 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Inverse Problems with NerfGANs
Dec 16, 2021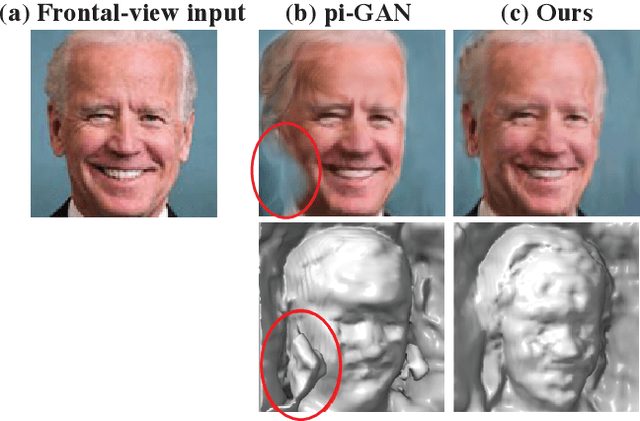
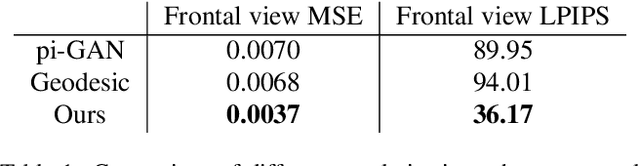

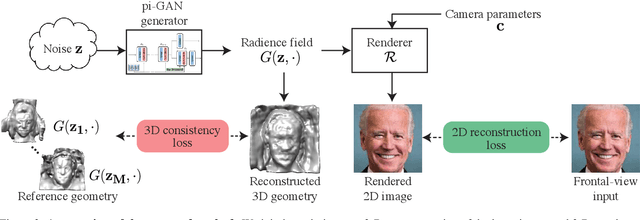
We introduce a novel framework for solving inverse problems using NeRF-style generative models. We are interested in the problem of 3-D scene reconstruction given a single 2-D image and known camera parameters. We show that naively optimizing the latent space leads to artifacts and poor novel view rendering. We attribute this problem to volume obstructions that are clear in the 3-D geometry and become visible in the renderings of novel views. We propose a novel radiance field regularization method to obtain better 3-D surfaces and improved novel views given single view observations. Our method naturally extends to general inverse problems including inpainting where one observes only partially a single view. We experimentally evaluate our method, achieving visual improvements and performance boosts over the baselines in a wide range of tasks. Our method achieves $30-40\%$ MSE reduction and $15-25\%$ reduction in LPIPS loss compared to the previous state of the art.
Inverse Problems Leveraging Pre-trained Contrastive Representations
Oct 26, 2021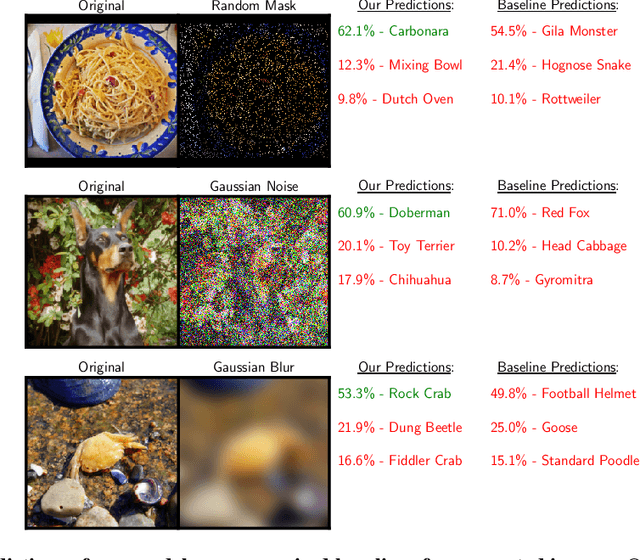
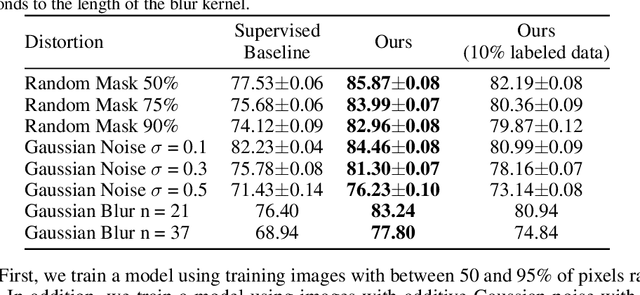
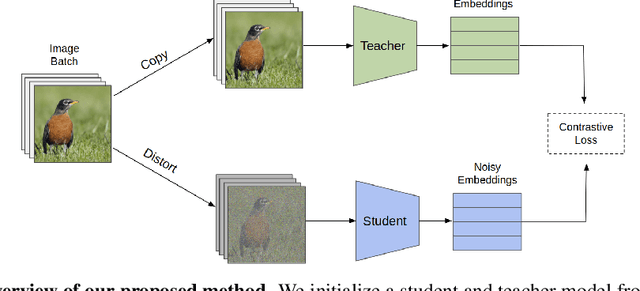
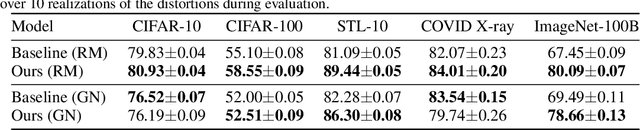
We study a new family of inverse problems for recovering representations of corrupted data. We assume access to a pre-trained representation learning network R(x) that operates on clean images, like CLIP. The problem is to recover the representation of an image R(x), if we are only given a corrupted