 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustifying $\ell_\infty$ Adversarial Training to the Union of Perturbation Models
Jun 11, 2021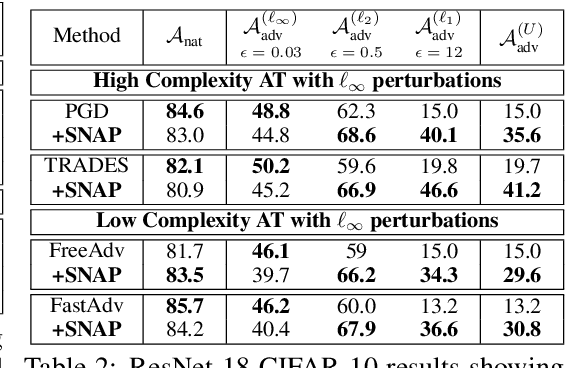
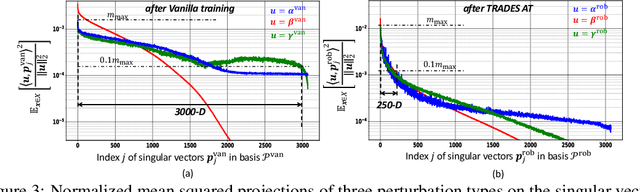
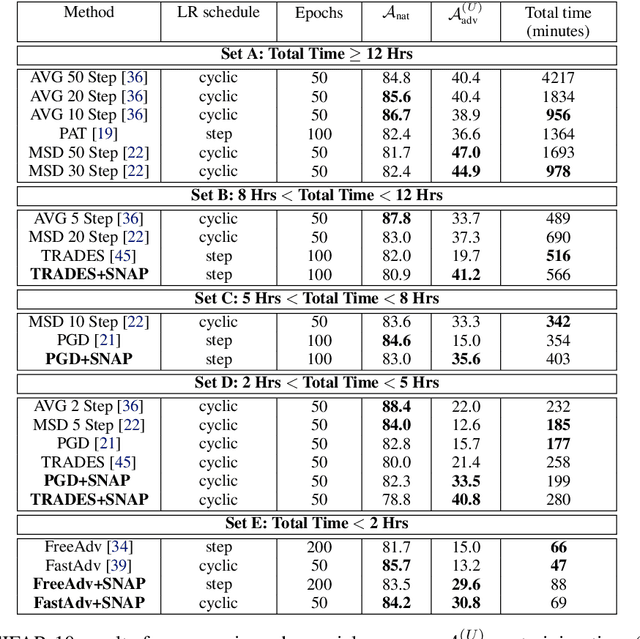
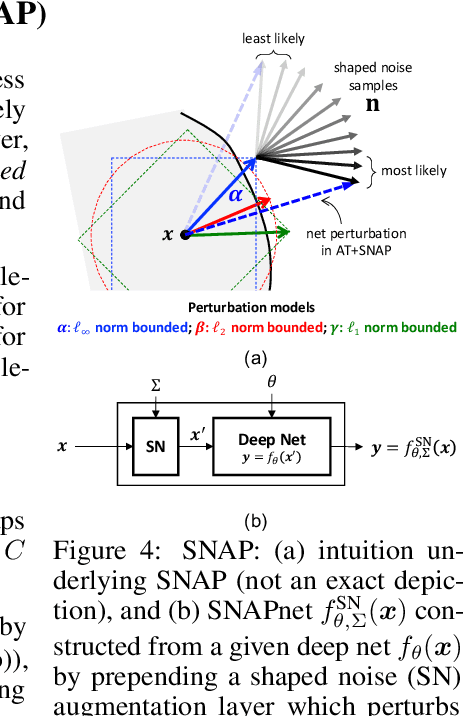
Classical adversarial training (AT) frameworks are designed to achieve high adversarial accuracy against a single attack type, typically $\ell_\infty$ norm-bounded perturbations. Recent extensions in AT have focused on defending against the union of multiple perturbations but this benefit is obtained at the expense of a significant (up to $10\times$) increase in training complexity over single-attack $\ell_\infty$ AT. In this work, we expand the capabilities of widely popular single-attack $\ell_\infty$ AT frameworks to provide robustness to the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations while preserving their training efficiency. Our technique, referred to as Shaped Noise Augmented Processing (SNAP), exploits a well-established byproduct of single-attack AT frameworks -- the reduction in the curvature of the decision boundary of networks. SNAP prepends a given deep net with a shaped noise augmentation layer whose distribution is learned along with network parameters using any standard single-attack AT. As a result, SNAP enhances adversarial accuracy of ResNet-18 on CIFAR-10 against the union of ($\ell_\infty, \ell_2, \ell_1$) perturbations by 14%-to-20% for four state-of-the-art (SOTA) single-attack $\ell_\infty$ AT frameworks, and, for the first time, establishes a benchmark for ResNet-50 and ResNet-101 on ImageNet.
SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction from Video Data
May 18, 2021
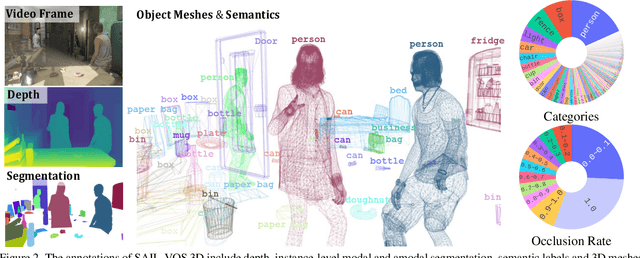

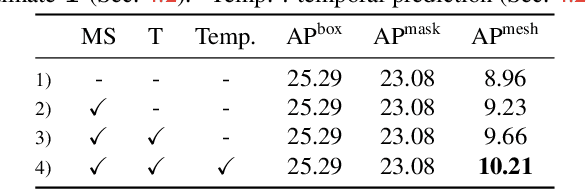
Extracting detailed 3D information of objects from video data is an important goal for holistic scene understanding. While recent methods have shown impressive results when reconstructing meshes of objects from a single image, results often remain ambiguous as part of the object is unobserved. Moreover, existing image-based datasets for mesh reconstruction don't permit to study models which integrate temporal information. To alleviate both concerns we present SAIL-VOS 3D: a synthetic video dataset with frame-by-frame mesh annotations which extends SAIL-VOS. We also develop first baselines for reconstruction of 3D meshes from video data via temporal models. We demonstrate efficacy of the proposed baseline on SAIL-VOS 3D and Pix3D, showing that temporal information improves reconstruction quality. Resources and additional information are available at http://sailvos.web.illinois.edu.
3D Spatial Recognition without Spatially Labeled 3D
May 13, 2021

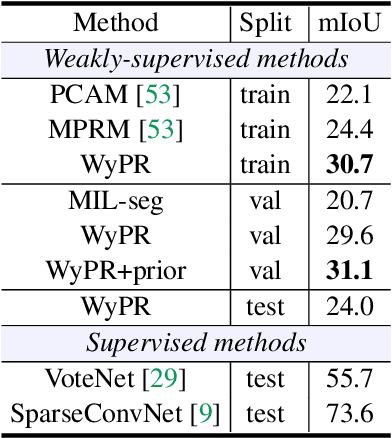

We introduce WyPR, a Weakly-supervised framework for Point cloud Recognition, requiring only scene-level class tags as supervision. WyPR jointly addresses three core 3D recognition tasks: point-level semantic segmentation, 3D proposal generation, and 3D object detection, coupling their predictions through self and cross-task consistency losses. We show that in conjunction with standard multiple-instance learning objectives, WyPR can detect and segment objects in point cloud data without access to any spatial labels at training time. We demonstrate its efficacy using the ScanNet and S3DIS datasets, outperforming prior state of the art on weakly-supervised segmentation by more than 6% mIoU. In addition, we set up the first benchmark for weakly-supervised 3D object detection on both datasets, where WyPR outperforms standard approaches and establishes strong baselines for future work.
