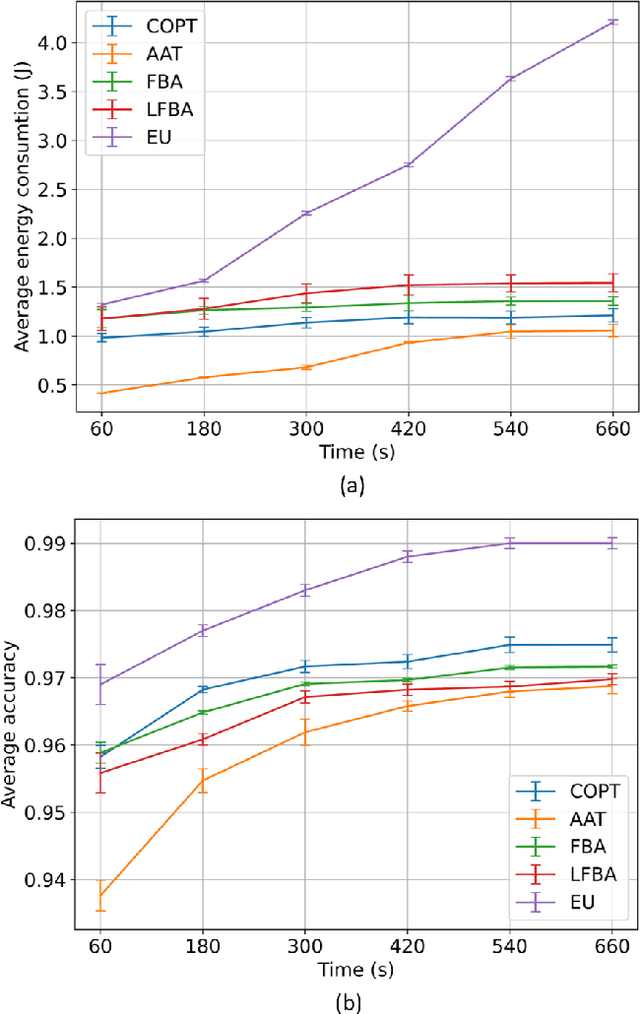
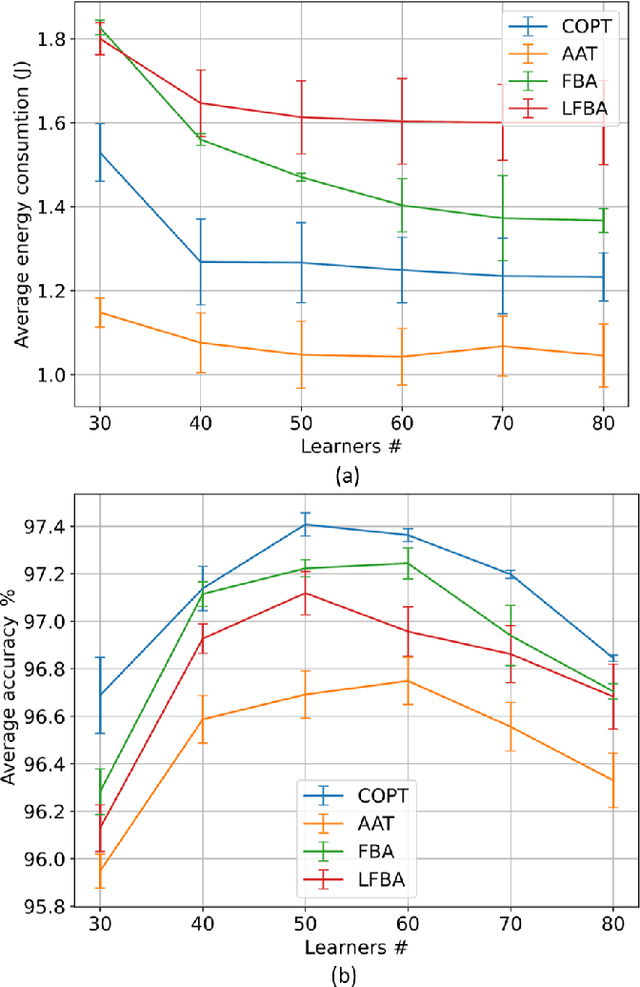
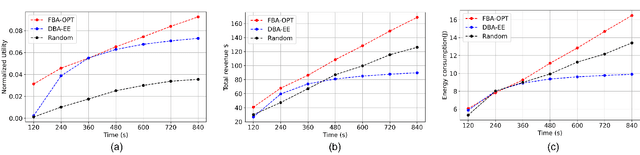
Mobile Edge Learning (MEL) is a collaborative learning paradigm that features distributed training of Machine Learning (ML) models over edge devices (e.g., IoT devices). In MEL, possible coexistence of multiple learning tasks with different datasets may arise. The heterogeneity in edge devices' capabilities will require the joint optimization of the learners-orchestrator association and task allocation. To this end, we aim to develop an energy-efficient framework for learners-orchestrator association and learning task allocation, in which each orchestrator gets associated with a group of learners with the same learning task based on their communication channel qualities and computational resources, and allocate the tasks accordingly. Therein, a multi objective optimization problem is formulated to minimize the total energy consumption and maximize the learning tasks' accuracy. However, solving such optimization problem requires centralization and the presence of the whole environment information at a single entity, which becomes impractical in large-scale systems. To reduce the solution complexity and to enable solution decentralization, we propose lightweight heuristic algorithms that can achieve near-optimal performance and facilitate the trade-offs between energy consumption, accuracy, and solution complexity. Simulation results show that the proposed approaches reduce the energy consumption significantly while executing multiple learning tasks compared to recent state-of-the-art methods.
