 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Multi-Object Relationships for Detecting Adversarial Attacks in Complex Scenes
Aug 19, 2021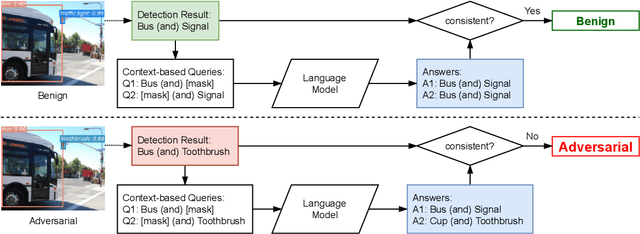
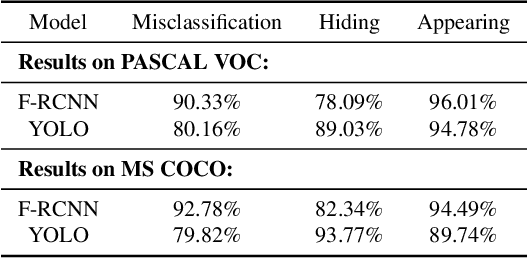
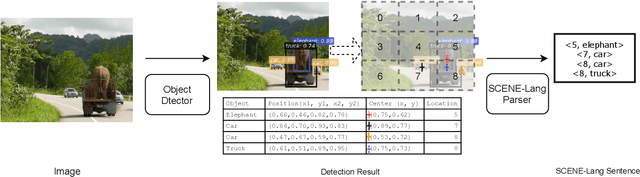
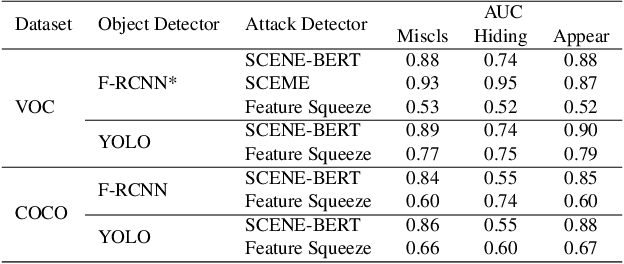
Vision systems that deploy Deep Neural Networks (DNNs) are known to be vulnerable to adversarial examples. Recent research has shown that checking the intrinsic consistencies in the input data is a promising way to detect adversarial attacks (e.g., by checking the object co-occurrence relationships in complex scenes). However, existing approaches are tied to specific models and do not offer generalizability. Motivated by the observation that language descriptions of natural scene images have already captured the object co-occurrence relationships that can be learned by a language model, we develop a novel approach to perform context consistency checks using such language models. The distinguishing aspect of our approach is that it is independent of the deployed object detector and yet offers very high accuracy in terms of detecting adversarial examples in practical scenes with multiple objects.
Spatio-Temporal Representation Factorization for Video-based Person Re-Identification
Aug 15, 2021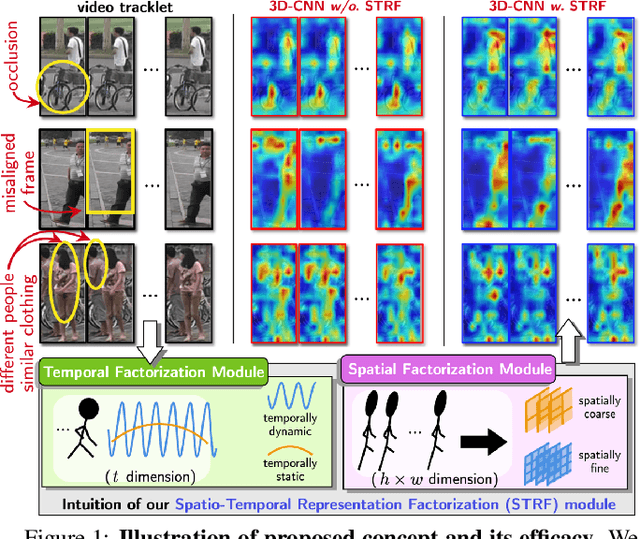
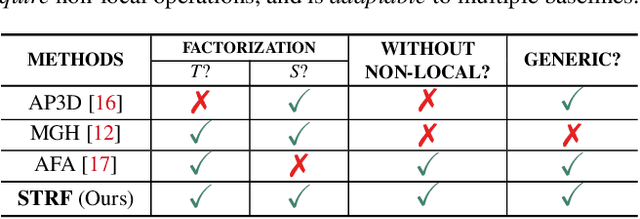

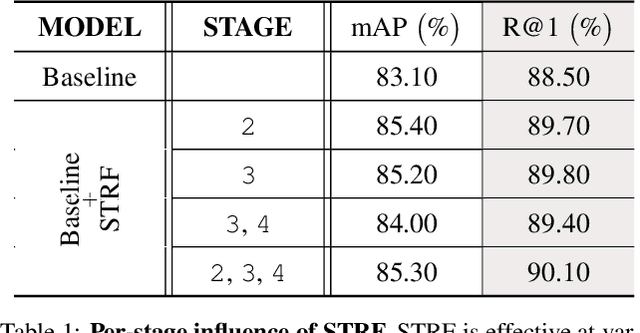
Despite much recent progress in video-based person re-identification (re-ID), the current state-of-the-art still suffers from common real-world challenges such as appearance similarity among various people, occlusions, and frame misalignment. To alleviate these problems, we propose Spatio-Temporal Representation Factorization (STRF), a flexible new computational unit that can be used in conjunction with most existing 3D convolutional neural network architectures for re-ID. The key innovations of STRF over prior work include explicit pathways for learning discriminative temporal and spatial features, with each component further factorized to capture complementary person-specific appearance and motion information. Specifically, temporal factorization comprises two branches, one each for static features (e.g., the color of clothes) that do not change much over time, and dynamic features (e.g., walking patterns) that change over time. Further, spatial factorization also comprises two branches to learn both global (coarse segments) as well