 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAL: Program-aided Language Models
Nov 18, 2022



Large language models (LLMs) have recently demonstrated an impressive ability to perform arithmetic and symbolic reasoning tasks when provided with a few examples at test time (few-shot prompting). Much of this success can be attributed to prompting methods for reasoning, such as chain-of-thought, that employ LLMs for both understanding the problem description by decomposing it into steps, as well as solving each step of the problem. While LLMs seem to be adept at this sort of step-by-step decomposition, LLMs often make logical and arithmetic mistakes in the solution part, even when the problem is correctly decomposed. We present Program-Aided Language models (PaL): a new method that uses the LLM to understand natural language problems and generate programs as the intermediate reasoning steps, but offloads the solution step to a programmatic runtime such as a Python interpreter. With PaL, decomposing the natural language problem into runnable steps remains the only learning task for the LLM, while solving is delegated to the interpreter. We experiment with 12 reasoning tasks from BIG-Bench Hard and other benchmarks, including mathematical reasoning, symbolic reasoning, and algorithmic problems. In all these natural language reasoning tasks, generating code using an LLM and reasoning using a Python interpreter leads to more accurate results than much larger models, and we set new state-of-the-art results in all 12 benchmarks. For example, PaL using Codex achieves state-of-the-art few-shot accuracy on the GSM benchmark of math word problems when the model is allowed only a single decoding, surpassing PaLM-540B with chain-of-thought prompting by an absolute 8% .In three reasoning tasks from the BIG-Bench Hard benchmark, PaL outperforms CoT by 11%. On GSM-hard, a more challenging version of GSM that we create, PaL outperforms chain-of-thought by an absolute 40%.
Language Models of Code are Few-Shot Commonsense Learners
Oct 13, 2022
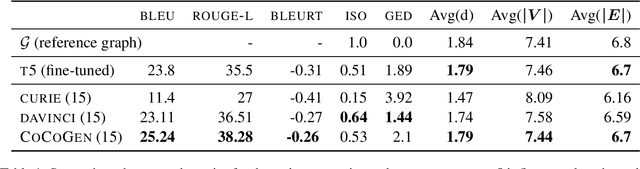

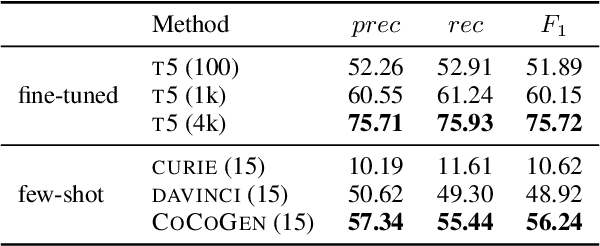