Reinforcement Learning for Intelligent Healthcare Systems: A Comprehensive Survey
Aug 05, 2021
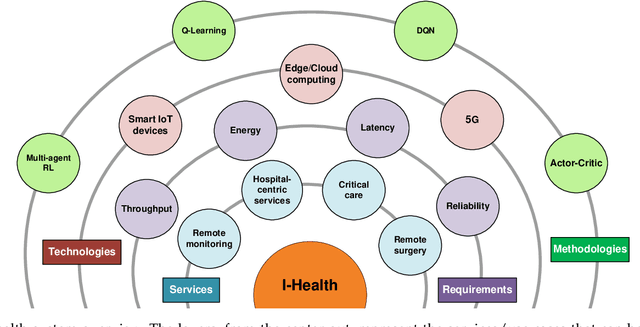

The rapid increase in the percentage of chronic disease patients along with the recent pandemic pose immediate threats on healthcare expenditure and elevate causes of death. This calls for transforming healthcare systems away from one-on-one patient treatment into intelligent health systems, to improve services, access and scalability, while reducing costs. Reinforcement Learning (RL) has witnessed an intrinsic breakthrough in solving a variety of complex problems for diverse applications and services. Thus, we conduct in this paper a comprehensive survey of the recent models and techniques of RL that have been developed/used for supporting Intelligent-healthcare (I-health) systems. This paper can guide the readers to deeply understand the state-of-the-art regarding the use of RL in the context of I-health. Specifically, we first present an overview for the I-health systems challenges, architecture, and how RL can benefit these systems. We then review the background and mathematical modeling of different RL, Deep RL (DRL), and multi-agent RL models. After that, we provide a deep literature review for the applications of RL in I-health systems. In particular, three main areas have been tackled, i.e., edge intelligence, smart core network, and dynamic treatment regimes. Finally, we highlight emerging challenges and outline future research directions in driving the future success of RL in I-health systems, which opens the door for exploring some interesting and unsolved problems.
