 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemo Alleviate: Demonstrating Artificial Intelligence Enabled Virtual Assistance for Telehealth: The Mental Health Case
Mar 31, 2023



After the pandemic, artificial intelligence (AI) powered support for mental health care has become increasingly important. The breadth and complexity of significant challenges required to provide adequate care involve: (a) Personalized patient understanding, (b) Safety-constrained and medically validated chatbot patient interactions, and (c) Support for continued feedback-based refinements in design using chatbot-patient interactions. We propose Alleviate, a chatbot designed to assist patients suffering from mental health challenges with personalized care and assist clinicians with understanding their patients better. Alleviate draws from an array of publicly available clinically valid mental-health texts and databases, allowing Alleviate to make medically sound and informed decisions. In addition, Alleviate's modular design and explainable decision-making lends itself to robust and continued feedback-based refinements to its design. In this paper, we explain the different modules of Alleviate and submit a short video demonstrating Alleviate's capabilities to help patients and clinicians understand each other better to facilitate optimal care strategies.
Memotion 3: Dataset on Sentiment and Emotion Analysis of Codemixed Hindi-English Memes
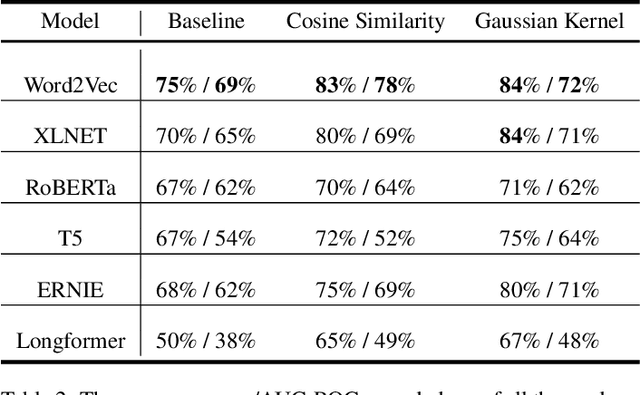
Mar 23, 2023Memes are the new-age conveyance mechanism for humor on social media sites. Memes often include an image and some text. Memes can be used to promote disinformation or hatred, thus it is crucial to investigate in details. We introduce Memotion 3, a new dataset with 10,000 annotated memes. Unlike other prevalent datasets in the domain, including prior iterations of Memotion, Memotion 3 introduces Hindi-English Codemixed memes while prior works in the area were limited to only the English memes. We describe the Memotion task, the data collection and the dataset creation methodologies. We also provide a baseline for the task. The baseline code and dataset will be made available at https://github.com/Shreyashm16/Memotion-3.0
KSAT: Knowledge-infused Self Attention Transformer -- Integrating Multiple Domain-Specific Contexts
Oct 09, 2022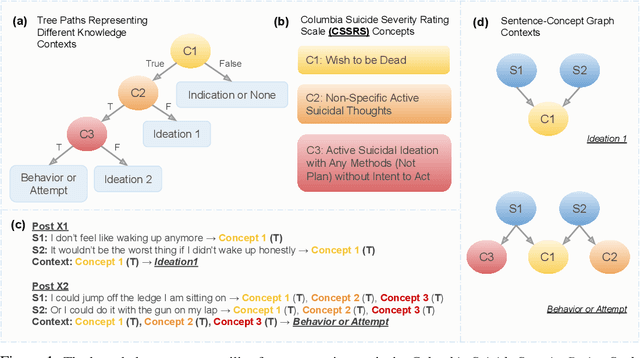

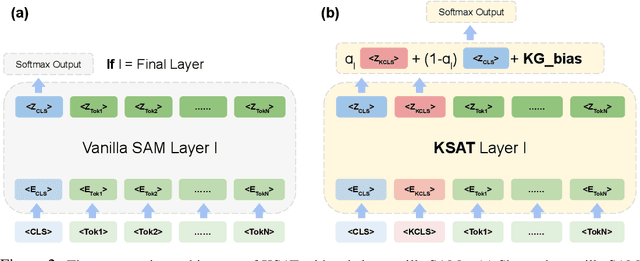
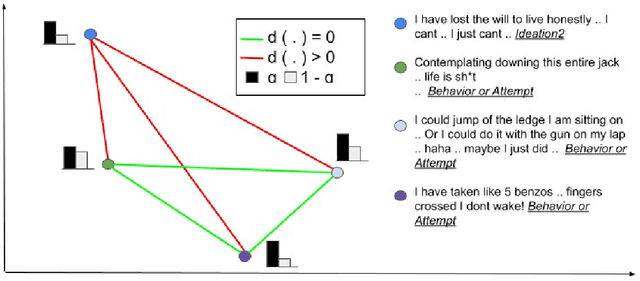