as local (finer segments) appearance features, with the local features particularly useful in cases of occlusion or spatial misalignment. These two factorization operations taken together result in a modular architecture for our parameter-wise light STRF unit that can be plugged in between any two 3D convolutional layers, resulting in an end-to-end learning framework. We empirically show that STRF improves performance of various existing baseline architectures while demonstrating new state-of-the-art results using standard person re-ID evaluation protocols on three benchmarks.
Ada-VSR: Adaptive Video Super-Resolution with Meta-Learning
Aug 05, 2021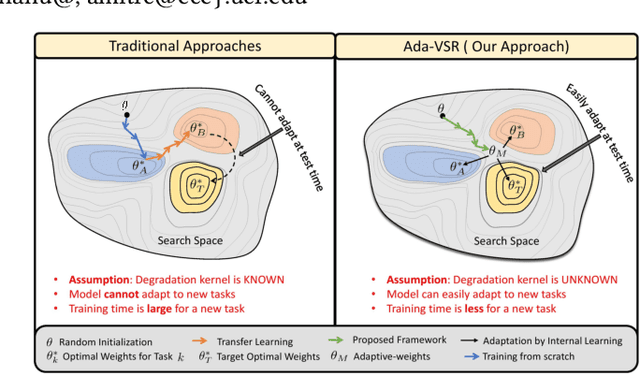
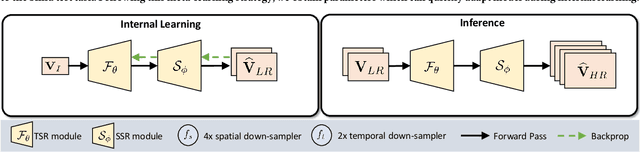
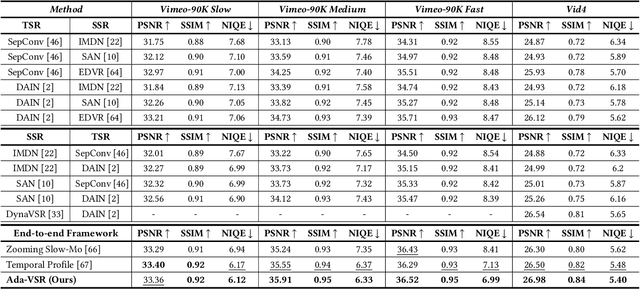
Most of the existing works in supervised spatio-temporal video super-resolution (STVSR) heavily rely on a large-scale external dataset consisting of paired low-resolution low-frame rate (LR-LFR)and high-resolution high-frame-rate (HR-HFR) videos. Despite their remarkable performance, these methods make a prior assumption that the low-resolution video is obtained by down-scaling the high-resolution video using a known degradation kernel, which does not hold in practical settings. Another problem with these methods is that they cannot exploit instance-specific internal information of video at testing time. Recently, deep internal learning approaches have gained attention due to their ability to utilize the instance-specific statistics of a video. However, these methods have a large inference time as they require thousands of gradient updates to learn the intrinsic structure of the data. In this work, we presentAdaptiveVideoSuper-Resolution (Ada-VSR) which leverages external, as well as internal, information through meta-transfer learning and internal learning, respectively. Specifically, meta-learning is employed to obtain adaptive parameters, using a large-scale external dataset, that can adapt quickly to the novel condition (degradation model) of the given test video during the internal learning task, thereby exploiting external and internal information of a video for super-resolution. The model trained using our approach can quickly adapt to a specific video condition with only a few gradient updates, which reduces the inference time significantly. Extensive experiments on standard datasets demonstrate that our method performs favorably against various state-of-the-art approaches.
