 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic Inference Using Sorted Fine-Tuning (SoFT)
Sep 16, 2023



The rapid advancement of large language models (LLMs) has revolutionized natural language processing (NLP). While these models excel at understanding and generating human-like text, their widespread deployment can be prohibitively expensive. SortedNet is a recent training technique for enabling dynamic inference for deep neural networks. It leverages network modularity to create sub-models with varying computational loads, sorting them based on computation/accuracy characteristics in a nested manner. We extend SortedNet to generative NLP tasks, making large language models dynamic without any pretraining and by only replacing standard Supervised Fine-Tuning (SFT) with Sorted Fine-Tuning (SoFT) at the same costs. Our approach boosts model efficiency, eliminating the need for multiple models for various scenarios during inference. We show that using this approach, we are able to unlock the potential of intermediate layers of transformers in generating the target output. Our sub-models remain integral components of the original model, minimizing storage requirements and transition costs between different computational/latency budgets. By applying this approach on LLaMa 2 13B for tuning on the Stanford Alpaca dataset and comparing it to normal tuning and early exit via PandaLM benchmark, we show that Sorted Fine-Tuning can deliver models twice as fast as the original model while maintaining or exceeding performance.
SortedNet, a Place for Every Network and Every Network in its Place: Towards a Generalized Solution for Training Many-in-One Neural Networks
Sep 01, 2023As the size of deep learning models continues to grow, finding optimal models under memory and computation constraints becomes increasingly more important. Although usually the architecture and constituent building blocks of neural networks allow them to be used in a modular way, their training process is not aware of this modularity. Consequently, conventional neural network training lacks the flexibility to adapt the computational load of the model during inference. This paper proposes SortedNet, a generalized and scalable solution to harness the inherent modularity of deep neural networks across various dimensions for efficient dynamic inference. Our training considers a nested architecture for the sub-models with shared parameters and trains them together with the main model in a sorted and probabilistic manner. This sorted training of sub-networks enables us to scale the number of sub-networks to hundreds using a single round of training. We utilize a novel updating scheme during training that combines random sampling of sub-networks with gradient accumulation to improve training efficiency. Furthermore, the sorted nature of our training leads to a search-free sub-network selection at inference time; and the nested architecture of the resulting sub-networks leads to minimal storage requirement and efficient switching between sub-networks at inference. Our general dynamic training approach is demonstrated across various architectures and tasks, including large language models and pre-trained vision models. Experimental results show the efficacy of the proposed approach in achieving efficient sub-networks while outperforming state-of-the-art dynamic training approaches. Our findings demonstrate the feasibility of training up to 160 different sub-models simultaneously, showcasing the extensive scalability of our proposed method while maintaining 96% of the model performance.
Recurrent Neural Networks and Long Short-Term Memory Networks: Tutorial and Survey
Apr 22, 2023



This is a tutorial paper on Recurrent Neural Network (RNN), Long Short-Term Memory Network (LSTM), and their variants. We start with a dynamical system and backpropagation through time for RNN. Then, we discuss the problems of gradient vanishing and explosion in long-term dependencies. We explain close-to-identity weight matrix, long delays, leaky units, and echo state networks for solving this problem. Then, we introduce LSTM gates and cells, history and variants of LSTM, and Gated Recurrent Units (GRU). Finally, we introduce bidirectional RNN, bidirectional LSTM, and the Embeddings from Language Model (ELMo) network, for processing a sequence in both directions.
Improved knowledge distillation by utilizing backward pass knowledge in neural networks
Jan 27, 2023Knowledge distillation (KD) is one of the prominent techniques for model compression. In this method, the knowledge of a large network (teacher) is distilled into a model (student) with usually significantly fewer parameters. KD tries to better-match the output of the student model to that of the teacher model based on the knowledge extracts from the forward pass of the teacher network. Although conventional KD is effective for matching the two networks over the given data points, there is no guarantee that these models would match in other areas for which we do not have enough training samples. In this work, we address that problem by generating new auxiliary training samples based on extracting knowledge from the backward pass of the teacher in the areas where the student diverges greatly from the teacher. We compute the difference between the teacher and the student and generate new data samples that maximize the divergence. This is done by perturbing data samples in the direction of the gradient of the difference between the student and the teacher. Augmenting the training set by adding this auxiliary improves the performance of KD significantly and leads to a closer match between the student and the teacher. Using this approach, when data samples come from a discrete domain, such as applications of natural language processing (NLP) and language understanding, is not trivial. However, we show how this technique can be used successfully in such applications. We evaluated the performance of our method on various tasks in computer vision and NLP domains and got promising results.
