 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
Mar 30, 2023



There has been a recent explosion of computer vision models which perform many tasks and are composed of an image encoder (usually a ViT) and an autoregressive decoder (usually a Transformer). However, most of this work simply presents one system and its results, leaving many questions regarding design decisions and trade-offs of such systems unanswered. In this work, we aim to provide such answers. We take a close look at autoregressive decoders for multi-task learning in multimodal computer vision, including classification, captioning, visual question answering, and optical character recognition. Through extensive systematic experiments, we study the effects of task and data mixture, training and regularization hyperparameters, conditioning type and specificity, modality combination, and more. Importantly, we compare these to well-tuned single-task baselines to highlight the cost incurred by multi-tasking. A key finding is that a small decoder learned on top of a frozen pretrained encoder works surprisingly well. We call this setup locked-image tuning with decoder (LiT-decoder). It can be seen as teaching a decoder to interact with a pretrained vision model via natural language.
Tuning computer vision models with task rewards
Feb 16, 2023



Misalignment between model predictions and intended usage can be detrimental for the deployment of computer vision models. The issue is exacerbated when the task involves complex structured outputs, as it becomes harder to design procedures which address this misalignment. In natural language processing, this is often addressed using reinforcement learning techniques that align models with a task reward. We adopt this approach and show its surprising effectiveness across multiple computer vision tasks, such as object detection, panoptic segmentation, colorization and image captioning. We believe this approach has the potential to be widely useful for better aligning models with a diverse range of computer vision tasks.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
FlexiViT: One Model for All Patch Sizes
Dec 15, 2022



Vision Transformers convert images to sequences by slicing them into patches. The size of these patches controls a speed/accuracy tradeoff, with smaller patches leading to higher accuracy at greater computational cost, but changing the patch size typically requires retraining the model. In this paper, we demonstrate that simply randomizing the patch size at training time leads to a single set of weights that performs well across a wide range of patch sizes, making it possible to tailor the model to different compute budgets at deployment time. We extensively evaluate the resulting model, which we call FlexiViT, on a wide range of tasks, including classification, image-text retrieval, open-world detection, panoptic segmentation, and semantic segmentation, concluding that it usually matches, and sometimes outperforms, standard ViT models trained at a single patch size in an otherwise identical setup. Hence, FlexiViT training is a simple drop-in improvement for ViT that makes it easy to add compute-adaptive capabilities to most models relying on a ViT backbone architecture. Code and pre-trained models are available at https://github.com/google-research/big_vision
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022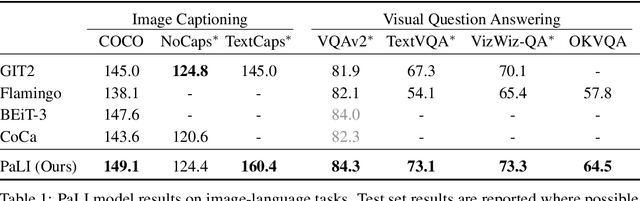

