 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust compressed sensing of generative models
Jun 18, 2020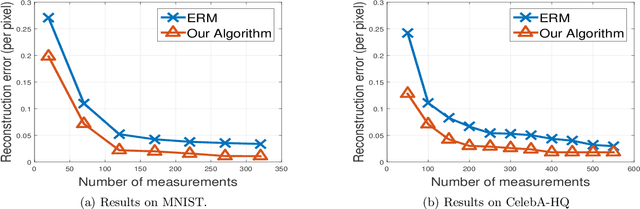
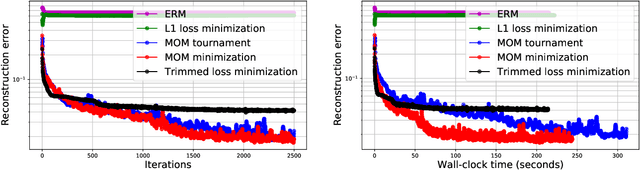

The goal of compressed sensing is to estimate a high dimensional vector from an underdetermined system of noisy linear equations. In analogy to classical compressed sensing, here we assume a generative model as a prior, that is, we assume the vector is represented by a deep generative model $G: \mathbb{R}^k \rightarrow \mathbb{R}^n$. Classical recovery approaches such as empirical risk minimization (ERM) are guaranteed to succeed when the measurement matrix is sub-Gaussian. However, when the measurement matrix and measurements are heavy-tailed or have outliers, recovery may fail dramatically. In this paper we propose an algorithm inspired by the Median-of-Means (MOM). Our algorithm guarantees recovery for heavy-tailed data, even in the presence of outliers. Theoretically, our results show our novel MOM-based algorithm enjoys the same sample complexity guarantees as ERM under sub-Gaussian assumptions. Our experiments validate both aspects of our claims: other algorithms are indeed fragile and fail under heavy-tailed and/or corrupted data, while our approach exhibits the predicted robustness.
Deep Learning Techniques for Inverse Problems in Imaging
May 12, 2020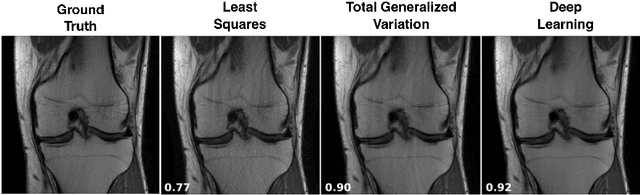
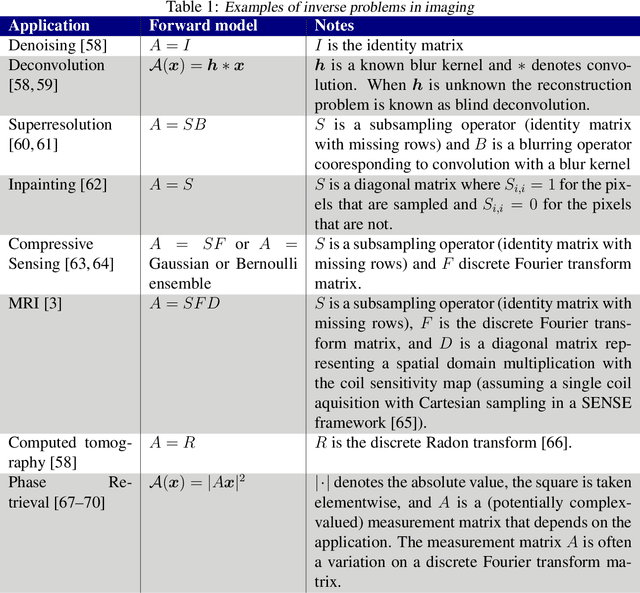

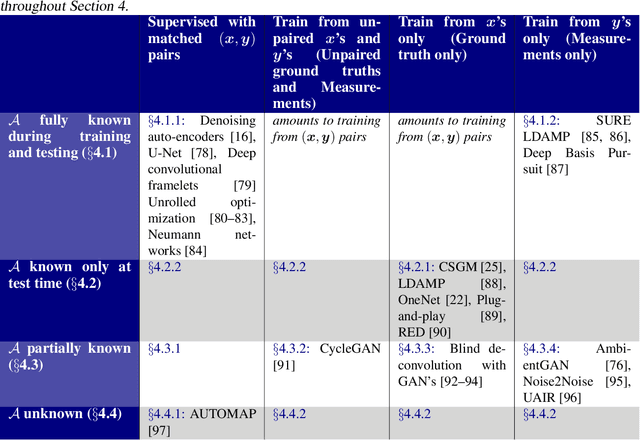
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the trade-offs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.