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event -- or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches ``serialize'' the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T5) and other strong LMs such as GPT-3 in the few-shot setting.
Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango
Sep 16, 2022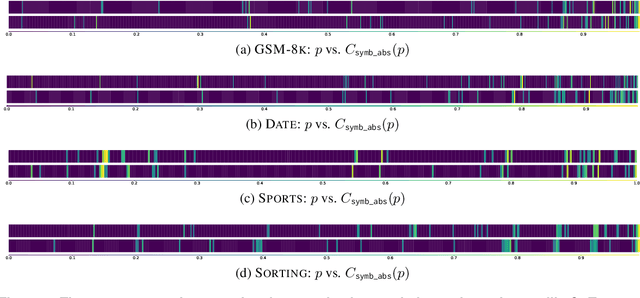


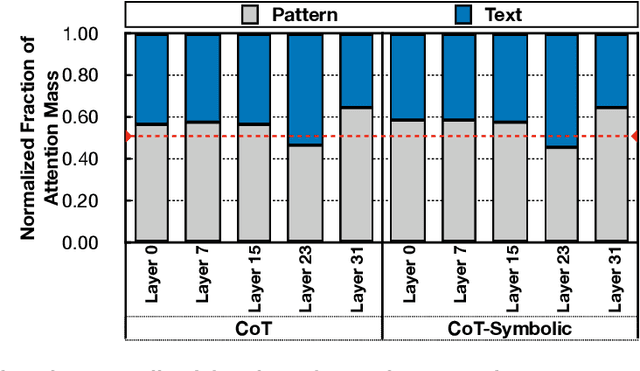
Reasoning is a key pillar of human cognition and intelligence. In the past decade, we witnessed dramatic gains in natural language processing and unprecedented scaling of large language models. Recent work has characterized the capability of few-shot prompting techniques such as chain of thought to emulate human reasoning in large language models. This hallmark feature of few-shot prompting, combined with ever scaling language models, opened a vista of possibilities to solve various tasks, such as math word problems, code completion, and commonsense reasoning. Chain of thought (CoT) prompting further pushes the performance of models in a few-shot setup, by supplying intermediate steps and urging the model to follow the same process. Despite its compelling performance, the genesis of reasoning capability in these models is less explored. This work initiates the preliminary steps towards a deeper understanding of reasoning mechanisms in large language models. Our work centers around querying the model while controlling for all but one of the components in a prompt: symbols, patterns, and text. We then analyze the performance divergence across the queries. Our results suggest the presence of factual patterns in a prompt is not necessary for the success of CoT. Nonetheless, we empirically show that relying solely on patterns is also insufficient for high quality results. We posit that text imbues patterns with commonsense knowledge and meaning. Our exhaustive empirical analysis provides qualitative examples of the symbiotic relationship between text and patterns. Such systematic understanding of CoT enables us to devise concise chain of thought, dubbed as CCoT, where text and patterns are pruned to only retain their key roles, while delivering on par or slightly higher solve task rate.