Domain-specific language understanding requires integrating multiple pieces of relevant contextual information. For example, we see both suicide and depression-related behavior (multiple contexts) in the text ``I have a gun and feel pretty bad about my life, and it wouldn't be the worst thing if I didn't wake up tomorrow''. Domain specificity in self-attention architectures is handled by fine-tuning on excerpts from relevant domain specific resources (datasets and external knowledge - medical textbook chapters on mental health diagnosis related to suicide and depression). We propose a modified self-attention architecture Knowledge-infused Self Attention Transformer (KSAT) that achieves the integration of multiple domain-specific contexts through the use of external knowledge sources. KSAT introduces knowledge-guided biases in dedicated self-attention layers for each knowledge source to accomplish this. In addition, KSAT provides mechanics for controlling the trade-off between learning from data and learning from knowledge. Our quantitative and qualitative evaluations show that (1) the KSAT architecture provides novel human-understandable ways to precisely measure and visualize the contributions of the infused domain contexts, and (2) KSAT performs competitively with other knowledge-infused baselines and significantly outperforms baselines that use fine-tuning for domain-specific tasks.
Can Language Models Capture Graph Semantics? From Graphs to Language Model and Vice-Versa
Jun 18, 2022
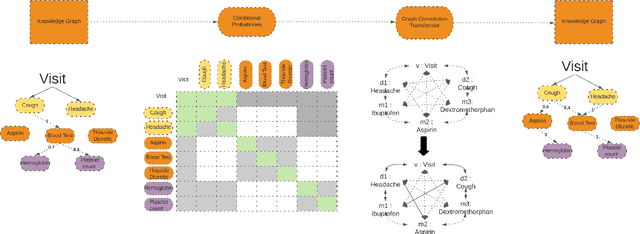
Knowledge Graphs are a great resource to capture semantic knowledge in terms of entities and relationships between the entities. However, current deep learning models takes as input distributed representations or vectors. Thus, the graph is compressed in a vectorized representation. We conduct a study to examine if the deep learning model can compress a graph and then output the same graph with most of the semantics intact. Our experiments show that Transformer models are not able to express the full semantics of the input knowledge graph. We find that this is due to the disparity between the directed, relationship and type based information contained in a Knowledge Graph and the fully connected token-token undirected graphical interpretation of the Transformer Attention matrix.
MMTM: Multi-Tasking Multi-Decoder Transformer for Math Word Problems
Jun 02, 2022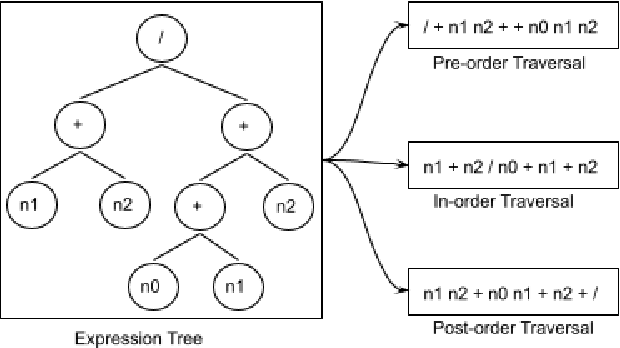
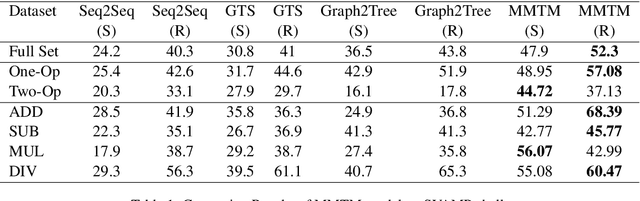
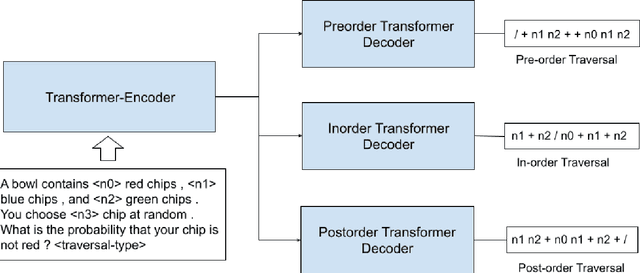

