 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Recipe for Multilingual Grammatical Error Correction
Jun 07, 2021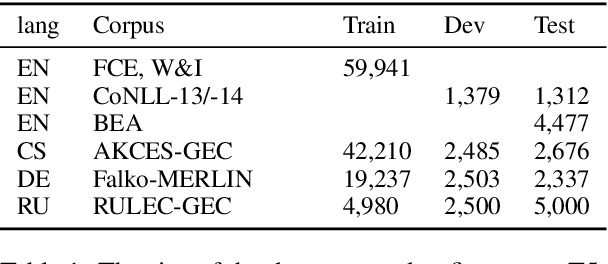
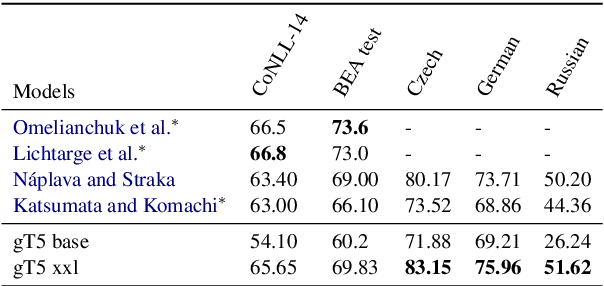
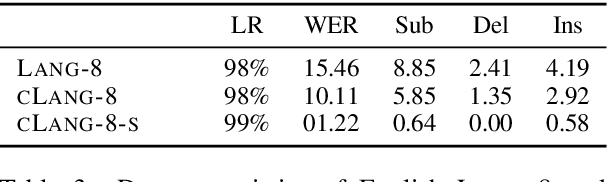
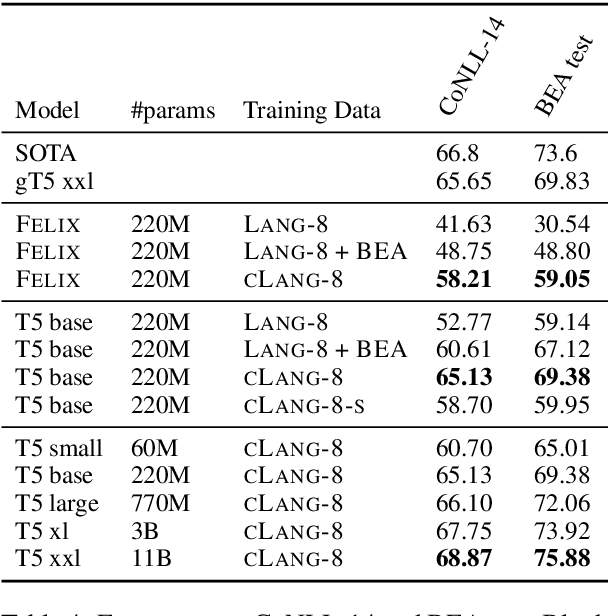
This paper presents a simple recipe to train state-of-the-art multilingual Grammatical Error Correction (GEC) models. We achieve this by first proposing a language-agnostic method to generate a large number of synthetic examples. The second ingredient is to use large-scale multilingual language models (up to 11B parameters). Once fine-tuned on language-specific supervised sets we surpass the previous state-of-the-art results on GEC benchmarks in four languages: English, Czech, German and Russian. Having established a new set of baselines for GEC, we make our results easily reproducible and accessible by releasing a cLang-8 dataset. It is produced by using our best model, which we call gT5, to clean the targets of a widely used yet noisy lang-8 dataset. cLang-8 greatly simplifies typical GEC training pipelines composed of multiple fine-tuning stages -- we demonstrate that performing a single fine-tuning step on cLang-8 with the off-the-shelf language models yields further accuracy improvements over an already top-performing gT5 model for English.
