 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical control for spatio-temporal MEG/EEG source imaging with desparsified multi-task Lasso
Sep 29, 2020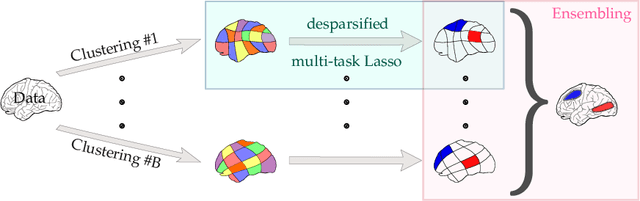
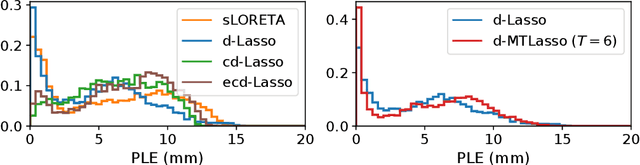
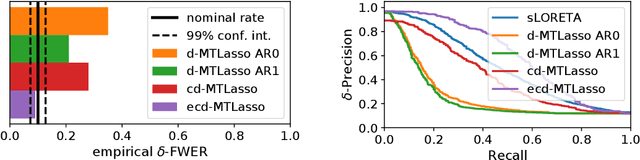
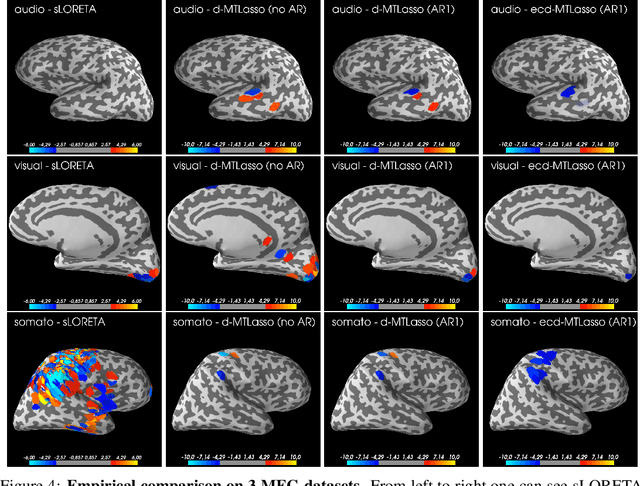
Detecting where and when brain regions activate in a cognitive task or in a given clinical condition is the promise of non-invasive techniques like magnetoencephalography (MEG) or electroencephalography (EEG). This problem, referred to as source localization, or source imaging, poses however a high-dimensional statistical inference challenge. While sparsity promoting regularizations have been proposed to address the regression problem, it remains unclear how to ensure statistical control of false detections. Moreover, M/EEG source imaging requires to work with spatio-temporal data and autocorrelated noise. To deal with this, we adapt the desparsified Lasso estimator -- an estimator tailored for high dimensional linear model that asymptotically follows a Gaussian distribution under sparsity and moderate feature correlation assumptions -- to temporal data corrupted with autocorrelated noise. We call it the desparsified multi-task Lasso (d-MTLasso). We combine d-MTLasso with spatially constrained clustering to reduce data dimension and with ensembling to mitigate the arbitrary choice of clustering; the resulting estimator is called ensemble of clustered desparsified multi-task Lasso (ecd-MTLasso). With respect to the current procedures, the two advantages of ecd-MTLasso are that i)it offers statistical guarantees and ii)it allows to trade spatial specificity for sensitivity, leading to a powerful adaptive method. Extensive simulations on realistic head geometries, as well as empirical results on various MEG datasets, demonstrate the high recovery performance of ecd-MTLasso and its primary practical benefit: offer a statistically principled way to threshold MEG/EEG source maps.
