 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Adversarial Supports in Few-shot Classifiers Using Feature Preserving Autoencoders and Self-Similarity
Dec 09, 2020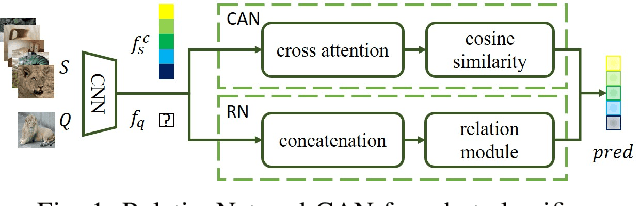
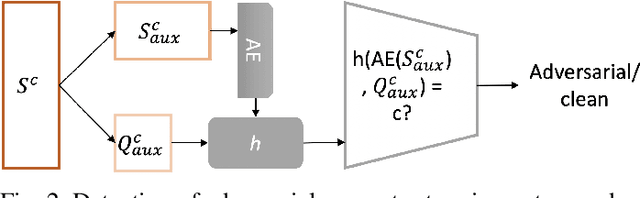
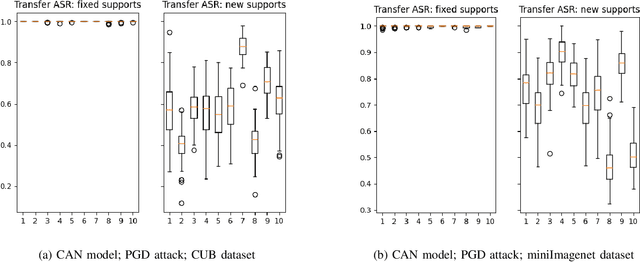
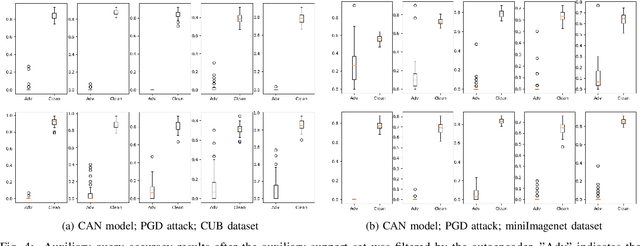
Few-shot classifiers excel under limited training samples, making it useful in real world applications. However, the advent of adversarial samples threatens the efficacy of such classifiers. For them to remain reliable, defences against such attacks must be explored. However, closer examination to prior literature reveals a big gap in this domain. Hence, in this work, we propose a detection strategy to highlight adversarial support sets, aiming to destroy a few-shot classifier's understanding of a certain class of objects. We make use of feature preserving autoencoder filtering and also the concept of self-similarity of a support set to perform this detection. As such, our method is attack-agnostic and also the first to explore detection for few-shot classifiers to the best of our knowledge. Our evaluation on the miniImagenet and CUB datasets exhibit optimism when employing our proposed approach, showing high AUROC scores for detection in general.
Deja vu from the SVM Era: Example-based Explanations with Outlier Detection
Nov 11, 2020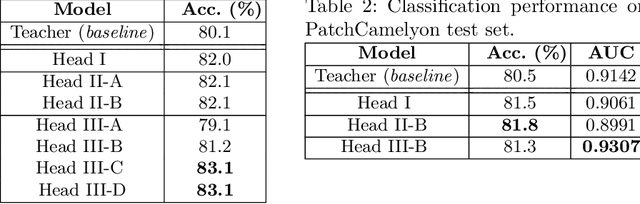
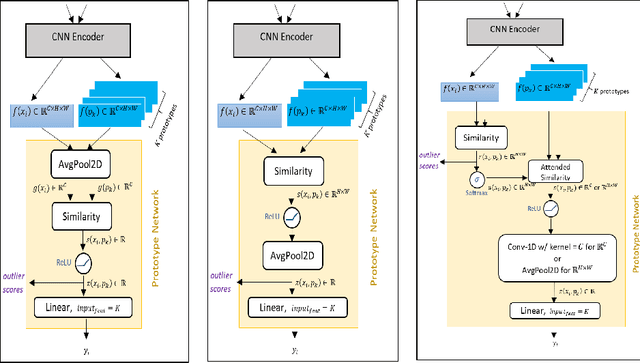
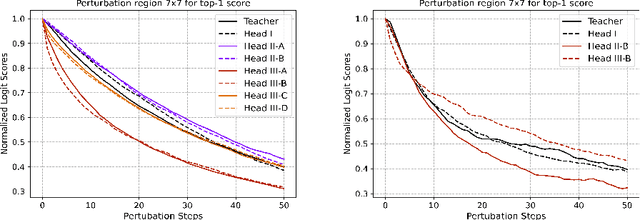
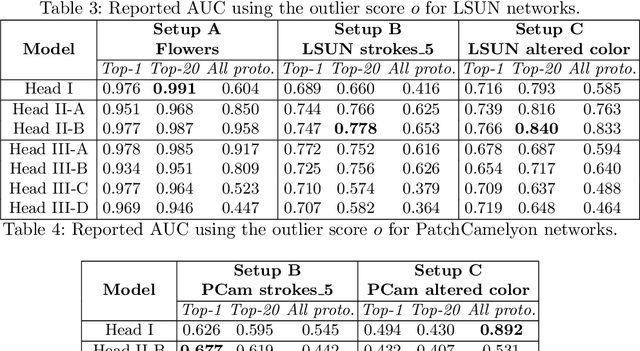
Understanding the features that contributed to a prediction is important for high-stake tasks. In this work, we revisit the idea of a student network to provide an example-based explanation for its prediction in two forms: i) identify top-k most relevant prototype examples and ii) show evidence of similarity between the prediction sample and each of the top-k prototypes. We compare the prediction performance and the explanation performance for the second type of explanation with the teacher network. In addition, we evaluate the outlier detection performance of the network. We show that using prototype-based students beyond similarity kernels deliver meaningful explanations and promising outlier detection results, without compromising on classification accuracy.
