 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Rank: Visual Attribution by Learning Importance Ranking
Apr 07, 2026Interpreting the decisions of complex computer vision models is crucial to establish trust and accountability, especially in safety-critical domains. An established approach to interpretability is generating visual attribution maps that highlight regions of the input most relevant to the model's prediction. However, existing methods face a three-way trade-off. Propagation-based approaches are efficient, but they can be biased and architecture-specific. Meanwhile, perturbation-based methods are causally grounded, yet they are expensive and for vision transformers often yield coarse, patch-level explanations. Learning-based explainers are fast but usually optimize surrogate objectives or distill from heuristic teachers. We propose a learning scheme that instead optimizes deletion and insertion metrics directly. Since these metrics depend on non-differentiable sorting and ranking, we frame them as permutation learning and replace the hard sorting with a differentiable relaxation using Gumbel-Sinkhorn. This enables end-to-end training through attribution-guided perturbations of the target model. During inference, our method produces dense, pixel-level attributions in a single forward pass with optional, few-step gradient refinement. Our experiments demonstrate consistent quantitative improvements and sharper, boundary-aligned explanations, particularly for transformer-based vision models.
SHARP: Short-Window Streaming for Accurate and Robust Prediction in Motion Forecasting
Mar 30, 2026In dynamic traffic environments, motion forecasting models must be able to accurately estimate future trajectories continuously. Streaming-based methods are a promising solution, but despite recent advances, their performance often degrades when exposed to heterogeneous observation lengths. To address this, we propose a novel streaming-based motion forecasting framework that explicitly focuses on evolving scenes. Our method incrementally processes incoming observation windows and leverages an instance-aware context streaming to maintain and update latent agent representations across inference steps. A dual training objective further enables consistent forecasting accuracy across diverse observation horizons. Extensive experiments on Argoverse 2, nuScenes, and Argoverse 1 demonstrate the robustness of our approach under evolving scene conditions and also on the single-agent benchmarks. Our model achieves state-of-the-art performance in streaming inference on the Argoverse 2 multi-agent benchmark, while maintaining minimal latency, highlighting its suitability for real-world deployment.
ASCENT: Transformer-Based Aircraft Trajectory Prediction in Non-Towered Terminal Airspace
Mar 17, 2026Accurate trajectory prediction can improve General Aviation safety in non-towered terminal airspace, where high traffic density increases accident risk. We present ASCENT, a lightweight transformer-based model for multi-modal 3D aircraft trajectory forecasting, which integrates domain-aware 3D coordinate normalization and parameterized predictions. ASCENT employs a transformer-based motion encoder and a query-based decoder, enabling the generation of diverse maneuver hypotheses with low latency. Experiments on the TrajAir and TartanAviation datasets demonstrate that our model outperforms prior baselines, as the encoder effectively captures motion dynamics and the decoder aligns with structured aircraft traffic patterns. Furthermore, ablation studies confirm the contributions of the decoder design, coordinate-frame modeling, and parameterized outputs. These results establish ASCENT as an effective approach for real-time aircraft trajectory prediction in non-towered terminal airspace.
Streaming Real-Time Trajectory Prediction Using Endpoint-Aware Modeling
Mar 02, 2026Future trajectories of neighboring traffic agents have a significant influence on the path planning and decision-making of autonomous vehicles. While trajectory forecasting is a well-studied field, research mainly focuses on snapshot-based prediction, where each scenario is treated independently of its global temporal context. However, real-world autonomous driving systems need to operate in a continuous setting, requiring real-time processing of data streams with low latency and consistent predictions over successive timesteps. We leverage this continuous setting to propose a lightweight yet highly accurate streaming-based trajectory forecasting approach. We integrate valuable information from previous predictions with a novel endpoint-aware modeling scheme. Our temporal context propagation uses the trajectory endpoints of the previous forecasts as anchors to extract targeted scenario context encodings. Our approach efficiently guides its scene encoder to extract highly relevant context information without needing refinement iterations or segment-wise decoding. Our experiments highlight that our approach effectively relays information across consecutive timesteps. Unlike methods using multi-stage refinement processing, our approach significantly reduces inference latency, making it well-suited for real-world deployment. We achieve state-of-the-art streaming trajectory prediction results on the Argoverse~2 multi-agent and single-agent benchmarks, while requiring substantially fewer resources.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Efficient Motion Prediction: A Lightweight & Accurate Trajectory Prediction Model With Fast Training and Inference Speed
Sep 25, 2024



For efficient and safe autonomous driving, it is essential that autonomous vehicles can predict the motion of other traffic agents. While highly accurate, current motion prediction models often impose significant challenges in terms of training resource requirements and deployment on embedded hardware. We propose a new efficient motion prediction model, which achieves highly competitive benchmark results while training only a few hours on a single GPU. Due to our lightweight architectural choices and the focus on reducing the required training resources, our model can easily be applied to custom datasets. Furthermore, its low inference latency makes it particularly suitable for deployment in autonomous applications with limited computing resources.