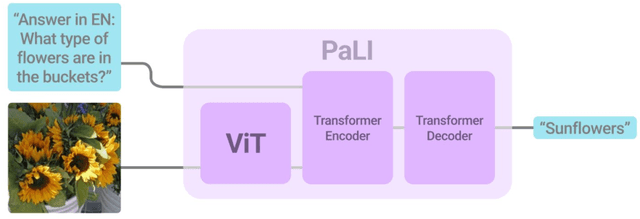

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
May 27, 2022

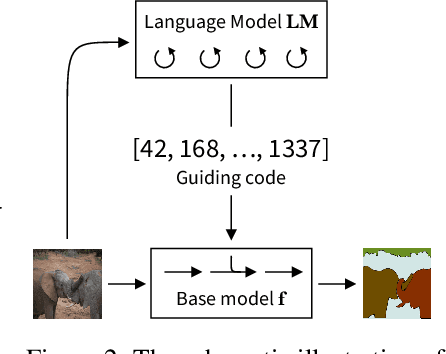

We introduce UViM, a unified approach capable of modeling a wide range of computer vision tasks. In contrast to previous models, UViM has the same functional form for all tasks; it requires no task-specific modifications which require extensive human expertise. The approach involves two components: (I) a base model (feed-forward) which is trained to directly predict raw vision outputs, guided by a learned discrete code and (II) a language model (autoregressive) that is trained to generate the guiding code. These components complement each other: the language model is well-suited to modeling structured interdependent data, while the base model is efficient at dealing with high-dimensional outputs. We demonstrate the effectiveness of UViM on three diverse and challenging vision tasks: panoptic segmentation, depth prediction and image colorization, where we achieve competitive and near state-of-the-art results. Our experimental results suggest that UViM is a promising candidate for a unified modeling approach in computer vision.
Better plain ViT baselines for ImageNet-1k
May 03, 2022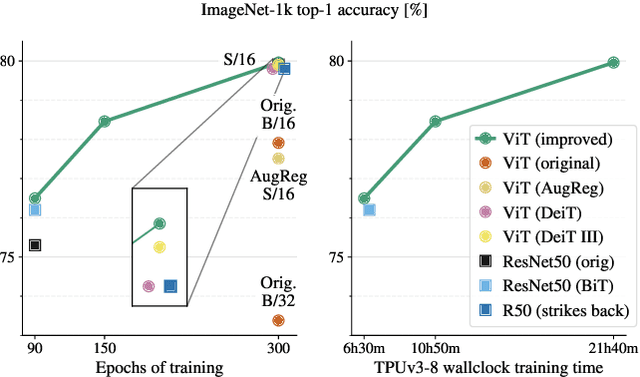
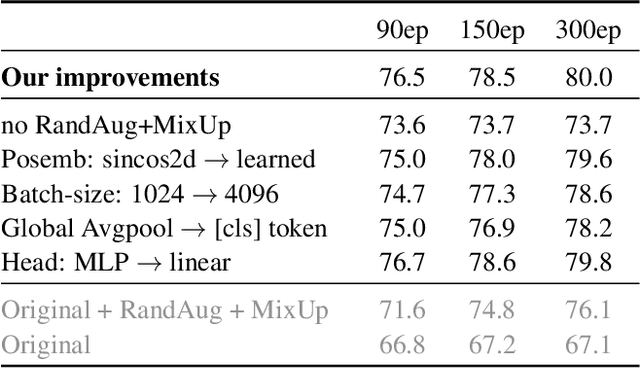
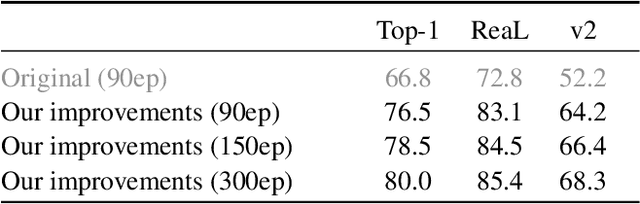
It is commonly accepted that the Vision Transformer model requires sophisticated regularization techniques to excel at ImageNet-1k scale data. Surprisingly, we find this is not the case and standard data augmentation is sufficient. This note presents a few minor modifications to the original Vision Transformer (ViT) vanilla training setting that dramatically improve the performance of plain ViT models. Notably, 90 epochs of training surpass 76% top-1 accuracy in under seven hours on a TPUv3-8, similar to the classic ResNet50 baseline, and 300 epochs of training reach 80% in less than one day.
LiT: Zero-Shot Transfer with Locked-image Text Tuning
Nov 15, 2021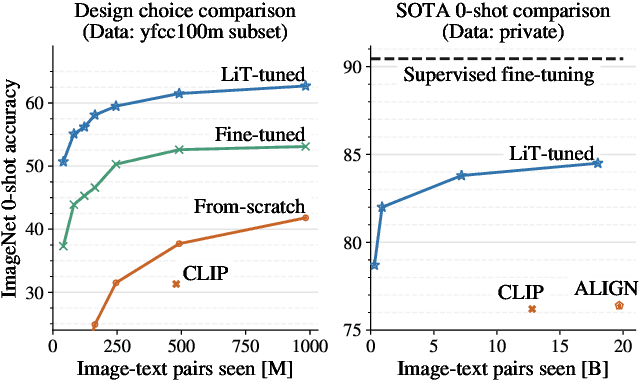
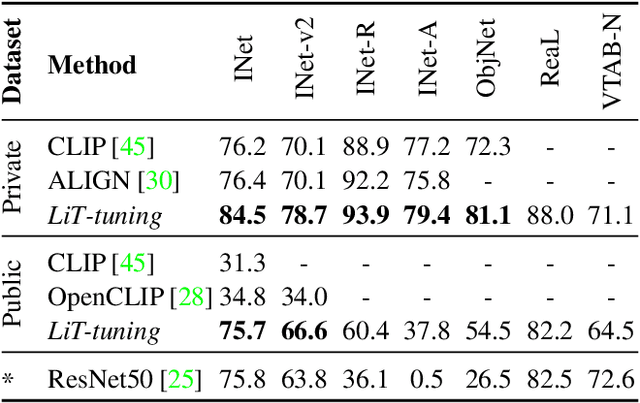
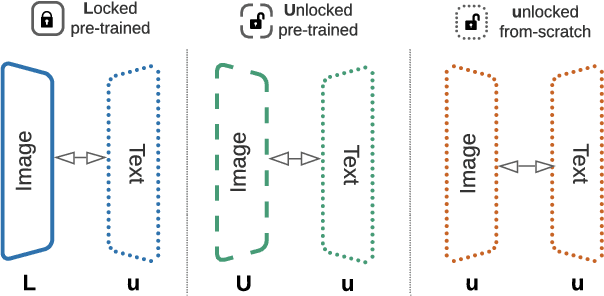

