 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data
Mar 30, 2021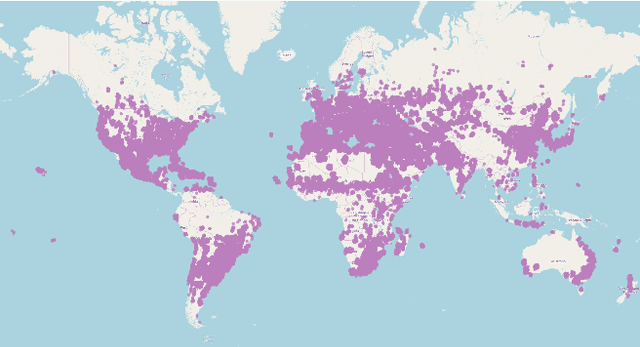
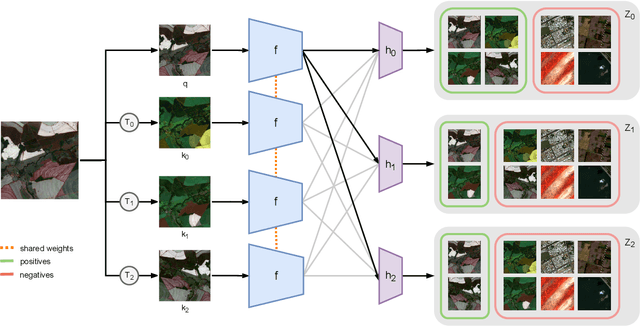

Remote sensing and automatic earth monitoring are key to solve global-scale challenges such as disaster prevention, land use monitoring, or tackling climate change. Although there exist vast amounts of remote sensing data, most of it remains unlabeled and thus inaccessible for supervised learning algorithms. Transfer learning approaches can reduce the data requirements of deep learning algorithms. However, most of these methods are pre-trained on ImageNet and their generalization to remote sensing imagery is not guaranteed due to the domain gap. In this work, we propose Seasonal Contrast (SeCo), an effective pipeline to leverage unlabeled data for in-domain pre-training of re-mote sensing representations. The SeCo pipeline is com-posed of two parts. First, a principled procedure to gather large-scale, unlabeled and uncurated remote sensing datasets containing images from multiple Earth locations at different timestamps. Second, a self-supervised algorithm that takes advantage of time and position invariance to learn transferable representations for re-mote sensing applications. We empirically show that models trained with SeCo achieve better performance than their ImageNet pre-trained counterparts and state-of-the-art self-supervised learning methods on multiple downstream tasks. The datasets and models in SeCo will be made public to facilitate transfer learning and enable rapid progress in re-mote sensing applications.
Beyond Trivial Counterfactual Explanations with Diverse Valuable Explanations
Mar 18, 2021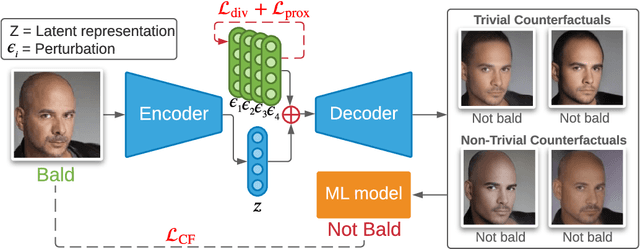
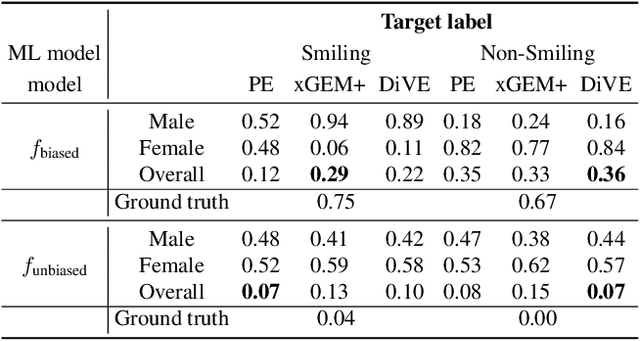

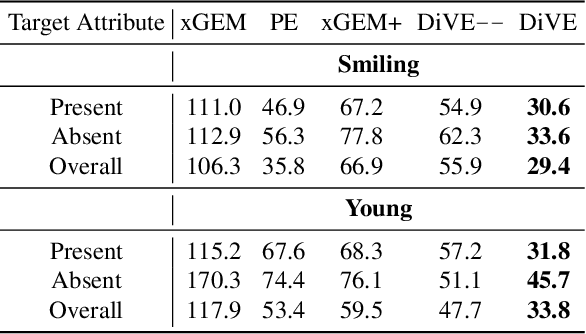
Explainability for machine learning models has gained considerable attention within our research community given the importance of deploying more reliable machine-learning systems. In computer vision applications, generative counterfactual methods indicate how to perturb a model's input to change its prediction, providing details about the model's decision-making. Current counterfactual methods make ambiguous interpretations as they combine multiple biases of the model and the data in a single counterfactual interpretation of the model's decision. Moreover, these methods tend to generate trivial counterfactuals about the model's decision, as they often suggest to exaggerate or remove the presence of the attribute being classified. For the machine learning practitioner, these types of counterfactuals offer little value, since they provide no new information about undesired model or data biases. In this work, we propose a counterfactual method that learns a perturbation in a disentangled latent space that is constrained using a diversity-enforcing loss to uncover multiple valuable explanations about the model's prediction. Further, we introduce a mechanism to prevent the model from producing trivial explanations. Experiments on CelebA and Synbols demonstrate that our model improves the success rate of producing high-quality valuable explanations when compared to previous state-of-the-art methods. We will publish the code.