DeepQAMVS: Query-Aware Hierarchical Pointer Networks for Multi-Video Summarization
May 13, 2021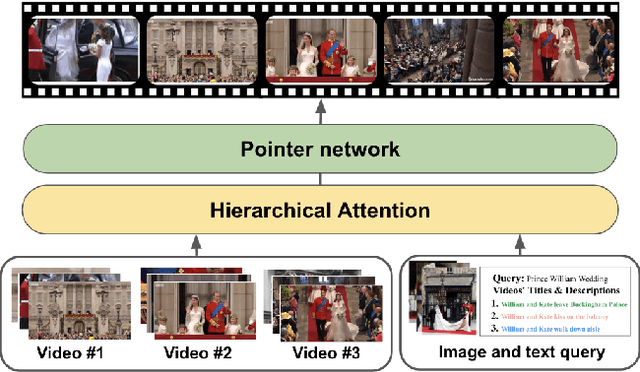
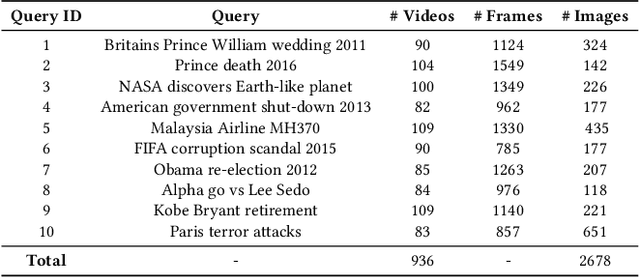
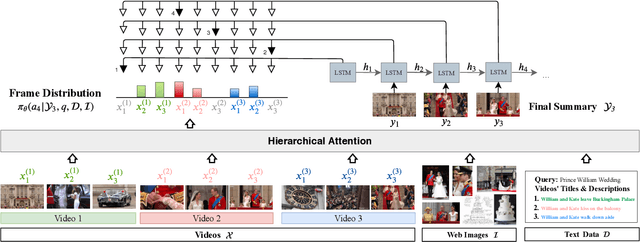
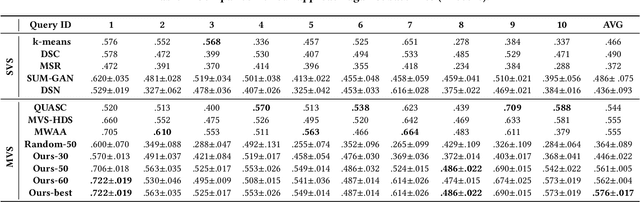
The recent growth of web video sharing platforms has increased the demand for systems that can efficiently browse, retrieve and summarize video content. Query-aware multi-video summarization is a promising technique that caters to this demand. In this work, we introduce a novel Query-Aware Hierarchical Pointer Network for Multi-Video Summarization, termed DeepQAMVS, that jointly optimizes multiple criteria: (1) conciseness, (2) representativeness of important query-relevant events and (3) chronological soundness. We design a hierarchical attention model that factorizes over three distributions, each collecting evidence from a different modality, followed by a pointer network that selects frames to include in the summary. DeepQAMVS is trained with reinforcement learning, incorporating rewards that capture representativeness, diversity, query-adaptability and temporal coherence. We achieve state-of-the-art results on the MVS1K dataset, with inference time scaling linearly with the number of input video frames.
