 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020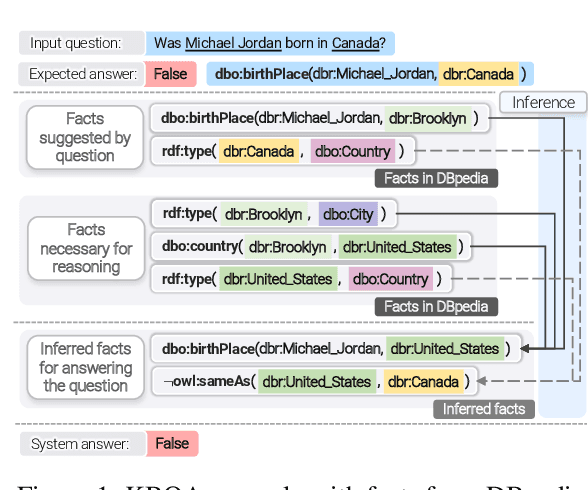
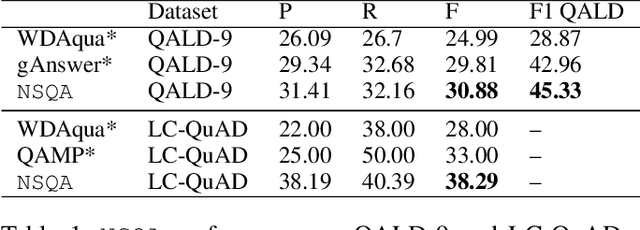
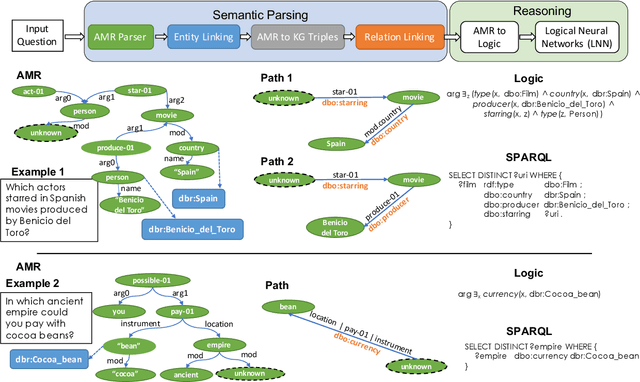

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
SeMantic AnsweR Type prediction task at ISWC 2020 Semantic Web Challenge
Dec 01, 2020

Each year the International Semantic Web Conference accepts a set of Semantic Web Challenges to establish competitions that will advance the state of the art solutions in any given problem domain. The SeMantic AnsweR Type prediction task (SMART) was part of ISWC 2020 challenges. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the task of SMART challenge is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata).
Leveraging Semantic Parsing for Relation Linking over Knowledge Bases
Sep 16, 2020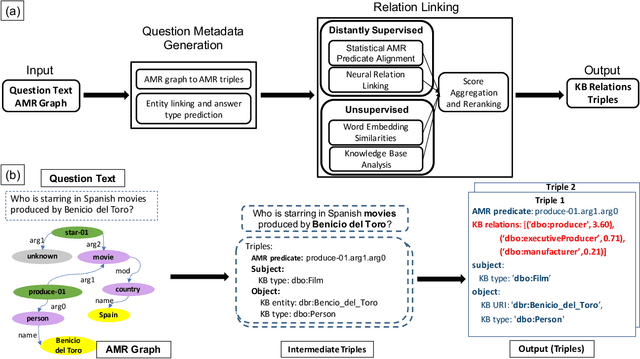

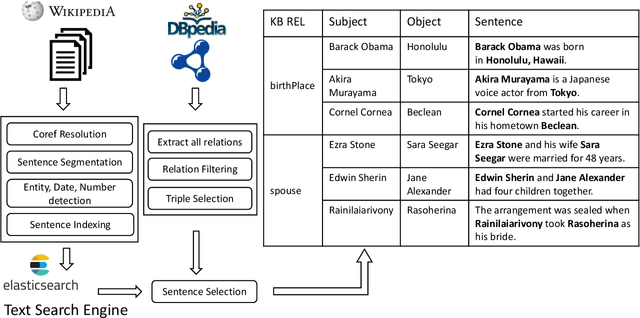
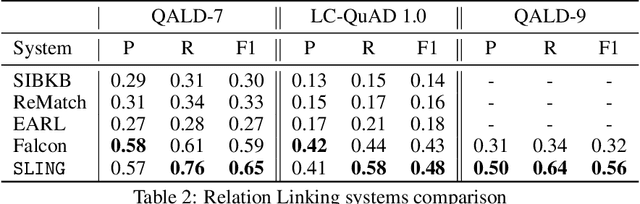
Knowledgebase question answering systems are heavily dependent on relation extraction and linking modules. However, the task of extracting and linking relations from text to knowledgebases faces two primary challenges; the ambiguity of natural language and lack of training data. To overcome these challenges, we present SLING, a relation linking framework which leverages semantic parsing using Abstract Meaning Representation (AMR) and distant supervision. SLING integrates multiple relation linking approaches that capture complementary signals such as linguistic cues, rich semantic representation, and information from the knowledgebase. The experiments on relation linking using three KBQA datasets; QALD-7, QALD-9, and LC-QuAD 1.0 demonstrate that the proposed approach achieves state-of-the-art performance on all benchmarks.