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021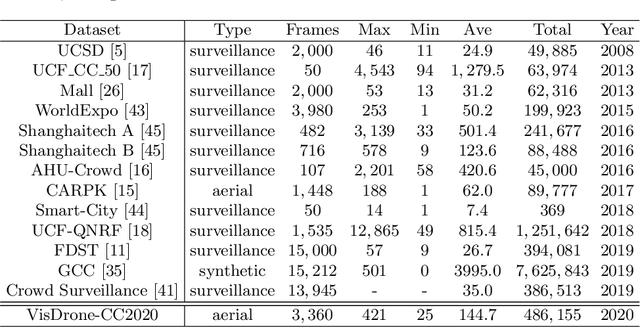

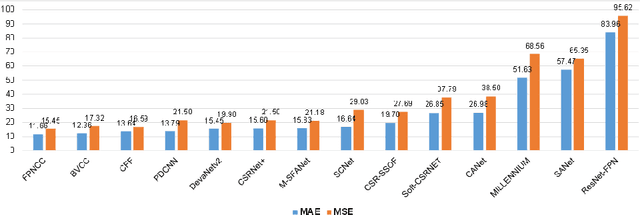
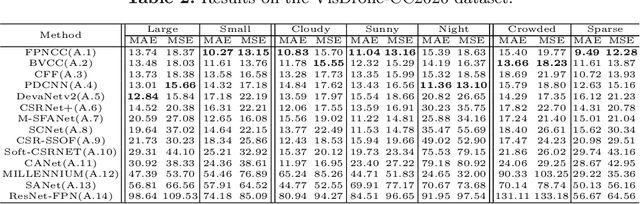
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added
Communication-Efficient Hierarchical Federated Learning for IoT Heterogeneous Systems with Imbalanced Data
Jul 14, 2021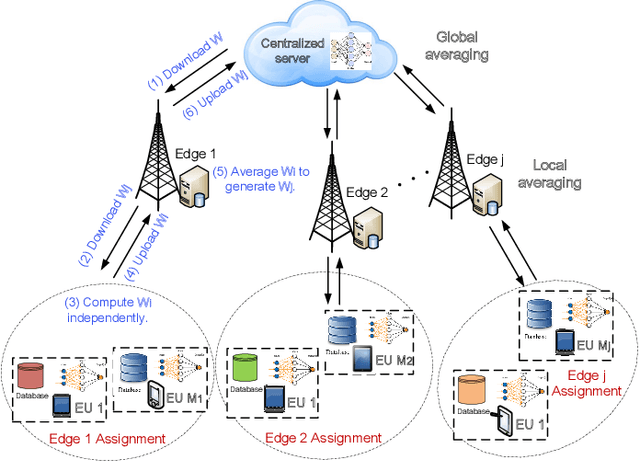

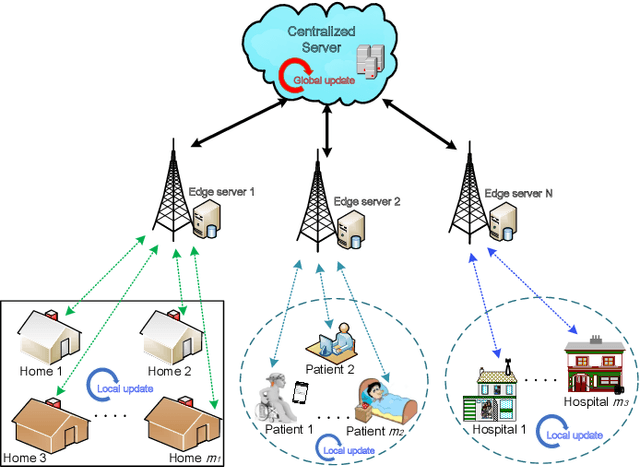
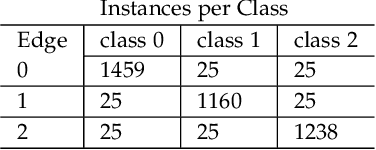
Federated learning (FL) is a distributed learning methodology that allows multiple nodes to cooperatively train a deep learning model, without the need to share their local data. It is a promising solution for telemonitoring systems that demand intensive data collection, for detection, classification, and prediction of future events, from different locations while maintaining a strict privacy constraint. Due to privacy concerns and critical communication bottlenecks, it can become impractical to send the FL updated models to a centralized server. Thus, this paper studies the potential of hierarchical FL in IoT heterogeneous systems and propose an optimized solution for user assignment and resource allocation on multiple edge nodes. In particular, this work focuses on a generic class of machine learning models that are trained using gradient-descent-based schemes while considering the practical constraints of non-uniformly distributed data across different users. We evaluate the proposed system using two real-world datasets, and we show that it outperforms state-of-the-art FL solutions. In particular, our numerical results highlight the effectiveness of our approach and its ability to provide 4-6% increase in the classification accuracy, with respect to hierarchical FL schemes that consider distance-based user assignment. Furthermore, the proposed approach could significantly accelerate FL training and reduce communication overhead by providing 75-85% reduction in the communication rounds between edge nodes and the centralized server, for the same model accuracy.