Compressed Sensing with Invertible Generative Models and Dependent Noise
Mar 18, 2020
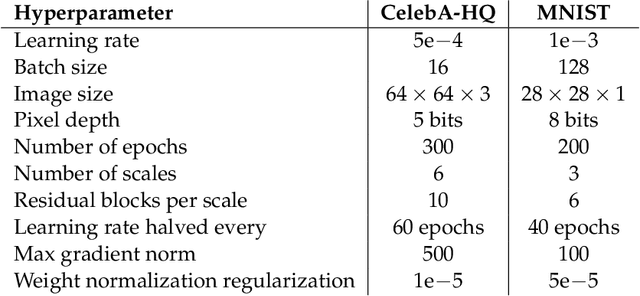
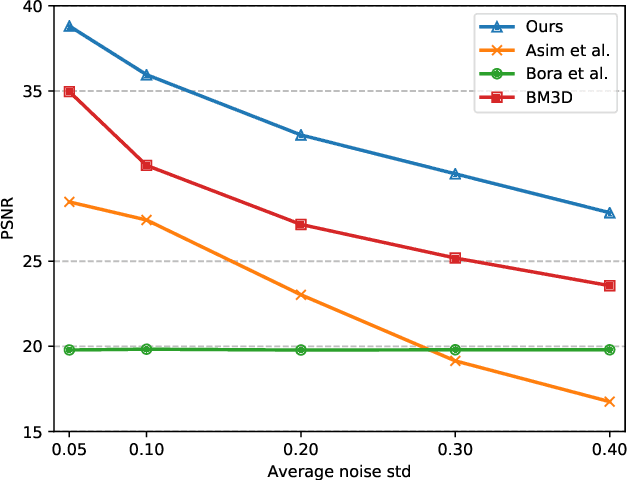
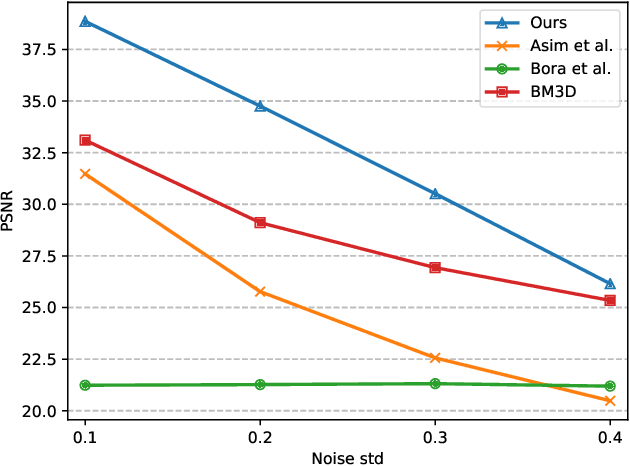
We study image inverse problems with invertible generative priors, specifically normalizing flow models. Our formulation views the solution as the Maximum a Posteriori (MAP) estimate of the image given the measurements. Our general formulation allows for non-linear differentiable forward operators and noise distributions with long-range dependencies. We establish theoretical recovery guarantees for denoising and compressed sensing under our framework. We also empirically validate our method on various inverse problems including compressed sensing with quantized measurements and denoising with dependent noise patterns.