Unsupervised Text Style Transfer with Padded Masked Language Models
Oct 02, 2020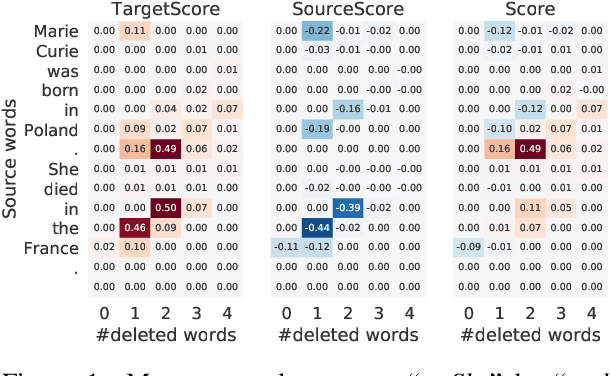
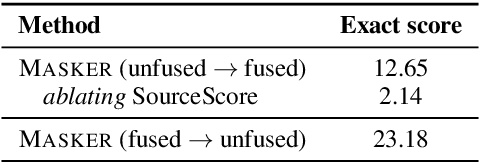
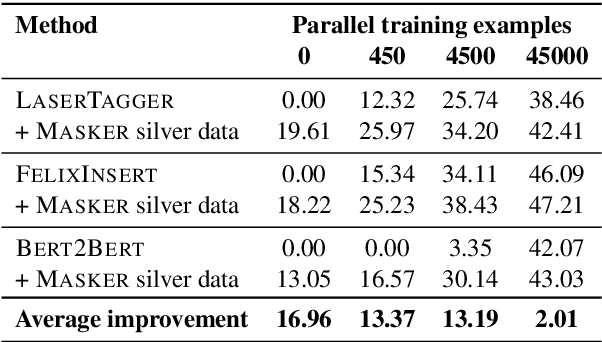
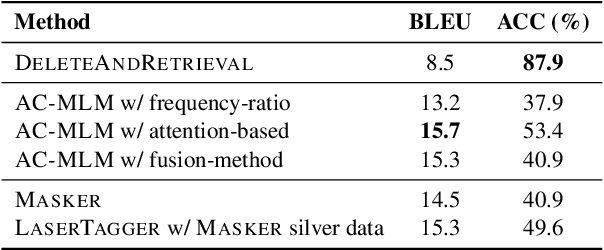
We propose Masker, an unsupervised text-editing method for style transfer. To tackle cases when no parallel source-target pairs are available, we train masked language models (MLMs) for both the source and the target domain. Then we find the text spans where the two models disagree the most in terms of likelihood. This allows us to identify the source tokens to delete to transform the source text to match the style of the target domain. The deleted tokens are replaced with the target MLM, and by using a padded MLM variant, we avoid having to predetermine the number of inserted tokens. Our experiments on sentence fusion and sentiment transfer demonstrate that Masker performs competitively in a fully unsupervised setting. Moreover, in low-resource settings, it improves supervised methods' accuracy by over 10 percentage points when pre-training them on silver training data generated by Masker.
Felix: Flexible Text Editing Through Tagging and Insertion
Mar 24, 2020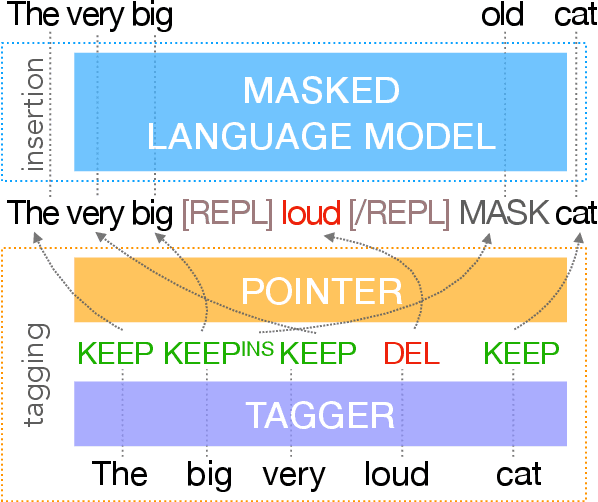
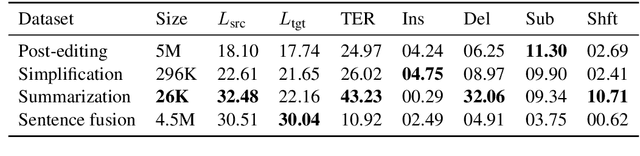

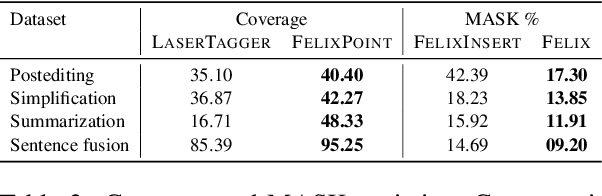
We present Felix --- a flexible text-editing approach for generation, designed to derive the maximum benefit from the ideas of decoding with bi-directional contexts and self-supervised pre-training. In contrast to conventional sequence-to-sequence (seq2seq) models, Felix is efficient in low-resource settings and fast at inference time, while being capable of modeling flexible input-output transformations. We achieve this by decomposing the text-editing task into two sub-tasks: tagging to decide on the subset of input tokens and their order in the output text and insertion to in-fill the missing tokens in the output not present in the input. The tagging model employs a novel Pointer mechanism, while the insertion model is based on a Masked Language Model. Both of these models are chosen to be non-autoregressive to guarantee faster inference. Felix performs favourably when compared to recent text-editing methods and strong seq2seq baselines when evaluated on four NLG tasks: Sentence Fusion, Machine Translation Automatic Post-Editing, Summarization, and Text Simplification.
