 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2SQL is Not Enough: Unifying AI and Databases with TAG
Aug 27, 2024



AI systems that serve natural language questions over databases promise to unlock tremendous value. Such systems would allow users to leverage the powerful reasoning and knowledge capabilities of language models (LMs) alongside the scalable computational power of data management systems. These combined capabilities would empower users to ask arbitrary natural language questions over custom data sources. However, existing methods and benchmarks insufficiently explore this setting. Text2SQL methods focus solely on natural language questions that can be expressed in relational algebra, representing a small subset of the questions real users wish to ask. Likewise, Retrieval-Augmented Generation (RAG) considers the limited subset of queries that can be answered with point lookups to one or a few data records within the database. We propose Table-Augmented Generation (TAG), a unified and general-purpose paradigm for answering natural language questions over databases. The TAG model represents a wide range of interactions between the LM and database that have been previously unexplored and creates exciting research opportunities for leveraging the world knowledge and reasoning capabilities of LMs over data. We systematically develop benchmarks to study the TAG problem and find that standard methods answer no more than 20% of queries correctly, confirming the need for further research in this area. We release code for the benchmark at https://github.com/TAG-Research/TAG-Bench.
NeuroCard: One Cardinality Estimator for All Tables
Jun 15, 2020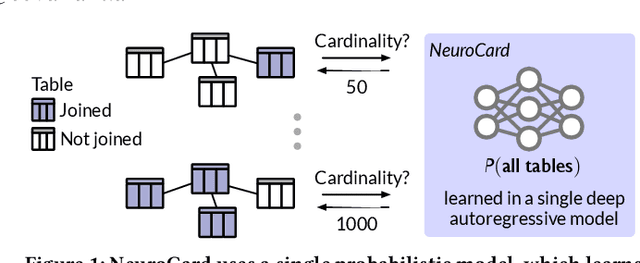
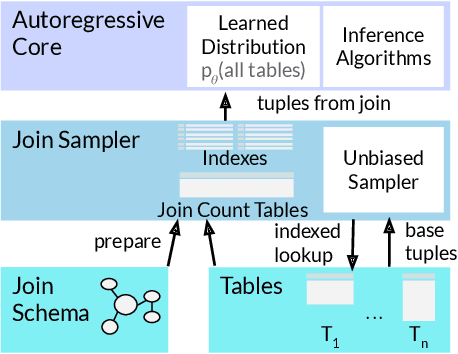
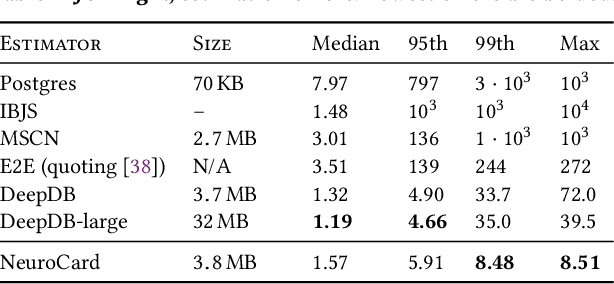
Query optimizers rely on accurate cardinality estimates to produce good execution plans. Despite decades of research, existing cardinality estimators are inaccurate for complex queries, due to making lossy modeling assumptions and not capturing inter-table correlations. In this work, we show that it is possible to learn the correlations across all tables in a database without any independence assumptions. We present NeuroCard, a join cardinality estimator that builds a single neural density estimator over an entire database. Leveraging join sampling and modern deep autoregressive models, NeuroCard makes no inter-table or inter-column independence assumptions in its probabilistic modeling. NeuroCard achieves orders of magnitude higher accuracy than the best prior methods (a new state-of-the-art result of 8.5$\times$ maximum error on JOB-light), scales to dozens of tables, while being compact in space (several MBs) and efficient to construct or update (seconds to minutes).