Counting Cows: Tracking Illegal Cattle Ranching From High-Resolution Satellite Imagery
Nov 14, 2020
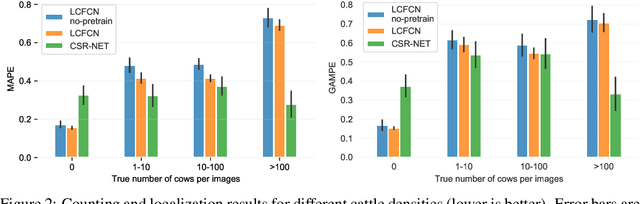

Cattle farming is responsible for 8.8\% of greenhouse gas emissions worldwide. In addition to the methane emitted due to their digestive process, the growing need for grazing areas is an important driver of deforestation. While some regulations are in place for preserving the Amazon against deforestation, these are being flouted in various ways, hence the need to scale and automate the monitoring of cattle ranching activities. Through a partnership with \textit{Global Witness}, we explore the feasibility of tracking and counting cattle at the continental scale from satellite imagery. With a license from Maxar Technologies, we obtained satellite imagery of the Amazon at 40cm resolution, and compiled a dataset of 903 images containing a total of 28498 cattle. Our experiments show promising results and highlight important directions for the next steps on both counting algorithms and the data collection process for solving such challenges. The code is available at \url{https://github.com/IssamLaradji/cownter_strike}.
Synbols: Probing Learning Algorithms with Synthetic Datasets
Sep 14, 2020
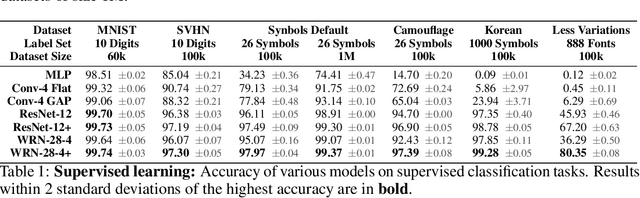
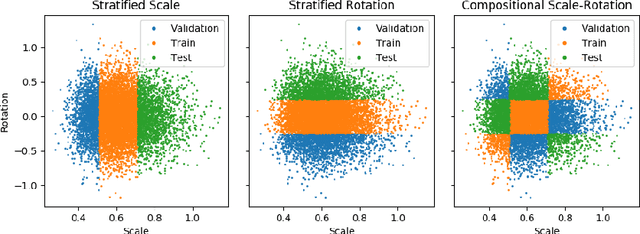
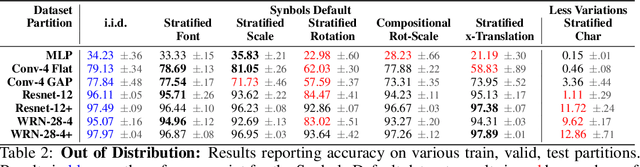
Progress in the field of machine learning has been fueled by the introduction of benchmark datasets pushing the limits of existing algorithms. Enabling the design of datasets to test specific properties and failure modes of learning algorithms is thus a problem of high interest, as it has a direct impact on innovation in the field. In this sense, we introduce Synbols -- Synthetic Symbols -- a tool for rapidly generating new datasets with a rich composition of latent features rendered in low resolution images. Synbols leverages the large amount of symbols available in the Unicode standard and the wide range of artistic font provided by the open font community. Our tool's high-level interface provides a language for rapidly generating new distributions on the latent features, including various types of textures and occlusions. To showcase the versatility of Synbols, we use it to dissect the limitations and flaws in standard learning algorithms in various learning setups including supervised learning, active learning, out of distribution generalization, unsupervised representation learning, and object counting.