Encode, Tag, Realize: High-Precision Text Editing
Sep 03, 2019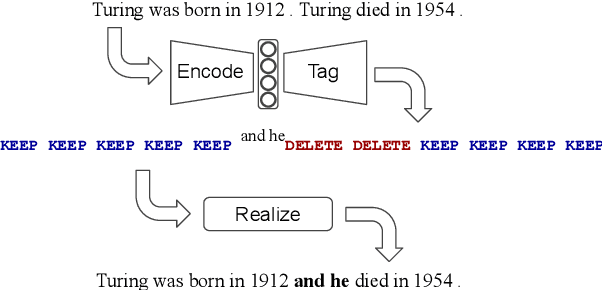
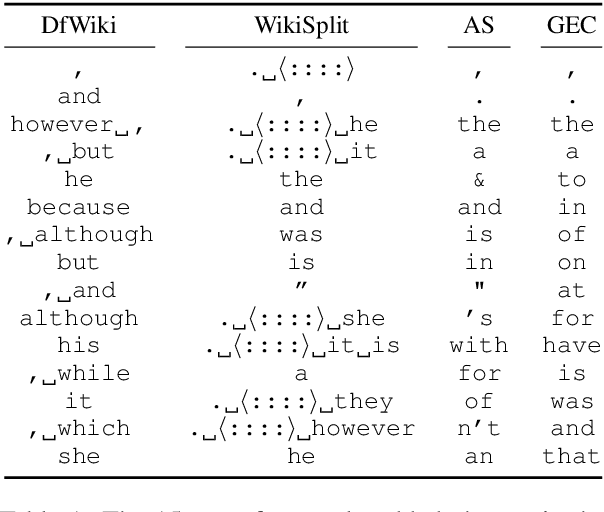

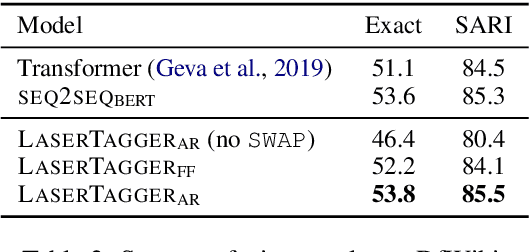
We propose LaserTagger - a sequence tagging approach that casts text generation as a text editing task. Target texts are reconstructed from the inputs using three main edit operations: keeping a token, deleting it, and adding a phrase before the token. To predict the edit operations, we propose a novel model, which combines a BERT encoder with an autoregressive Transformer decoder. This approach is evaluated on English text on four tasks: sentence fusion, sentence splitting, abstractive summarization, and grammar correction. LaserTagger achieves new state-of-the-art results on three of these tasks, performs comparably to a set of strong seq2seq baselines with a large number of training examples, and outperforms them when the number of examples is limited. Furthermore, we show that at inference time tagging can be more than two orders of magnitude faster than comparable seq2seq models, making it more attractive for running in a live environment.
Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
Jul 29, 2019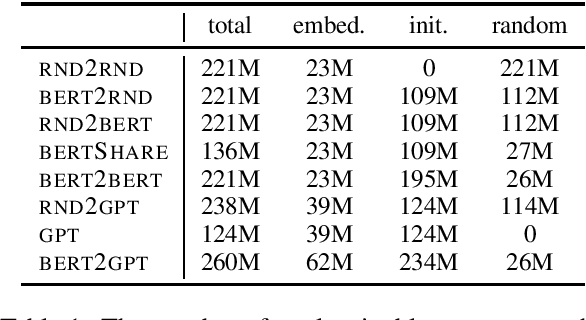
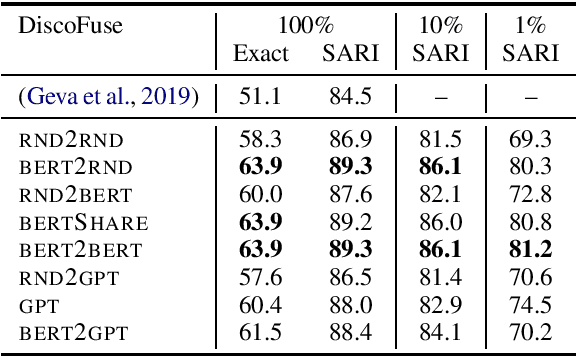
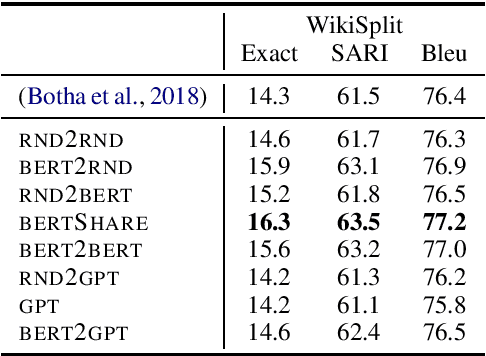
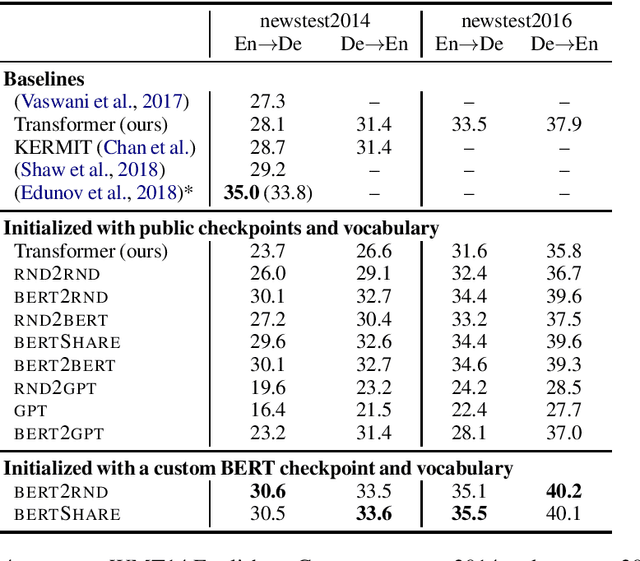
Unsupervised pre-training of large neural models has recently revolutionized Natural Language Processing. Warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language Understanding tasks. In this paper, we present an extensive empirical study on the utility of initializing large Transformer-based sequence-to-sequence models with the publicly available pre-trained BERT and GPT-2 checkpoints for sequence generation. We have run over 300 experiments spending thousands of TPU hours to find the recipe that works best and demonstrate that it results in new state-of-the-art results on Machine Translation, Summarization, Sentence Splitting and Sentence Fusion.
Breaking the Softmax Bottleneck via Learnable Monotonic Pointwise Non-linearities
Feb 21, 2019
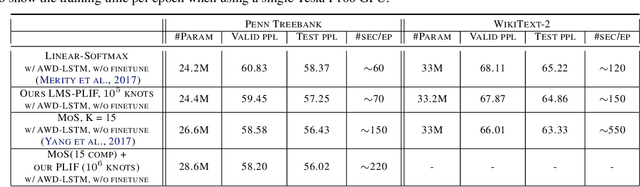
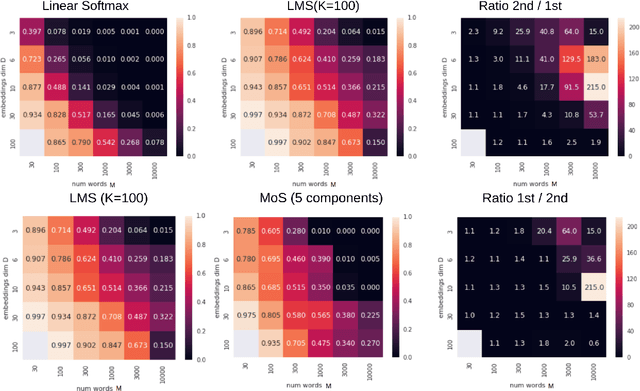
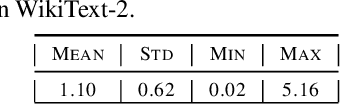
The softmax function on top of a final linear layer is the de facto method to output probability distributions in neural networks. In many applications such as language models or text generation, this model has to produce distributions over large output vocabularies. Recently, this has been shown to have limited representational capacity due to its connection with the rank bottleneck in matrix factorization. However, little is known about the limitations of linear-softmax for quantities of practical interest such as cross entropy or mode estimation, a direction that we theoretically and empirically explore here. As an efficient and effective solution to alleviate this issue, we propose to learn parametric monotonic functions on top of the logits. We theoretically investigate the rank increasing capabilities of such monotonic functions. Empirically, our method improves in two different quality metrics over the traditional softmax-linear layer in synthetic and real language model experiments, adding little time or memory overhead, while being comparable to the more computationally expensive mixture of softmaxes.
