 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


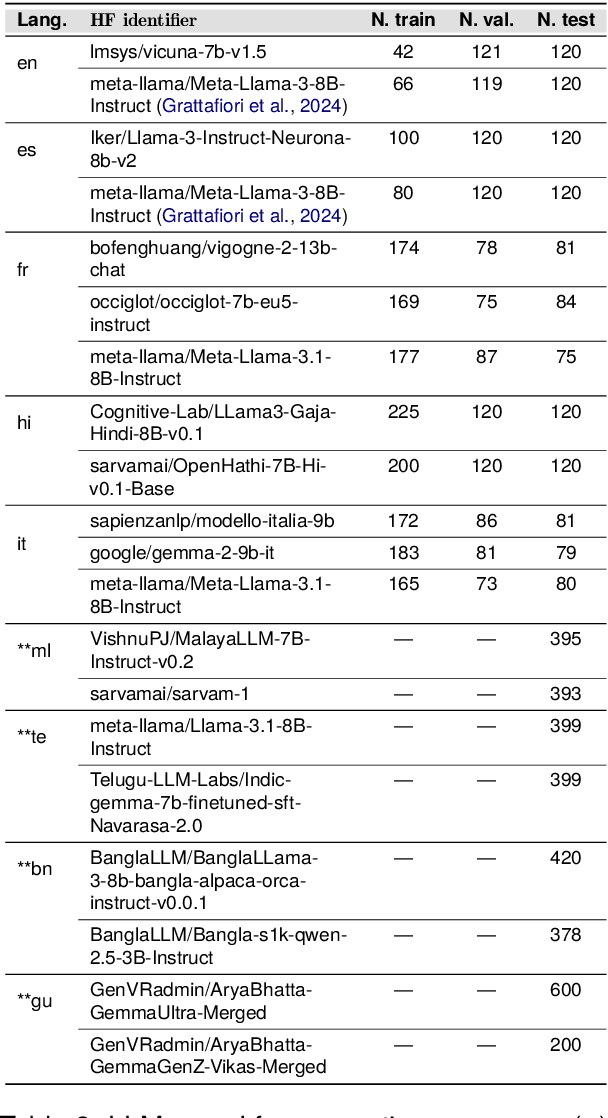
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
Chain-of-MetaWriting: Linguistic and Textual Analysis of How Small Language Models Write Young Students Texts
Dec 19, 2024Large Language Models (LLMs) have been used to generate texts in response to different writing tasks: reports, essays, story telling. However, language models do not have a meta-representation of the text writing process, nor inherent communication learning needs, comparable to those of young human students. This paper introduces a fine-grained linguistic and textual analysis of multilingual Small Language Models' (SLMs) writing. With our method, Chain-of-MetaWriting, SLMs can imitate some steps of the human writing process, such as planning and evaluation. We mainly focused on short story and essay writing tasks in French for schoolchildren and undergraduate students respectively. Our results show that SLMs encounter difficulties in assisting young students on sensitive topics such as violence in the schoolyard, and they sometimes use words too complex for the target audience. In particular, the output is quite different from the human produced texts in term of text cohesion and coherence regarding temporal connectors, topic progression, reference.
Retrieve, Generate, Evaluate: A Case Study for Medical Paraphrases Generation with Small Language Models
Jul 23, 2024Recent surge in the accessibility of large language models (LLMs) to the general population can lead to untrackable use of such models for medical-related recommendations. Language generation via LLMs models has two key problems: firstly, they are prone to hallucination and therefore, for any medical purpose they require scientific and factual grounding; secondly, LLMs pose tremendous challenge to computational resources due to their gigantic model size. In this work, we introduce pRAGe, a pipeline for Retrieval Augmented Generation and evaluation of medical paraphrases generation using Small Language Models (SLM). We study the effectiveness of SLMs and the impact of external knowledge base for medical paraphrase generation in French.