Differentiable Causal Discovery from Interventional Data
Jul 03, 2020

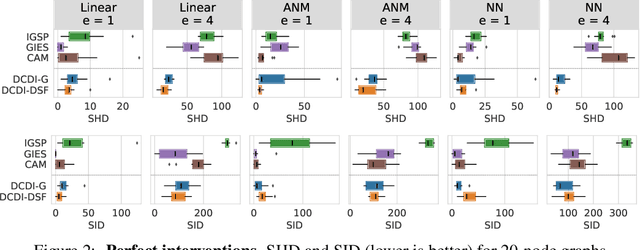

Discovering causal relationships in data is a challenging task that involves solving a combinatorial problem for which the solution is not always identifiable. A new line of work reformulates the combinatorial problem as a continuous constrained optimization one, enabling the use of different powerful optimization techniques. However, methods based on this idea do not yet make use of interventional data, which can significantly alleviate identifiability issues. In this work, we propose a neural network-based method for this task that can leverage interventional data. We illustrate the flexibility of the continuous-constrained framework by taking advantage of expressive neural architectures such as normalizing flows. We show that our approach compares favorably to the state of the art in a variety of settings, including perfect and imperfect interventions for which the targeted nodes may even be unknown.
Bayesian active learning for production, a systematic study and a reusable library
Jun 17, 2020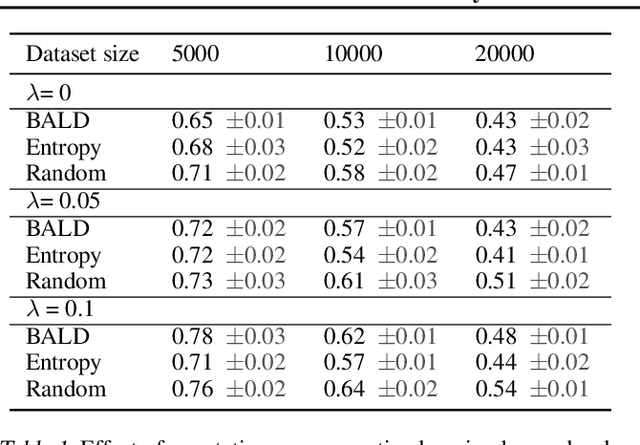
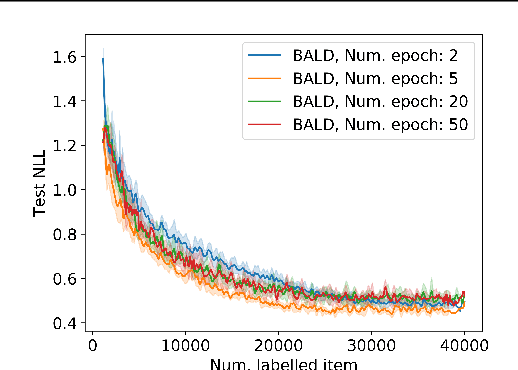
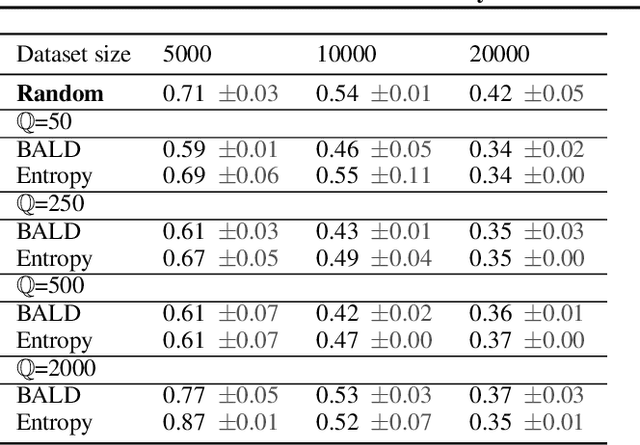
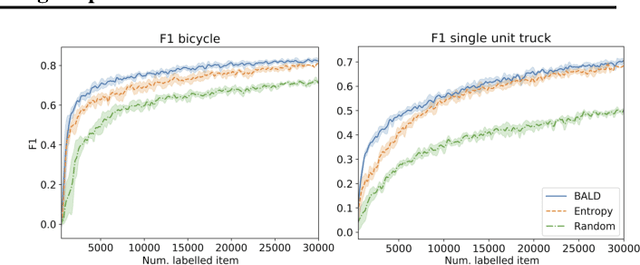
Active learning is able to reduce the amount of labelling effort by using a machine learning model to query the user for specific inputs. While there are many papers on new active learning techniques, these techniques rarely satisfy the constraints of a real-world project. In this paper, we analyse the main drawbacks of current active learning techniques and we present approaches to alleviate them. We do a systematic study on the effects of the most common issues of real-world datasets on the deep active learning process: model convergence, annotation error, and dataset imbalance. We derive two techniques that can speed up the active learning loop such as partial uncertainty sampling and larger query size. Finally, we present our open-source Bayesian active learning library, BaaL.