Lymphocyte counting -- Error Analysis of Regression versus Bounding Box Detection Approaches
Jul 21, 2020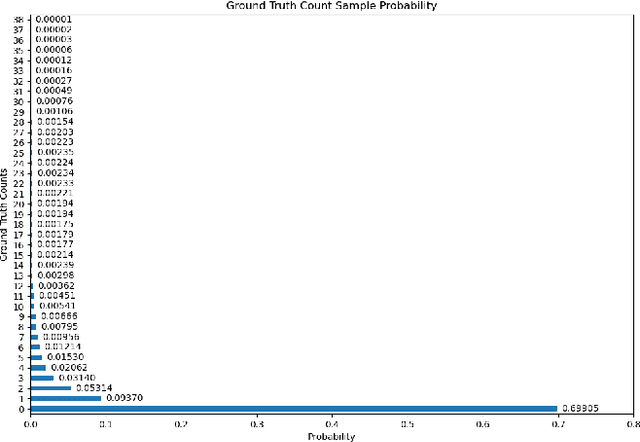
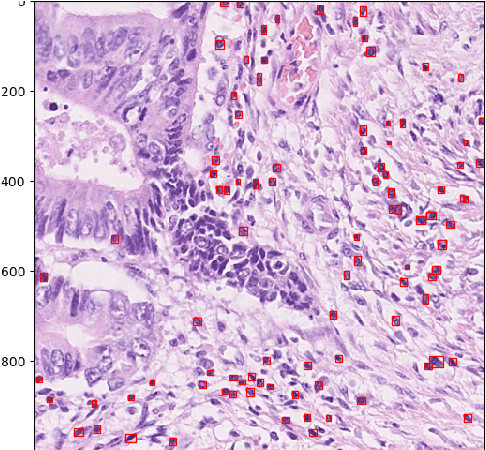
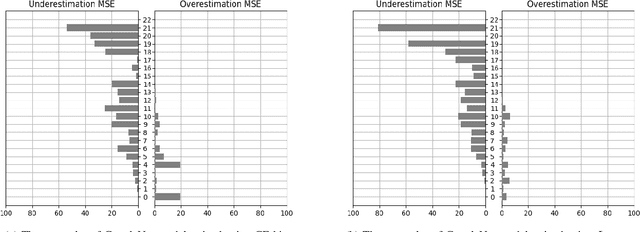
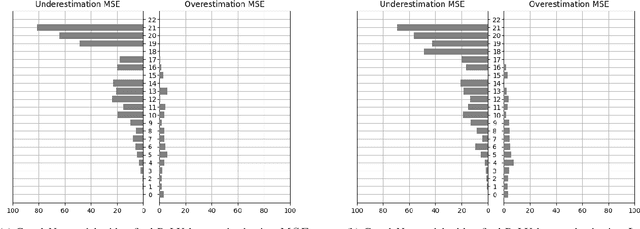
We consider the problem of counting cell nuclei from celltype-agnostic histopathological stains, exemplified here by the Haematoxylin and Eosin stain. We compare direct estimation by classification and regression against bounding box prediction models for a dataset with relatively low sample sizes. We find from a fine-grained analysis of MSE errors that all models suffer from a substantial underestimation bias. Detection models, while more capricious and sensitive in training, are more robust against underestimation in their optimum. Furthermore the simple idea of combining models from different prediction setups results in large improvements.