Uncovering the structure of clinical EEG signals with self-supervised learning
Jul 31, 2020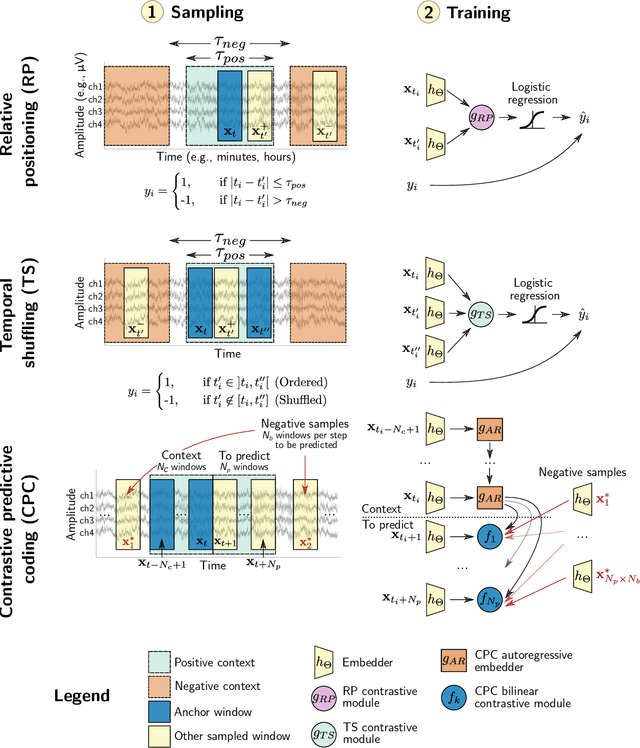

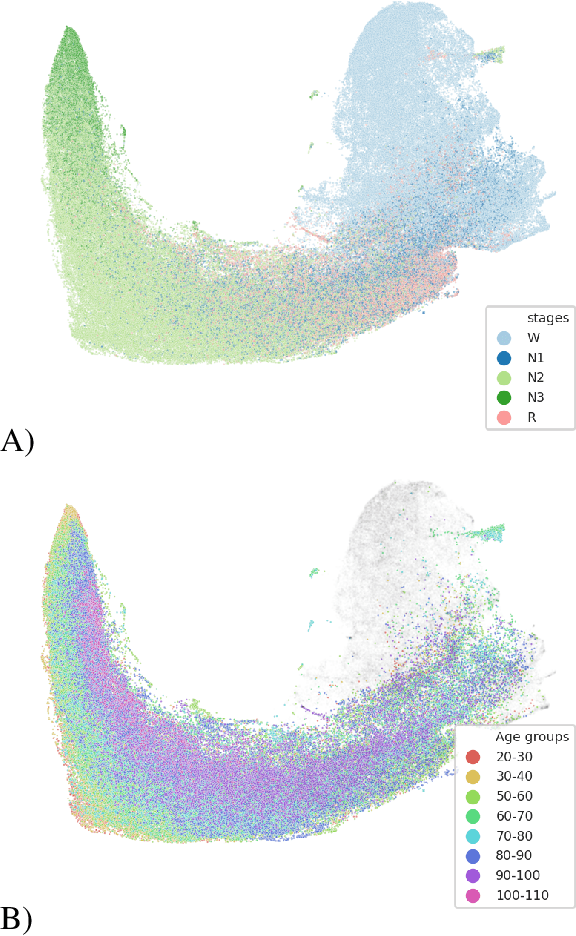
Objective. Supervised learning paradigms are often limited by the amount of labeled data that is available. This phenomenon is particularly problematic in clinically-relevant data, such as electroencephalography (EEG), where labeling can be costly in terms of specialized expertise and human processing time. Consequently, deep learning architectures designed to learn on EEG data have yielded relatively shallow models and performances at best similar to those of traditional feature-based approaches. However, in most situations, unlabeled data is available in abundance. By extracting information from this unlabeled data, it might be possible to reach competitive performance with deep neural networks despite limited access to labels. Approach. We investigated self-supervised learning (SSL), a promising technique for discovering structure in unlabeled data, to learn representations of EEG signals. Specifically, we explored two tasks based on temporal context prediction as well as contrastive predictive coding on two clinically-relevant problems: EEG-based sleep staging and pathology detection. We conducted experiments on two large public datasets with thousands of recordings and performed baseline comparisons with purely supervised and hand-engineered approaches. Main results. Linear classifiers trained on SSL-learned features consistently outperformed purely supervised deep neural networks in low-labeled data regimes while reaching competitive performance when all labels were available. Additionally, the embeddings learned with each method revealed clear latent structures related to physiological and clinical phenomena, such as age effects. Significance. We demonstrate the benefit of self-supervised learning approaches on EEG data. Our results suggest that SSL may pave the way to a wider use of deep learning models on EEG data.