Improving Generalization of Pre-trained Language Models via Stochastic Weight Averaging
Dec 16, 2022



Knowledge Distillation (KD) is a commonly used technique for improving the generalization of compact Pre-trained Language Models (PLMs) on downstream tasks. However, such methods impose the additional burden of training a separate teacher model for every new dataset. Alternatively, one may directly work on the improvement of the optimization procedure of the compact model toward better generalization. Recent works observe that the flatness of the local minimum correlates well with better generalization. In this work, we adapt Stochastic Weight Averaging (SWA), a method encouraging convergence to a flatter minimum, to fine-tuning PLMs. We conduct extensive experiments on various NLP tasks (text classification, question answering, and generation) and different model architectures and demonstrate that our adaptation improves the generalization without extra computation cost. Moreover, we observe that this simple optimization technique is able to outperform the state-of-the-art KD methods for compact models.
Continuation KD: Improved Knowledge Distillation through the Lens of Continuation Optimization
Dec 12, 2022Knowledge Distillation (KD) has been extensively used for natural language understanding (NLU) tasks to improve a small model's (a student) generalization by transferring the knowledge from a larger model (a teacher). Although KD methods achieve state-of-the-art performance in numerous settings, they suffer from several problems limiting their performance. It is shown in the literature that the capacity gap between the teacher and the student networks can make KD ineffective. Additionally, existing KD techniques do not mitigate the noise in the teacher's output: modeling the noisy behaviour of the teacher can distract the student from learning more useful features. We propose a new KD method that addresses these problems and facilitates the training compared to previous techniques. Inspired by continuation optimization, we design a training procedure that optimizes the highly non-convex KD objective by starting with the smoothed version of this objective and making it more complex as the training proceeds. Our method (Continuation-KD) achieves state-of-the-art performance across various compact architectures on NLU (GLUE benchmark) and computer vision tasks (CIFAR-10 and CIFAR-100).
DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation
Oct 14, 2022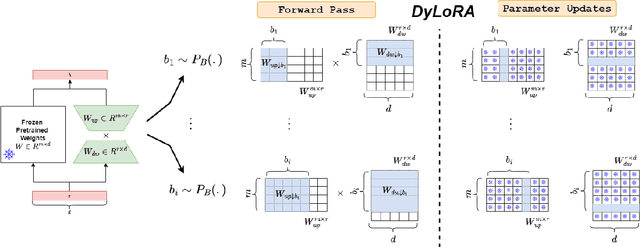
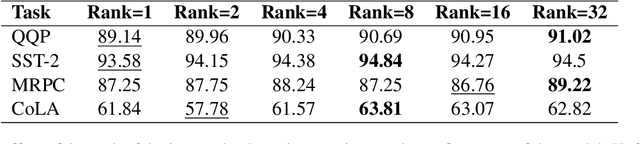

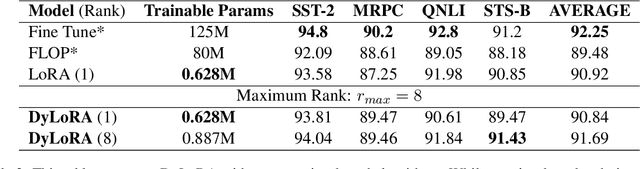
With the ever-growing size of pre-trained models (PMs), fine-tuning them has become more expensive and resource-hungry. As a remedy, low-rank adapters (LoRA) keep the main pre-trained weights of the model frozen and just introduce some learnable truncated SVD modules (so-called LoRA blocks) to the model. While LoRA blocks are parameter efficient, they suffer from two major problems: first, the size of these blocks is fixed and cannot be modified after training (for example, if we need to change the rank of LoRA blocks, then we need to re-train them from scratch); second, optimizing their rank requires an exhaustive search and effort. In this work, we introduce a dynamic low-rank adaptation (DyLoRA) technique to address these two problems together. Our DyLoRA method trains LoRA blocks for a range of ranks instead of a single rank by sorting out the representation learned by the adapter module at different ranks during training. We evaluate our solution on different tasks of the GLUE benchmark using the RoBERTa model. Our results show that we can train dynamic search-free models with DyLoRA at least $7\times$ faster than LoRA without significantly compromising performance. Moreover, our models can perform consistently well on a much larger range of ranks compared to LoRA.