FLOWGEN: Fast and slow graph generation
Jul 21, 2022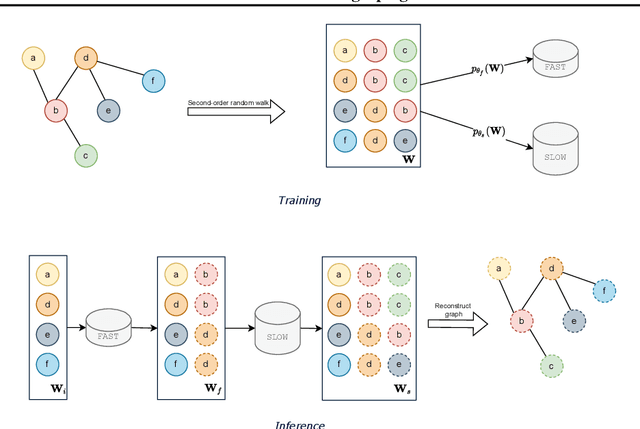

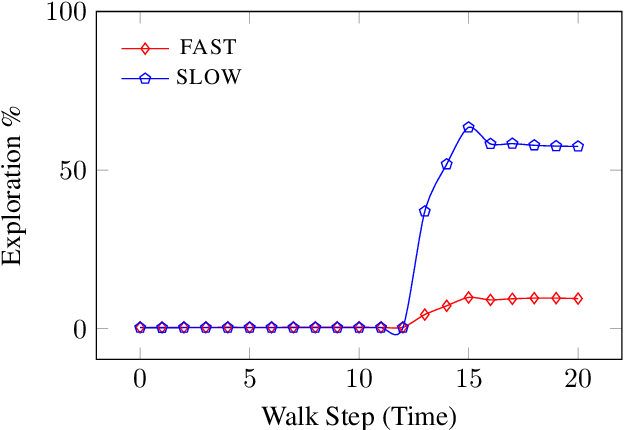

We present FLOWGEN, a graph-generation model inspired by the dual-process theory of mind that generates large graphs incrementally. Depending on the difficulty of completing the graph at the current step, graph generation is routed to either a fast~(weaker) or a slow~(stronger) model. fast and slow models have identical architectures, but vary in the number of parameters and consequently the strength. Experiments on real-world graphs show that ours can successfully generate graphs similar to those generated by a single large model in a fraction of time.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022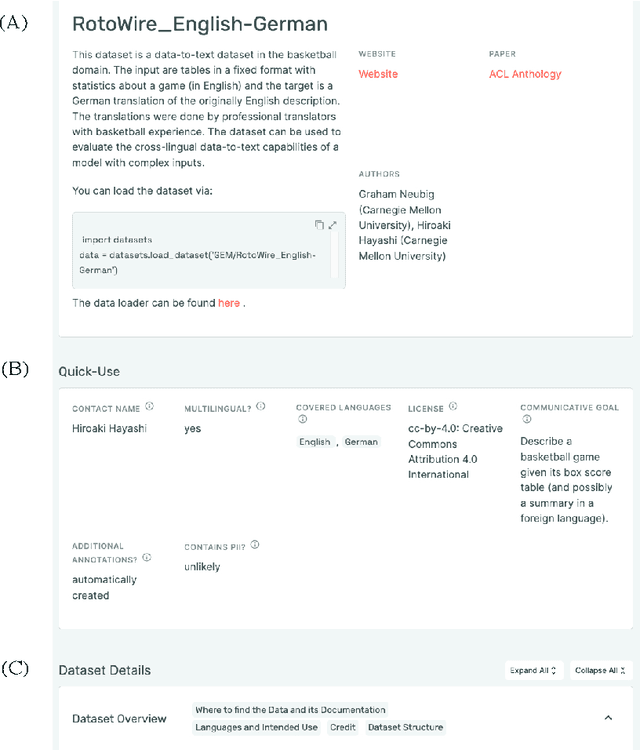

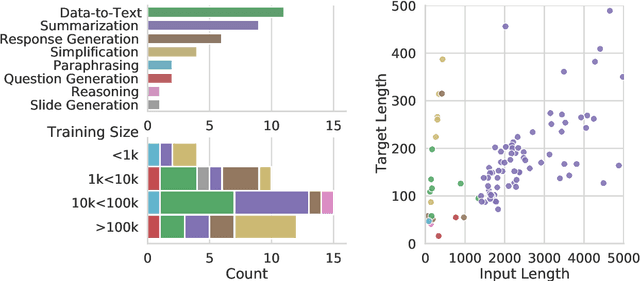

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Conditional set generation using Seq2seq models
May 25, 2022
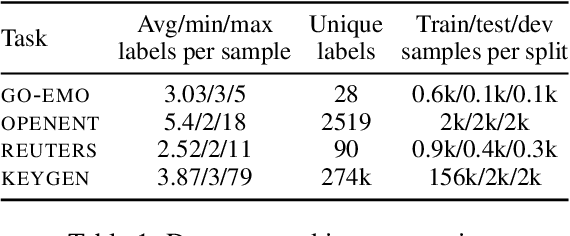
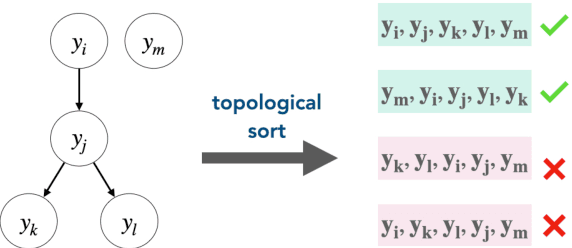
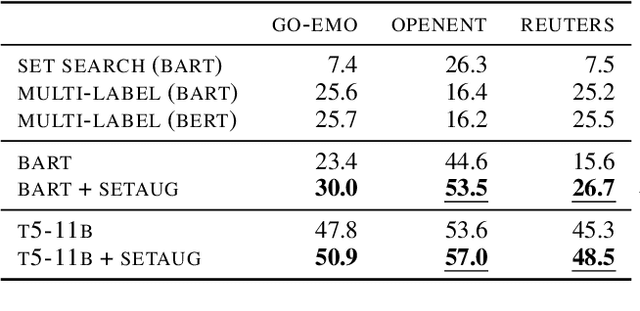
Conditional set generation learns a mapping from an input sequence of tokens to a set. Several NLP tasks, such as entity typing and dialogue emotion tagging, are instances of set generation. Sequence-to-sequence~(Seq2seq) models are a popular choice to model set generation, but they treat a set as a sequence and do not fully leverage its key properties, namely order-invariance and cardinality. We propose a novel algorithm for effectively sampling informative orders over the combinatorial space of label orders. Further, we jointly model the set cardinality and output by adding the set size as the first element and taking advantage of the autoregressive factorization used by Seq2seq models. Our method is a model-independent data augmentation approach that endows any Seq2seq model with the signals of order-invariance and cardinality. Training a Seq2seq model on this new augmented data~(without any additional annotations) gets an average relative improvement of 20% for four benchmarks datasets across models spanning from BART-base, T5-xxl, and GPT-3.