version A(x), for some known forward operator A. We propose a supervised inversion method that uses a contrastive objective to obtain excellent representations for highly corrupted images. Using a linear probe on our robust representations, we achieve a higher accuracy than end-to-end supervised baselines when classifying images with various types of distortions, including blurring, additive noise, and random pixel masking. We evaluate on a subset of ImageNet and observe that our method is robust to varying levels of distortion. Our method outperforms end-to-end baselines even with a fraction of the labeled data in a wide range of forward operators.
Robust Compressed Sensing MRI with Deep Generative Priors
Aug 03, 2021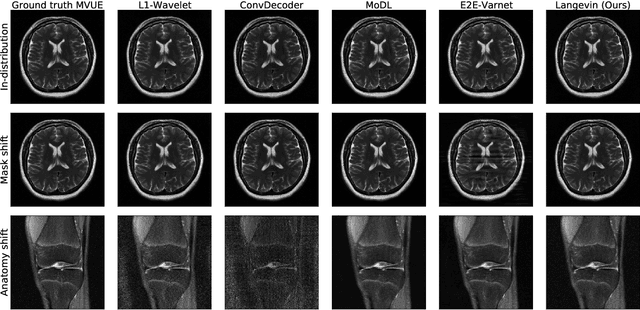
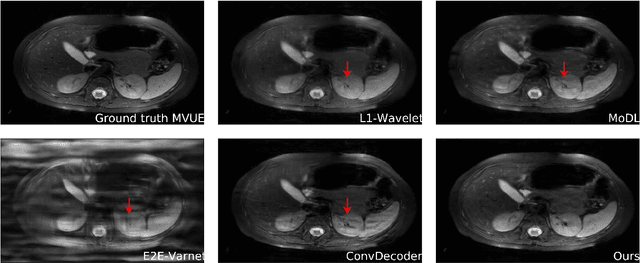
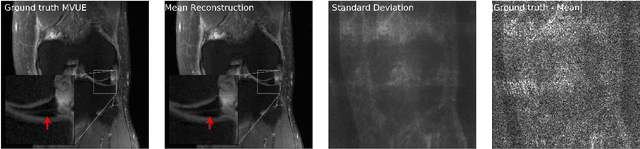
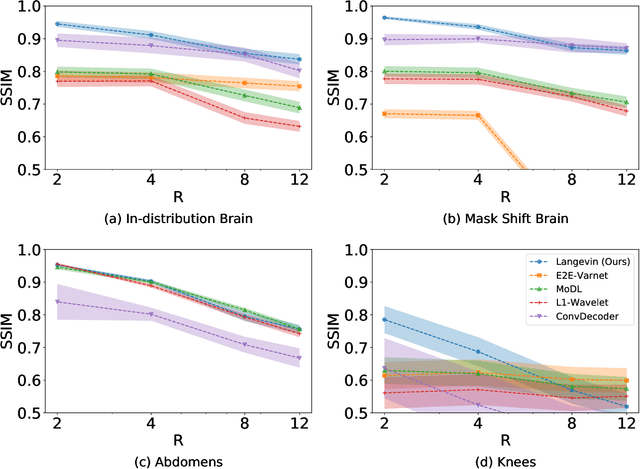
The CSGM framework (Bora-Jalal-Price-Dimakis'17) has shown that deep generative priors can be powerful tools for solving inverse problems. However, to date this framework has been empirically successful only on certain datasets (for example, human faces and MNIST digits), and it is known to perform poorly on out-of-distribution samples. In this paper, we present the first successful application of the CSGM framework on clinical MRI data. We train a generative prior on brain scans from the fastMRI dataset, and show that posterior sampling via Langevin dynamics achieves high quality reconstructions. Furthermore, our experiments and theory show that posterior sampling is robust to changes in the ground-truth distribution and measurement process. Our code and models are available at: \url{https://github.com/utcsilab/csgm-mri-langevin}.
