 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-parametric Topological Memory for Navigation
Mar 01, 2018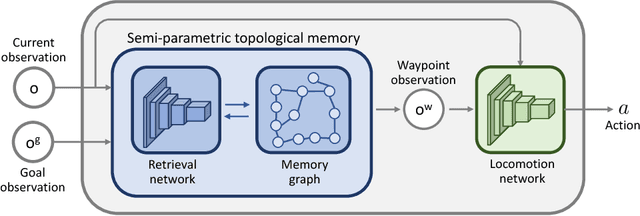

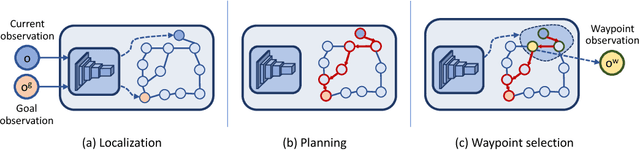

We introduce a new memory architecture for navigation in previously unseen environments, inspired by landmark-based navigation in animals. The proposed semi-parametric topological memory (SPTM) consists of a (non-parametric) graph with nodes corresponding to locations in the environment and a (parametric) deep network capable of retrieving nodes from the graph based on observations. The graph stores no metric information, only connectivity of locations corresponding to the nodes. We use SPTM as a planning module in a navigation system. Given only 5 minutes of footage of a previously unseen maze, an SPTM-based navigation agent can build a topological map of the environment and use it to confidently navigate towards goals. The average success rate of the SPTM agent in goal-directed navigation across test environments is higher than the best-performing baseline by a factor of three. A video of the agent is available at https://youtu.be/vRF7f4lhswo
MINOS: Multimodal Indoor Simulator for Navigation in Complex Environments
Dec 11, 2017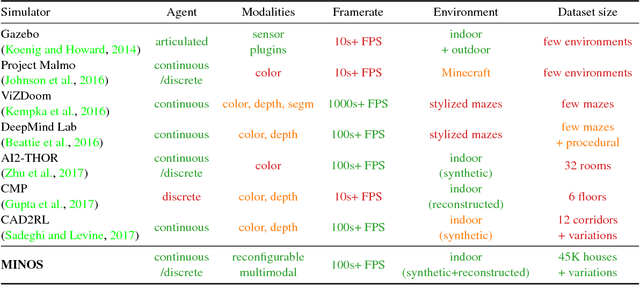
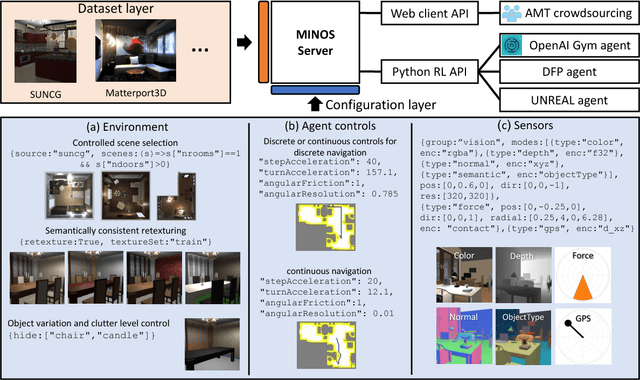

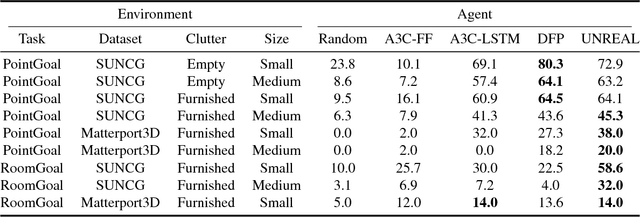
We present MINOS, a simulator designed to support the development of multisensory models for goal-directed navigation in complex indoor environments. The simulator leverages large datasets of complex 3D environments and supports flexible configuration of multimodal sensor suites. We use MINOS to benchmark deep-learning-based navigation methods, to analyze the influence of environmental complexity on navigation performance, and to carry out a controlled study of multimodality in sensorimotor learning. The experiments show that current deep reinforcement learning approaches fail in large realistic environments. The experiments also indicate that multimodality is beneficial in learning to navigate cluttered scenes. MINOS is released open-source to the research community at http://minosworld.org . A video that shows MINOS can be found at https://youtu.be/c0mL9K64q84
CARLA: An Open Urban Driving Simulator
Nov 10, 2017
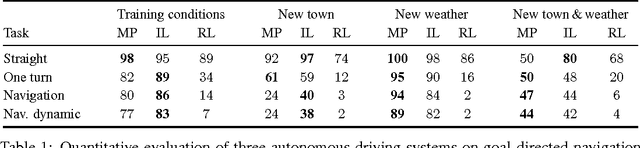