Towards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
May 25, 2022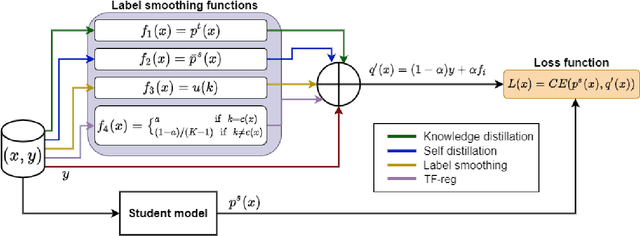
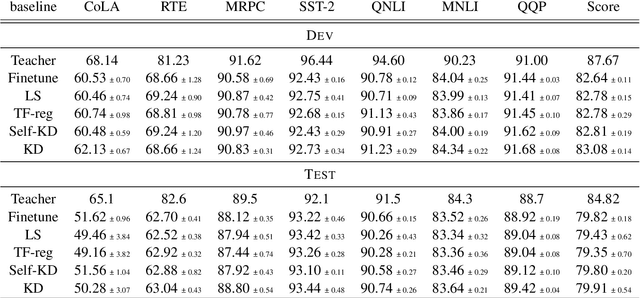
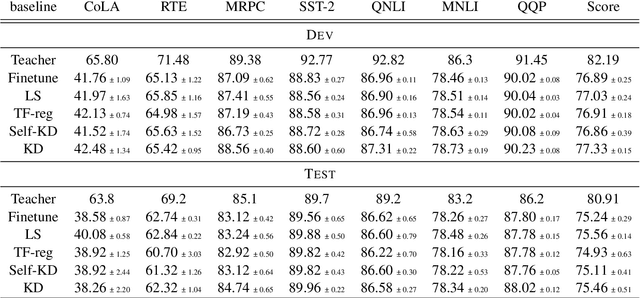
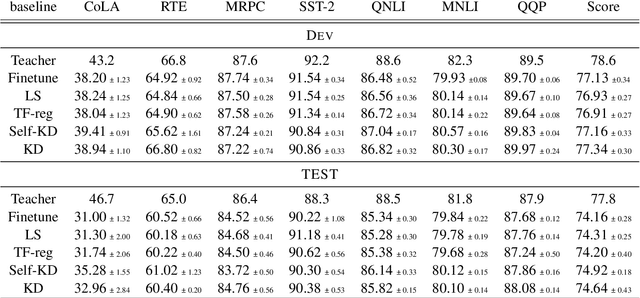
Knowledge Distillation (KD) is a prominent neural model compression technique which heavily relies on teacher network predictions to guide the training of a student model. Considering the ever-growing size of pre-trained language models (PLMs), KD is often adopted in many NLP tasks involving PLMs. However, it is evident that in KD, deploying the teacher network during training adds to the memory and computational requirements of training. In the computer vision literature, the necessity of the teacher network is put under scrutiny by showing that KD is a label regularization technique that can be replaced with lighter teacher-free variants such as the label-smoothing technique. However, to the best of our knowledge, this issue is not investigated in NLP. Therefore, this work concerns studying different label regularization techniques and whether we actually need the teacher labels to fine-tune smaller PLM student networks on downstream tasks. In this regard, we did a comprehensive set of experiments on different PLMs such as BERT, RoBERTa, and GPT with more than 600 distinct trials and ran each configuration five times. This investigation led to a surprising observation that KD and other label regularization techniques do not play any meaningful role over regular fine-tuning when the student model is pre-trained. We further explore this phenomenon in different settings of NLP and computer vision tasks and demonstrate that pre-training itself acts as a kind of regularization, and additional label regularization is unnecessary.