Memory-assisted prompt editing to improve GPT-3 after deployment
Jan 16, 2022
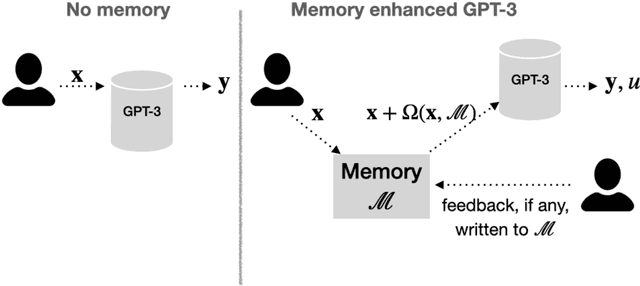

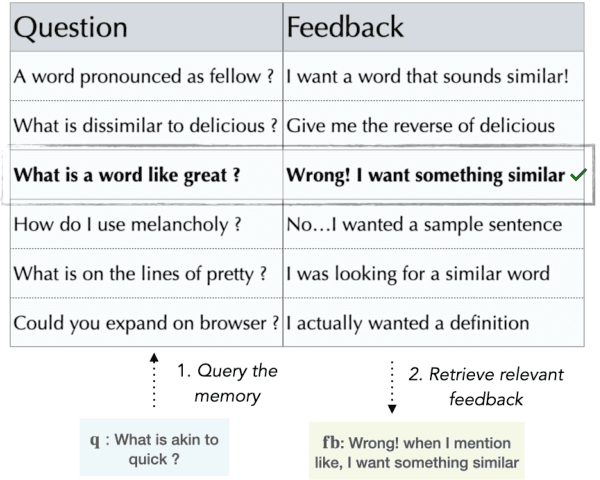
Large LMs such as GPT-3, while powerful, are not immune to mistakes, but are prohibitively costly to retrain. One failure mode is misinterpreting a user's instruction (e.g., GPT-3 interpreting "What word is similar to good?" to mean a homonym, while the user intended a synonym). Our goal is to allow users to correct such errors directly through interaction -- without retraining. Our approach pairs GPT-3 with a growing memory of cases where the model misunderstood the user's intent and was provided with feedback, clarifying the instruction. Given a new query, our memory-enhanced GPT-3 uses feedback from similar, prior queries to enrich the prompt. Through simple proof-of-concept experiments, we show how a (simulated) user can interactively teach a deployed GPT-3, doubling its accuracy on basic lexical tasks (e.g., generate a synonym) where users query in different, novel (often misunderstood) ways. In such scenarios, memory helps avoid repeating similar past mistakes. Our simple idea is a first step towards strengthening deployed models, potentially broadening their utility. All the code and data is available at https://github.com/madaan/memprompt.
Improving scripts with a memory of natural feedback
Dec 16, 2021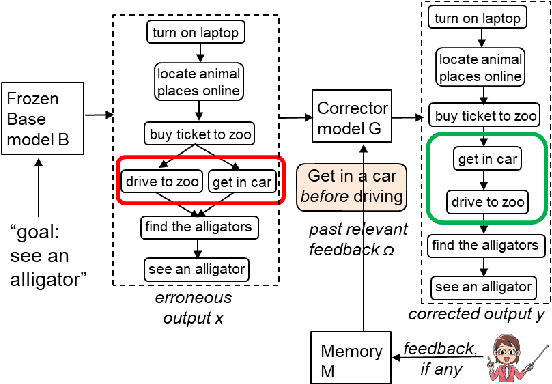
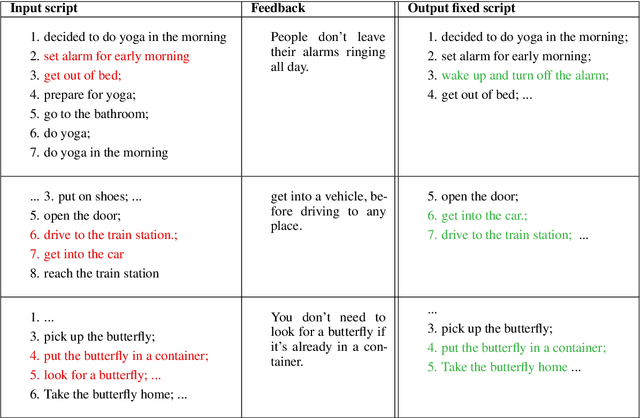
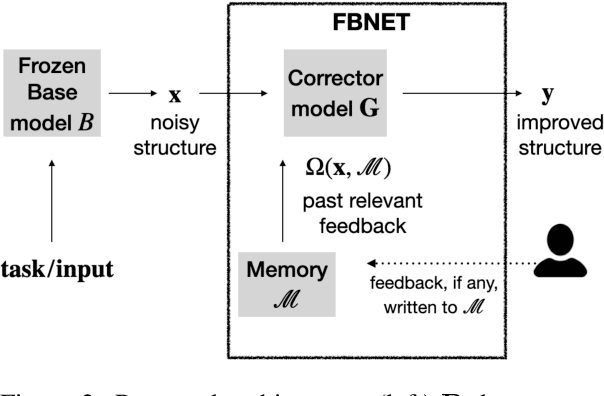
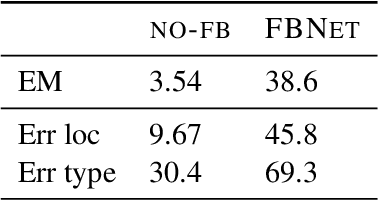
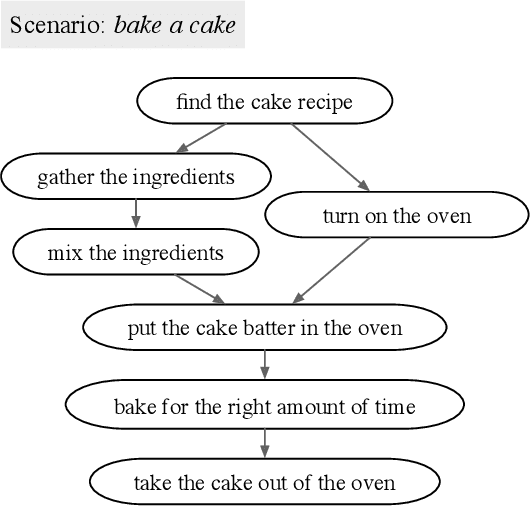