Recently, quite a few novel neural architectures were derived to solve math word problems by predicting expression trees. These architectures varied from seq2seq models, including encoders leveraging graph relationships combined with tree decoders. These models achieve good performance on various MWPs datasets but perform poorly when applied to an adversarial challenge dataset, SVAMP. We present a novel model MMTM that leverages multi-tasking and multi-decoder during pre-training. It creates variant tasks by deriving labels using pre-order, in-order and post-order traversal of expression trees, and uses task-specific decoders in a multi-tasking framework. We leverage transformer architectures with lower dimensionality and initialize weights from RoBERTa model. MMTM model achieves better mathematical reasoning ability and generalisability, which we demonstrate by outperforming the best state of the art baseline models from Seq2Seq, GTS, and Graph2Tree with a relative improvement of 19.4% on an adversarial challenge dataset SVAMP.
Learning to Automate Follow-up Question Generation using Process Knowledge for Depression Triage on Reddit Posts
May 27, 2022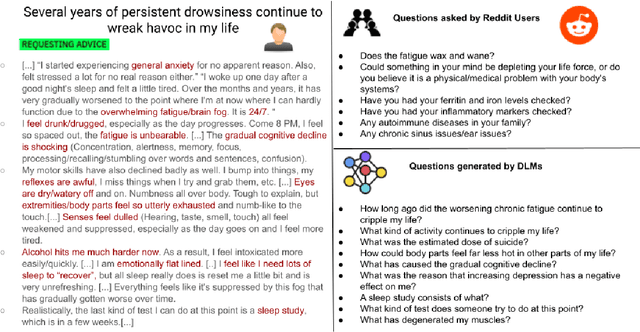

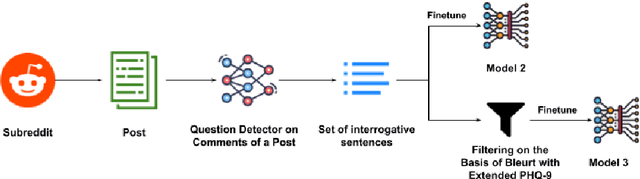
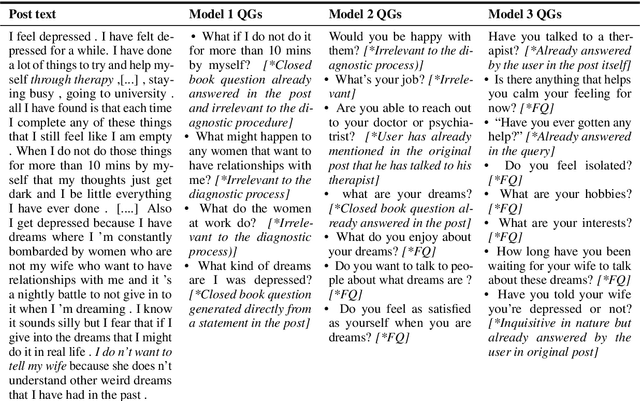
Conversational Agents (CAs) powered with deep language models (DLMs) have shown tremendous promise in the domain of mental health. Prominently, the CAs have been used to provide informational or therapeutic services to patients. However, the utility of CAs to assist in mental health triaging has not been explored in the existing work as it requires a controlled generation of follow-up questions (FQs), which are often initiated and guided by the mental health professionals (MHPs) in clinical settings. In the context of depression, our experiments show that DLMs coupled with process knowledge in a mental health questionnaire generate 12.54% and 9.37% better FQs based on similarity and longest common subsequence matches to questions in the PHQ-9 dataset respectively, when compared with DLMs without process knowledge support. Despite coupling with process knowledge, we find that DLMs are still prone to hallucination, i.e., generating redundant, irrelevant, and unsafe FQs. We demonstrate the challenge of using existing datasets to train a DLM for generating FQs that adhere to clinical process knowledge. To address this limitation, we prepared an extended PHQ-9 based dataset, PRIMATE, in collaboration with MHPs. PRIMATE contains annotations regarding whether a particular question in the PHQ-9 dataset has already been answered in the user's initial description of the mental health condition. We used PRIMATE to train a DLM in a supervised setting to identify which of the PHQ-9 questions can be answered directly from the user's post and which ones would require more information from the user. Using performance analysis based on MCC scores, we show that PRIMATE is appropriate for identifying questions in PHQ-9 that could guide generative DLMs towards controlled FQ generation suitable for aiding triaging. Dataset created as a part of this research: https://github.com/primate-mh/Primate2022