Modeling Shared Responses in Neuroimaging Studies through MultiView ICA
Jun 12, 2020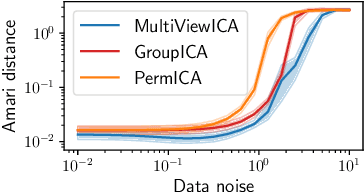
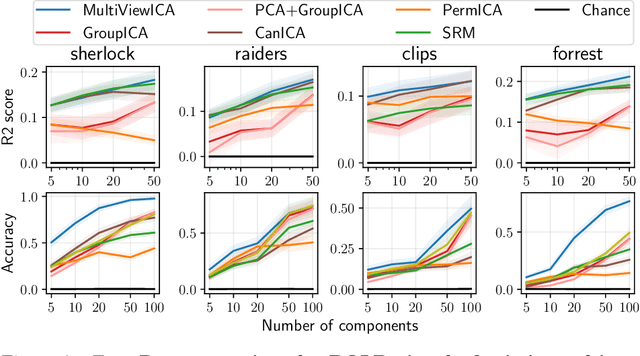
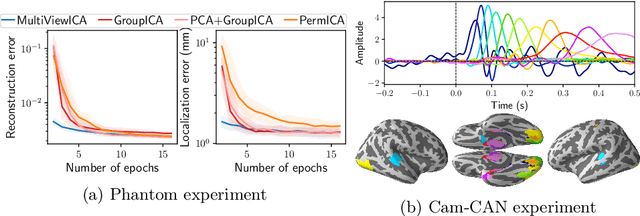
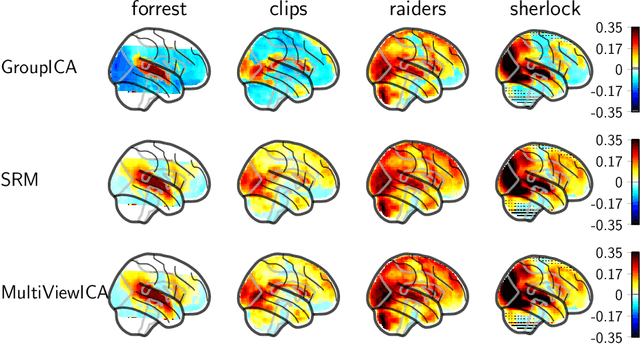
Group studies involving large cohorts of subjects are important to draw general conclusions about brain functional organization. However, the aggregation of data coming from multiple subjects is challenging, since it requires accounting for large variability in anatomy, functional topography and stimulus response across individuals. Data modeling is especially hard for ecologically relevant conditions such as movie watching, where the experimental setup does not imply well-defined cognitive operations. We propose a novel MultiView Independent Component Analysis (ICA) model for group studies, where data from each subject are modeled as a linear combination of shared independent sources plus noise. Contrary to most group-ICA procedures, the likelihood of the model is available in closed form. We develop an alternate quasi-Newton method for maximizing the likelihood, which is robust and converges quickly. We demonstrate the usefulness of our approach first on fMRI data, where our model demonstrates improved sensitivity in identifying common sources among subjects. Moreover, the sources recovered by our model exhibit lower between-session variability than other methods.On magnetoencephalography (MEG) data, our method yields more accurate source localization on phantom data. Applied on 200 subjects from the Cam-CAN dataset it reveals a clear sequence of evoked activity in sensor and source space. The code is freely available at https://github.com/hugorichard/multiviewica.