Inducing Hypernym Relationships Based On Order Theory
Sep 23, 2019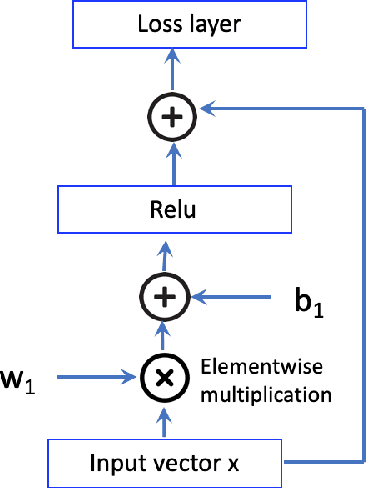
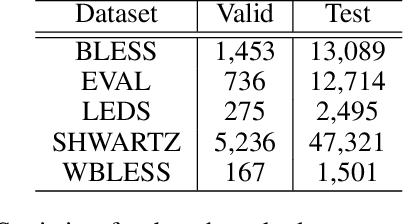
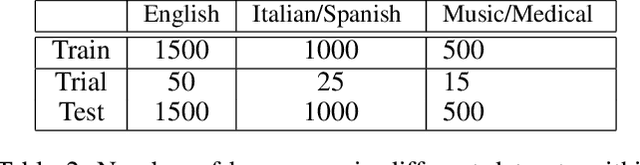
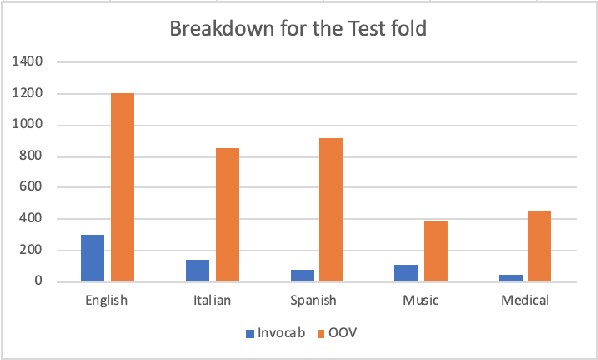
This paper introduces Strict Partial Order Networks (SPON), a novel neural network architecture designed to enforce asymmetry and transitive properties as soft constraints. We apply it to induce hypernymy relations by training with is-a pairs. We also present an augmented variant of SPON that can generalize type information learned for in-vocabulary terms to previously unseen ones. An extensive evaluation over eleven benchmarks across different tasks shows that SPON consistently either outperforms or attains the state of the art on all but one of these benchmarks.