Exactly Computing the Local Lipschitz Constant of ReLU Networks
Mar 02, 2020
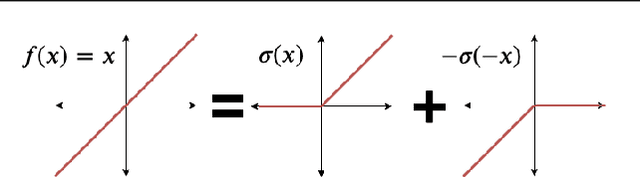
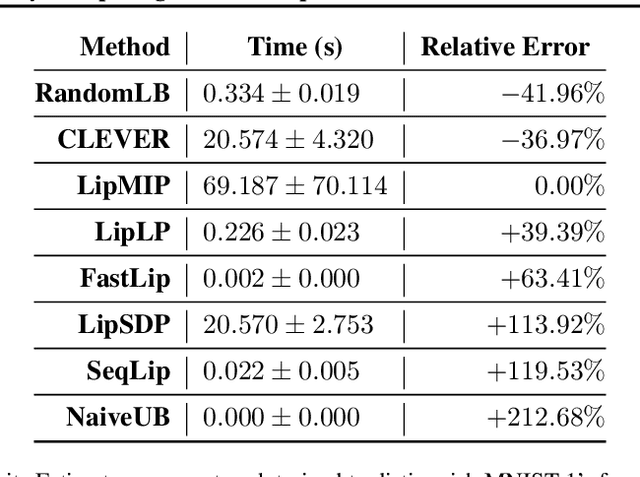
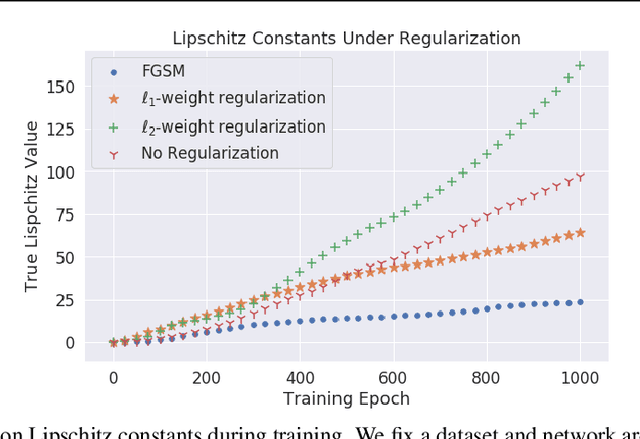
The Lipschitz constant of a neural network is a useful metric for provable robustness and generalization. We present a novel analytic result which relates gradient norms to Lipschitz constants for nondifferentiable functions. Next we prove hardness and inapproximability results for computing the local Lipschitz constant of ReLU neural networks. We develop a mixed-integer programming formulation to exactly compute the local Lipschitz constant for scalar and vector-valued networks. Finally, we apply our technique on networks trained on synthetic datasets and MNIST, drawing observations about the tightness of competing Lipschitz estimators and the effects of regularized training on Lipschitz constants.
Conditional Sampling from Invertible Generative Models with Applications to Inverse Problems
Feb 26, 2020
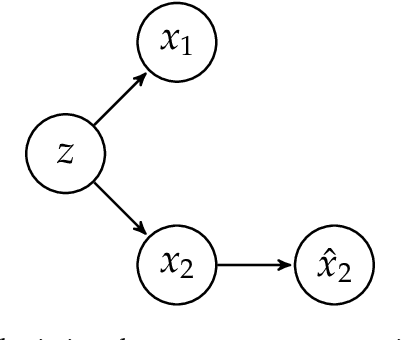

We consider uncertainty aware compressive sensing when the prior distribution is defined by an invertible generative model. In this problem, we receive a set of low dimensional measurements and we want to generate conditional samples of high dimensional objects conditioned on these measurements. We first show that the conditional sampling problem is hard in general, and thus we consider approximations to the problem. We develop a variational approach to conditional sampling that composes a new generative model with the given generative model. This allows us to utilize the sampling ability of the given generative model to quickly generate samples from the conditional distribution.