Eval all, trust a few, do wrong to none: Comparing sentence generation models
Oct 30, 2018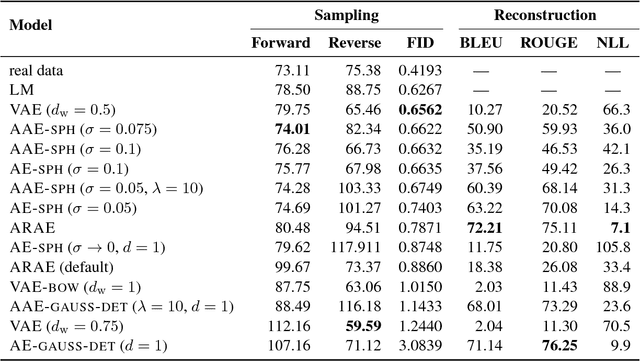
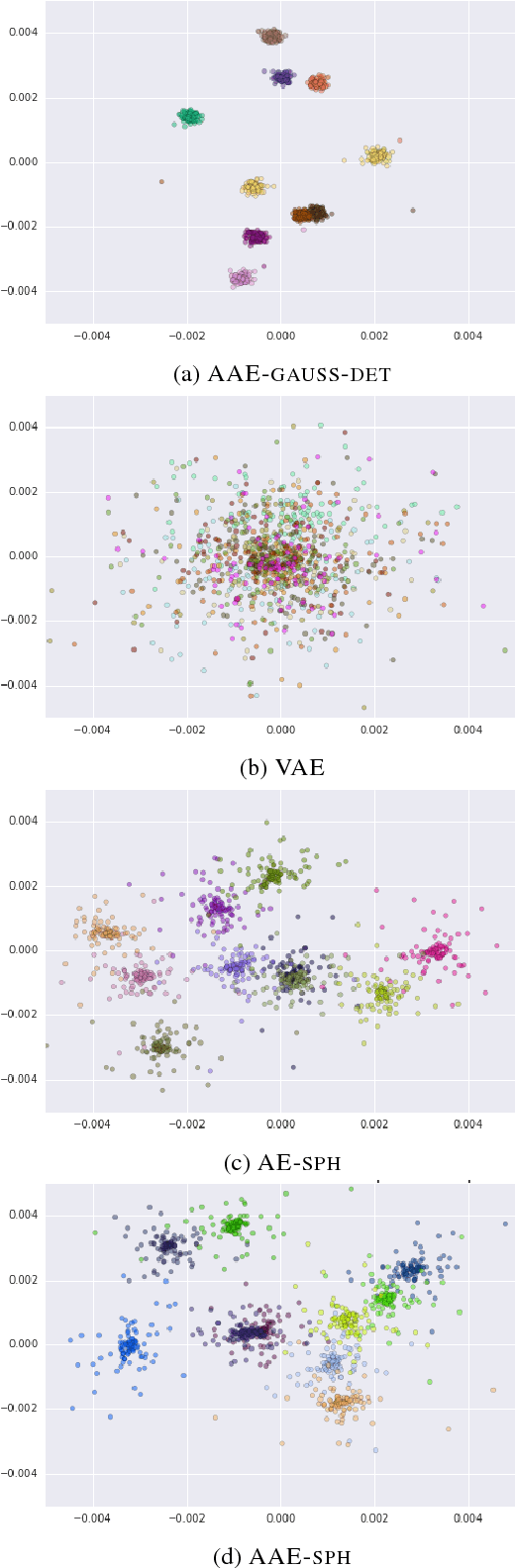


In this paper, we study recent neural generative models for text generation related to variational autoencoders. Previous works have employed various techniques to control the prior distribution of the latent codes in these models, which is important for sampling performance, but little attention has been paid to reconstruction error. In our study, we follow a rigorous evaluation protocol using a large set of previously used and novel automatic and human evaluation metrics, applied to both generated samples and reconstructions. We hope that it will become the new evaluation standard when comparing neural generative models for text.