Process Knowledge-infused Learning for Suicidality Assessment on Social Media
Apr 26, 2022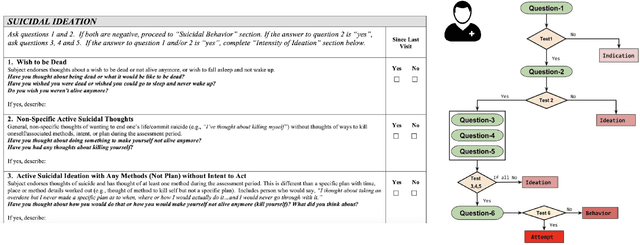

Improving the performance and natural language explanations of deep learning algorithms is a priority for adoption by humans in the real world. In several domains, such as healthcare, such technology has significant potential to reduce the burden on humans by providing quality assistance at scale. However, current methods rely on the traditional pipeline of predicting labels from data, thus completely ignoring the process and guidelines used to obtain the labels. Furthermore, post hoc explanations on the data to label prediction using explainable AI (XAI) models, while satisfactory to computer scientists, leave much to be desired to the end-users due to lacking explanations of the process in terms of human-understandable concepts. We \textit{introduce}, \textit{formalize}, and \textit{develop} a novel Artificial Intelligence (A) paradigm -- Process Knowledge-infused Learning (PK-iL). PK-iL utilizes a structured process knowledge that explicitly explains the underlying prediction process that makes sense to end-users. The qualitative human evaluation confirms through a annotator agreement of 0.72, that humans are understand explanations for the predictions. PK-iL also performs competitively with the state-of-the-art (SOTA) baselines.
Knowledge-based Entity Prediction for Improved Machine Perception in Autonomous Systems
Mar 30, 2022
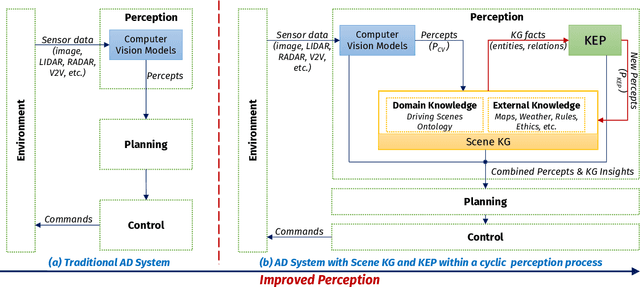
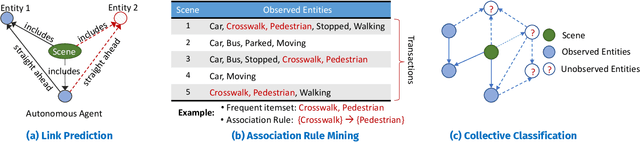
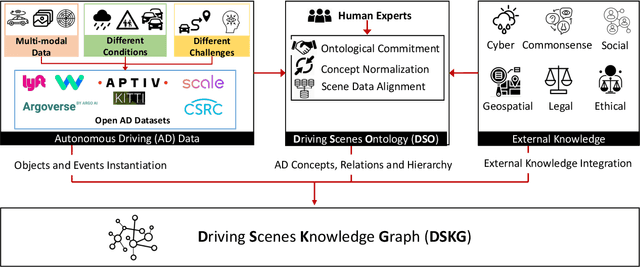
Knowledge-based entity prediction (KEP) is a novel task that aims to improve machine perception in autonomous systems. KEP leverages relational knowledge from heterogeneous sources in predicting potentially unrecognized entities. In this paper, we provide a formal definition of KEP as a knowledge completion task. Three potential solutions are then introduced, which employ several machine learning and data mining techniques. Finally, the applicability of KEP is demonstrated on two autonomous systems from different domains; namely, autonomous driving and smart manufacturing. We argue that in complex real-world systems, the use of KEP would significantly improve machine perception while pushing the current technology one step closer to achieving the full autonomy.
