 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Cut by Watching Movies
Aug 09, 2021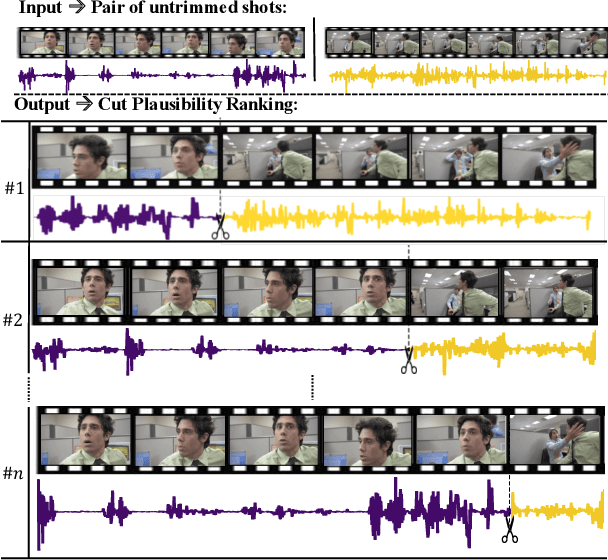
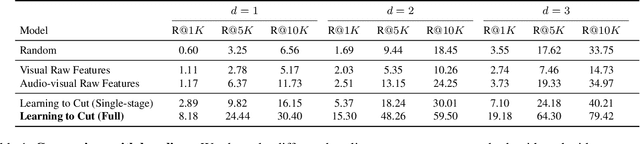


Video content creation keeps growing at an incredible pace; yet, creating engaging stories remains challenging and requires non-trivial video editing expertise. Many video editing components are astonishingly hard to automate primarily due to the lack of raw video materials. This paper focuses on a new task for computational video editing, namely the task of raking cut plausibility. Our key idea is to leverage content that has already been edited to learn fine-grained audiovisual patterns that trigger cuts. To do this, we first collected a data source of more than 10K videos, from which we extract more than 255K cuts. We devise a model that learns to discriminate between real and artificial cuts via contrastive learning. We set up a new task and a set of baselines to benchmark video cut generation. We observe that our proposed model outperforms the baselines by large margins. To demonstrate our model in real-world applications, we conduct human studies in a collection of unedited videos. The results show that our model does a better job at cutting than random and alternative baselines.
Enhancing Adversarial Robustness via Test-time Transformation Ensembling
Jul 29, 2021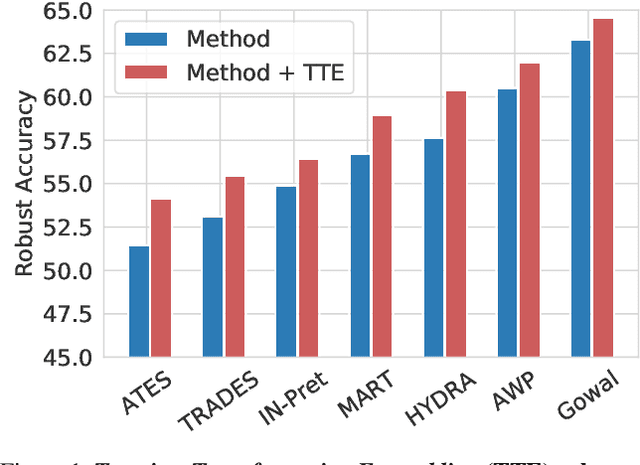
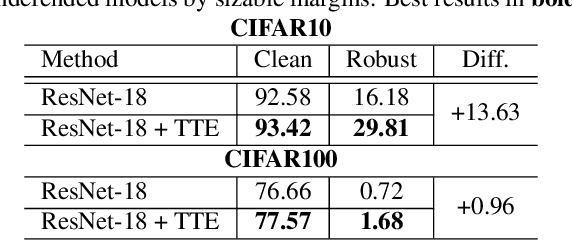
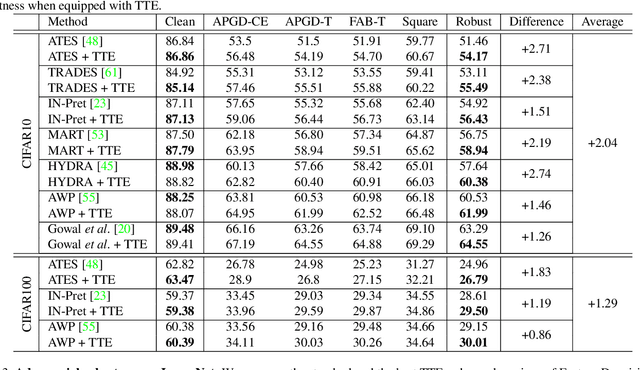
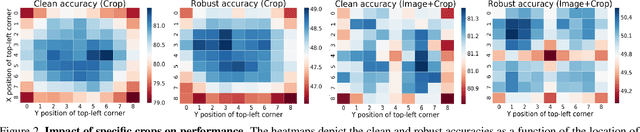
