 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today?
Oct 12, 2023



Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. To answer whether generalized dynamic novel view synthesis from monocular videos is possible today, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find a pseudo-generalized process without scene-specific appearance optimization is possible, but geometrically and temporally consistent depth estimates are needed. Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.
Property-Guided Generative Modelling for Robust Model-Based Design with Imbalanced Data
May 23, 2023



The problem of designing protein sequences with desired properties is challenging, as it requires to explore a high-dimensional protein sequence space with extremely sparse meaningful regions. This has led to the development of model-based optimization (MBO) techniques that aid in the design, by using effective search models guided by the properties over the sequence space. However, the intrinsic imbalanced nature of experimentally derived datasets causes existing MBO approaches to struggle or outright fail. We propose a property-guided variational auto-encoder (PGVAE) whose latent space is explicitly structured by the property values such that samples are prioritized according to these properties. Through extensive benchmarking on real and semi-synthetic protein datasets, we demonstrate that MBO with PGVAE robustly finds sequences with improved properties despite significant dataset imbalances. We further showcase the generality of our approach to continuous design spaces, and its robustness to dataset imbalance in an application to physics-informed neural networks.
CEIP: Combining Explicit and Implicit Priors for Reinforcement Learning with Demonstrations
Oct 18, 2022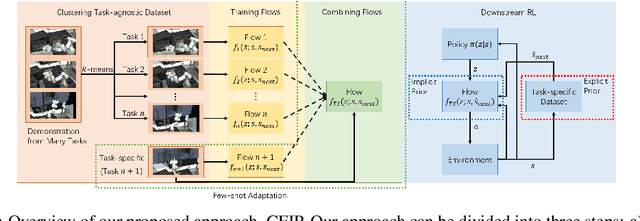
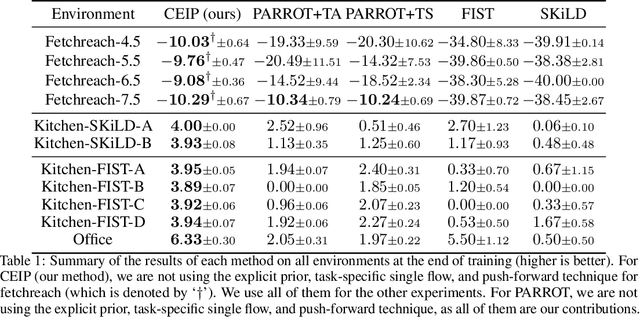
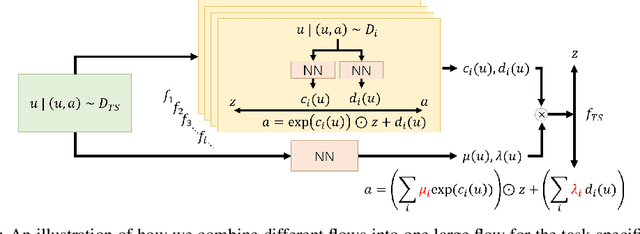

Although reinforcement learning has found widespread use in dense reward settings, training autonomous agents with sparse rewards remains challenging. To address this difficulty, prior work has shown promising results when using not only task-specific demonstrations but also task-agnostic albeit somewhat related demonstrations. In most cases, the available demonstrations are distilled into an implicit prior, commonly represented via a single deep net. Explicit priors in the form of a database that can be queried have also been shown to lead to encouraging results. To better benefit from available demonstrations, we develop a method to Combine Explicit and Implicit Priors (CEIP). CEIP exploits multiple implicit priors in the form of normalizing flows in parallel to form a single complex prior. Moreover, CEIP uses an effective explicit retrieval and push-forward mechanism to condition the implicit priors. In three challenging environments, we find the proposed CEIP method to improve upon sophisticated state-of-the-art techniques.