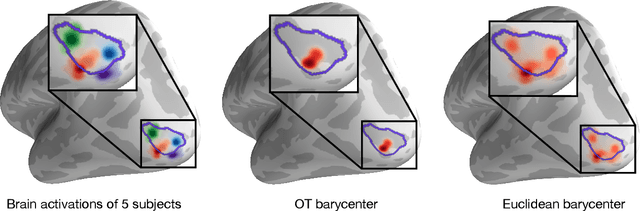
Debiased Sinkhorn barycenters
Jun 03, 2020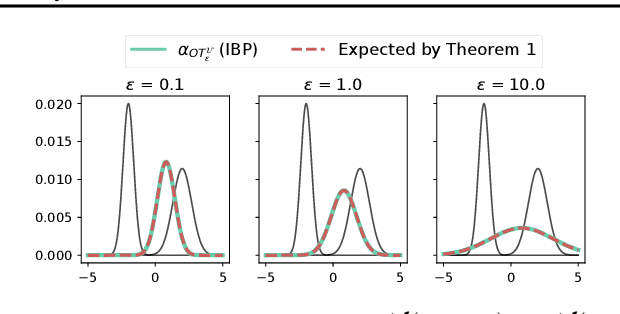
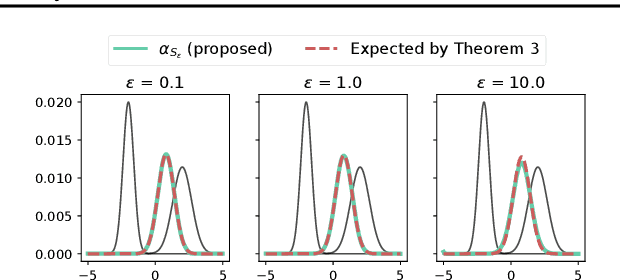
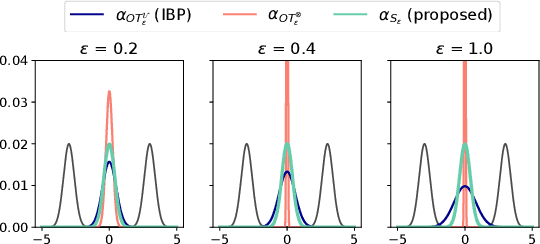
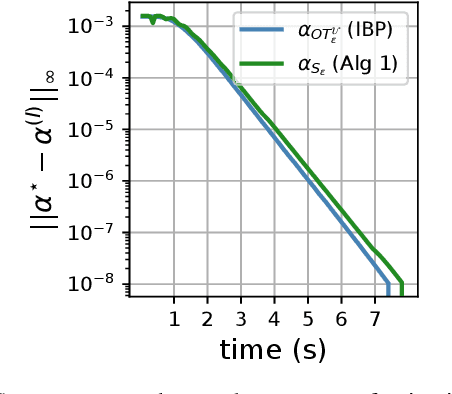
Entropy regularization in optimal transport (OT) has been the driver of many recent interests for Wasserstein metrics and barycenters in machine learning. It allows to keep the appealing geometrical properties of the unregularized Wasserstein distance while having a significantly lower complexity thanks to Sinkhorn's algorithm. However, entropy brings some inherent smoothing bias, resulting for example in blurred barycenters. This side effect has prompted an increasing temptation in the community to settle for a slower algorithm such as log-domain stabilized Sinkhorn which breaks the parallel structure that can be leveraged on GPUs, or even go back to unregularized OT. Here we show how this bias is tightly linked to the reference measure that defines the entropy regularizer and propose debiased Wasserstein barycenters that preserve the best of both worlds: fast Sinkhorn-like iterations without entropy smoothing. Theoretically, we prove that the entropic OT barycenter of univariate Gaussians is a Gaussian and quantify its variance bias. This result is obtained by extending the differentiability and convexity of entropic OT to sub-Gaussian measures with unbounded supports. Empirically, we illustrate the reduced blurring and the computational advantage on various applications.