Deep learning models are prone to being fooled by imperceptible perturbations known as adversarial attacks. In this work, we study how equipping models with Test-time Transformation Ensembling (TTE) can work as a reliable defense against such attacks. While transforming the input data, both at train and test times, is known to enhance model performance, its effects on adversarial robustness have not been studied. Here, we present a comprehensive empirical study of the impact of TTE, in the form of widely-used image transforms, on adversarial robustness. We show that TTE consistently improves model robustness against a variety of powerful attacks without any need for re-training, and that this improvement comes at virtually no trade-off with accuracy on clean samples. Finally, we show that the benefits of TTE transfer even to the certified robustness domain, in which TTE provides sizable and consistent improvements.
Combating Adversaries with Anti-Adversaries
Mar 26, 2021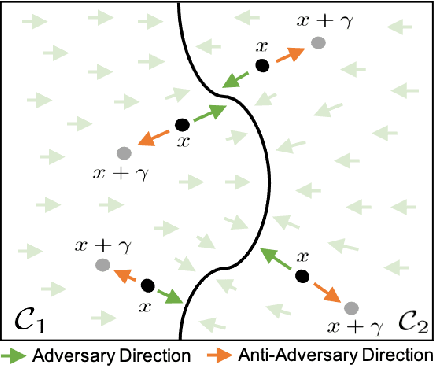
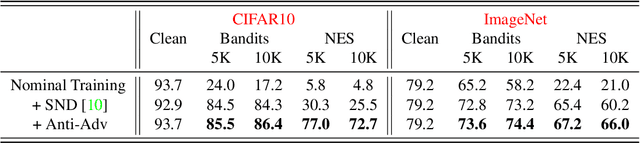
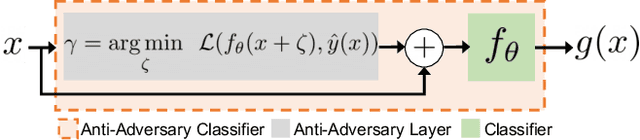
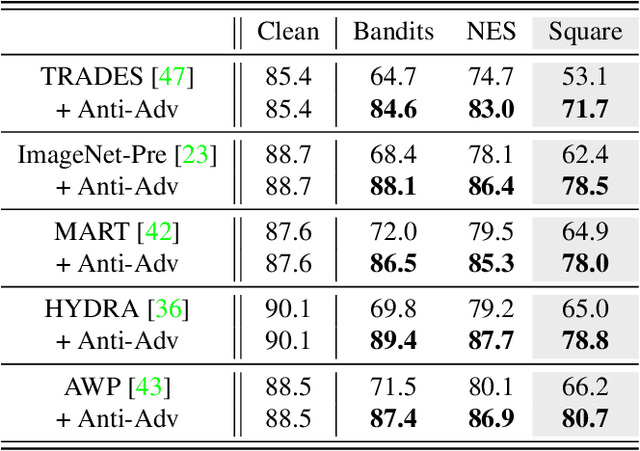
Deep neural networks are vulnerable to small input perturbations known as adversarial attacks. Inspired by the fact that these adversaries are constructed by iteratively minimizing the confidence of a network for the true class label, we propose the anti-adversary layer, aimed at countering this effect. In particular, our layer generates an input perturbation in the opposite direction of the adversarial one, and feeds the classifier a perturbed version of the input. Our approach is training-free and theoretically supported. We verify the effectiveness of our approach by combining our layer with both nominally and robustly trained models, and conduct large scale experiments from black-box to adaptive attacks on CIFAR10, CIFAR100 and ImageNet. Our anti-adversary layer significantly enhances model robustness while coming at no cost on clean accuracy.