Learnable Polyphase Sampling for Shift Invariant and Equivariant Convolutional Networks
Oct 14, 2022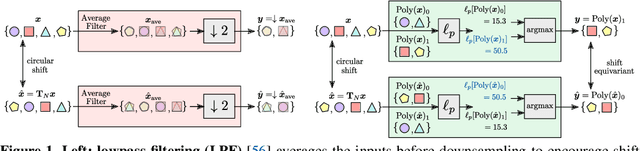
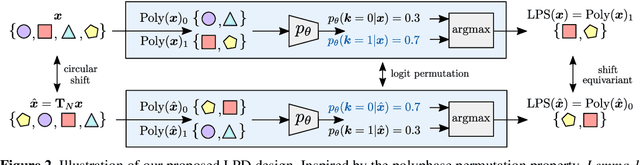
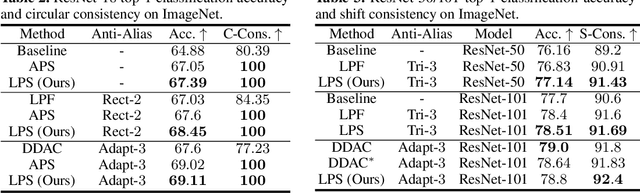
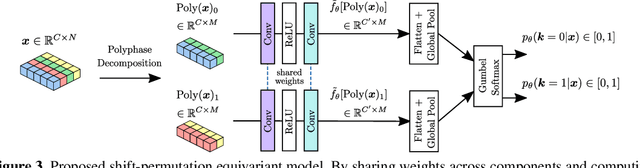
We propose learnable polyphase sampling (LPS), a pair of learnable down/upsampling layers that enable truly shift-invariant and equivariant convolutional networks. LPS can be trained end-to-end from data and generalizes existing handcrafted downsampling layers. It is widely applicable as it can be integrated into any convolutional network by replacing down/upsampling layers. We evaluate LPS on image classification and semantic segmentation. Experiments show that LPS is on-par with or outperforms existing methods in both performance and shift consistency. For the first time, we achieve true shift-equivariance on semantic segmentation (PASCAL VOC), i.e., 100% shift consistency, outperforming baselines by an absolute 3.3%.
Controllable Radiance Fields for Dynamic Face Synthesis
Oct 11, 2022
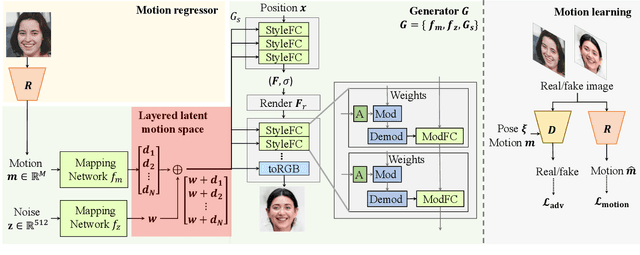
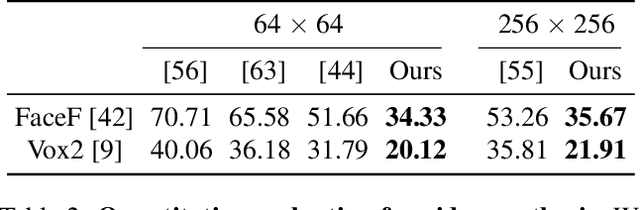
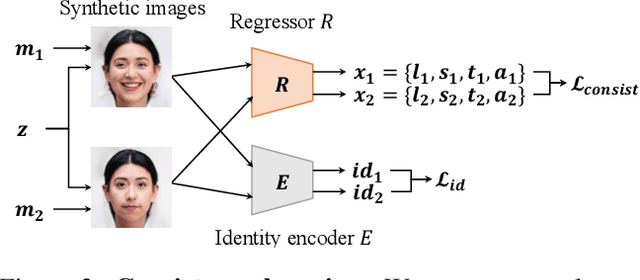
Recent work on 3D-aware image synthesis has achieved compelling results using advances in neural rendering. However, 3D-aware synthesis of face dynamics hasn't received much attention. Here, we study how to explicitly control generative model synthesis of face dynamics exhibiting non-rigid motion (e.g., facial expression change), while simultaneously ensuring 3D-awareness. For this we propose a Controllable Radiance Field (CoRF): 1) Motion control is achieved by embedding motion features within the layered latent motion space of a style-based generator; 2) To ensure consistency of background, motion features and subject-specific attributes such as lighting, texture, shapes, albedo, and identity, a face parsing net, a head regressor and an identity encoder are incorporated. On head image/video data we show that CoRFs are 3D-aware while enabling editing of identity, viewing directions, and motion.