Selectivity Estimation with Deep Likelihood Models
May 10, 2019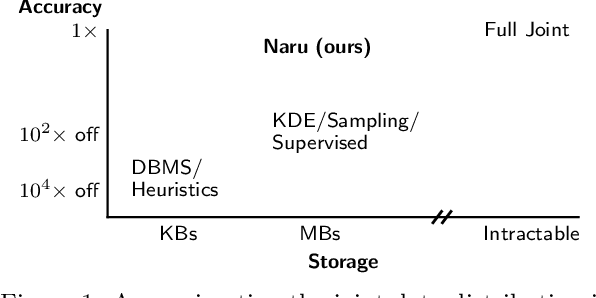
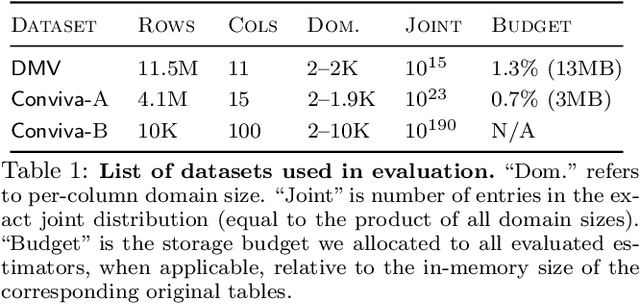
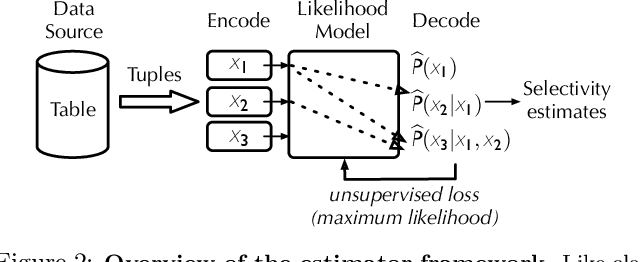
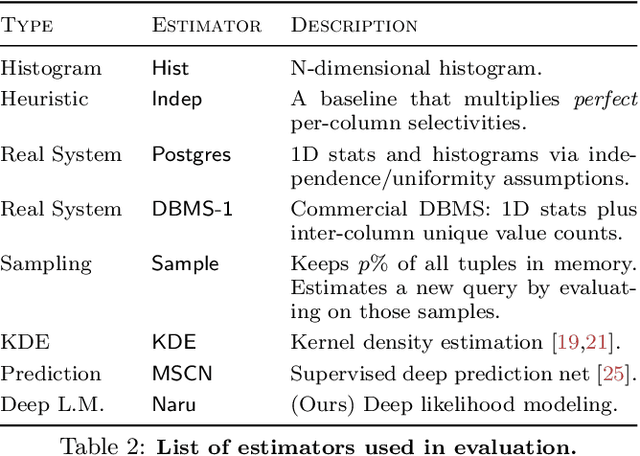
Selectivity estimation has long been grounded in statistical tools for density estimation. To capture the rich multivariate distributions of relational tables, we propose the use of a new type of high-capacity statistical model: deep likelihood models. However, direct application of these models leads to a limited estimator that is prohibitively expensive to evaluate for range and wildcard predicates. To make a truly usable estimator, we develop a Monte Carlo integration scheme on top of likelihood models that can efficiently handle range queries with dozens of filters or more. Like classical synopses, our estimator summarizes the data without supervision. Unlike previous solutions, our estimator approximates the joint data distribution without any independence assumptions. When evaluated on real-world datasets and compared against real systems and dominant families of techniques, our likelihood model based estimator achieves single-digit multiplicative error at tail, a 40-200$\times$ accuracy improvement over the second best method, and is space- and runtime-efficient.
Targeted Adversarial Examples for Black Box Audio Systems
May 20, 2018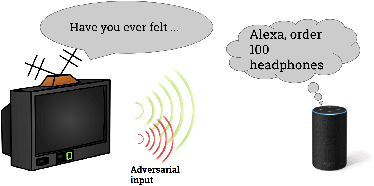
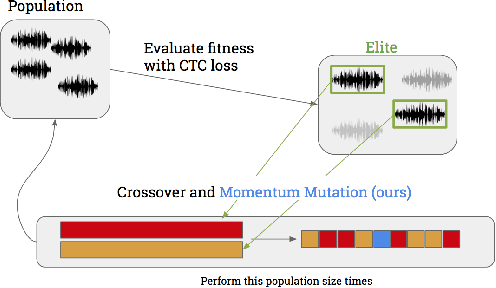
The application of deep recurrent networks to audio transcription has led to impressive gains in automatic speech recognition (ASR) systems. Many have demonstrated that small adversarial perturbations can fool deep neural networks into incorrectly predicting a specified target with high confidence. Current work on fooling ASR systems have focused on white-box attacks, in which the model architecture and parameters are known. In this paper, we adopt a black-box approach to adversarial generation, combining the approaches of both genetic algorithms and gradient estimation to solve the task. We achieve a 89.25% targeted attack similarity after 3000 generations while maintaining 94.6% audio file similarity.