MAAS: Multi-modal Assignation for Active Speaker Detection
Jan 11, 2021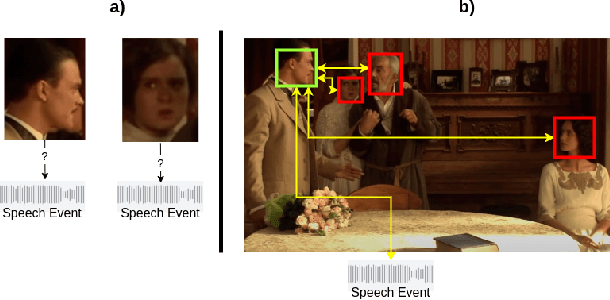

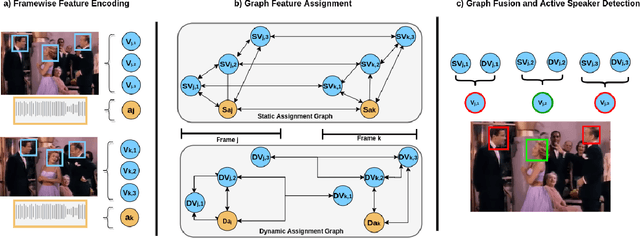

Active speaker detection requires a solid integration of multi-modal cues. While individual modalities can approximate a solution, accurate predictions can only be achieved by explicitly fusing the audio and visual features and modeling their temporal progression. Despite its inherent muti-modal nature, current methods still focus on modeling and fusing short-term audiovisual features for individual speakers, often at frame level. In this paper we present a novel approach to active speaker detection that directly addresses the multi-modal nature of the problem, and provides a straightforward strategy where independent visual features from potential speakers in the scene are assigned to a previously detected speech event. Our experiments show that, an small graph data structure built from a single frame, allows to approximate an instantaneous audio-visual assignment problem. Moreover, the temporal extension of this initial graph achieves a new state-of-the-art on the AVA-ActiveSpeaker dataset with a mAP of 88.8\%.
SALA: Soft Assignment Local Aggregation for 3D Semantic Segmentation
Dec 29, 2020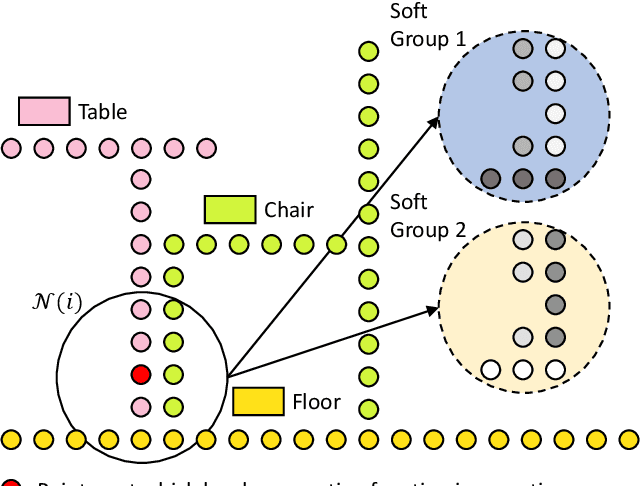
