 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based approaches to Sentiment Detection
Mar 13, 2023



The use of transfer learning methods is largely responsible for the present breakthrough in Natural Learning Processing (NLP) tasks across multiple domains. In order to solve the problem of sentiment detection, we examined the performance of four different types of well-known state-of-the-art transformer models for text classification. Models such as Bidirectional Encoder Representations from Transformers (BERT), Robustly Optimized BERT Pre-training Approach (RoBERTa), a distilled version of BERT (DistilBERT), and a large bidirectional neural network architecture (XLNet) were proposed. The performance of the four models that were used to detect disaster in the text was compared. All the models performed well enough, indicating that transformer-based models are suitable for the detection of disaster in text. The RoBERTa transformer model performs best on the test dataset with a score of 82.6% and is highly recommended for quality predictions. Furthermore, we discovered that the learning algorithms' performance was influenced by the pre-processing techniques, the nature of words in the vocabulary, unbalanced labeling, and the model parameters.
Guilt Detection in Text: A Step Towards Understanding Complex Emotions
Mar 06, 2023



We introduce a novel Natural Language Processing (NLP) task called Guilt detection, which focuses on detecting guilt in text. We identify guilt as a complex and vital emotion that has not been previously studied in NLP, and we aim to provide a more fine-grained analysis of it. To address the lack of publicly available corpora for guilt detection, we created VIC, a dataset containing 4622 texts from three existing emotion detection datasets that we binarized into guilt and no-guilt classes. We experimented with traditional machine learning methods using bag-of-words and term frequency-inverse document frequency features, achieving a 72% f1 score with the highest-performing model. Our study provides a first step towards understanding guilt in text and opens the door for future research in this area.
ReDDIT: Regret Detection and Domain Identification from Text
Dec 14, 2022In this paper, we present a study of regret and its expression on social media platforms. Specifically, we present a novel dataset of Reddit texts that have been classified into three classes: Regret by Action, Regret by Inaction, and No Regret. We then use this dataset to investigate the language used to express regret on Reddit and to identify the domains of text that are most commonly associated with regret. Our findings show that Reddit users are most likely to express regret for past actions, particularly in the domain of relationships. We also found that deep learning models using GloVe embedding outperformed other models in all experiments, indicating the effectiveness of GloVe for representing the meaning and context of words in the domain of regret. Overall, our study provides valuable insights into the nature and prevalence of regret on social media, as well as the potential of deep learning and word embeddings for analyzing and understanding emotional language in online text. These findings have implications for the development of natural language processing algorithms and the design of social media platforms that support emotional expression and communication.
Sarcasm Detection Framework Using Emotion and Sentiment Features
Nov 23, 2022Sarcasm detection is an essential task that can help identify the actual sentiment in user-generated data, such as discussion forums or tweets. Sarcasm is a sophisticated form of linguistic expression because its surface meaning usually contradicts its inner, deeper meaning. Such incongruity is the essential component of sarcasm, however, it makes sarcasm detection quite a challenging task. In this paper, we propose a model which incorporates emotion and sentiment features to capture the incongruity intrinsic to sarcasm. Moreover, we use CNN and pre-trained Transformer to capture context features. Our approach achieved state-of-the-art results on four datasets from social networking platforms and online media.
PolyHope: Two-Level Hope Speech Detection from Tweets
Nov 03, 2022



Hope is characterized as openness of spirit toward the future, a desire, expectation, and wish for something to happen or to be true that remarkably affects human's state of mind, emotions, behaviors, and decisions. Hope is usually associated with concepts of desired expectations and possibility/probability concerning the future. Despite its importance, hope has rarely been studied as a social media analysis task. This paper presents a hope speech dataset that classifies each tweet first into "Hope" and "Not Hope", then into three fine-grained hope categories: "Generalized Hope", "Realistic Hope", and "Unrealistic Hope" (along with "Not Hope"). English tweets in the first half of 2022 were collected to build this dataset. Furthermore, we describe our annotation process and guidelines in detail and discuss the challenges of classifying hope and the limitations of the existing hope speech detection corpora. In addition, we reported several baselines based on different learning approaches, such as traditional machine learning, deep learning, and transformers, to benchmark our dataset. We evaluated our baselines using weighted-averaged and macro-averaged F1-scores. Observations show that a strict process for annotator selection and detailed annotation guidelines enhanced the dataset's quality. This strict annotation process resulted in promising performance for simple machine learning classifiers with only bi-grams; however, binary and multiclass hope speech detection results reveal that contextual embedding models have higher performance in this dataset.
The Effect of Normalization for Bi-directional Amharic-English Neural Machine Translation
Oct 27, 2022