Enjoy Your Editing: Controllable GANs for Image Editing via Latent Space Navigation
Feb 03, 2021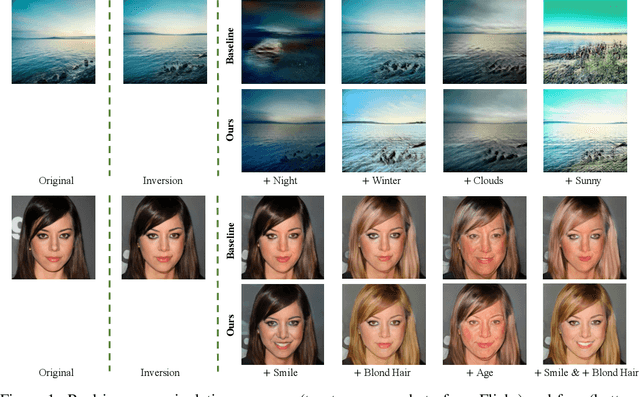
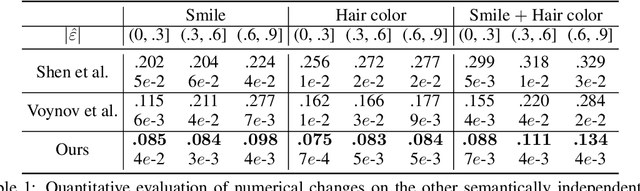
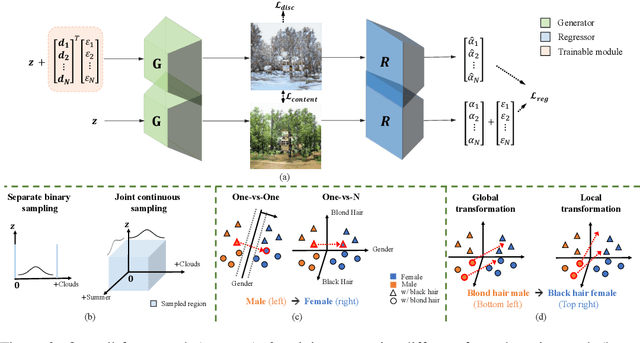
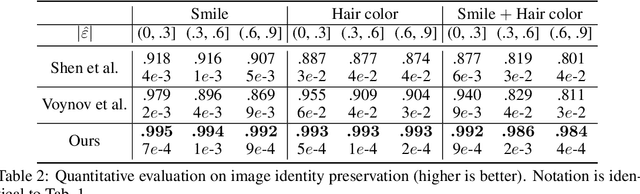
Controllable semantic image editing enables a user to change entire image attributes with few clicks, e.g., gradually making a summer scene look like it was taken in winter. Classic approaches for this task use a Generative Adversarial Net (GAN) to learn a latent space and suitable latent-space transformations. However, current approaches often suffer from attribute edits that are entangled, global image identity changes, and diminished photo-realism. To address these concerns, we learn multiple attribute transformations simultaneously, we integrate attribute regression into the training of transformation functions, apply a content loss and an adversarial loss that encourage the maintenance of image identity and photo-realism. We propose quantitative evaluation strategies for measuring controllable editing performance, unlike prior work which primarily focuses on qualitative evaluation. Our model permits better control for both single- and multiple-attribute editing, while also preserving image identity and realism during transformation. We provide empirical results for both real and synthetic images, highlighting that our model achieves state-of-the-art performance for targeted image manipulation.
High-Throughput Synchronous Deep RL
Dec 17, 2020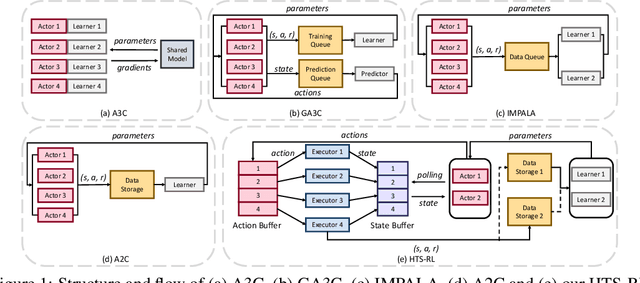
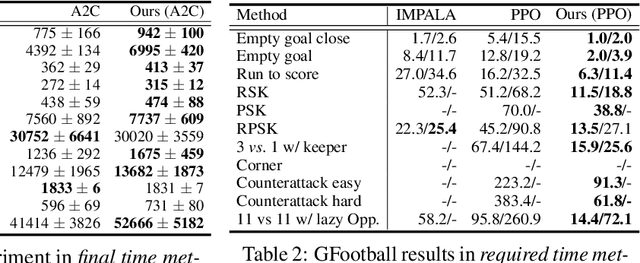

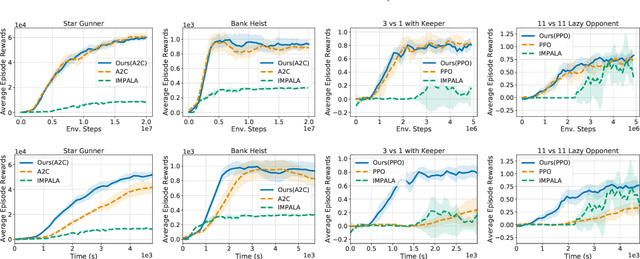
Deep reinforcement learning (RL) is computationally demanding and requires processing of many data points. Synchronous methods enjoy training stability while having lower data throughput. In contrast, asynchronous methods achieve high throughput but suffer from stability issues and lower sample efficiency