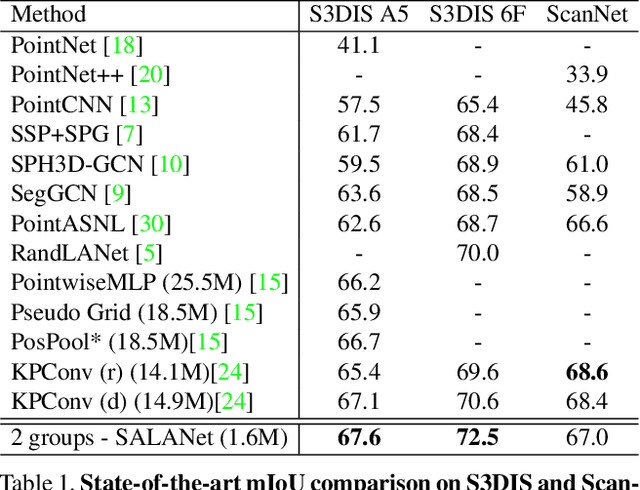
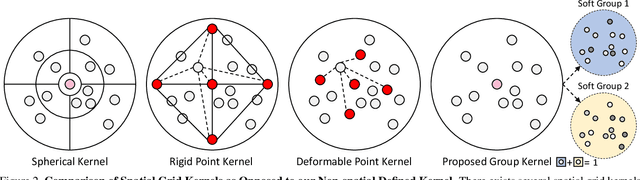
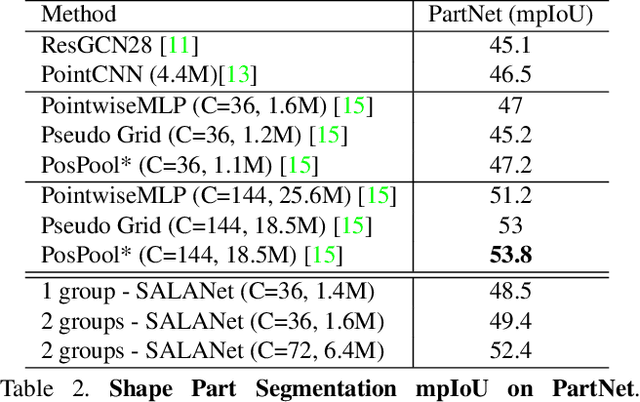
We introduce the idea of using learnable neighbor-to-grid soft assignment in grid-based aggregation functions for the task of 3D semantic segmentation. Previous methods in literature operate on a predefined geometric grid such as local volume partitions or irregular kernel points. These methods use geometric functions to assign local neighbors to their corresponding grid. Such geometric heuristics are potentially sub-optimal for the end task of semantic segmentation. Furthermore, they are applied uniformly throughout the depth of the network. A more general alternative would allow the network to learn its own neighbor-to-grid assignment function that best suits the end task. Since it is learnable, this mapping has the flexibility to be different per layer. This paper leverages learned neighbor-to-grid soft assignment to define an aggregation function that balances efficiency and performance. We demonstrate the efficacy of our method by reaching state-of-the-art (SOTA) performance on S3DIS with almost 10$\times$ less parameters than the current reigning method. We also demonstrate competitive performance on ScanNet and PartNet as compared with much larger SOTA models.