How can an end-user provide feedback if a deployed structured prediction model generates incorrect output? Our goal is to allow users to correct errors directly through interaction, without retraining, by giving feedback on the model's output. We create a dynamic memory architecture with a growing memory of feedbacks about errors in the output. Given a new, unseen input, our model can use feedback from a similar, past erroneous state. On a script generation task, we show empirically that the model learns to apply feedback effectively (up to 30 points improvement), while avoiding similar past mistakes after deployment (up to 10 points improvement on an unseen set). This is a first step towards strengthening deployed models, potentially broadening their utility.
Interscript: A dataset for interactive learning of scripts through error feedback
Dec 16, 2021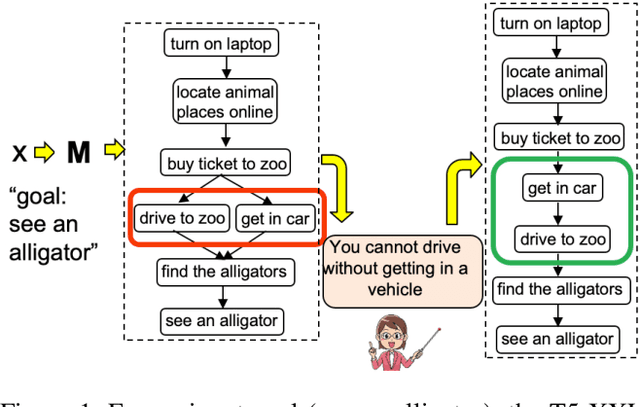
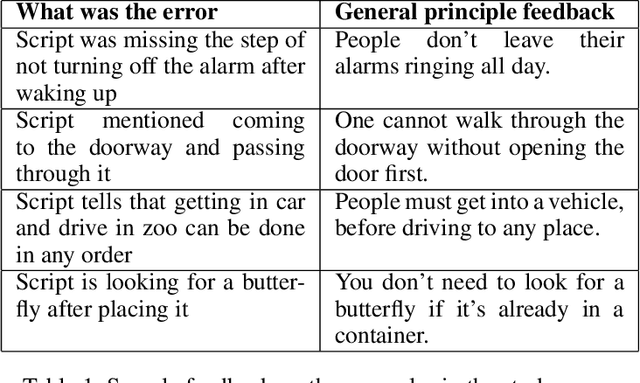

How can an end-user provide feedback if a deployed structured prediction model generates inconsistent output, ignoring the structural complexity of human language? This is an emerging topic with recent progress in synthetic or constrained settings, and the next big leap would require testing and tuning models in real-world settings. We present a new dataset, Interscript, containing user feedback on a deployed model that generates complex everyday tasks. Interscript contains 8,466 data points -- the input is a possibly erroneous script and a user feedback, and the output is a modified script. We posit two use-cases of \ours that might significantly advance the state-of-the-art in interactive learning. The dataset is available at: https://github.com/allenai/interscript.