Implicit differentiation of Lasso-type models for hyperparameter optimization
Feb 20, 2020
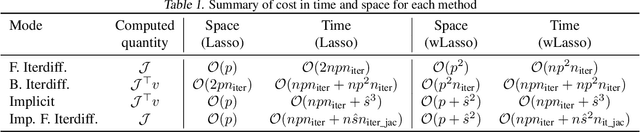
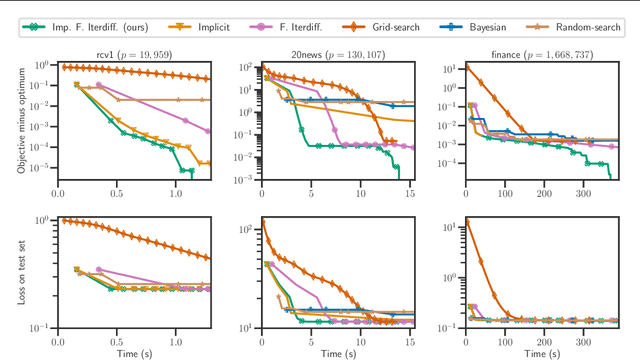
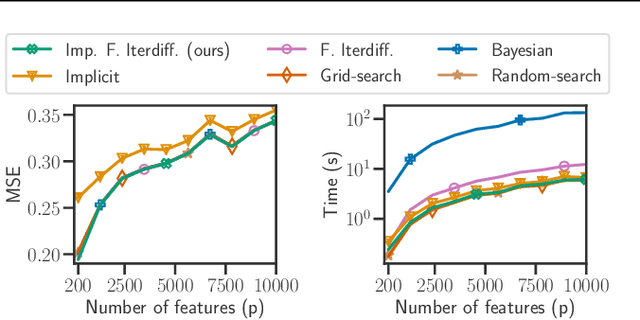
Setting regularization parameters for Lasso-type estimators is notoriously difficult, though crucial in practice. The most popular hyperparameter optimization approach is grid-search using held-out validation data. Grid-search however requires to choose a predefined grid for each parameter, which scales exponentially in the number of parameters. Another approach is to cast hyperparameter optimization as a bi-level optimization problem, one can solve by gradient descent. The key challenge for these methods is the estimation of the gradient with respect to the hyperparameters. Computing this gradient via forward or backward automatic differentiation is possible yet usually suffers from high memory consumption. Alternatively implicit differentiation typically involves solving a linear system which can be prohibitive and numerically unstable in high dimension. In addition, implicit differentiation usually assumes smooth loss functions, which is not the case for Lasso-type problems. This work introduces an efficient implicit differentiation algorithm, without matrix inversion, tailored for Lasso-type problems. Our approach scales to high-dimensional data by leveraging the sparsity of the solutions. Experiments demonstrate that the proposed method outperforms a large number of standard methods to optimize the error on held-out data, or the Stein Unbiased Risk Estimator (SURE).
Support recovery and sup-norm convergence rates for sparse pivotal estimation
Jan 15, 2020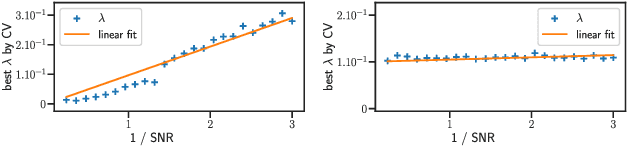

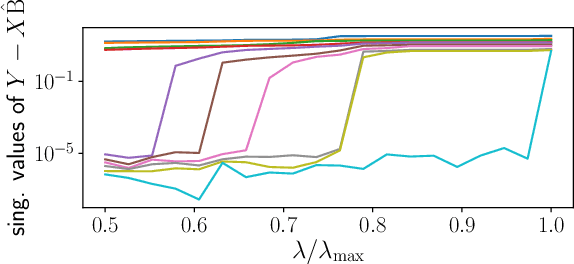
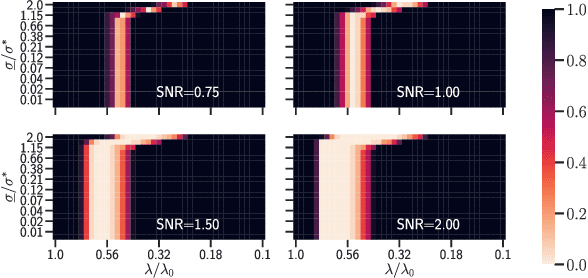
In high dimensional sparse regression, pivotal estimators are estimators for which the optimal regularization parameter is independent of the noise level. The canonical pivotal estimator is the square-root Lasso, formulated along with its derivatives as a ``non-smooth + non-smooth'' optimization problem. Modern techniques to solve these include smoothing the datafitting term, to benefit from fast efficient proximal algorithms. In this work we show minimax sup-norm convergence rates for non smoothed and smoothed, single task and multitask square-root Lasso-type estimators. Thanks to our theoretical analysis, we provide some guidelines on how to set the smoothing hyperparameter, and illustrate on synthetic data the interest of such guidelines.