Video Self-Stitching Graph Network for Temporal Action Localization
Dec 13, 2020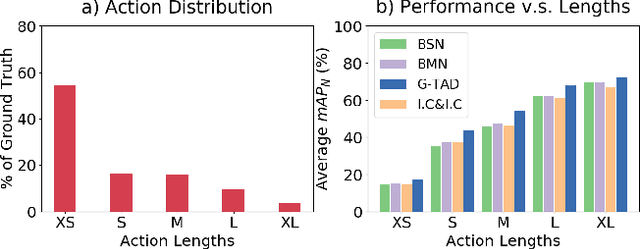
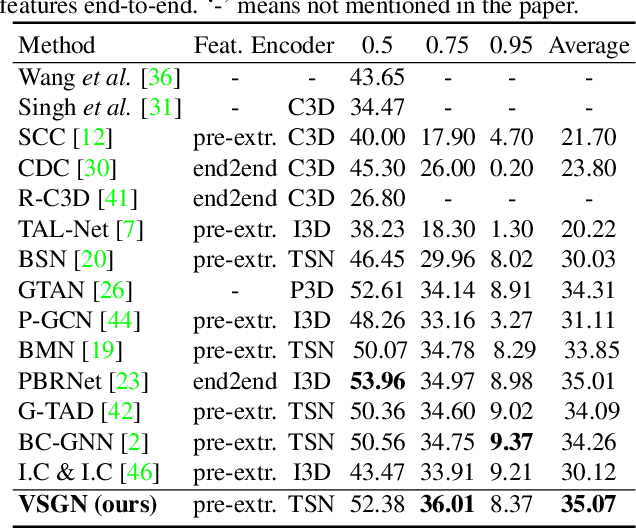
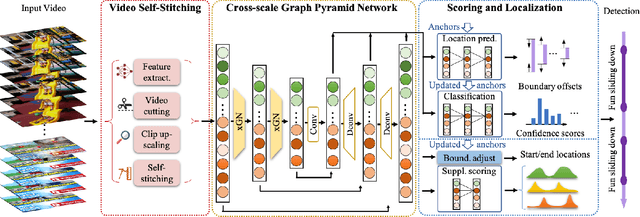
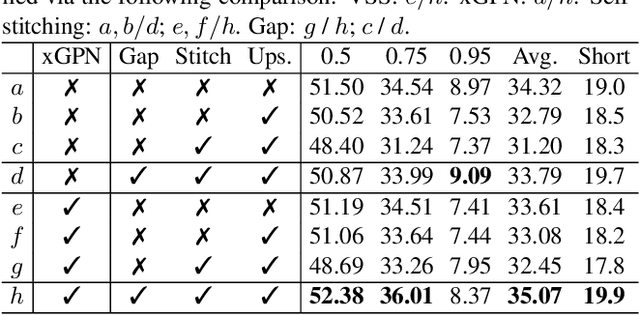
Temporal action localization (TAL) in videos is a challenging task, especially due to the large scale variation of actions. In the data, short actions usually occupy the major proportion, but have the lowest performance with all current methods. In this paper, we confront the challenge of short actions and propose a multi-level cross-scale solution dubbed as video self-stitching graph network (VSGN). We have two key components in VSGN: video self-stitching (VSS) and cross-scale graph pyramid network (xGPN). In VSS, we focus on a short period of a video and magnify it along the temporal dimension to obtain a larger scale. By our self-stitching approach, we are able to utilize the original clip and its magnified counterpart in one input sequence to take advantage of the complementary properties of both scales. The xGPN component further exploits the cross-scale correlations by a pyramid of cross-scale graph networks, each containing a hybrid temporal-graph module to aggregate features from across scales as well as within the same scale. Our VSGN not only enhances the feature representations, but also generates more positive anchors for short actions and more short training samples. Experiments demonstrate that VSGN obviously improves the localization performance of short actions as well as achieving the state-of-the-art overall performance on ActivityNet-v1.3, reaching an average mAP of 35.07 %.