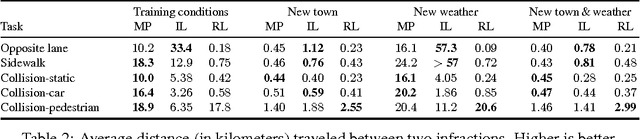
We introduce CARLA, an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous urban driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites and environmental conditions. We use CARLA to study the performance of three approaches to autonomous driving: a classic modular pipeline, an end-to-end model trained via imitation learning, and an end-to-end model trained via reinforcement learning. The approaches are evaluated in controlled scenarios of increasing difficulty, and their performance is examined via metrics provided by CARLA, illustrating the platform's utility for autonomous driving research. The supplementary video can be viewed at https://youtu.be/Hp8Dz-Zek2E
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs
Aug 07, 2017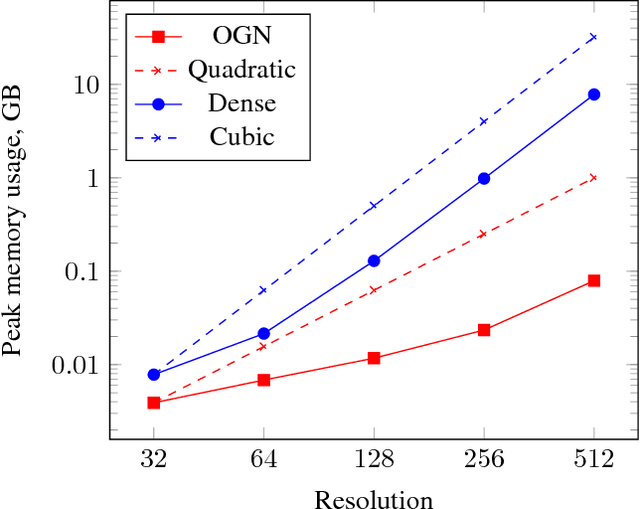
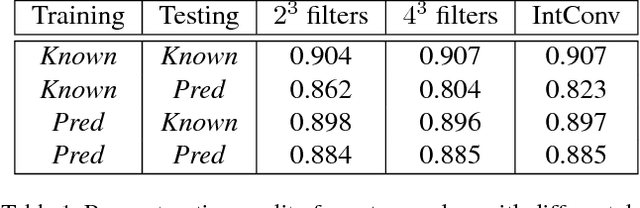
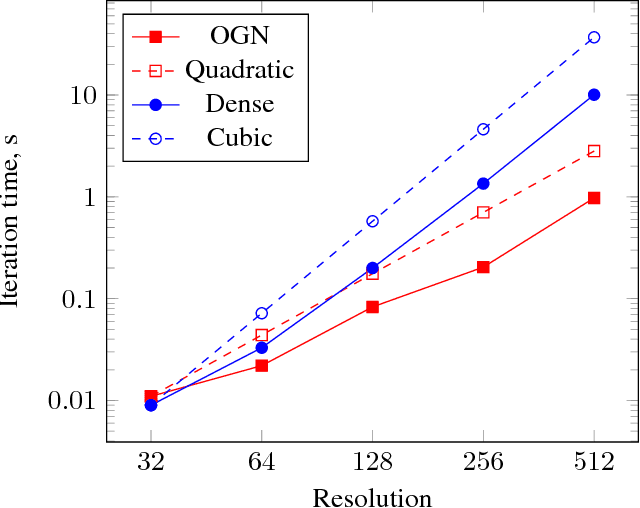
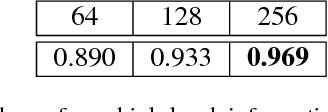
We present a deep convolutional decoder architecture that can generate volumetric 3D outputs in a compute- and memory-efficient manner by using an octree representation. The network learns to predict both the structure of the octree, and the occupancy values of individual cells. This makes it a particularly valuable technique for generating 3D shapes. In contrast to standard decoders acting on regular voxel grids, the architecture does not have cubic complexity. This allows representing much higher resolution outputs with a limited memory budget. We demonstrate this in several application domains, including 3D convolutional autoencoders, generation of objects and whole scenes from high-level representations, and shape from a single image.
Learning to Generate Chairs, Tables and Cars with Convolutional Networks
Aug 02, 2017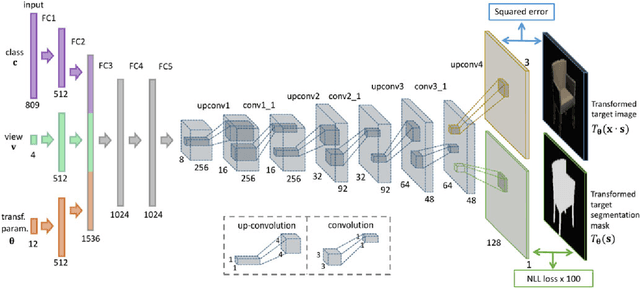
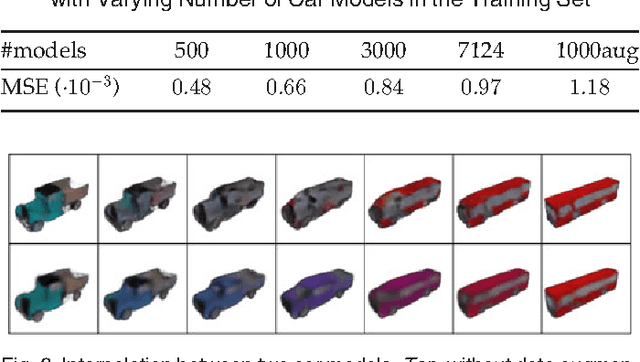