Machine translation (MT) is one of the main tasks in natural language processing whose objective is to translate texts automatically from one natural language to another. Nowadays, using deep neural networks for MT tasks has received great attention. These networks require lots of data to learn abstract representations of the input and store it in continuous vectors. This paper presents the first relatively large-scale Amharic-English parallel sentence dataset. Using these compiled data, we build bi-directional Amharic-English translation models by fine-tuning the existing Facebook M2M100 pre-trained model achieving a BLEU score of 37.79 in Amharic-English 32.74 in English-Amharic translation. Additionally, we explore the effects of Amharic homophone normalization on the machine translation task. The results show that the normalization of Amharic homophone characters increases the performance of Amharic-English machine translation in both directions.
WikiDes: A Wikipedia-Based Dataset for Generating Short Descriptions from Paragraphs
Sep 27, 2022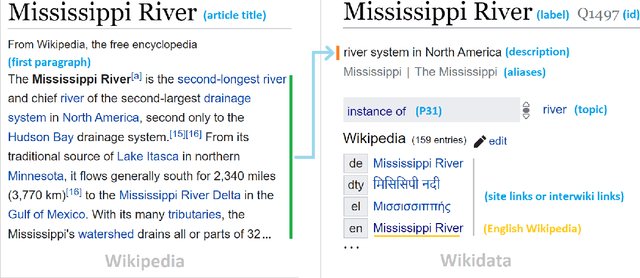
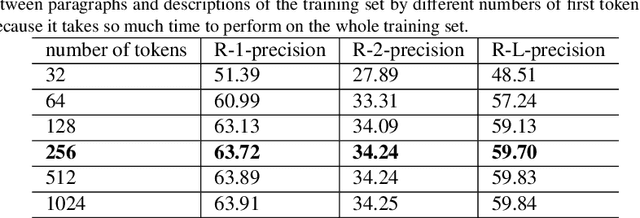

As free online encyclopedias with massive volumes of content, Wikipedia and Wikidata are key to many Natural Language Processing (NLP) tasks, such as information retrieval, knowledge base building, machine translation, text classification, and text summarization. In this paper, we introduce WikiDes, a novel dataset to generate short descriptions of Wikipedia articles for the problem of text summarization. The dataset consists of over 80k English samples on 6987 topics. We set up a two-phase summarization method - description generation (Phase I) and candidate ranking (Phase II) - as a strong approach that relies on transfer and contrastive learning. For description generation, T5 and BART show their superiority compared to other small-scale pre-trained models. By applying contrastive learning with the diverse input from beam search, the metric fusion-based ranking models outperform the direct description generation models significantly up to 22 ROUGE in topic-exclusive split and topic-independent split. Furthermore, the outcome descriptions in Phase II are supported by human evaluation in over 45.33% chosen compared to 23.66% in Phase I against the gold descriptions. In the aspect of sentiment analysis, the generated descriptions cannot effectively capture all sentiment polarities from paragraphs while doing this task better from the gold descriptions. The automatic generation of new descriptions reduces the human efforts in creating them and enriches Wikidata-based knowledge graphs. Our paper shows a practical impact on Wikipedia and Wikidata since there are thousands of missing descriptions. Finally, we expect WikiDes to be a useful dataset for related works in capturing salient information from short paragraphs. The curated dataset is publicly available at: https://github.com/declare-lab/WikiDes.
UrduFake@FIRE2020: Shared Track on Fake News Identification in Urdu
Jul 25, 2022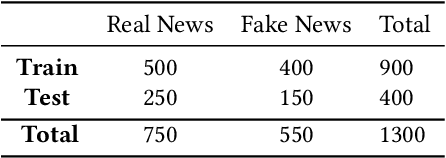