MVTN: Multi-View Transformation Network for 3D Shape Recognition
Nov 26, 2020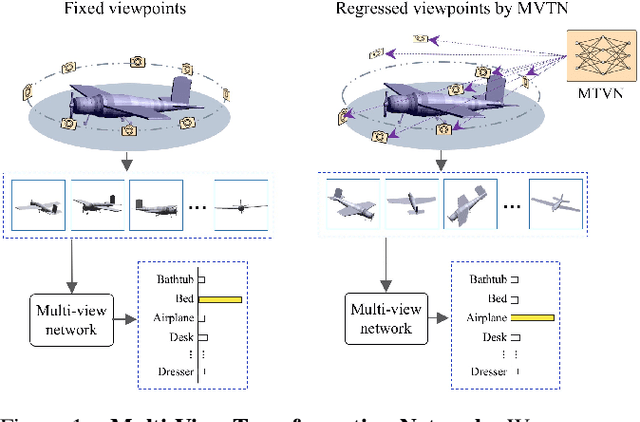
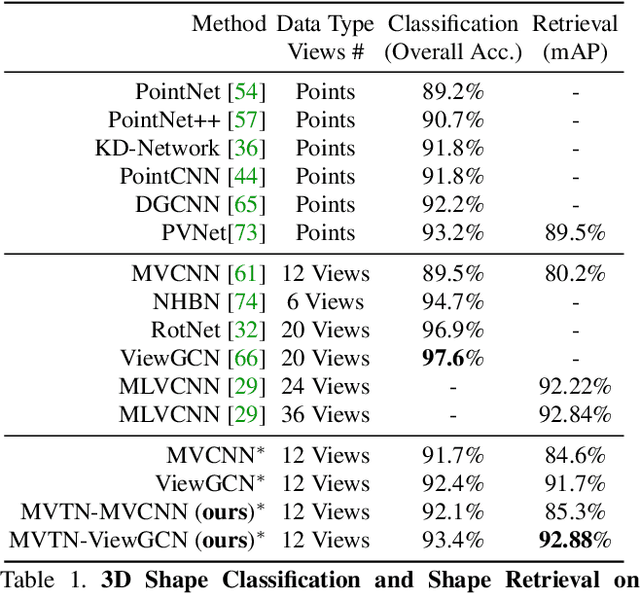
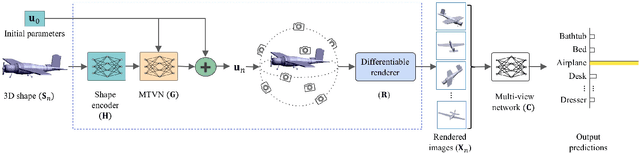
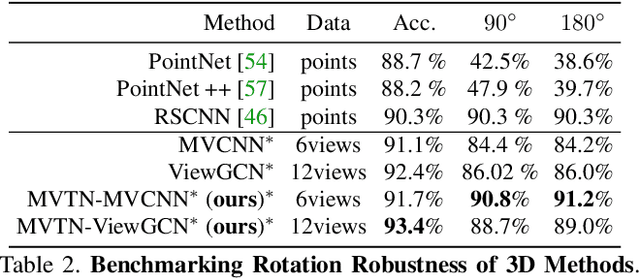
Multi-view projection methods have shown the capability to reach state-of-the-art performance on 3D shape recognition. Most advances in multi-view representation focus on pooling techniques that learn to aggregate information from the different views, which tend to be heuristically set and fixed for all shapes. To circumvent the lack of dynamism of current multi-view methods, we propose to learn those viewpoints. In particular, we introduce a Multi-View Transformation Network (MVTN) that regresses optimal viewpoints for 3D shape recognition. By leveraging advances in differentiable rendering, our MVTN is trained end-to-end with any multi-view network and optimized for 3D shape classification. We show that MVTN can be seamlessly integrated into various multi-view approaches to exhibit clear performance gains in the tasks of 3D shape classification and shape retrieval without any extra training supervision. Furthermore, our MVTN improves multi-view networks to achieve state-of-the-art performance in rotation robustness and in object shape retrieval on ModelNet40.