Think about it! Improving defeasible reasoning by first modeling the question scenario
Oct 24, 2021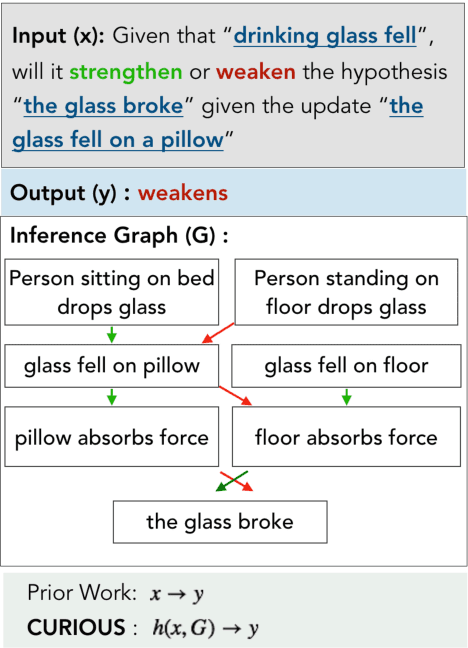
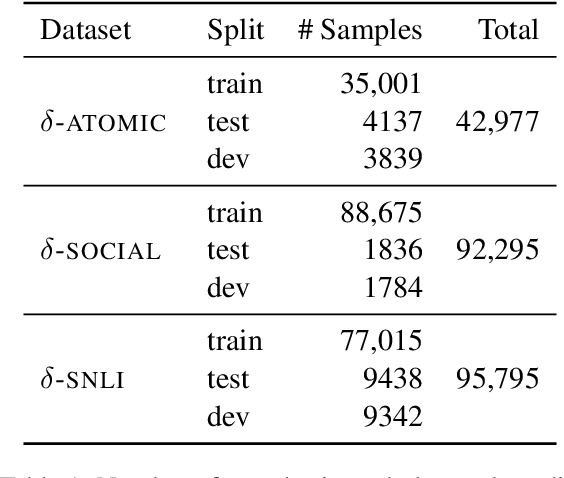
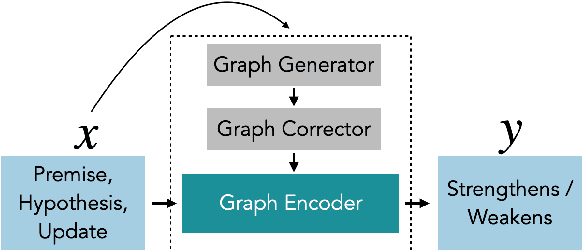
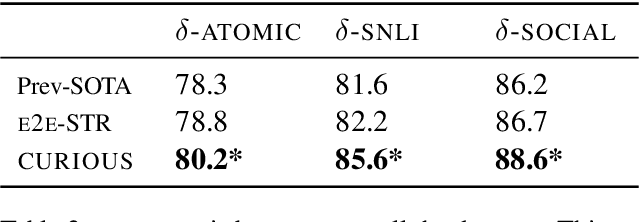
Defeasible reasoning is the mode of reasoning where conclusions can be overturned by taking into account new evidence. Existing cognitive science literature on defeasible reasoning suggests that a person forms a mental model of the problem scenario before answering questions. Our research goal asks whether neural models can similarly benefit from envisioning the question scenario before answering a defeasible query. Our approach is, given a question, to have a model first create a graph of relevant influences, and then leverage that graph as an additional input when answering the question. Our system, CURIOUS, achieves a new state-of-the-art on three different defeasible reasoning datasets. This result is significant as it illustrates that performance can be improved by guiding a system to "think about" a question and explicitly model the scenario, rather than answering reflexively. Code, data, and pre-trained models are located at https://github.com/madaan/thinkaboutit.