Provable Lipschitz Certification for Generative Models
Jul 06, 2021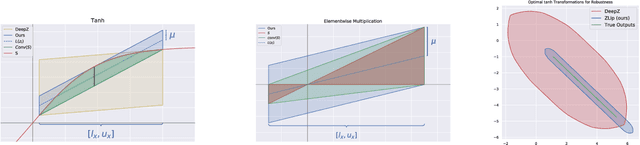
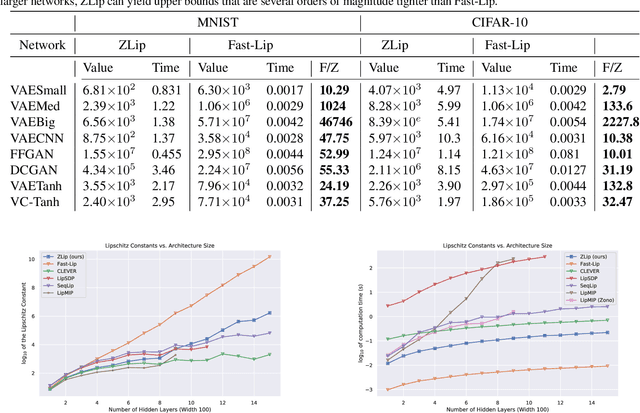
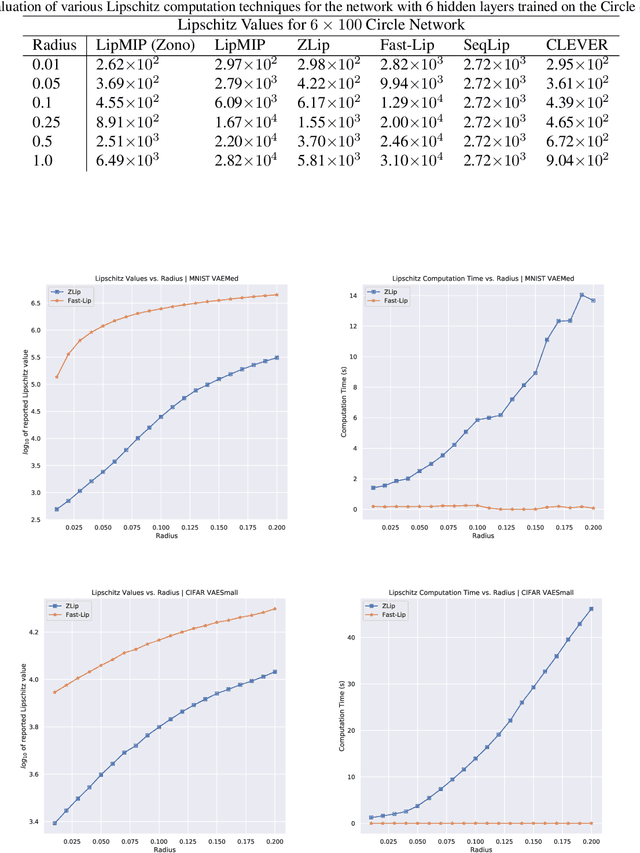

We present a scalable technique for upper bounding the Lipschitz constant of generative models. We relate this quantity to the maximal norm over the set of attainable vector-Jacobian products of a given generative model. We approximate this set by layerwise convex approximations using zonotopes. Our approach generalizes and improves upon prior work using zonotope transformers and we extend to Lipschitz estimation of neural networks with large output dimension. This provides efficient and tight bounds on small networks and can scale to generative models on VAE and DCGAN architectures.