Adversarial Neural Networks for Cross-lingual Sequence Tagging
Aug 14, 2018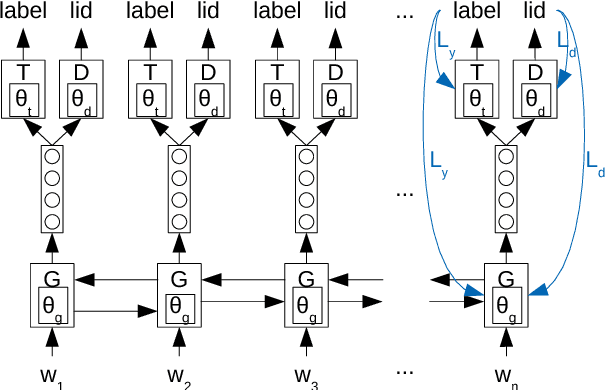
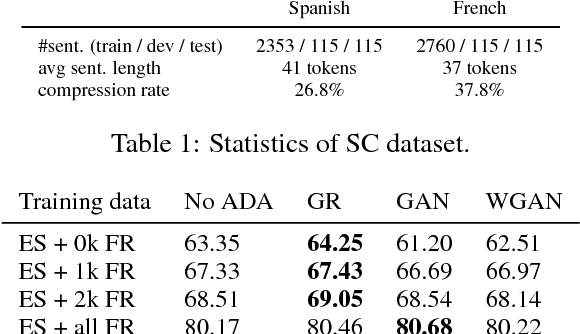

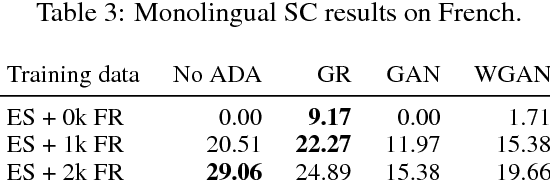
We study cross-lingual sequence tagging with little or no labeled data in the target language. Adversarial training has previously been shown to be effective for training cross-lingual sentence classifiers. However, it is not clear if language-agnostic representations enforced by an adversarial language discriminator will also enable effective transfer for token-level prediction tasks. Therefore, we experiment with different types of adversarial training on two tasks: dependency parsing and sentence compression. We show that adversarial training consistently leads to improved cross-lingual performance on each task compared to a conventionally trained baseline.
On Accurate Evaluation of GANs for Language Generation
Jun 14, 2018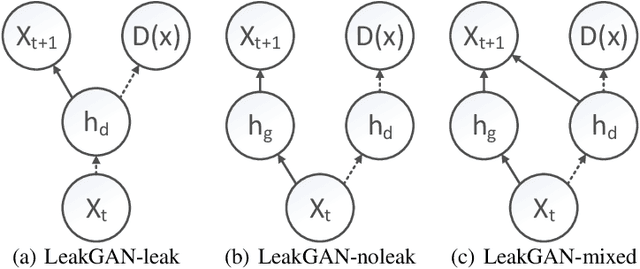
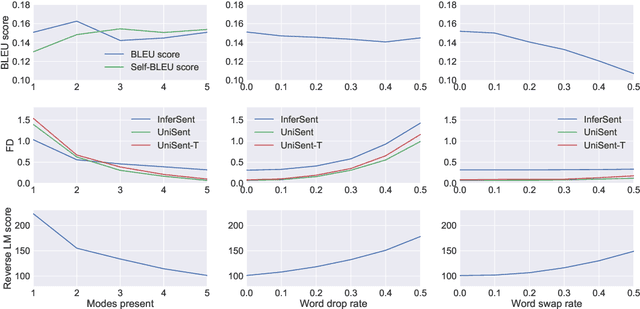
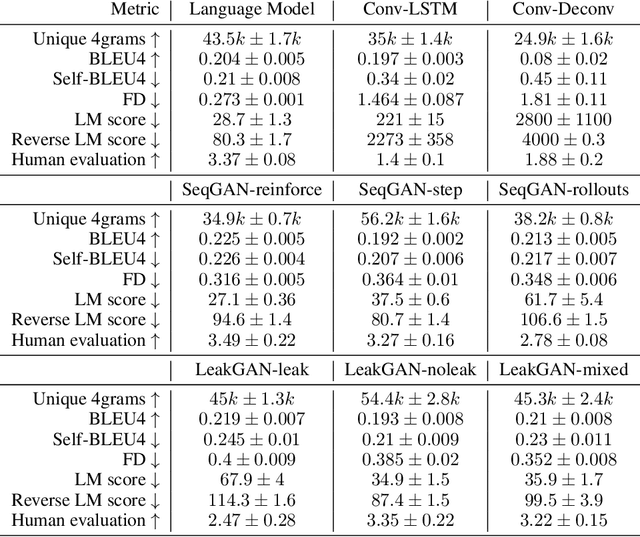
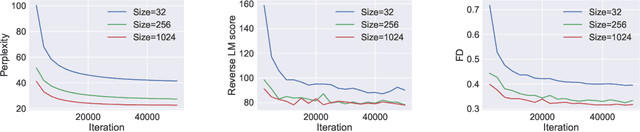
Generative Adversarial Networks (GANs) are a promising approach to language generation. The latest works introducing novel GAN models for language generation use n-gram based metrics for evaluation and only report single scores of the best run. In this paper, we argue that this often misrepresents the true picture and does not tell the full story, as GAN models can be extremely sensitive to the random initialization and small deviations from the best