Learning to Decompose Visual Features with Latent Textual Prompts
Oct 09, 2022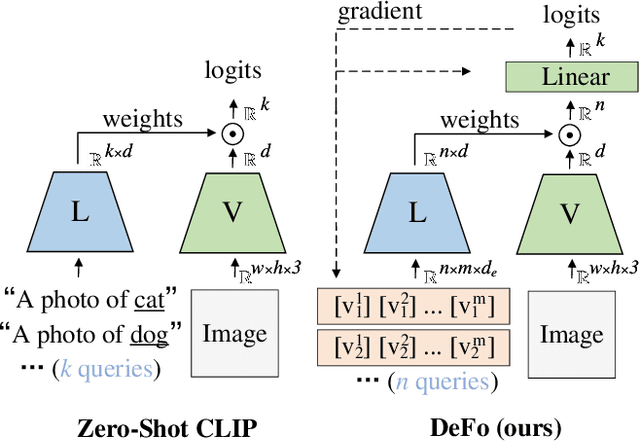
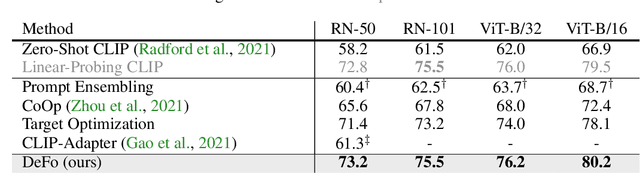

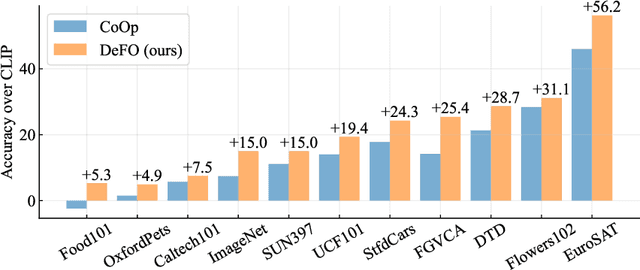
Recent advances in pre-training vision-language models like CLIP have shown great potential in learning transferable visual representations. Nonetheless, for downstream inference, CLIP-like models suffer from either 1) degraded accuracy and robustness in the case of inaccurate text descriptions during retrieval-based inference (the challenge for zero-shot protocol); or 2) breaking the well-established vision-language alignment (the challenge for linear probing). To address them, we propose Decomposed Feature Prompting (DeFo). DeFo leverages a flexible number of learnable embeddings as textual input while maintaining the vision-language dual-model architecture, which enables the model to learn decomposed visual features with the help of feature-level textual prompts. We further use an additional linear layer to perform classification, allowing a scalable size of language inputs. Our empirical study shows DeFo's significance in improving the vision-language models. For example, DeFo obtains 73.2% test accuracy on ImageNet with a ResNet-50 backbone without tuning any pretrained weights of both the vision and language encoder, outperforming zero-shot CLIP by a large margin of 15.0%, and outperforming state-of-the-art vision-language prompt tuning method by 7.6%.
Occupancy Planes for Single-view RGB-D Human Reconstruction
Aug 04, 2022
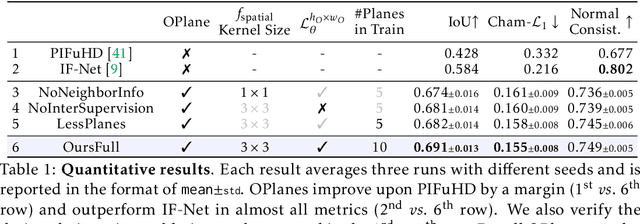
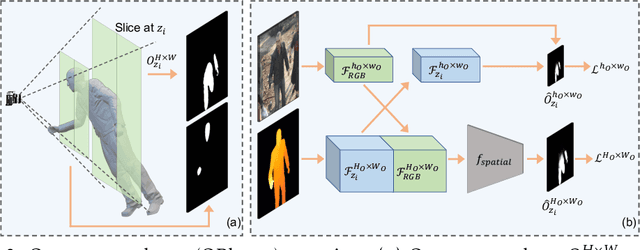
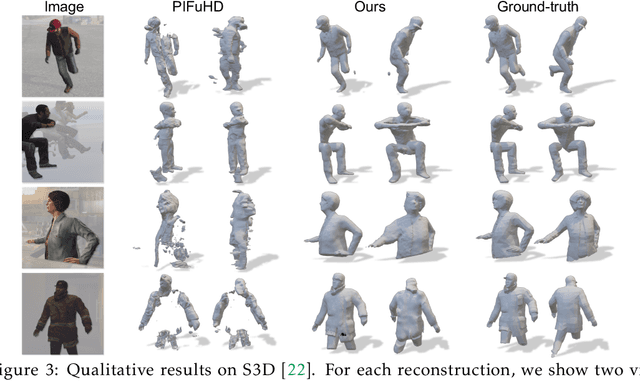
Single-view RGB-D human reconstruction with implicit functions is often formulated as per-point classification. Specifically, a set of 3D locations within the view-frustum of the camera are first projected independently onto the image and a corresponding feature is subsequently extracted for each 3D location. The feature of each 3D location is then used to classify independently whether the corresponding 3D point is inside or outside the observed object. This procedure leads to sub-optimal results because correlations between predictions for neighboring locations are only taken into account implicitly via the extracted features. For more accurate results we propose the occupancy planes (OPlanes) representation, which enables to formulate single-view RGB-D human reconstruction as occupancy prediction on planes which slice through the camera's view frustum. Such a representation provides more flexibility than voxel grids and enables to better leverage correlations than per-point classification. On the challenging S3D data we observe a simple classifier based on the OPlanes representation to yield compelling results, especially in difficult situations with partial occlusions due to other objects and partial visibility, which haven't been addressed by prior work.