Frustratingly Easy Natural Question Answering
Sep 11, 2019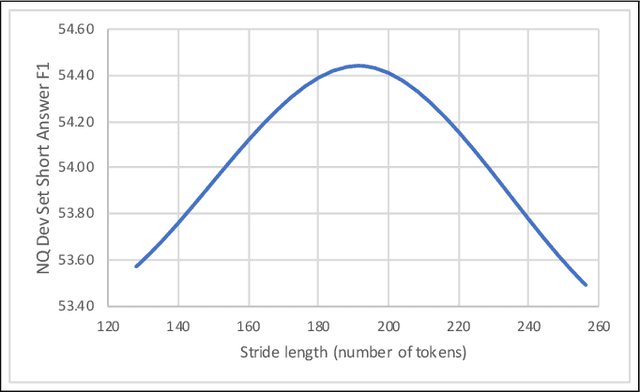
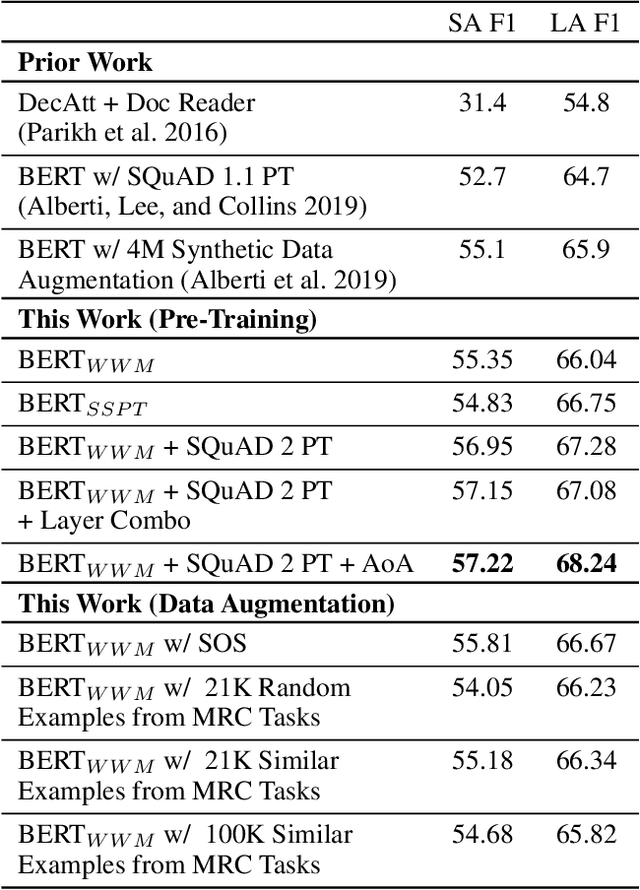
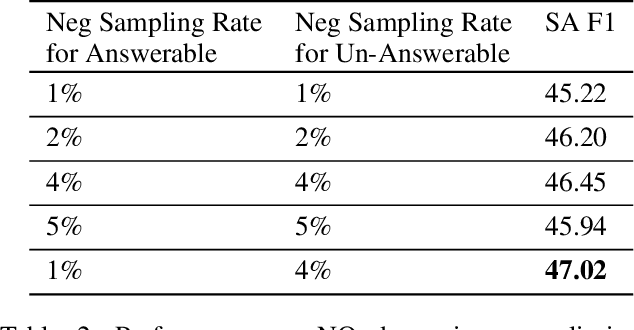
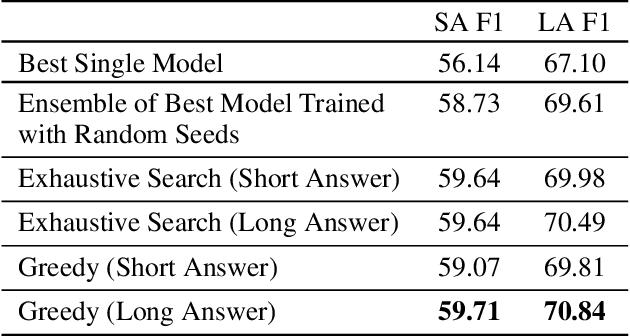
Existing literature on Question Answering (QA) mostly focuses on algorithmic novelty, data augmentation, or increasingly large pre-trained language models like XLNet and RoBERTa. Additionally, a lot of systems on the QA leaderboards do not have associated research documentation in order to successfully replicate their experiments. In this paper, we outline these algorithmic components such as Attention-over-Attention, coupled with data augmentation and ensembling strategies that have shown to yield state-of-the-art results on benchmark datasets like SQuAD, even achieving super-human performance. Contrary to these prior results, when we evaluate on the recently proposed Natural Questions benchmark dataset, we find that an incredibly simple approach of transfer learning from BERT outperforms the previous state-of-the-art system trained on 4 million more examples than ours by 1.9 F1 points. Adding ensembling strategies further improves that number by 2.3 F1 points.