Learning Few-shot Open-set Classifiers using Exemplar Reconstruction
Jul 31, 2021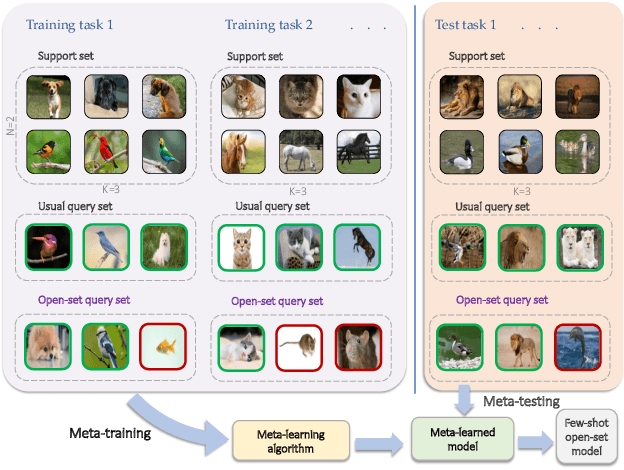
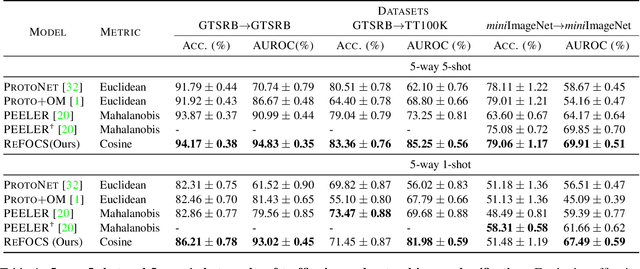
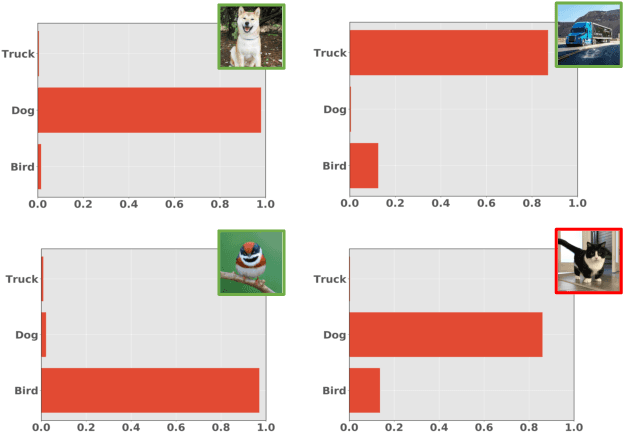
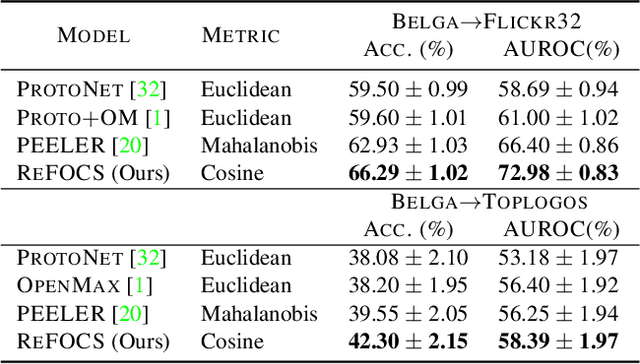
We study the problem of how to identify samples from unseen categories (open-set classification) when there are only a few samples given from the seen categories (few-shot setting). The challenge of learning a good abstraction for a class with very few samples makes it extremely difficult to detect samples from the unseen categories; consequently, open-set recognition has received minimal attention in the few-shot setting. Most open-set few-shot classification methods regularize the softmax score to indicate uniform probability for open class samples but we argue that this approach is often inaccurate, especially at a fine-grained level. Instead, we propose a novel exemplar reconstruction-based meta-learning strategy for jointly detecting open class samples, as well as, categorizing samples from seen classes via metric-based classification. The exemplars, which act as representatives of a class, can either be provided in the training dataset or estimated in the feature domain. Our framework, named Reconstructing Exemplar based Few-shot Open-set ClaSsifier (ReFOCS), is tested on a wide variety of datasets and the experimental results clearly highlight our method as the new state of the art.