Your Local GAN: Designing Two Dimensional Local Attention Mechanisms for Generative Models
Dec 02, 2019
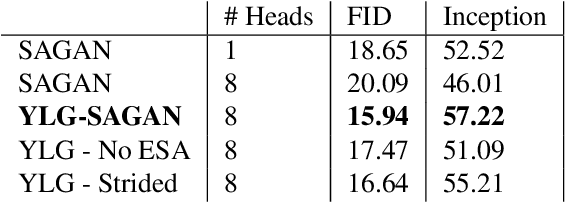
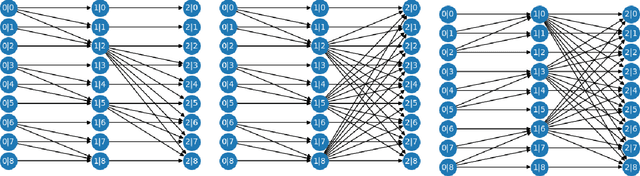

We introduce a new local sparse attention layer that preserves two-dimensional geometry and locality. We show that by just replacing the dense attention layer of SAGAN with our construction, we obtain very significant FID, Inception score and pure visual improvements. FID score is improved from $18.65$ to $15.94$ on ImageNet, keeping all other parameters the same. The sparse attention patterns that we propose for our new layer are designed using a novel information theoretic criterion that uses information flow graphs. We also present a novel way to invert Generative Adversarial Networks with attention. Our method extracts from the attention layer of the discriminator a saliency map, which we use to construct a new loss function for the inversion. This allows us to visualize the newly introduced attention heads and show that they indeed capture interesting aspects of two-dimensional geometry of real images.
Communication-Efficient Asynchronous Stochastic Frank-Wolfe over Nuclear-norm Balls
Oct 17, 2019
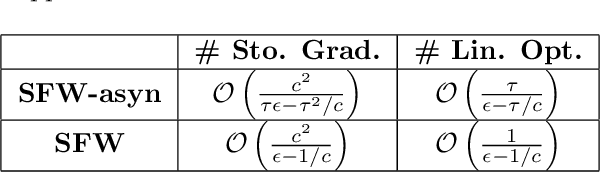
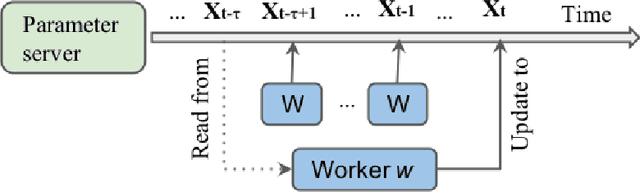
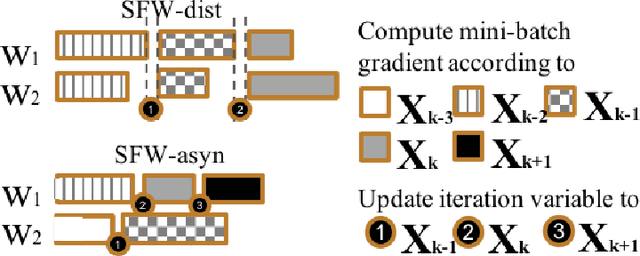
Large-scale machine learning training suffers from two prior challenges, specifically for nuclear-norm constrained problems with distributed systems: the synchronization slowdown due to the straggling workers, and high communication costs. In this work, we propose an asynchronous Stochastic Frank Wolfe (SFW-asyn) method, which, for the first time, solves the two problems simultaneously, while successfully maintaining the same convergence rate as the vanilla SFW. We implement our algorithm in python (with MPI) to run on Amazon EC2, and demonstrate that SFW-asyn yields speed-ups almost linear to the number of machines compared to the vanilla SFW.
SGD Learns One-Layer Networks in WGANs
Oct 15, 2019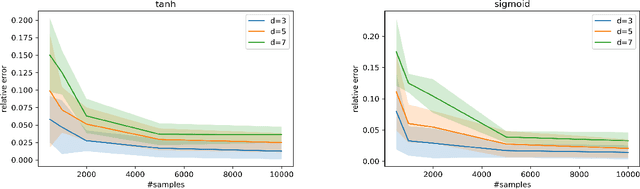
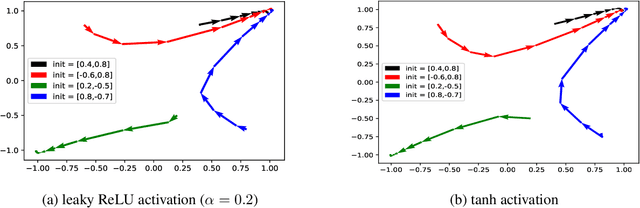
Generative adversarial networks (GANs) are a widely used framework for learning generative models. Wasserstein GANs (WGANs), one of the most successful variants of GANs, require solving a minmax optimization problem to global optimality, but are in practice successfully trained using stochastic gradient descent-ascent. In this paper, we show that, when the generator is a one-layer network, stochastic gradient descent-ascent converges to a global solution with polynomial time and sample complexity.