Self-supervised representation learning from electroencephalography signals
Nov 13, 2019
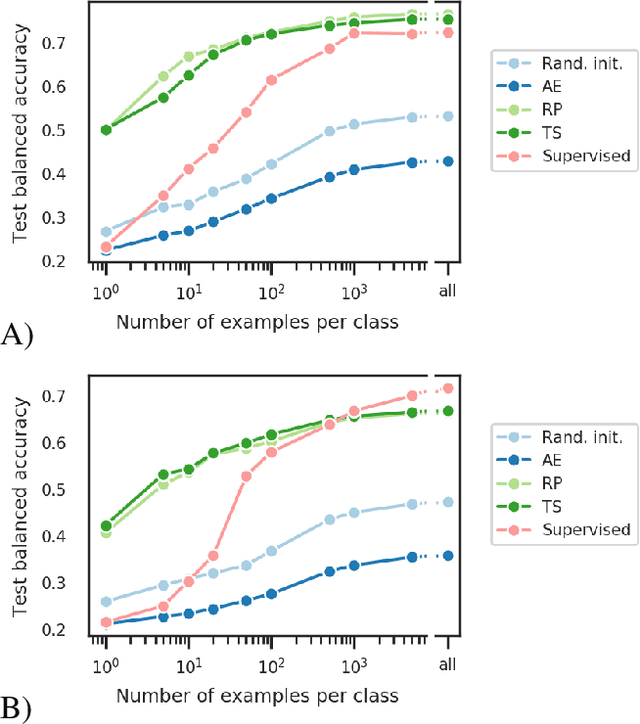
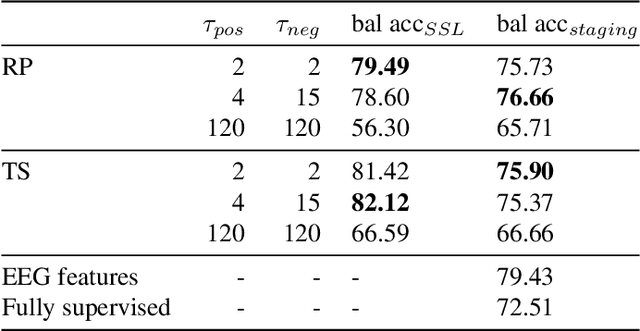
The supervised learning paradigm is limited by the cost - and sometimes the impracticality - of data collection and labeling in multiple domains. Self-supervised learning, a paradigm which exploits the structure of unlabeled data to create learning problems that can be solved with standard supervised approaches, has shown great promise as a pretraining or feature learning approach in fields like computer vision and time series processing. In this work, we present self-supervision strategies that can be used to learn informative representations from multivariate time series. One successful approach relies on predicting whether time windows are sampled from the same temporal context or not. As demonstrated on a clinically relevant task (sleep scoring) and with two electroencephalography datasets, our approach outperforms a purely supervised approach in low data regimes, while capturing important physiological information without any access to labels.