Initialization and Alignment for Adversarial Texture Optimization
Jul 28, 2022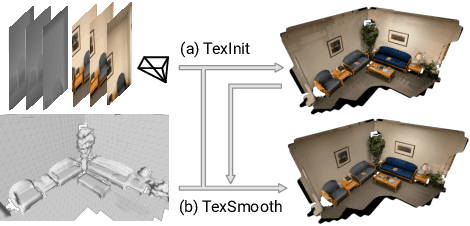
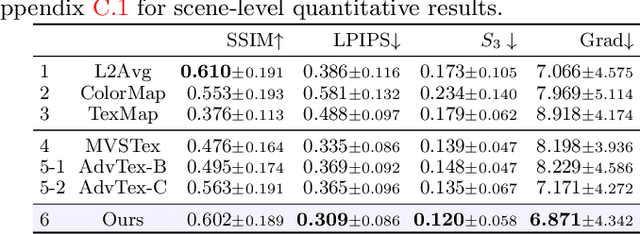

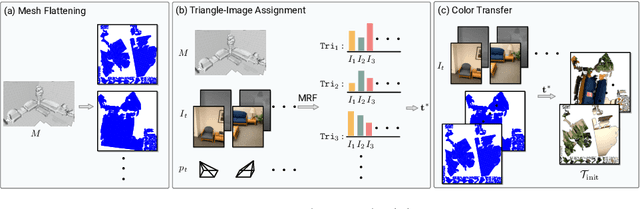
While recovery of geometry from image and video data has received a lot of attention in computer vision, methods to capture the texture for a given geometry are less mature. Specifically, classical methods for texture generation often assume clean geometry and reasonably well-aligned image data. While very recent methods, e.g., adversarial texture optimization, better handle lower-quality data obtained from hand-held devices, we find them to still struggle frequently. To improve robustness, particularly of recent adversarial texture optimization, we develop an explicit initialization and an alignment procedure. It deals with complex geometry due to a robust mapping of the geometry to the texture map and a hard-assignment-based initialization. It deals with misalignment of geometry and images by integrating fast image-alignment into the texture refinement optimization. We demonstrate efficacy of our texture generation on a dataset of 11 scenes with a total of 2807 frames, observing 7.8% and 11.1% relative improvements regarding perceptual and sharpness measurements.