Populating Web Scale Knowledge Graphs using Distantly Supervised Relation Extraction and Validation
Sep 11, 2019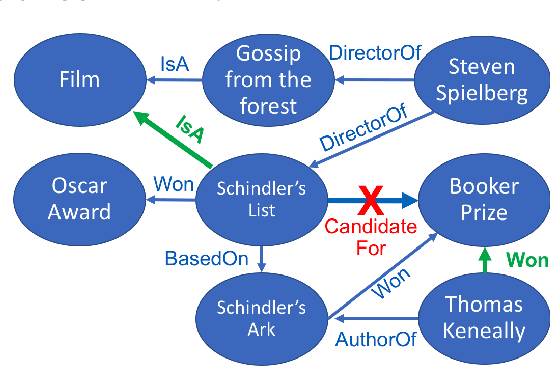
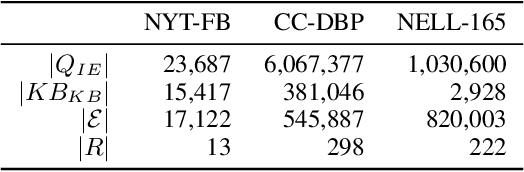
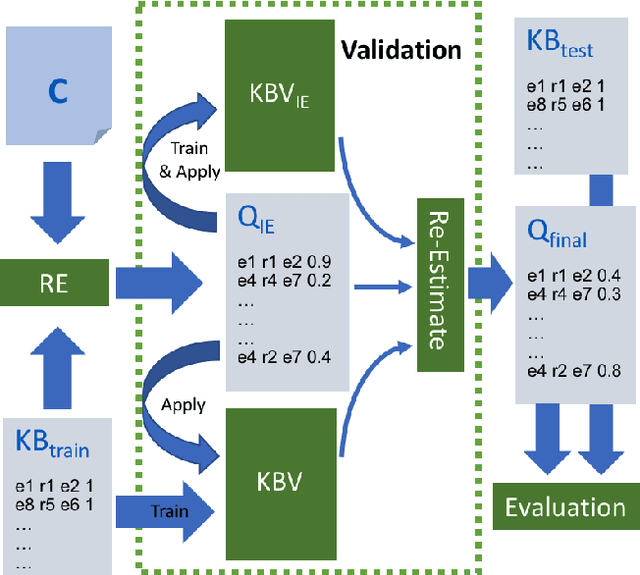
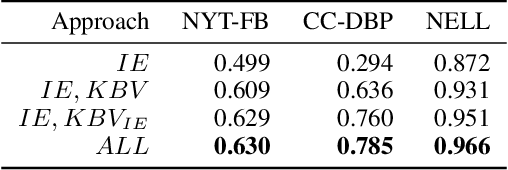
In this paper, we propose a fully automated system to extend knowledge graphs using external information from web-scale corpora. The designed system leverages a deep learning based technology for relation extraction that can be trained by a distantly supervised approach. In addition to that, the system uses a deep learning approach for knowledge base completion by utilizing the global structure information of the induced KG to further refine the confidence of the newly discovered relations. The designed system does not require any effort for adaptation to new languages and domains as it does not use any hand-labeled data, NLP analytics and inference rules. Our experiments, performed on a popular academic benchmark demonstrate that the suggested system boosts the performance of relation extraction by a wide margin, reporting error reductions of 50%, resulting in relative improvement of up to 100%. Also, a web-scale experiment conducted to extend DBPedia with knowledge from Common Crawl shows that our system is not only scalable but also does not require any adaptation cost, while yielding substantial accuracy gain.
Span Selection Pre-training for Question Answering
Sep 09, 2019
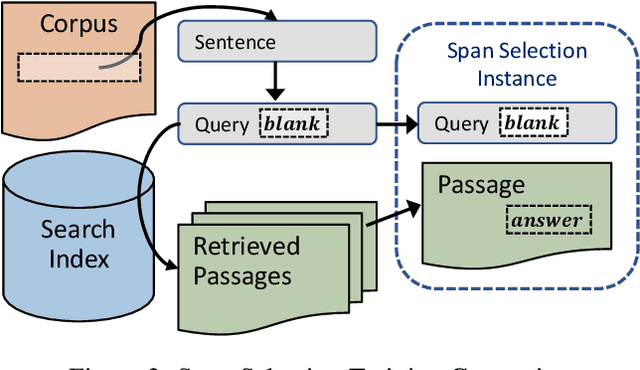

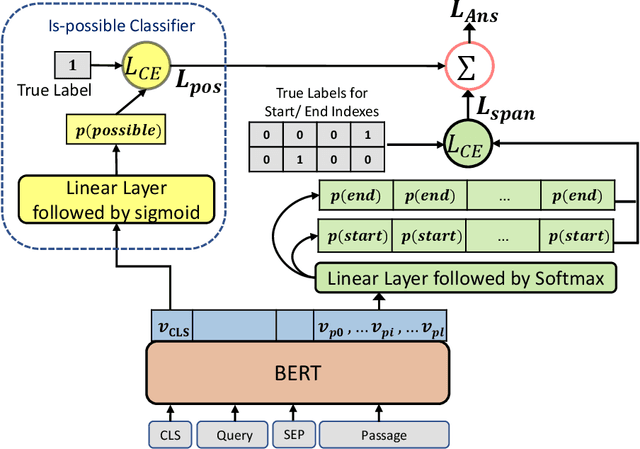
BERT (Bidirectional Encoder Representations from Transformers) and related pre-trained Transformers have provided large gains across many language understanding tasks, achieving a new state-of-the-art (SOTA). BERT is pre-trained on two auxiliary tasks: Masked Language Model and Next Sentence Prediction. In this paper we introduce a