LC-NAS: Latency Constrained Neural Architecture Search for Point Cloud Networks
Aug 24, 2020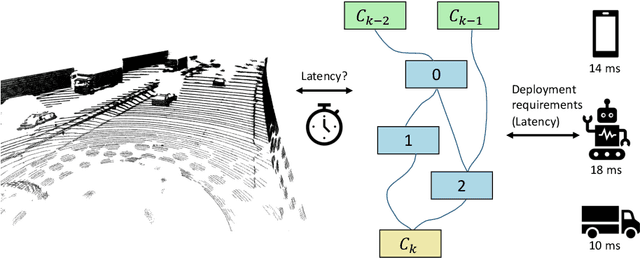
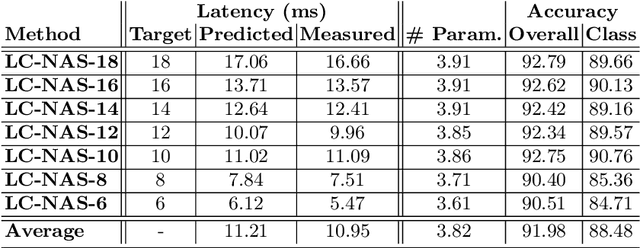
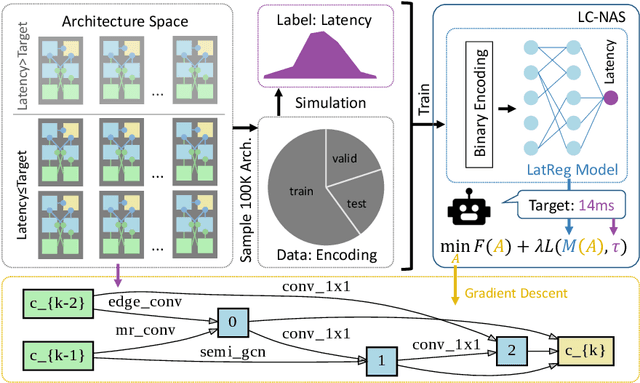
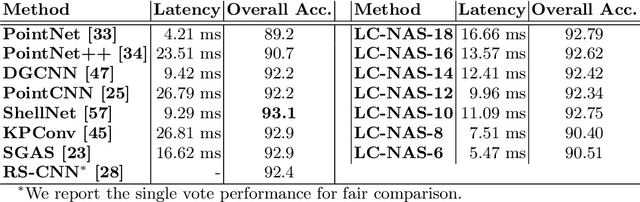
Point cloud architecture design has become a crucial problem for 3D deep learning. Several efforts exist to manually design architectures with high accuracy in point cloud tasks such as classification, segmentation, and detection. Recent progress in automatic Neural Architecture Search (NAS) minimizes the human effort in network design and optimizes high performing architectures. However, these efforts fail to consider important factors such as latency during inference. Latency is of high importance in time critical applications like self-driving cars, robot navigation, and mobile applications, that are generally bound by the available hardware. In this paper, we introduce a new NAS framework, dubbed LC-NAS, where we search for point cloud architectures that are constrained to a target latency. We implement a novel latency constraint formulation to trade-off between accuracy and latency in our architecture search. Contrary to previous works, our latency loss guarantees that the final network achieves latency under a specified target value. This is crucial when the end task is to be deployed in a limited hardware setting. Extensive experiments show that LC-NAS is able to find state-of-the-art architectures for point cloud classification in ModelNet40 with minimal computational cost. We also show how our searched architectures achieve any desired latency with a reasonably low drop in accuracy. Finally, we show how our searched architectures easily transfer to a different task, part segmentation on PartNet, where we achieve state-of-the-art results while lowering latency by a factor of 10.
ClusTR: Clustering Training for Robustness
Jun 24, 2020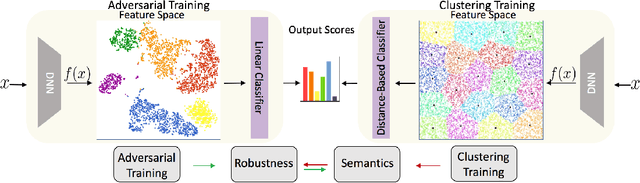
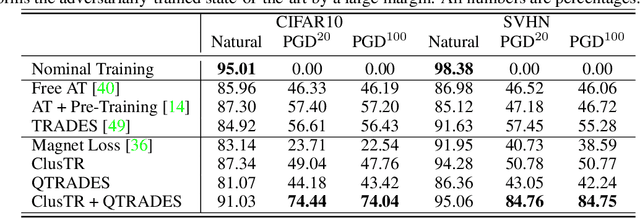
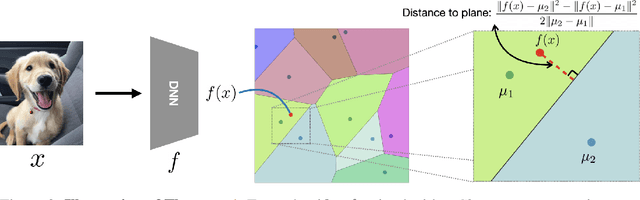
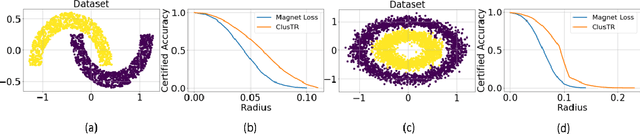
This paper studies how encouraging semantically-aligned features during deep neural network training can increase network robustness. Recent works observed that Adversarial Training leads to robust models, whose learnt features appear to correlate with human perception. Inspired by this connection from robustness to semantics, we study the complementary connection: from semantics to robustness. To do so, we provide a tight robustness certificate for distance-based classification models (clustering-based classifiers), which we leverage to propose ClusTR (Clustering Training for Robustness), a clustering-based and adversary-free training framework to learn robust models. Interestingly, ClusTR outperforms adversarially-trained networks by up to 4\% under strong PGD attacks. Moreover, it can be equipped with simple and fast adversarial training to improve the current state-of-the-art in robustness by 16\%-29\% on CIFAR10, SVHN, and CIFAR100.