Generative Multiplane Images: Making a 2D GAN 3D-Aware
Jul 21, 2022
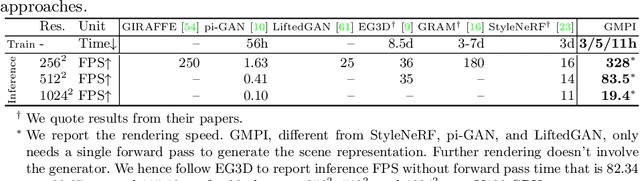
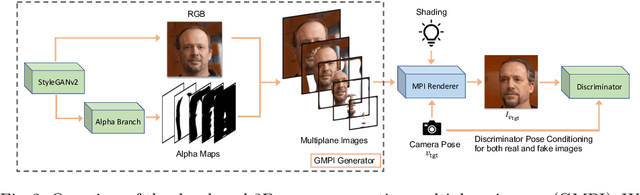
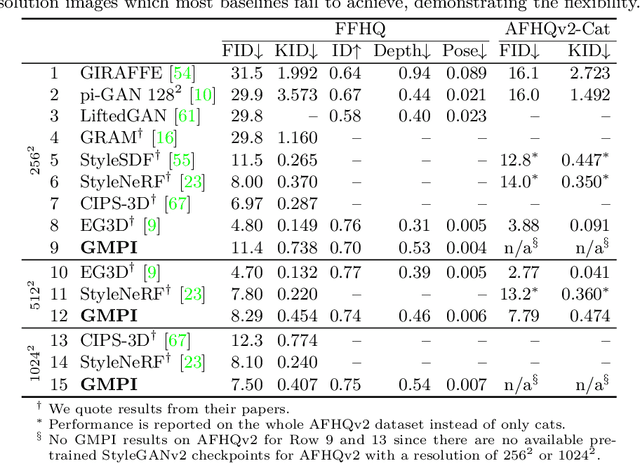
What is really needed to make an existing 2D GAN 3D-aware? To answer this question, we modify a classical GAN, i.e., StyleGANv2, as little as possible. We find that only two modifications are absolutely necessary: 1) a multiplane image style generator branch which produces a set of alpha maps conditioned on their depth; 2) a pose-conditioned discriminator. We refer to the generated output as a 'generative multiplane image' (GMPI) and emphasize that its renderings are not only high-quality but also guaranteed to be view-consistent, which makes GMPIs different from many prior works. Importantly, the number of alpha maps can be dynamically adjusted and can differ between training and inference, alleviating memory concerns and enabling fast training of GMPIs in less than half a day at a resolution of $1024^2$. Our findings are consistent across three challenging and common high-resolution datasets, including FFHQ, AFHQv2, and MetFaces.
XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
Jul 18, 2022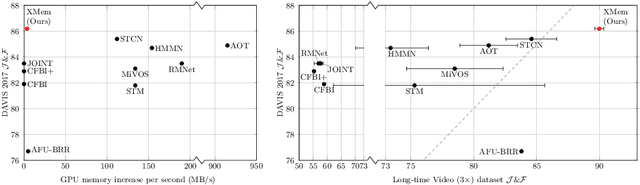

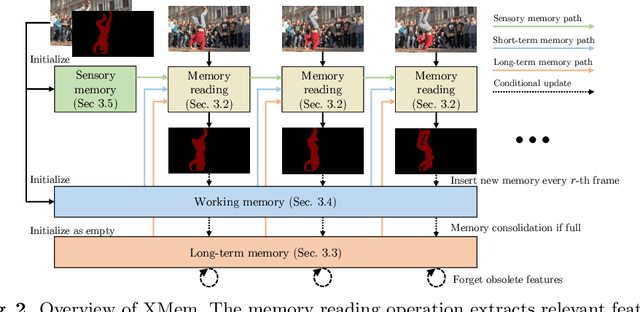
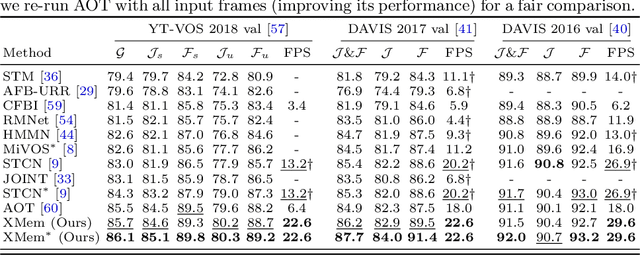
We present XMem, a video object segmentation architecture for long videos with unified feature memory stores inspired by the Atkinson-Shiffrin memory model. Prior work on video object segmentation typically only uses one type of feature memory. For videos longer than a minute, a single feature memory model tightly links memory consumption and accuracy. In contrast, following the Atkinson-Shiffrin model, we develop an architecture that incorporates multiple independent yet deeply-connected feature memory stores: a rapidly updated sensory memory, a high-resolution working memory, and a compact thus sustained long-term memory. Crucially, we develop a memory potentiation algorithm that routinely consolidates actively used working memory elements into the long-term memory, which avoids memory explosion and minimizes performance decay for long-term prediction. Combined with a new memory reading mechanism, XMem greatly exceeds state-of-the-art performance on long-video datasets while being on par with state-of-the-art methods (that do not work on long videos) on short-video datasets. Code is available at https://hkchengrex.github.io/XMem