Design and Development of a Web-based Tool for Inpainting of Dissected Aortae in Angiography Images
May 06, 2020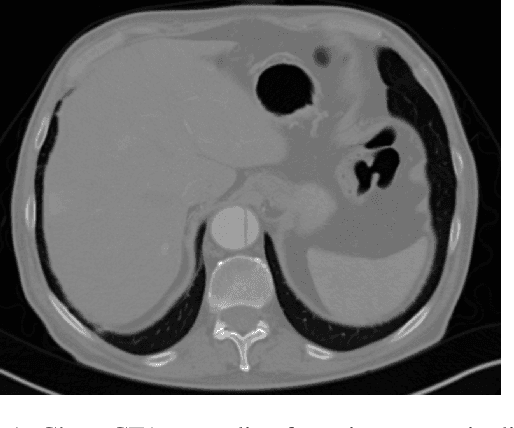
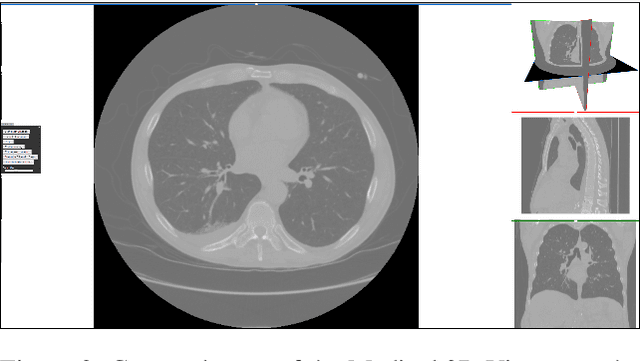

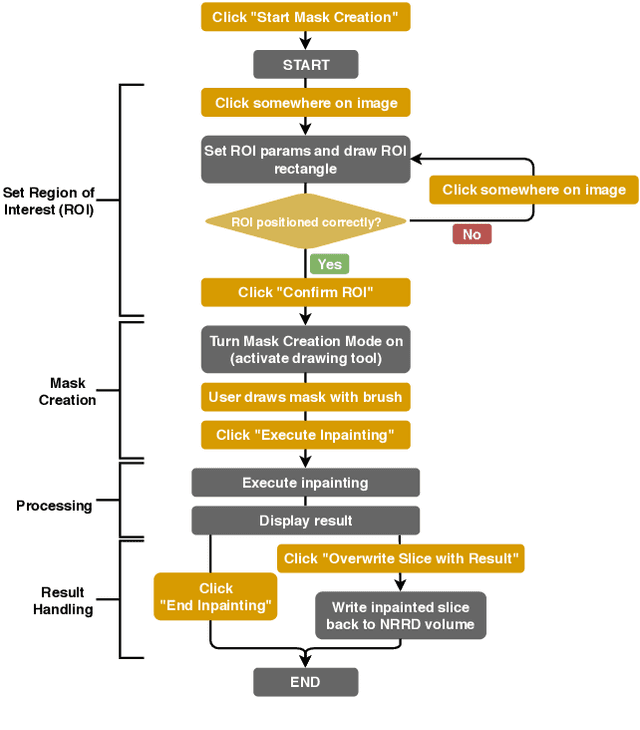
Medical imaging is an important tool for the diagnosis and the evaluation of an aortic dissection (AD); a serious condition of the aorta, which could lead to a life-threatening aortic rupture. AD patients need life-long medical monitoring of the aortic enlargement and of the disease progression, subsequent to the diagnosis of the aortic dissection. Since there is a lack of 'healthy-dissected' image pairs from medical studies, the application of inpainting techniques offers an alternative source for generating them by doing a virtual regression from dissected aortae to healthy aortae; an indirect way to study the origin of the disease. The proposed inpainting tool combines a neural network, which was trained on the task of inpainting aortic dissections, with an easy-to-use user interface. To achieve this goal, the inpainting tool has been integrated within the 3D medical image viewer of StudierFenster (www.studierfenster.at). By designing the tool as a web application, we simplify the usage of the neural network and reduce the initial learning curve.
* 9 figures, 14 references