A Computational Approach to Understand Mental Health from Reddit: Knowledge-aware Multitask Learning Framework
Mar 22, 2022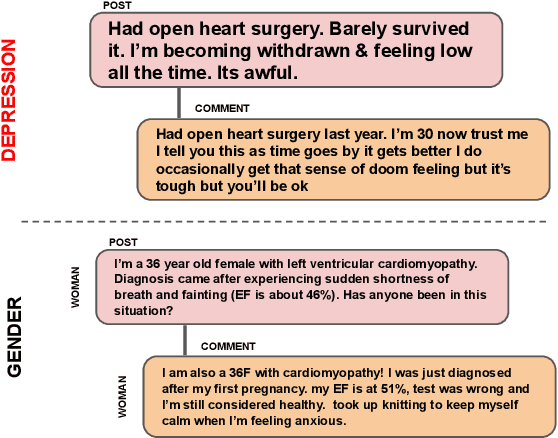
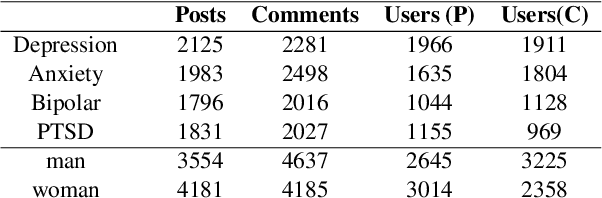

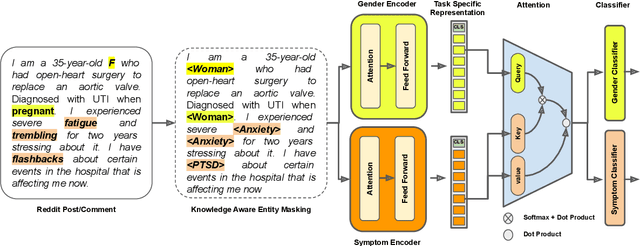
Analyzing gender is critical to study mental health (MH) support in CVD (cardiovascular disease). The existing studies on using social media for extracting MH symptoms consider symptom detection and tend to ignore user context, disease, or gender. The current study aims to design and evaluate a system to capture how MH symptoms associated with CVD are expressed differently with the gender on social media. We observe that the reliable detection of MH symptoms expressed by persons with heart disease in user posts is challenging because of the co-existence of (dis)similar MH symptoms in one post and due to variation in the description of symptoms based on gender. We collect a corpus of $150k$ items (posts and comments) annotated using the subreddit labels and transfer learning approaches. We propose GeM, a novel task-adaptive multi-task learning approach to identify the MH symptoms in CVD patients based on gender. Specifically, we adapt a knowledge-assisted RoBERTa based bi-encoder model to capture CVD-related MH symptoms. Moreover, it enhances the reliability for differentiating the gender language in MH symptoms when compared to the state-of-art language models. Our model achieves high (statistically significant) performance and predicts four labels of MH issues and two gender labels, which outperforms RoBERTa, improving the recall by 2.14% on the symptom identification task and by 2.55% on the gender identification task.