Deep Quantized Representation for Enhanced Reconstruction
Jul 29, 2021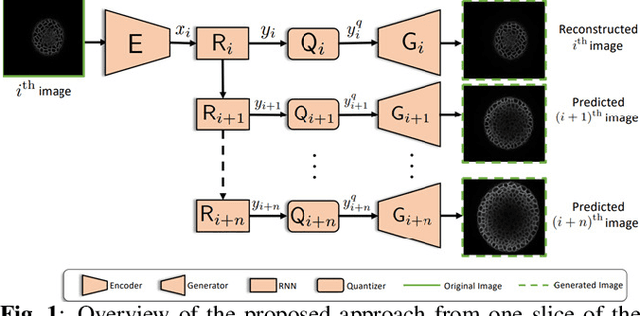
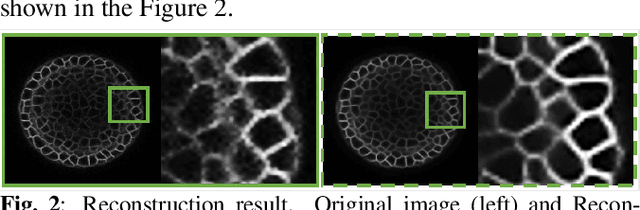
While machine learning approaches have shown remarkable performance in biomedical image analysis, most of these methods rely on high-quality and accurate imaging data. However, collecting such data requires intensive and careful manual effort. One of the major challenges in imaging the Shoot Apical Meristem (SAM) of Arabidopsis thaliana, is that the deeper slices in the z-stack suffer from different perpetual quality-related problems like poor contrast and blurring. These quality-related issues often lead to the disposal of the painstakingly collected data with little to no control on quality while collecting the data. Therefore, it becomes necessary to employ and design techniques that can enhance the images to make them more suitable for further analysis. In this paper, we propose a data-driven Deep Quantized Latent Representation (DQLR) methodology for high-quality image reconstruction in the Shoot Apical Meristem (SAM) of Arabidopsis thaliana. Our proposed framework utilizes multiple consecutive slices in the z-stack to learn a low dimensional latent space, quantize it and subsequently perform reconstruction using the quantized representation to obtain sharper images. Experiments on a publicly available dataset validate our methodology showing promising results.