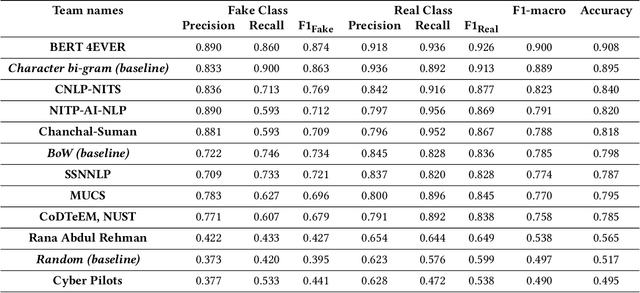
This paper gives the overview of the first shared task at FIRE 2020 on fake news detection in the Urdu language. This is a binary classification task in which the goal is to identify fake news using a dataset composed of 900 annotated news articles for training and 400 news articles for testing. The dataset contains news in five domains: (i) Health, (ii) Sports, (iii) Showbiz, (iv) Technology, and (v) Business. 42 teams from 6 different countries (India, China, Egypt, Germany, Pakistan, and the UK) registered for the task. 9 teams submitted their experimental results. The participants used various machine learning methods ranging from feature-based traditional machine learning to neural network techniques. The best performing system achieved an F-score value of 0.90, showing that the BERT-based approach outperforms other machine learning classifiers.
Overview of the Shared Task on Fake News Detection in Urdu at FIRE 2020
Jul 25, 2022
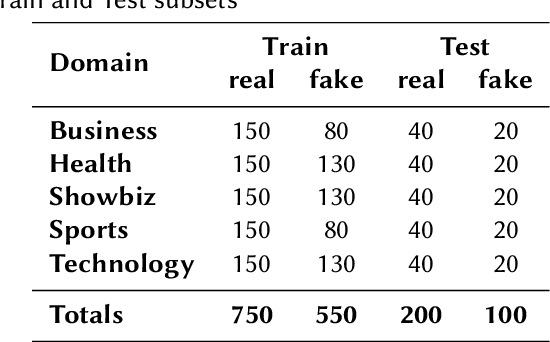
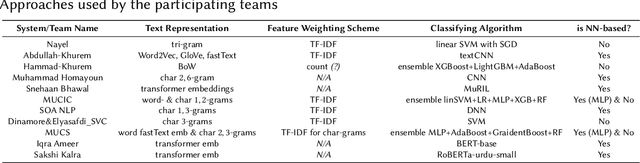
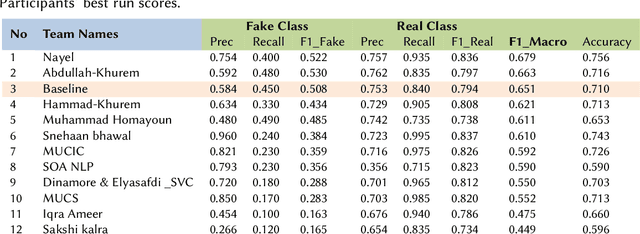
This overview paper describes the first shared task on fake news detection in Urdu language. The task was posed as a binary classification task, in which the goal is to differentiate between real and fake news. We provided a dataset divided into 900 annotated news articles for training and 400 news articles for testing. The dataset contained news in five domains: (i) Health, (ii) Sports, (iii) Showbiz, (iv) Technology, and (v) Business. 42 teams from 6 different countries (India, China, Egypt, Germany, Pakistan, and the UK) registered for the task. 9 teams submitted their experimental results. The participants used various machine learning methods ranging from feature-based traditional machine learning to neural networks techniques. The best performing system achieved an F-score value of 0.90, showing that the BERT-based approach outperforms other machine learning techniques
Overview of Abusive and Threatening Language Detection in Urdu at FIRE 2021
Jul 14, 2022



With the growth of social media platform influence, the effect of their misuse becomes more and more impactful. The importance of automatic detection of threatening and abusive language can not be overestimated. However, most of the existing studies and state-of-the-art methods focus on English as the target language, with limited work on low- and medium-resource languages. In this paper, we present two shared tasks of abusive and threatening language detection for the Urdu language which has more than 170 million speakers worldwide. Both are posed as binary classification tasks where participating systems are required to classify tweets in Urdu into two classes, namely: (i) Abusive and Non-Abusive for the first task, and (ii) Threatening and Non-Threatening for the second. We present two manually annotated datasets containing tweets labelled as (i) Abusive and Non-Abusive, and (ii) Threatening and Non-Threatening. The abusive dataset contains 2400 annotated tweets in the train part and 1100 annotated tweets in the test part. The threatening dataset contains 6000 annotated tweets in the train part and 3950 annotated tweets in the test part. We also provide logistic regression and BERT-based baseline classifiers for both tasks. In this shared task, 21 teams from six countries registered for participation (India, Pakistan, China, Malaysia, United Arab Emirates, and Taiwan), 10 teams submitted their runs for Subtask A, which is Abusive Language Detection and 9 teams submitted their runs for Subtask B, which is Threatening Language detection, and seven teams submitted their technical reports. The best performing system achieved an F1-score value of 0.880 for Subtask A and 0.545 for Subtask B. For both subtasks, m-Bert based transformer model showed the best performance.