DeeperGCN: All You Need to Train Deeper GCNs
Jun 13, 2020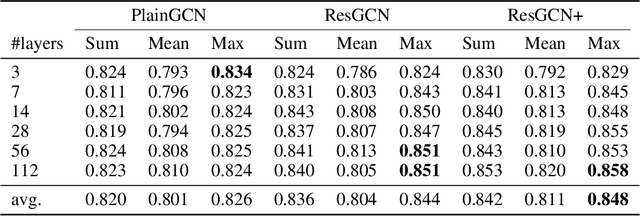
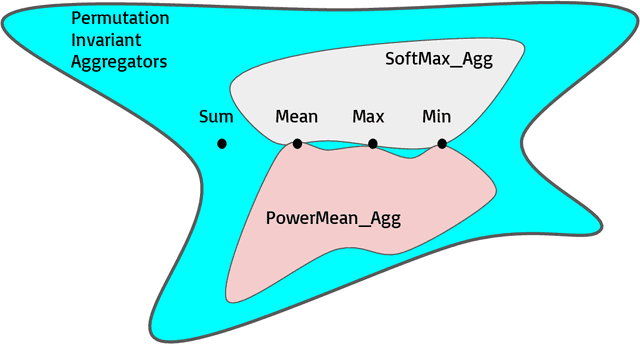
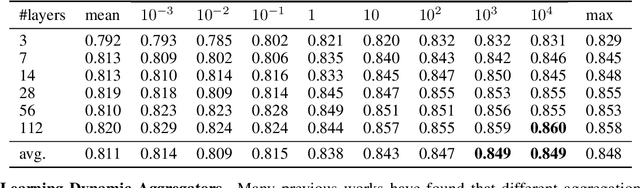
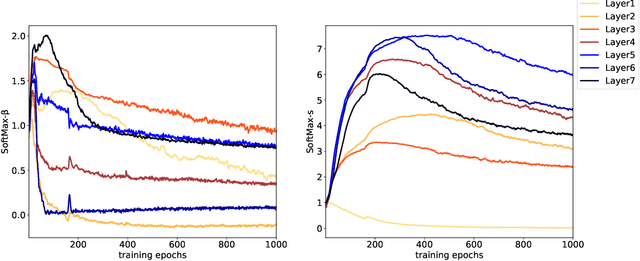
Graph Convolutional Networks (GCNs) have been drawing significant attention with the power of representation learning on graphs. Unlike Convolutional Neural Networks (CNNs), which are able to take advantage of stacking very deep layers, GCNs suffer from vanishing gradient, over-smoothing and over-fitting issues when going deeper. These challenges limit the representation power of GCNs on large-scale graphs. This paper proposes DeeperGCN that is capable of successfully and reliably training very deep GCNs. We define differentiable generalized aggregation functions to unify different message aggregation operations (e.g. mean, max). We also propose a novel normalization layer namely MsgNorm and a pre-activation version of residual connections for GCNs. Extensive experiments on Open Graph Benchmark (OGB) show DeeperGCN significantly boosts performance over the state-of-the-art on the large scale graph learning tasks of node property prediction and graph property prediction. Please visit https://www.deepgcns.org for more information.