Fairness for Image Generation with Uncertain Sensitive Attributes
Jul 02, 2021
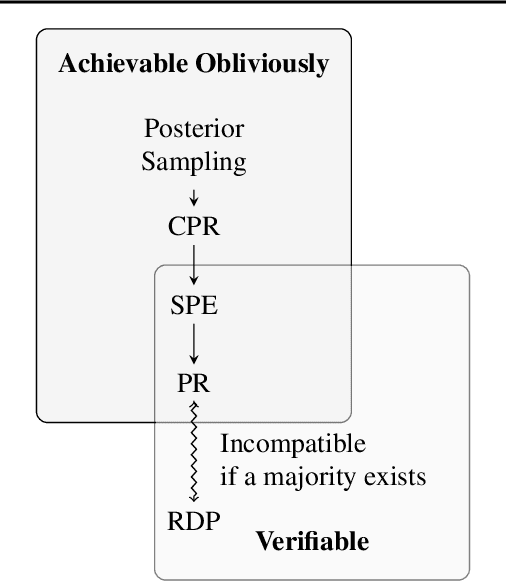
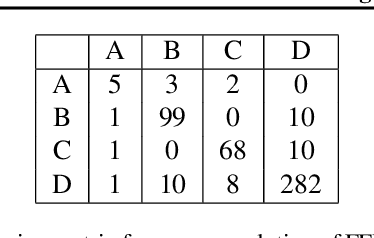
This work tackles the issue of fairness in the context of generative procedures, such as image super-resolution, which entail different definitions from the standard classification setting. Moreover, while traditional group fairness definitions are typically defined with respect to specified protected groups -- camouflaging the fact that these groupings are artificial and carry historical and political motivations -- we emphasize that there are no ground truth identities. For instance, should South and East Asians be viewed as a single group or separate groups? Should we consider one race as a whole or further split by gender? Choosing which groups are valid and who belongs in them is an impossible dilemma and being "fair" with respect to Asians may require being "unfair" with respect to South Asians. This motivates the introduction of definitions that allow algorithms to be \emph{oblivious} to the relevant groupings. We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and \emph{impossible} to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical results and achieve fair image reconstruction using state-of-the-art generative models.
Instance-Optimal Compressed Sensing via Posterior Sampling
Jun 21, 2021

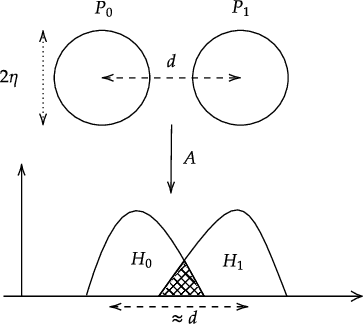
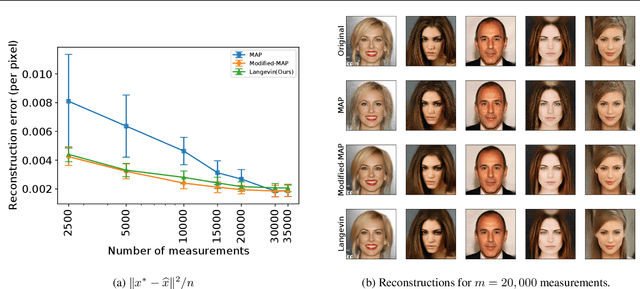
We characterize the measurement complexity of compressed sensing of signals drawn from a known prior distribution, even when the support of the prior is the entire space (rather than, say, sparse vectors). We show for Gaussian measurements and \emph{any} prior distribution on the signal, that the posterior sampling estimator achieves near-optimal recovery guarantees. Moreover, this result is robust to model mismatch, as long as the distribution estimate (e.g., from an invertible generative model) is close to the true distribution in Wasserstein distance. We implement the posterior sampling estimator for deep generative priors using Langevin dynamics, and empirically find that it produces accurate estimates with more diversity than MAP.