This paper presents contrastive-tuning, a simple method employing contrastive training to align image and text models while still taking advantage of their pre-training. In our empirical study we find that locked pre-trained image models with unlocked text models work best. We call this instance of contrastive-tuning "Locked-image Text tuning" (LiT-tuning), which just teaches a text model to read out good representations from a pre-trained image model for new tasks. A LiT-tuned model gains the capability of zero-shot transfer to new vision tasks, such as image classification or retrieval. The proposed LiT-tuning is widely applicable; it works reliably with multiple pre-training methods (supervised and unsupervised) and across diverse architectures (ResNet, Vision Transformers and MLP-Mixer) using three different image-text datasets. With the transformer-based pre-trained ViT-g/14 model, the LiT-tuned model achieves 84.5% zero-shot transfer accuracy on the ImageNet test set, and 81.1% on the challenging out-of-distribution ObjectNet test set.
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Jun 18, 2021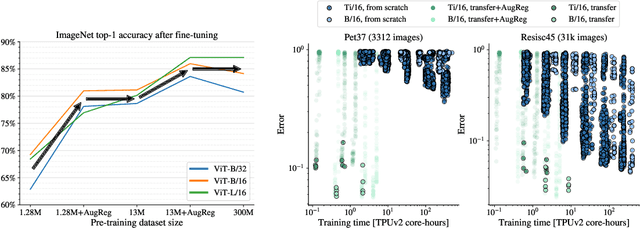
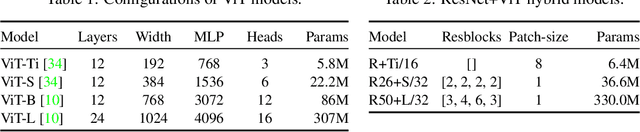
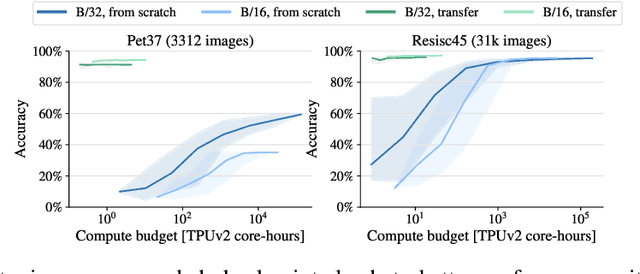
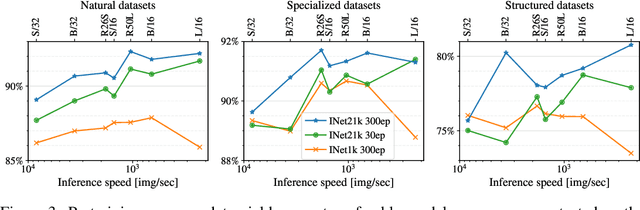
Vision Transformers (ViT) have been shown to attain highly competitive performance for a wide range of vision applications, such as image classification, object detection and semantic image segmentation. In comparison to convolutional neural networks, the Vision Transformer's weaker inductive bias is generally found to cause an increased reliance on model regularization or data augmentation (``AugReg'' for short) when training on smaller training datasets. We conduct a systematic empirical study in order to better understand the interplay between the amount of training data, AugReg, model size and compute budget. As one result of this study we find that the combination of increased compute and AugReg can yield models with the same performance as models trained on an order of magnitude more training data: we train ViT models of various sizes on the public ImageNet-21k dataset which either match or outperform their counterparts trained on the larger, but not publicly available JFT-300M dataset.
Knowledge distillation: A good teacher is patient and consistent
Jun 09, 2021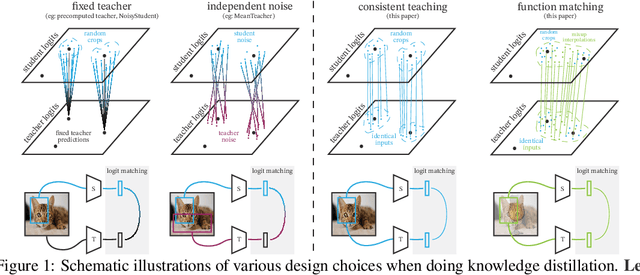
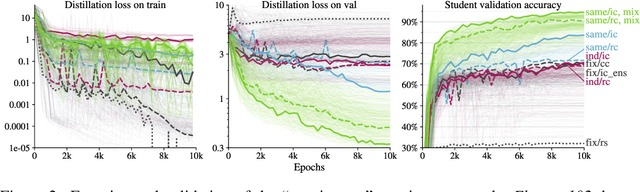

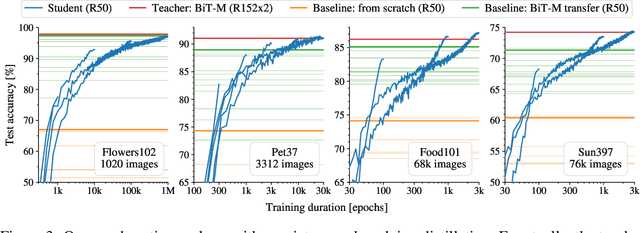
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8\% top-1 accuracy.