due to `stale policies.' To combine the advantages of both methods we propose High-Throughput Synchronous Deep Reinforcement Learning (HTS-RL). In HTS-RL, we perform learning and rollouts concurrently, devise a system design which avoids `stale policies' and ensure that actors interact with environment replicas in an asynchronous manner while maintaining full determinism. We evaluate our approach on Atari games and the Google Research Football environment. Compared to synchronous baselines, HTS-RL is 2-6$\times$ faster. Compared to state-of-the-art asynchronous methods, HTS-RL has competitive throughput and consistently achieves higher average episode rewards.
UFO$^2$: A Unified Framework towards Omni-supervised Object Detection
Oct 21, 2020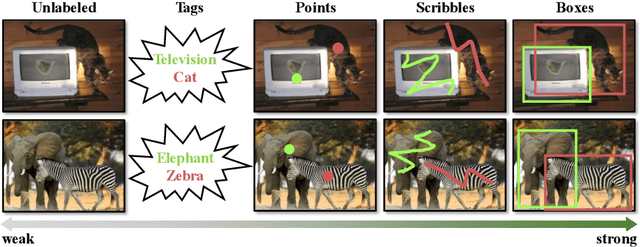


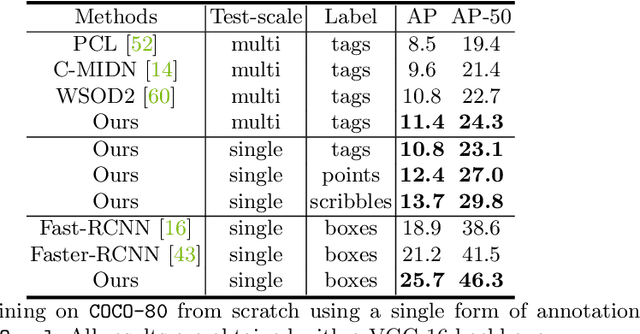
Existing work on object detection often relies on a single form of annotation: the model is trained using either accurate yet costly bounding boxes or cheaper but less expressive image-level tags. However, real-world annotations are often diverse in form, which challenges these existing works. In this paper, we present UFO$^2$, a unified object detection framework that can handle different forms of supervision simultaneously. Specifically, UFO$^2$ incorporates strong supervision (e.g., boxes), various forms of partial supervision (e.g., class tags, points, and scribbles), and unlabeled data. Through rigorous evaluations, we demonstrate that each form of label can be utilized to either train a model from scratch or to further improve a pre-trained model. We also use UFO$^2$ to investigate budget-aware omni-supervised learning, i.e., various annotation policies are studied under a fixed annotation budget: we show that competitive performance needs no strong labels for all data. Finally, we demonstrate the generalization of UFO$^2$, detecting more than 1,000 different objects without bounding box annotations.
Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning
Jul 02, 2020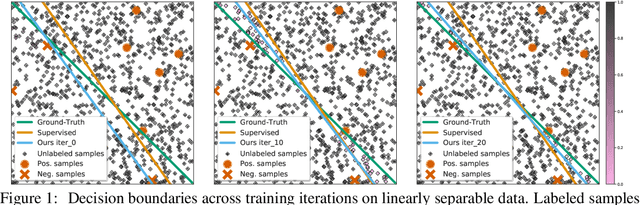
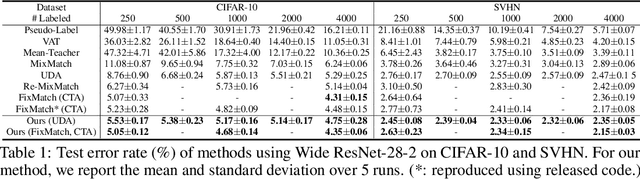
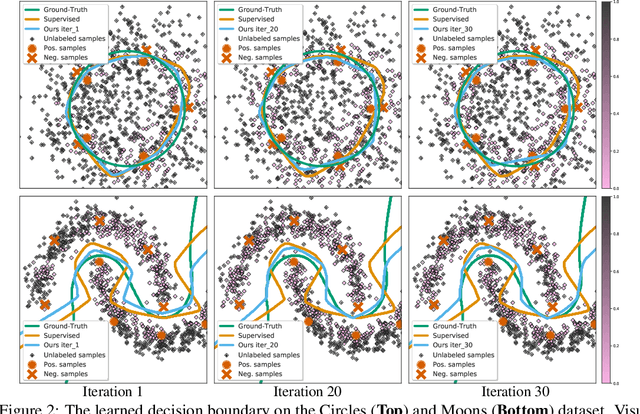
Existing semi-supervised learning (SSL) algorithms use a single weight to balance the loss of labeled and unlabeled examples, i.e., all unlabeled examples are equally weighted. But not all unlabeled data are equal. In this paper we study how to use a different weight for every unlabeled example. Manual tuning of all those weights -- as done in prior work -- is no longer possible. Instead, we adjust those weights via an algorithm based on the influence function, a measure of a model's dependency on one training example. To make the approach efficient, we propose a fast and effective approximation of the influence function. We demonstrate that this technique outperforms state-of-the-art methods on semi-supervised image and language classification tasks.
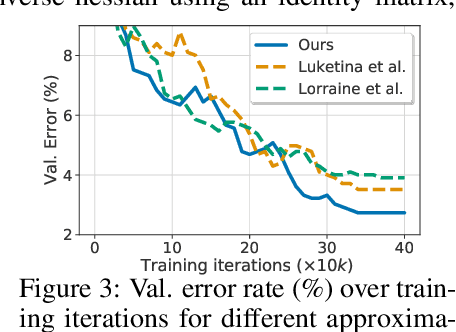
Can We Learn Heuristics For Graphical Model Inference Using Reinforcement Learning?
May 05, 2020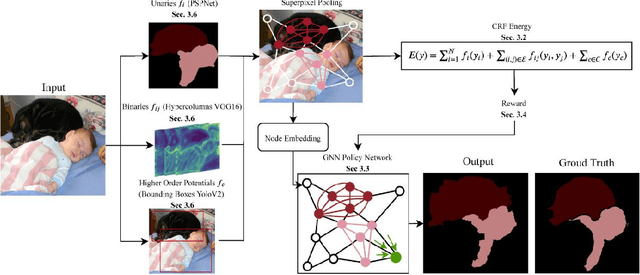

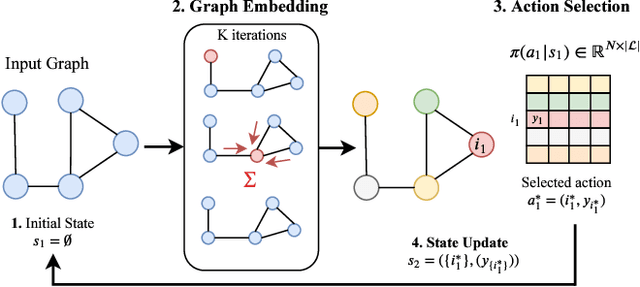
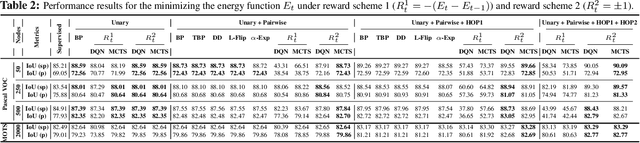
Combinatorial optimization is frequently used in computer vision. For instance, in applications like semantic segmentation, human pose estimation and action recognition, programs are formulated for solving inference in Conditional Random Fields (CRFs) to produce a structured output that is consistent with visual features of the image. However, solving inference in CRFs is in general intractable, and approximation methods are computationally demanding and limited to unary, pairwise and hand-crafted forms of higher order potentials. In this paper, we show that we can learn program heuristics, i.e., policies, for solving inference in higher order CRFs for the task of semantic segmentation, using reinforcement learning. Our method solves inference tasks efficiently without imposing any constraints on the form of the potentials. We show compelling results on the Pascal VOC and MOTS datasets.
Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object Detection
Apr 09, 2020
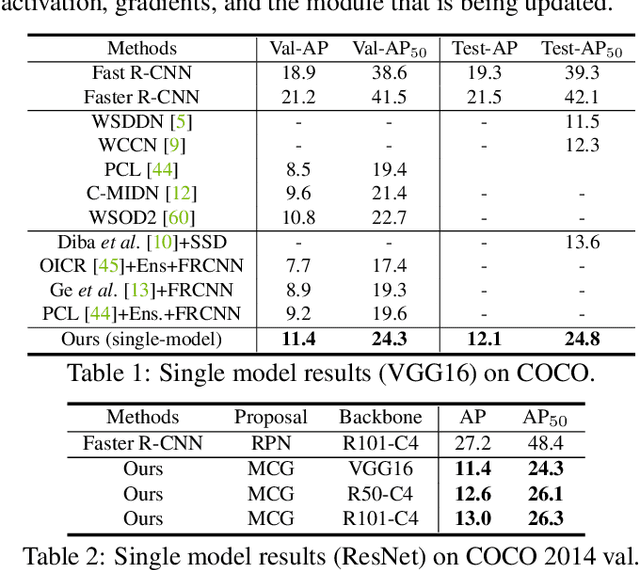
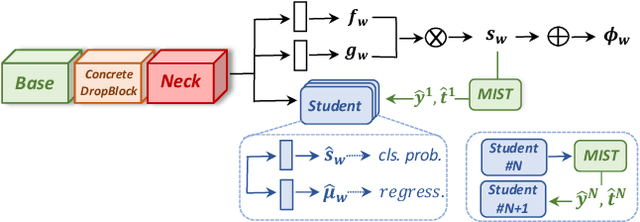
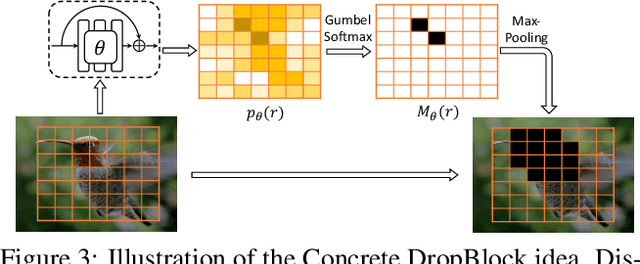
Weakly supervised learning has emerged as a compelling tool for object detection by reducing the need for strong supervision during training. However, major challenges remain: (1) differentiation of object instances can be ambiguous; (2) detectors tend to focus on discriminative parts rather than entire objects; (3) without ground truth, object proposals have to be redundant for high recalls, causing significant memory consumption. Addressing these challenges is difficult, as it often requires to eliminate uncertainties and trivial solutions. To target these issues we develop an instance-aware and context-focused unified framework. It employs an instance-aware self-training algorithm and a learnable Concrete DropBlock while devising a memory-efficient sequential batch back-propagation. Our proposed method achieves state-of-the-art results on COCO ($12.1\% ~AP$, $24.8\% ~AP_{50}$), VOC 2007 ($54.9\% ~AP$), and VOC 2012 ($52.1\% ~AP$), improving baselines by great margins. In addition, the proposed method is the first to benchmark ResNet based models and weakly supervised video object detection. Refer to our project page for code, models, and more details: https://github.com/NVlabs/wetectron.