Neural Distributed Source Coding
Jun 05, 2021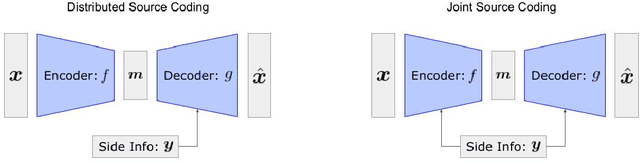
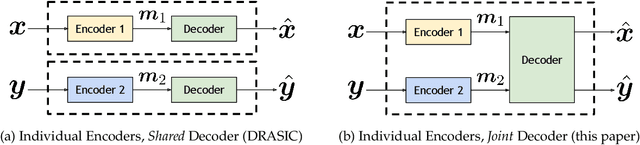


Distributed source coding is the task of encoding an input in the absence of correlated side information that is only available to the decoder. Remarkably, Slepian and Wolf showed in 1973 that an encoder that has no access to the correlated side information can asymptotically achieve the same compression rate as when the side information is available at both the encoder and the decoder. While there is significant prior work on this topic in information theory, practical distributed source coding has been limited to synthetic datasets and specific correlation structures. Here we present a general framework for lossy distributed source coding that is agnostic to the correlation structure and can scale to high dimensions. Rather than relying on hand-crafted source-modeling, our method utilizes a powerful conditional deep generative model to learn the distributed encoder and decoder. We evaluate our method on realistic high-dimensional datasets and show substantial improvements in distributed compression performance.
Intermediate Layer Optimization for Inverse Problems using Deep Generative Models
Feb 15, 2021
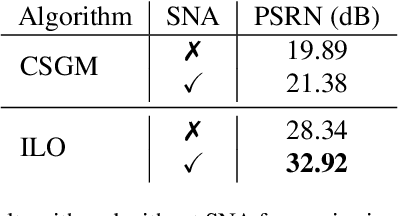
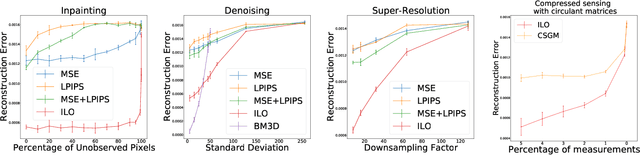

We propose Intermediate Layer Optimization (ILO), a novel optimization algorithm for solving inverse problems with deep generative models. Instead of optimizing only over the initial latent code, we progressively change the input layer obtaining successively more expressive generators. To explore the higher dimensional spaces, our method searches for latent codes that lie within a small $l_1$ ball around the manifold induced by the previous layer. Our theoretical analysis shows that by keeping the radius of the ball relatively small, we can improve the established error bound for compressed sensing with deep generative models. We empirically show that our approach outperforms state-of-the-art methods introduced in StyleGAN-2 and PULSE for a wide range of inverse problems including inpainting, denoising, super-resolution and compressed sensing.
Model-Based Deep Learning
Dec 15, 2020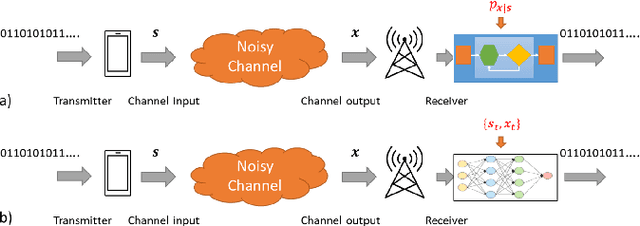
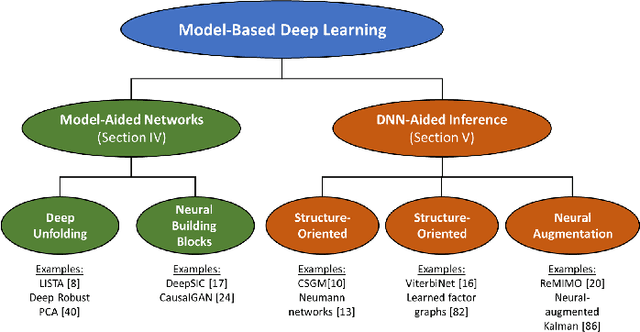
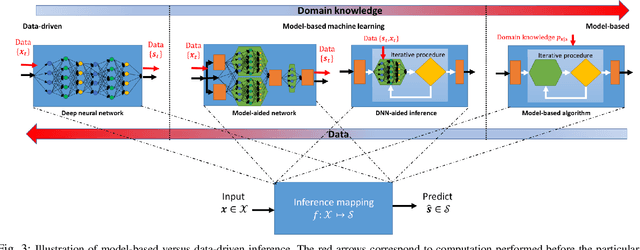
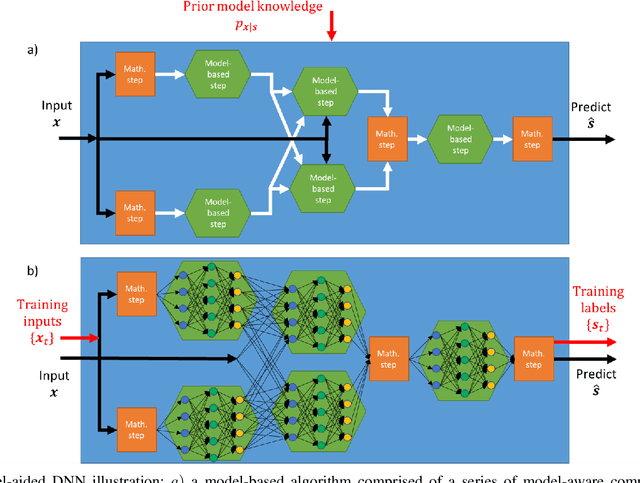