Spatio-Temporal Alignments: Optimal transport through space and time
Nov 10, 2019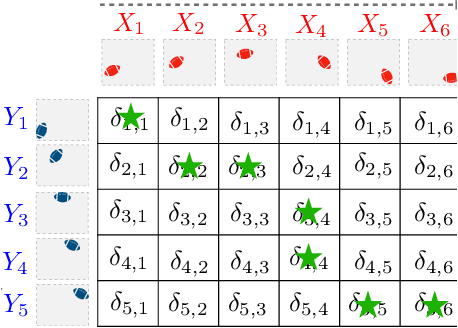
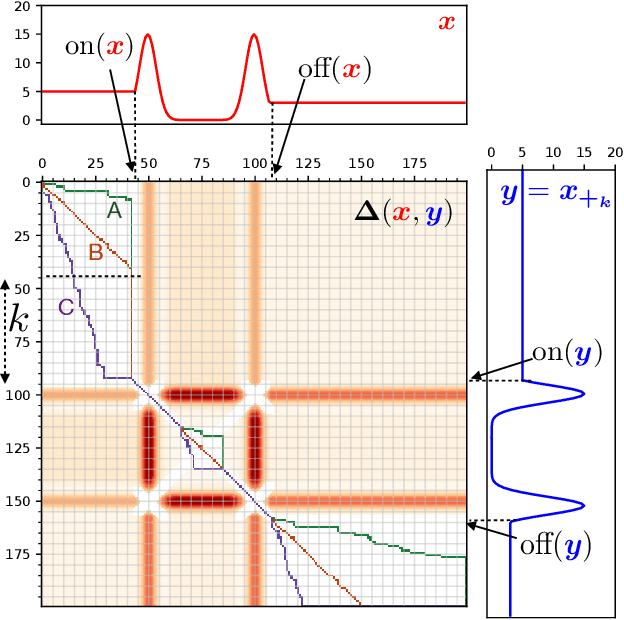
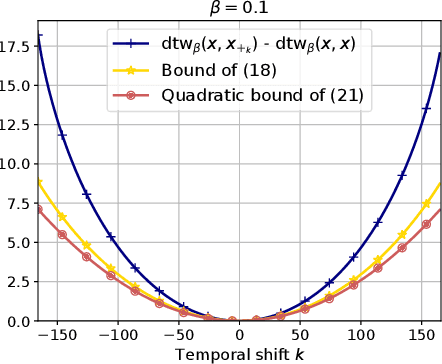
Comparing data defined over space and time is notoriously hard, because it involves quantifying both spatial and temporal variability, while at the same time taking into account the chronological structure of data. Dynamic Time Warping (DTW) computes an optimal alignment between time series in agreement with the chronological order, but is inherently blind to spatial shifts. In this paper, we propose Spatio-Temporal Alignments (STA), a new differentiable formulation of DTW, in which spatial differences between time samples are accounted for using regularized optimal transport (OT). Our temporal alignments are handled through a smooth variant of DTW called soft-DTW, for which we prove a new property: soft-DTW increases quadratically with time shifts. The cost matrix within soft-DTW that we use are computed using unbalanced OT, to handle the case in which observations are not normalized probabilities. Experiments on handwritten letters and brain imaging data confirm our theoretical findings and illustrate the effectiveness of STA as a dissimilarity for spatio-temporal data.
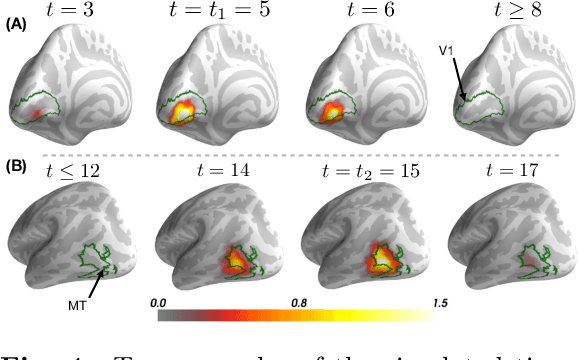
Multi-subject MEG/EEG source imaging with sparse multi-task regression
Oct 14, 2019
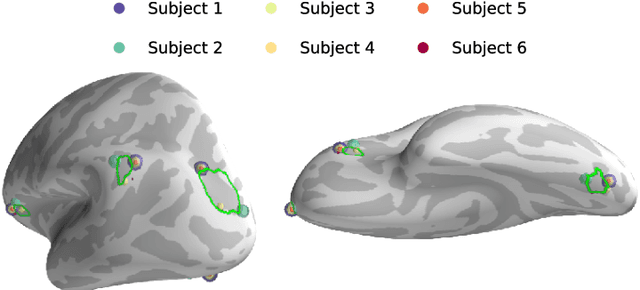
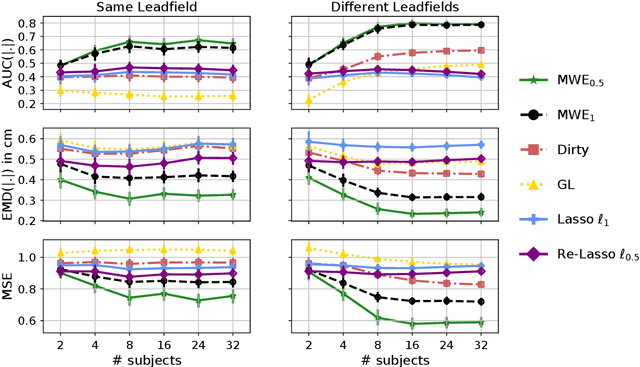
Magnetoencephalography and electroencephalography (M/EEG) are non-invasive modalities that measure the weak electromagnetic fields generated by neural activity. Estimating the location and magnitude of the current sources that generated these electromagnetic fields is a challenging ill-posed regression problem known as \emph{source imaging}. When considering a group study, a common approach consists in carrying out the regression tasks independently for each subject. An alternative is to jointly localize sources for all subjects taken together, while enforcing some similarity between them. By pooling all measurements in a single multi-task regression, one makes the problem better