Learning Distributions Generated by One-Layer ReLU Networks
Sep 19, 2019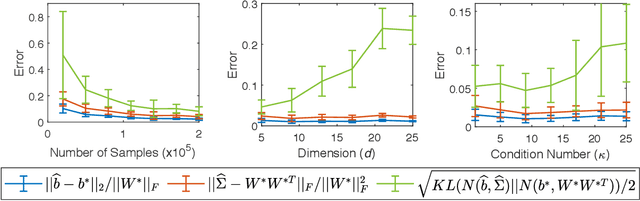
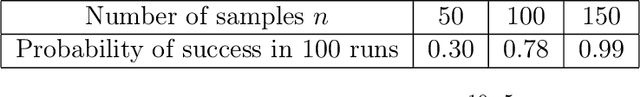
We consider the problem of estimating the parameters of a $d$-dimensional rectified Gaussian distribution from i.i.d. samples. A rectified Gaussian distribution is defined by passing a standard Gaussian distribution through a one-layer ReLU neural network. We give a simple algorithm to estimate the parameters (i.e., the weight matrix and bias vector of the ReLU neural network) up to an error $\epsilon||W||_F$ using $\tilde{O}(1/\epsilon^2)$ samples and $\tilde{O}(d^2/\epsilon^2)$ time (log factors are ignored for simplicity). This implies that we can estimate the distribution up to $\epsilon$ in total variation distance using $\tilde{O}(\kappa^2d^2/\epsilon^2)$ samples, where $\kappa$ is the condition number of the covariance matrix. Our only assumption is that the bias vector is non-negative. Without this non-negativity assumption, we show that estimating the bias vector within any error requires the number of samples at least exponential in the infinity norm of the bias vector. Our algorithm is based on the key observation that vector norms and pairwise angles can be estimated separately. We use a recent result on learning from truncated samples. We also prove two sample complexity lower bounds: $\Omega(1/\epsilon^2)$ samples are required to estimate the parameters up to error $\epsilon$, while $\Omega(d/\epsilon^2)$ samples are necessary to estimate the distribution up to $\epsilon$ in total variation distance. The first lower bound implies that our algorithm is optimal for parameter estimation. Finally, we show an interesting connection between learning a two-layer generative model and non-negative matrix factorization. Experimental results are provided to support our analysis.
Inverting Deep Generative models, One layer at a time
Jun 19, 2019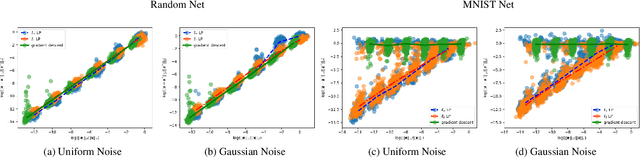

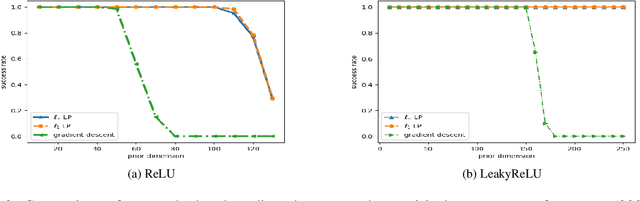

We study the problem of inverting a deep generative model with ReLU activations. Inversion corresponds to finding a latent code vector that explains observed measurements as much as possible. In most prior works this is performed by attempting to solve a non-convex optimization problem involving the generator. In this paper we obtain several novel theoretical results for the inversion problem. We show that for the realizable case, single layer inversion can be performed exactly in polynomial time, by solving a linear program. Further, we show that for multiple layers, inversion is NP-hard and the pre-image set can be non-convex. For generative models of arbitrary depth, we show that exact recovery is possible in polynomial time with high probability, if the layers are expanding and the weights are randomly selected. Very recent work analyzed the same problem for gradient descent inversion. Their analysis requires significantly higher expansion (logarithmic in the latent dimension) while our proposed algorithm can provably reconstruct even with constant factor expansion. We also provide provable error bounds for different norms for reconstructing noisy observations. Our empirical validation demonstrates that we obtain better reconstructions when the latent dimension is large.