Theoretical Connection between Locally Linear Embedding, Factor Analysis, and Probabilistic PCA
Mar 25, 2022Locally Linear Embedding (LLE) is a nonlinear spectral dimensionality reduction and manifold learning method. It has two main steps which are linear reconstruction and linear embedding of points in the input space and embedding space, respectively. In this work, we look at the linear reconstruction step from a stochastic perspective where it is assumed that every data point is conditioned on its linear reconstruction weights as latent factors. The stochastic linear reconstruction of LLE is solved using expectation maximization. We show that there is a theoretical connection between three fundamental dimensionality reduction methods, i.e., LLE, factor analysis, and probabilistic Principal Component Analysis (PCA). The stochastic linear reconstruction of LLE is formulated similar to the factor analysis and probabilistic PCA. It is also explained why factor analysis and probabilistic PCA are linear and LLE is a nonlinear method. This work combines and makes a bridge between two broad approaches of dimensionality reduction, i.e., the spectral and probabilistic algorithms.
When Chosen Wisely, More Data Is What You Need: A Universal Sample-Efficient Strategy For Data Augmentation
Mar 17, 2022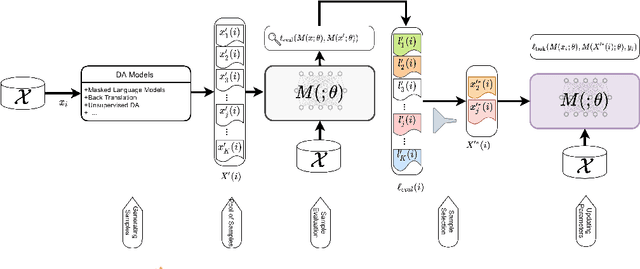
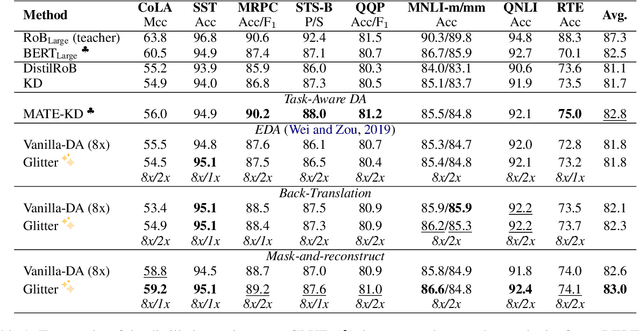
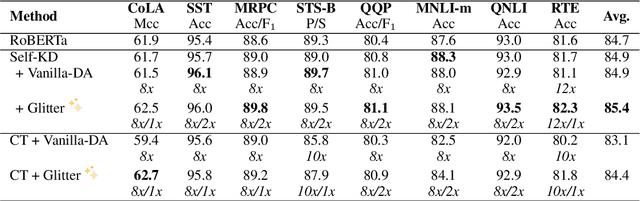

Data Augmentation (DA) is known to improve the generalizability of deep neural networks. Most existing DA techniques naively add a certain number of augmented samples without considering the quality and the added computational cost of these samples. To tackle this problem, a common strategy, adopted by several state-of-the-art DA methods, is to adaptively generate or re-weight augmented samples with respect to the task objective during training. However, these adaptive DA methods: (1) are computationally expensive and not sample-efficient, and (2) are designed merely for a specific setting. In this work, we present a universal DA technique, called Glitter, to overcome both issues. Glitter can be plugged into any DA method, making training sample-efficient without sacrificing performance. From a pre-generated pool of augmented samples, Glitter adaptively selects a subset of worst-case samples with maximal loss, analogous to adversarial DA. Without altering the training strategy, the task objective can be optimized on the selected subset. Our thorough experiments on the GLUE benchmark, SQuAD, and HellaSwag in three widely used training setups including consistency training, self-distillation and knowledge distillation reveal that Glitter is substantially faster to train and achieves a competitive performance, compared to strong baselines.