Embedding Propagation: Smoother Manifold for Few-Shot Classification
Mar 09, 2020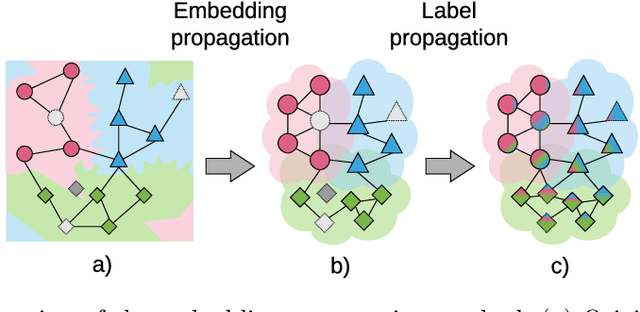
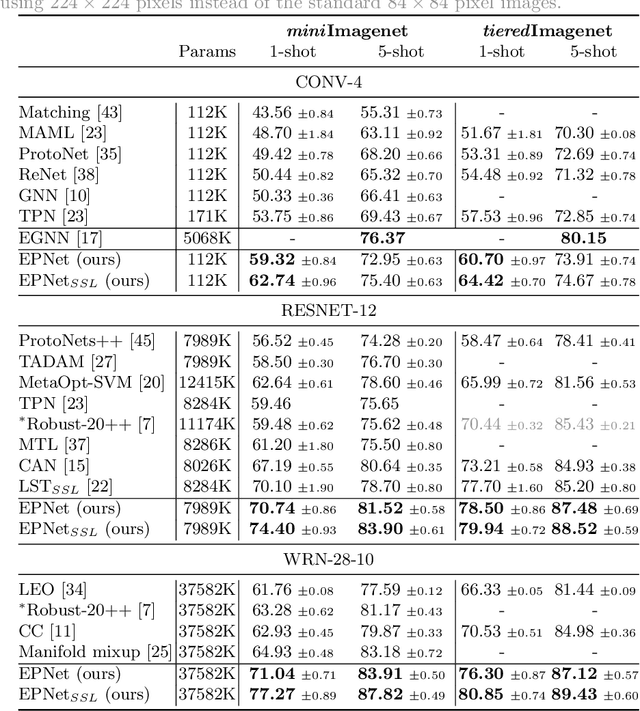
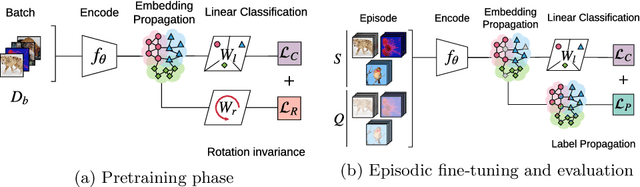
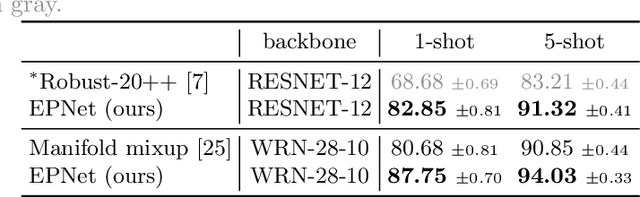
Few-shot classification is challenging because the data distribution of the training set can be widely different to the distribution of the test set as their classes are disjoint. This distribution shift often results in poor generalization. Manifold smoothing has been shown to address the distribution shift problem by extending the decision boundaries and reducing the noise of the class representations. Moreover, manifold smoothness is a key factor for semi-supervised learning and transductive learning algorithms. In this work, we present embedding propagation as an unsupervised non-parametric regularizer for manifold smoothing. Embedding propagation leverages interpolations between the extracted features of a neural network based on a similarity graph. We empirically show that embedding propagation yields a smoother embedding manifold. We also show that incorporating embedding propagation to a transductive classifier leads to new state-of-the-art results in mini-Imagenet, tiered-Imagenet, and CUB. Furthermore, we show that embedding propagation results in additional improvement in performance for semi-supervised learning scenarios.