Cross-domain Imitation from Observations
May 20, 2021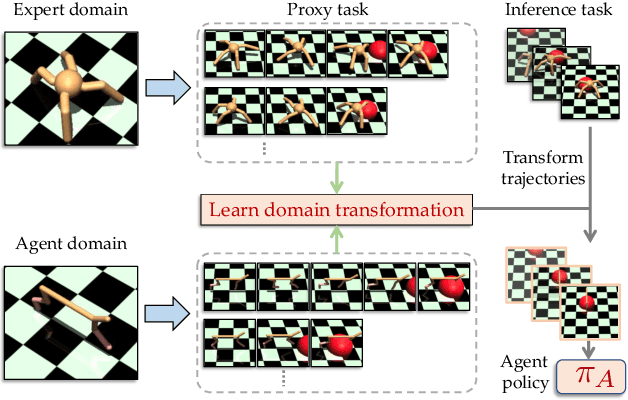

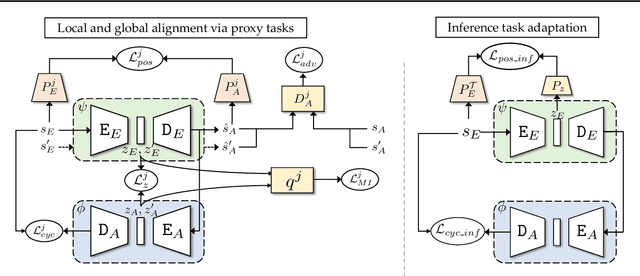
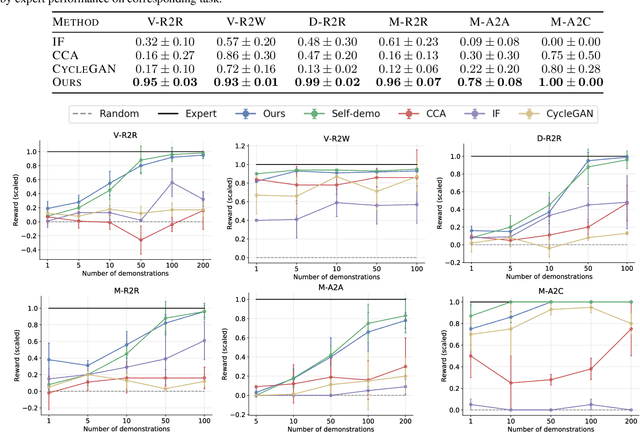
Imitation learning seeks to circumvent the difficulty in designing proper reward functions for training agents by utilizing expert behavior. With environments modeled as Markov Decision Processes (MDP), most of the existing imitation algorithms are contingent on the availability of expert demonstrations in the same MDP as the one in which a new imitation policy is to be learned. In this paper, we study the problem of how to imitate tasks when there exist discrepancies between the expert and agent MDP. These discrepancies across domains could include differing dynamics, viewpoint, or morphology; we present a novel framework to learn correspondences across such domains. Importantly, in contrast to prior works, we use unpaired and unaligned trajectories containing only states in the expert domain, to learn this correspondence. We utilize a cycle-consistency constraint on both the state space and a domain agnostic latent space to do this. In addition, we enforce consistency on the temporal position of states via a normalized position estimator function, to align the trajectories across the two domains. Once this correspondence is found, we can directly transfer the demonstrations on one domain to the other and use it for imitation. Experiments across a wide variety of challenging domains demonstrate the efficacy of our approach.
Unsupervised Multi-source Domain Adaptation Without Access to Source Data
Apr 05, 2021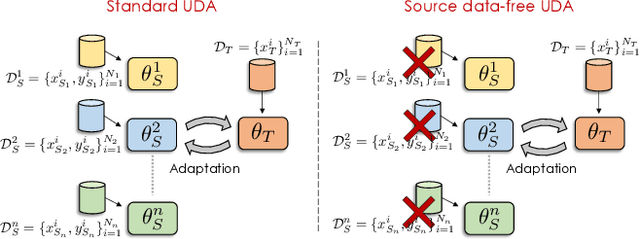

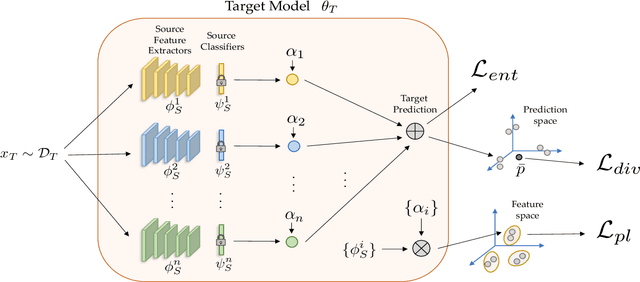
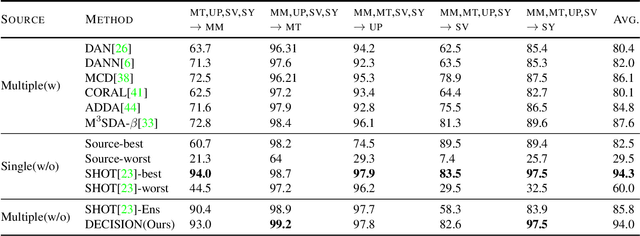
Unsupervised Domain Adaptation (UDA) aims to learn a predictor model for an unlabeled domain by transferring knowledge from a separate labeled source domain. However, most of these conventional UDA approaches make the strong assumption of having access to the source data during training, which may not be very practical due to privacy, security and storage concerns. A recent line of work addressed this problem and proposed an algorithm that transfers knowledge to the unlabeled target domain from a single source model without requiring access to the source data. However, for adaptation purposes, if there are multiple trained source models available to choose from, this method has to go through adapting each and every model individually, to check for the best source. Thus, we ask the question: can we find the optimal combination of source models, with no source data and without target labels, whose performance is no worse than the single best source? To answer this, we propose a novel and efficient algorithm which automatically combines the source models with suitable weights in such a way that it performs at least as good as the best source model. We provide intuitive theoretical insights to justify our claim. Furthermore, extensive experiments are conducted on several benchmark datasets to show the effectiveness of our algorithm, where in most cases, our method not only reaches best source accuracy but also outperforms it.