CausalKG: Causal Knowledge Graph Explainability using interventional and counterfactual reasoning
Jan 06, 2022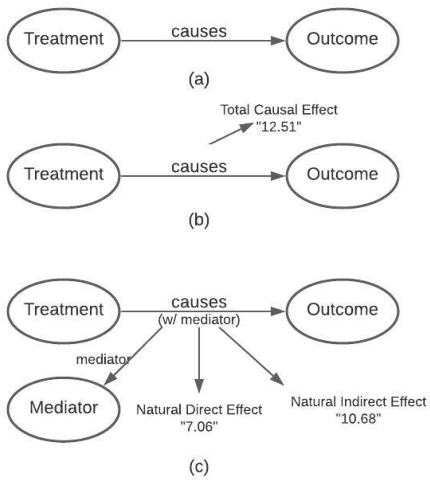
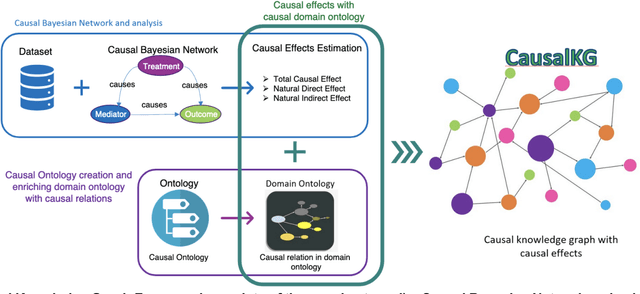
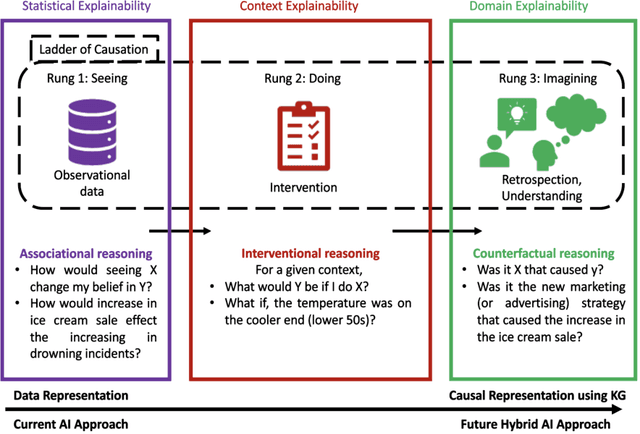
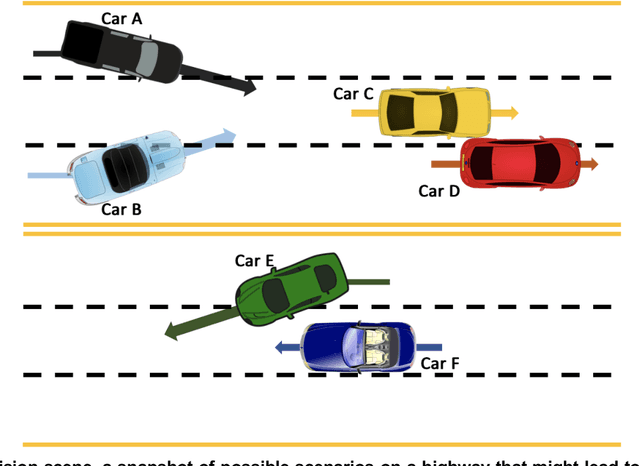
Humans use causality and hypothetical retrospection in their daily decision-making, planning, and understanding of life events. The human mind, while retrospecting a given situation, think about questions such as "What was the cause of the given situation?", "What would be the effect of my action?", or "Which action led to this effect?". It develops a causal model of the world, which learns with fewer data points, makes inferences, and contemplates counterfactual scenarios. The unseen, unknown, scenarios are known as counterfactuals. AI algorithms use a representation based on knowledge graphs (KG) to represent the concepts of time, space, and facts. A KG is a graphical data model which captures the semantic relationships between entities such as events, objects, or concepts. The existing KGs represent causal relationships extracted from texts based on linguistic patterns of noun phrases for causes and effects as in ConceptNet and WordNet. The current causality representation in KGs makes it challenging to support counterfactual reasoning. A richer representation of causality in AI systems using a KG-based approach is needed for better explainability, and support for intervention and counterfactuals reasoning, leading to improved understanding of AI systems by humans. The causality representation requires a higher representation framework to define the context, the causal information, and the causal effects. The proposed Causal Knowledge Graph (CausalKG) framework, leverages recent progress of causality and KG towards explainability. CausalKG intends to address the lack of a domain adaptable causal model and represent the complex causal relations using the hyper-relational graph representation in the KG. We show that the CausalKG's interventional and counterfactual reasoning can be used by the AI system for the domain explainability.