posed, offering the ability to identify more sources and with greater precision. The Minimum Wasserstein Estimates (MWE) promotes focal activations that do not perfectly overlap for all subjects, thanks to a regularizer based on Optimal Transport (OT) metrics. MWE promotes spatial proximity on the cortical mantel while coping with the varying noise levels across subjects. On realistic simulations, MWE decreases the localization error by up to 4 mm per source compared to individual solutions. Experiments on the Cam-CAN dataset show a considerable improvement in spatial specificity in population imaging. Our analysis of a multimodal dataset shows how multi-subject source localization closes the gap between MEG and fMRI for brain mapping.
Dual Extrapolation for Sparse Generalized Linear Models
Jul 12, 2019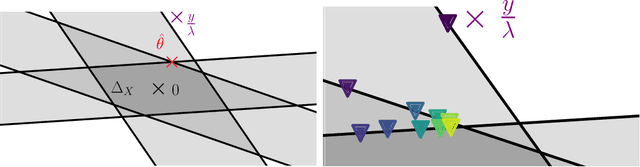

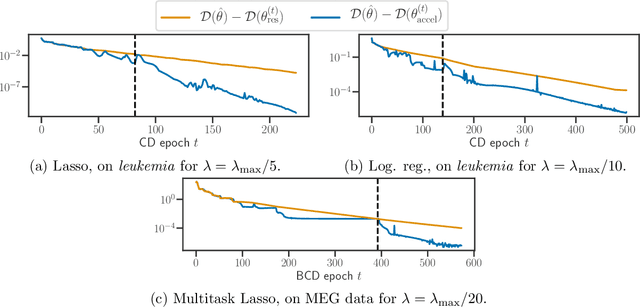
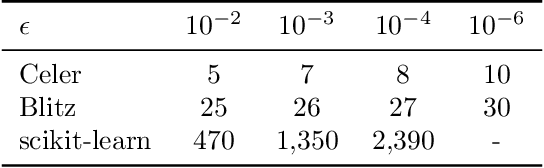
Generalized Linear Models (GLM) form a wide class of regression and classification models, where prediction is a function of a linear combination of the input variables. For statistical inference in high dimension, sparsity inducing regularizations have proven to be useful while offering statistical guarantees. However, solving the resulting optimization problems can be challenging: even for popular iterative algorithms such as coordinate descent, one needs to loop over a large number of variables. To mitigate this, techniques known as screening rules and working sets diminish the size of the optimization problem at hand, either by progressively removing variables, or by solving a growing sequence of smaller problems. For both techniques, significant variables are identified thanks to convex duality arguments. In this paper, we show that the dual iterates of a GLM exhibit a Vector AutoRegressive (VAR) behavior after sign identification, when the primal problem is solved with proximal gradient descent or cyclic coordinate descent. Exploiting this regularity, one can construct dual points that offer tighter certificates of optimality, enhancing the performance of screening rules and helping to design competitive working set algorithms.