Quantifying the Carbon Emissions of Machine Learning
Nov 04, 2019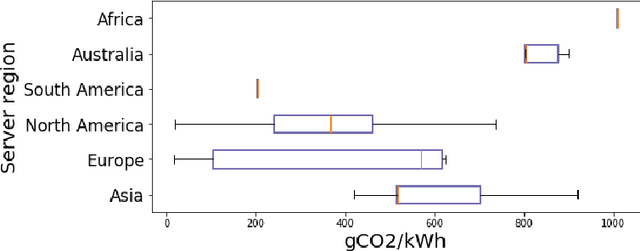
From an environmental standpoint, there are a few crucial aspects of training a neural network that have a major impact on the quantity of carbon that it emits. These factors include: the location of the server used for training and the energy grid that it uses, the length of the training procedure, and even the make and model of hardware on which the training takes place. In order to approximate these emissions, we present our Machine Learning Emissions Calculator, a tool for our community to better understand the environmental impact of training ML models. We accompany this tool with an explanation of the factors cited above, as well as concrete actions that individual practitioners and organizations can take to mitigate their carbon emissions.
Stochastic Neural Network with Kronecker Flow
Jun 10, 2019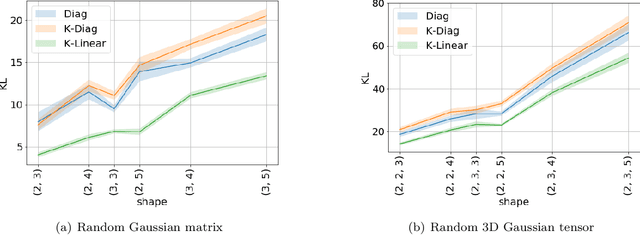



Recent advances in variational inference enable the modelling of highly structured joint distributions, but are limited in their capacity to scale to the high-dimensional setting of stochastic neural networks. This limitation motivates a need for scalable parameterizations of the noise generation process, in a manner that adequately captures the dependencies among the various parameters. In this work, we address this need and present the Kronecker Flow, a generalization of the Kronecker product to invertible mappings designed for stochastic neural networks. We apply our method to variational Bayesian neural networks on predictive tasks, PAC-Bayes generalization bound estimation, and approximate Thompson sampling in contextual bandits. In all setups, our methods prove to be competitive with existing methods and better than the baselines.
Tackling Climate Change with Machine Learning
Jun 10, 2019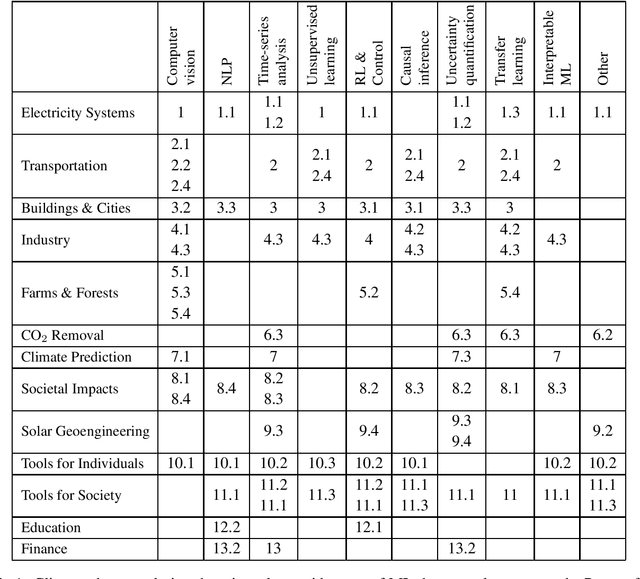
Climate change is one of the greatest challenges facing humanity, and we, as machine learning experts, may wonder how we can help. Here we describe how machine learning can be a powerful tool in reducing greenhouse gas emissions and helping society adapt to a changing climate. From smart grids to disaster management, we identify high impact problems where existing gaps can be filled by machine learning, in collaboration with other fields. Our recommendations encompass exciting research questions as well as promising business opportunities. We call on the machine learning community to join the global effort against climate change.