Detection and Localization of Facial Expression Manipulations
Mar 15, 2021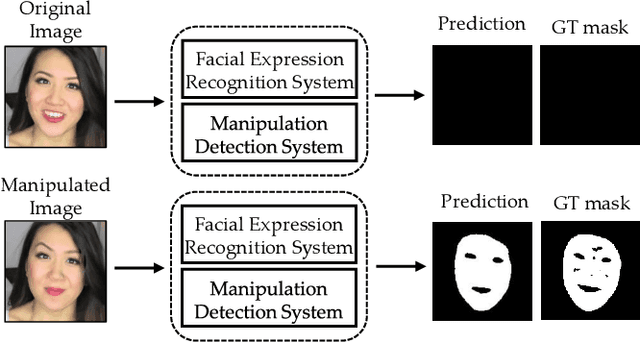
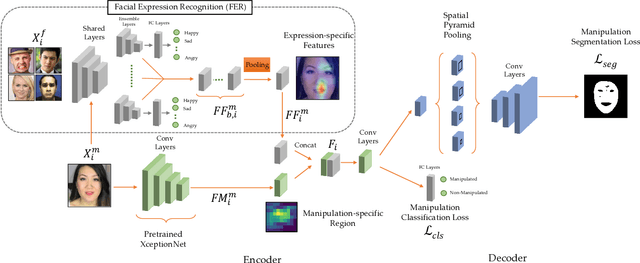

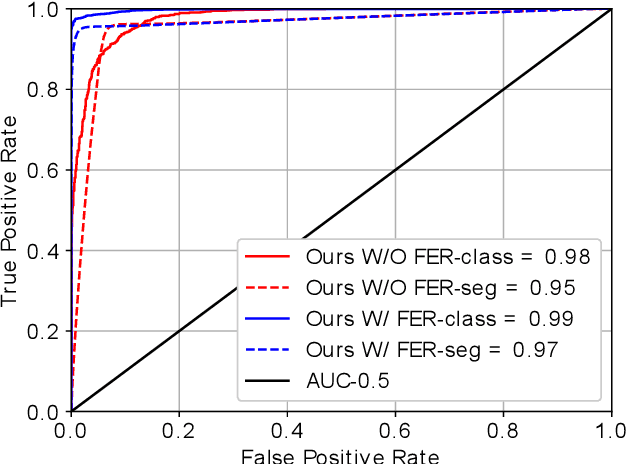
Concern regarding the wide-spread use of fraudulent images/videos in social media necessitates precise detection of such fraud. The importance of facial expressions in communication is widely known, and adversarial attacks often focus on manipulating the expression related features. Thus, it is important to develop methods that can detect manipulations in facial expressions, and localize the manipulated regions. To address this problem, we propose a framework that is able to detect manipulations in facial expression using a close combination of facial expression recognition and image manipulation methods. With the addition of feature maps extracted from the facial expression recognition framework, our manipulation detector is able to localize the manipulated region. We show that, on the Face2Face dataset, where there is abundant expression manipulation, our method achieves over 3% higher accuracy for both classification and localization of manipulations compared to state-of-the-art methods. In addition, results on the NeuralTextures dataset where the facial expressions corresponding to the mouth regions have been modified, show 2% higher accuracy in both classification and localization of manipulation. We demonstrate that the method performs at-par with the state-of-the-art methods in cases where the expression is not manipulated, but rather the identity is changed, thus ensuring generalizability of the approach.