We train generative 'up-convolutional' neural networks which are able to generate images of objects given object style, viewpoint, and color. We train the networks on rendered 3D models of chairs, tables, and cars. Our experiments show that the networks do not merely learn all images by heart, but rather find a meaningful representation of 3D models allowing them to assess the similarity of different models, interpolate between given views to generate the missing ones, extrapolate views, and invent new objects not present in the training set by recombining training instances, or even two different object classes. Moreover, we show that such generative networks can be used to find correspondences between different objects from the dataset, outperforming existing approaches on this task.
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
Apr 12, 2017

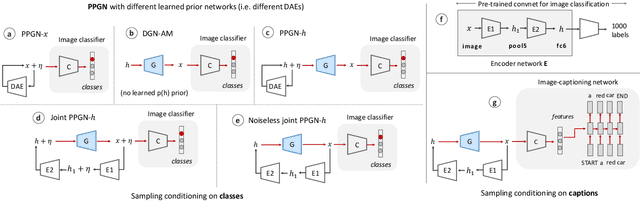

Generating high-resolution, photo-realistic images has been a long-standing goal in machine learning. Recently, Nguyen et al. (2016) showed one interesting way to synthesize novel images by performing gradient ascent in the latent space of a generator network to maximize the activations of one or multiple neurons in a separate classifier network. In this paper we extend this method by introducing an additional prior on the latent code, improving both sample quality and sample diversity, leading to a state-of-the-art generative model that produces high quality images at higher resolutions (227x227) than previous generative models, and does so for all 1000 ImageNet categories. In addition, we provide a unified probabilistic interpretation of related activation maximization methods and call the general class of models "Plug and Play Generative Networks". PPGNs are composed of 1) a generator network G that is capable of drawing a wide range of image types and 2) a replaceable "condition" network C that tells the generator what to draw. We demonstrate the generation of images conditioned on a class (when C is an ImageNet or MIT Places classification network) and also conditioned on a caption (when C is an image captioning network). Our method also improves the state of the art of Multifaceted Feature Visualization, which generates the set of synthetic inputs that activate a neuron in order to better understand how deep neural networks operate. Finally, we show that our model performs reasonably well at the task of image inpainting. While image models are used in this paper, the approach is modality-agnostic and can be applied to many types of data.
DeMoN: Depth and Motion Network for Learning Monocular Stereo
Apr 11, 2017