hyperparameter choice. In particular, we demonstrate that the previously used BLEU score is not sensitive to semantic deterioration of generated texts and propose alternative metrics that better capture the quality and diversity of the generated samples. We also conduct a set of experiments comparing a number of GAN models for text with a conventional Language Model (LM) and find that neither of the considered models performs convincingly better than the LM.
Prosody Modifications for Question-Answering in Voice-Only Settings
Jun 11, 2018

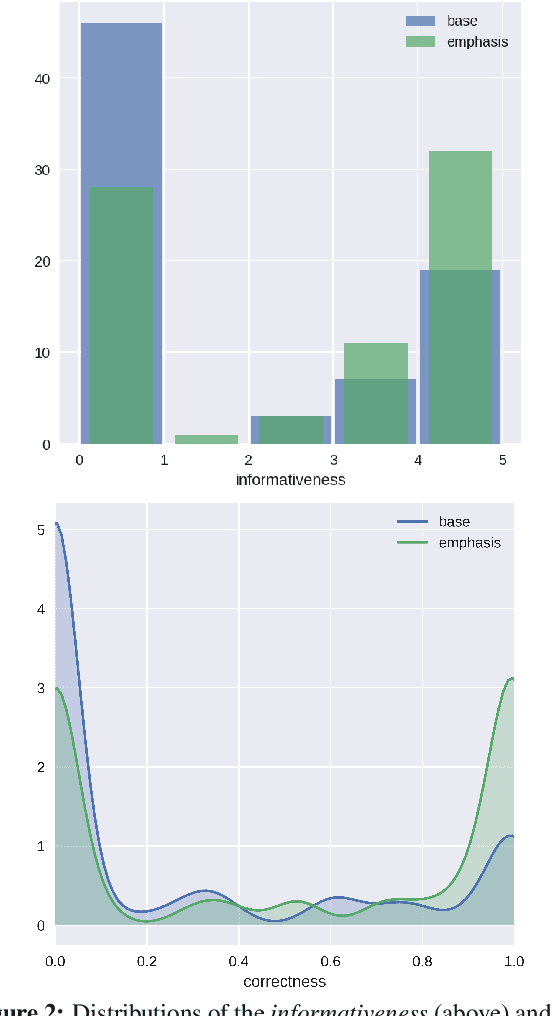

Many popular form factors of digital assistant---such as Amazon Echo, Apple Homepod or Google Home---enable the user to hold a conversation with the assistant based only on the speech modality. The lack of a screen from which the user can read text or watch supporting images or video presents unique challenges. In order to satisfy the information need of a user, we believe that the presentation of the answer needs to be optimized for such voice-only interactions. In this paper we propose a task of evaluating usefulness of prosody modifications for the purpose of voice-only question answering. We describe a crowd-sourcing setup where we evaluate the quality of these modifications along multiple dimensions corresponding to the informativeness, naturalness, and ability of the user to identify the key part of the answer. In addition, we propose a set of simple prosodic modifications that highlight important parts of the answer using various acoustic cues.