new pre-training task inspired by reading comprehension and an effort to avoid encoding general knowledge in the transformer network itself. We find significant and consistent improvements over both BERT-BASE and BERT-LARGE on multiple reading comprehension (MRC) and paraphrasing datasets. Specifically, our proposed model has strong empirical evidence as it obtains SOTA results on Natural Questions, a new benchmark MRC dataset, outperforming BERT-LARGE by 3 F1 points on short answer prediction. We also establish a new SOTA in HotpotQA, improving answer prediction F1 by 4 F1 points and supporting fact prediction by 1 F1 point. Moreover, we show that our pre-training approach is particularly effective when training data is limited, improving the learning curve by a large amount.
Distributional Negative Sampling for Knowledge Base Completion
Aug 16, 2019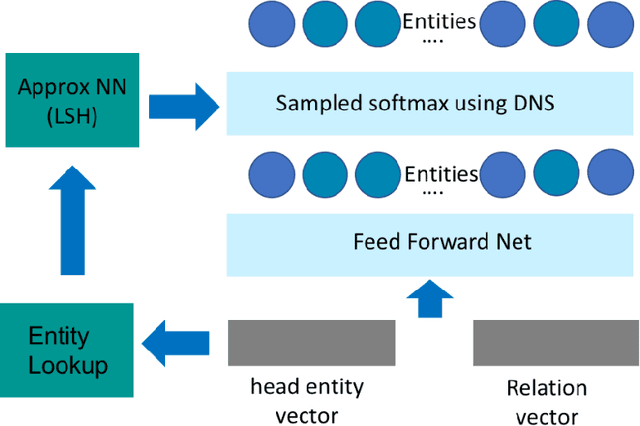
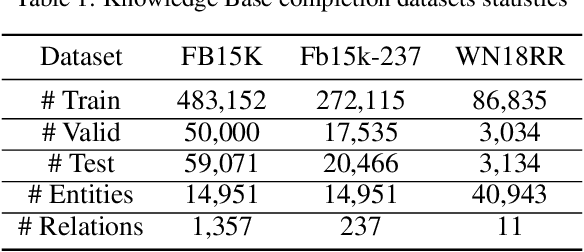
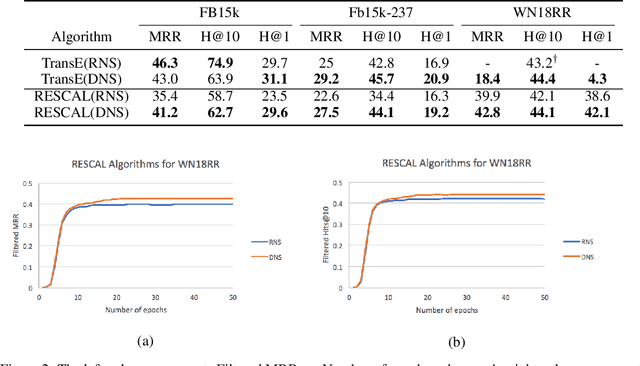

State-of-the-art approaches for Knowledge Base Completion (KBC) exploit deep neural networks trained with both false and true assertions: positive assertions are explicitly taken from the knowledge base, whereas negative ones are generated by random sampling of entities. In this paper, we argue that random sampling is not a good training strategy since it is highly likely to generate a huge number of nonsensical assertions during training, which does not provide relevant training signal to the system. Hence, it slows down the learning process and decreases accuracy. To address this issue, we propose an alternative approach called Distributional Negative Sampling that generates meaningful negative examples which are highly likely to be false. Our approach achieves a significant improvement in Mean Reciprocal Rank values amongst two different KBC algorithms in three standard academic benchmarks.