Learning to identify image manipulations in scientific publications
Feb 03, 2021

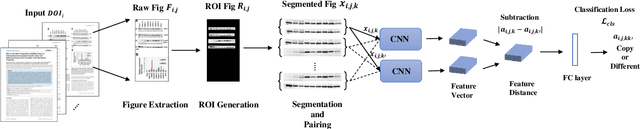

Adherence to scientific community standards ensures objectivity, clarity, reproducibility, and helps prevent bias, fabrication, falsification, and plagiarism. To help scientific integrity officers and journal/publisher reviewers monitor if researchers stick with these standards, it is important to have a solid procedure to detect duplication as one of the most frequent types of manipulation in scientific papers. Images in scientific papers are used to support the experimental description and the discussion of the findings. Therefore, in this work we focus on detecting the duplications in images as one of the most important parts of a scientific paper. We propose a framework that combines image processing and deep learning methods to classify images in the articles as duplicated or unduplicated ones. We show that our method leads to a 90% accuracy rate of detecting duplicated images, a ~ 13% improvement in detection accuracy in comparison to other manipulation detection methods. We also show how effective the pre-processing steps are by comparing our method to other state-of-art manipulation detectors which lack these steps.
Exploiting Context for Robustness to Label Noise in Active Learning
Oct 18, 2020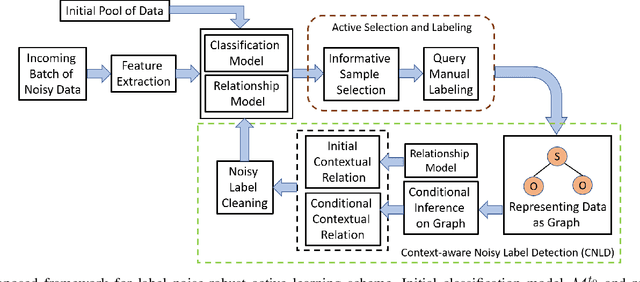
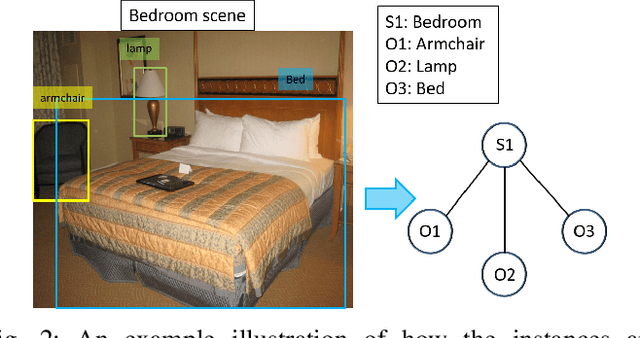
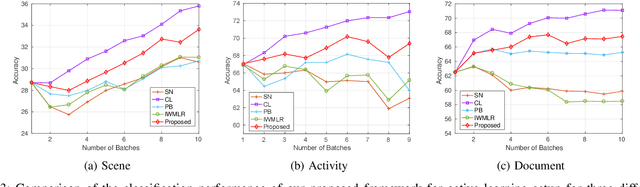
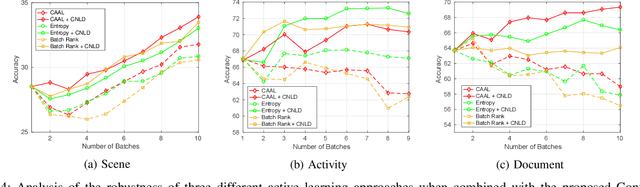
Several works in computer vision have demonstrated the effectiveness of active learning for adapting the recognition model when new unlabeled data becomes available. Most of these works consider that labels obtained from the annotator are correct. However, in a practical scenario, as the quality of the labels depends on the annotator, some of the labels might be wrong, which results in degraded recognition performance. In this paper, we address the problems of i) how a system can identify which of the queried labels are wrong and ii) how a multi-class active learning system can be adapted to minimize the negative impact of label noise. Towards solving the problems, we propose a noisy label filtering based learning approach where the inter-relationship (context) that is quite common in natural data is utilized to detect the wrong labels. We construct a graphical representation of the unlabeled data to encode these relationships and obtain new beliefs on the graph when noisy labels are available. Comparing the new beliefs with the prior relational information, we generate a dissimilarity score to detect the incorrect labels and update the recognition model with correct labels which result in better recognition performance. This is demonstrated in three different applications: scene classification, activity classification, and document classification.