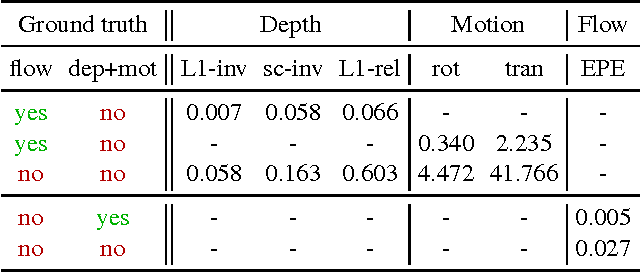
In this paper we formulate structure from motion as a learning problem. We train a convolutional network end-to-end to compute depth and camera motion from successive, unconstrained image pairs. The architecture is composed of multiple stacked encoder-decoder networks, the core part being an iterative network that is able to improve its own predictions. The network estimates not only depth and motion, but additionally surface normals, optical flow between the images and confidence of the matching. A crucial component of the approach is a training loss based on spatial relative differences. Compared to traditional two-frame structure from motion methods, results are more accurate and more robust. In contrast to the popular depth-from-single-image networks, DeMoN learns the concept of matching and, thus, better generalizes to structures not seen during training.
Learning to Act by Predicting the Future
Feb 14, 2017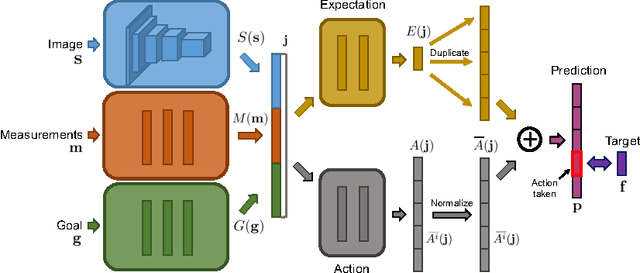
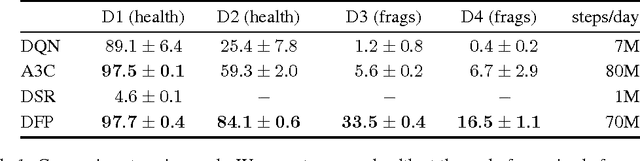