Signal processing, communications, and control have traditionally relied on classical statistical modeling techniques. Such model-based methods utilize mathematical formulations that represent the underlying physics, prior information and additional domain knowledge. Simple classical models are useful but sensitive to inaccuracies and may lead to poor performance when real systems display complex or dynamic behavior. On the other hand, purely data-driven approaches that are model-agnostic are becoming increasingly popular as datasets become abundant and the power of modern deep learning pipelines increases. Deep neural networks (DNNs) use generic architectures which learn to operate from data, and demonstrate excellent performance, especially for supervised problems. However, DNNs typically require massive amounts of data and immense computational resources, limiting their applicability for some signal processing scenarios. We are interested in hybrid techniques that combine principled mathematical models with data-driven systems to benefit from the advantages of both approaches. Such model-based deep learning methods exploit both partial domain knowledge, via mathematical structures designed for specific problems, as well as learning from limited data. In this article we survey the leading approaches for studying and designing model-based deep learning systems. We divide hybrid model-based/data-driven systems into categories based on their inference mechanism. We provide a comprehensive review of the leading approaches for combining model-based algorithms with deep learning in a systematic manner, along with concrete guidelines and detailed signal processing oriented examples from recent literature. Our aim is to facilitate the design and study of future systems on the intersection of signal processing and machine learning that incorporate the advantages of both domains.
SMYRF: Efficient Attention using Asymmetric Clustering
Oct 11, 2020
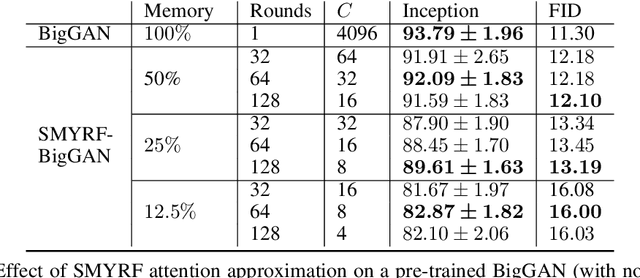


We propose a novel type of balanced clustering algorithm to approximate attention. Attention complexity is reduced from $O(N^2)$ to $O(N \log N)$, where $N$ is the sequence length. Our algorithm, SMYRF, uses Locality Sensitive Hashing (LSH) in a novel way by defining new Asymmetric transformations and an adaptive scheme that produces balanced clusters. The biggest advantage of SMYRF is that it can be used as a drop-in replacement for dense attention layers without any retraining. On the contrary, prior fast attention methods impose constraints (e.g. queries and keys share the same vector representations) and require re-training from scratch. We apply our method to pre-trained state-of-the-art Natural Language Processing and Computer Vision models and we report significant memory and speed benefits. Notably, SMYRF-BERT outperforms (slightly) BERT on GLUE, while using $50\%$ less memory. We also show that SMYRF can be used interchangeably with dense attention before and after training. Finally, we use SMYRF to train GANs with attention in high resolutions. Using a single TPU, we were able to scale attention to 128x128=16k and 256x256=65k tokens on BigGAN on CelebA-HQ.