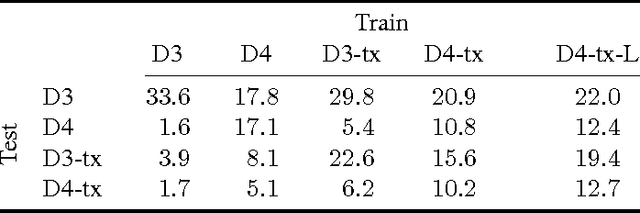
We present an approach to sensorimotor control in immersive environments. Our approach utilizes a high-dimensional sensory stream and a lower-dimensional measurement stream. The cotemporal structure of these streams provides a rich supervisory signal, which enables training a sensorimotor control model by interacting with the environment. The model is trained using supervised learning techniques, but without extraneous supervision. It learns to act based on raw sensory input from a complex three-dimensional environment. The presented formulation enables learning without a fixed goal at training time, and pursuing dynamically changing goals at test time. We conduct extensive experiments in three-dimensional simulations based on the classical first-person game Doom. The results demonstrate that the presented approach outperforms sophisticated prior formulations, particularly on challenging tasks. The results also show that trained models successfully generalize across environments and goals. A model trained using the presented approach won the Full Deathmatch track of the Visual Doom AI Competition, which was held in previously unseen environments.
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
Dec 06, 2016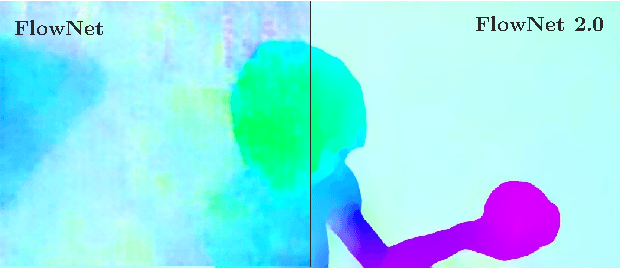
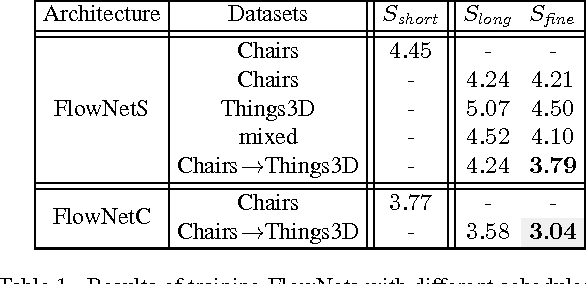
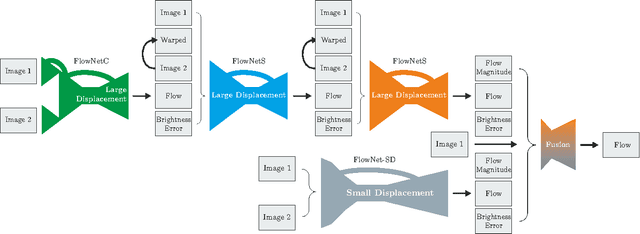

The FlowNet demonstrated that optical flow estimation can be cast as a learning problem. However, the state of the art with regard to the quality of the flow has still been defined by traditional methods. Particularly on small displacements and real-world data, FlowNet cannot compete with variational methods. In this paper, we advance the concept of end-to-end learning of optical flow and make it work really well. The large improvements in quality and speed are caused by three major contributions: first, we focus on the training data and show that the schedule of presenting data during training is very important. Second, we develop a stacked architecture that includes warping of the second image with intermediate optical flow. Third, we elaborate on small displacements by introducing a sub-network specializing on small motions. FlowNet 2.0 is only marginally slower than the original FlowNet but decreases the estimation error by more than 50%. It performs on par with state-of-the-art methods, while running at interactive frame rates. Moreover, we present faster variants that allow optical flow computation at up to 140fps with accuracy matching the original FlowNet.
Synthesizing the preferred inputs for neurons in neural networks via deep generator networks
Nov 23, 2016
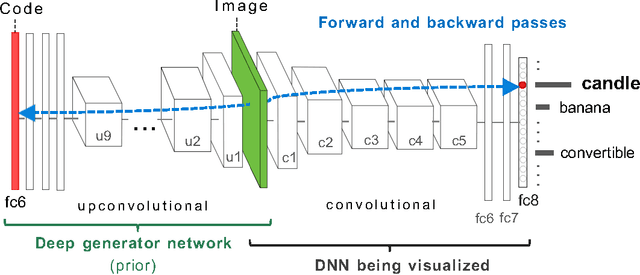


Deep neural networks (DNNs) have demonstrated state-of-the-art results on many pattern recognition tasks, especially vision classification problems. Understanding the inner workings of such computational brains is both fascinating basic science that is interesting in its own right - similar to why we study the human brain - and will enable researchers to further improve DNNs. One path to understanding how a neural network functions internally is to study what each of its neurons has learned to detect. One such method is called activation maximization (AM), which synthesizes an input (e.g. an image) that highly activates a neuron. Here we dramatically improve the qualitative state of the art of activation maximization by harnessing a powerful, learned prior: a deep generator network (DGN). The algorithm (1) generates qualitatively state-of-the-art synthetic images that look almost real, (2) reveals the features learned by each neuron in an interpretable way, (3) generalizes well to new datasets and somewhat well to different network architectures without requiring the prior to be relearned, and (4) can be considered as a high-quality generative method (in this case, by generating novel, creative, interesting, recognizable images).