Explanation-Guided Training for Cross-Domain Few-Shot Classification
Jul 17, 2020
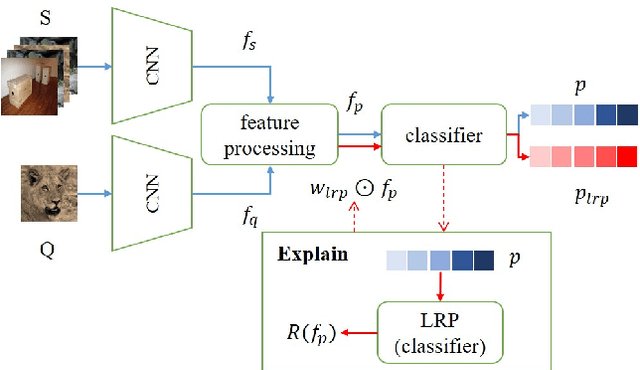
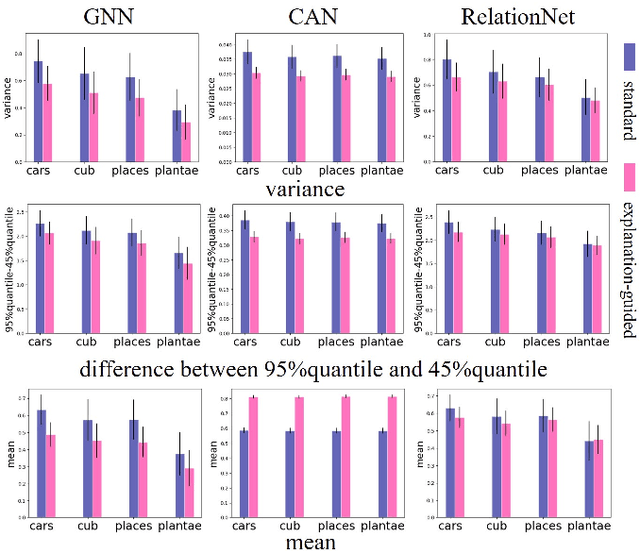
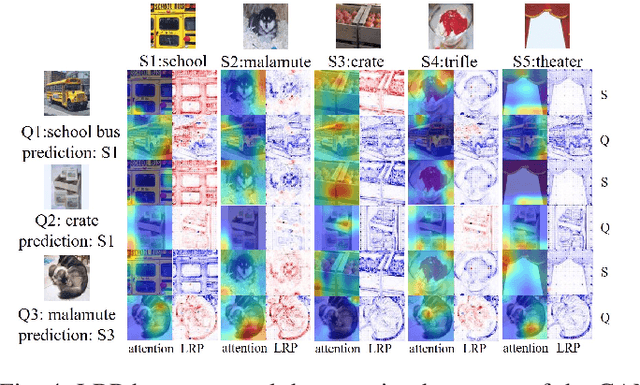
Cross-domain few-shot classification task (CD-FSC) combines few-shot classification with the requirement to generalize across domains represented by datasets. This setup faces challenges originating from the limited labeled data in each class and, additionally, from the domain shift between training and test sets. In this paper, we introduce a novel training approach for existing FSC models. It leverages on the explanation scores, obtained from existing explanation methods when applied to the predictions of FSC models, computed for intermediate feature maps of the models. Firstly, we tailor the layer-wise relevance propagation (LRP) method to explain the prediction outcomes of FSC models. Secondly, we develop a model-agnostic explanation-guided training strategy that dynamically finds and emphasizes the features which are important for the predictions. Our contribution does not target a novel explanation method but lies in a novel application of explanations for the training phase. We show that explanation-guided training effectively improves the model generalization. We observe improved accuracy for three different FSC models: RelationNet, cross attention network, and a graph neural network-based formulation, on five few-shot learning datasets: miniImagenet, CUB, Cars, Places, and Plantae.
Understanding Integrated Gradients with SmoothTaylor for Deep Neural Network Attribution
Apr 22, 2020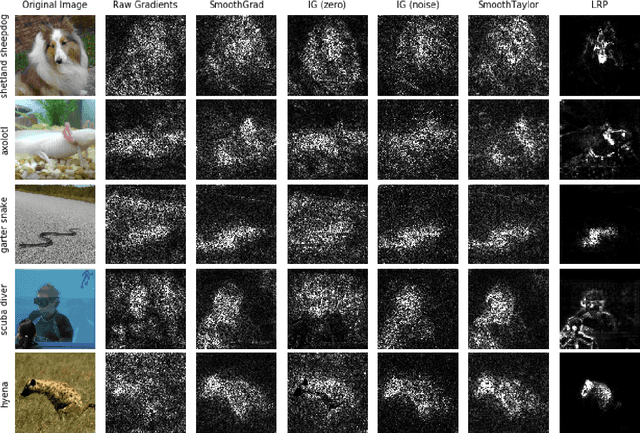
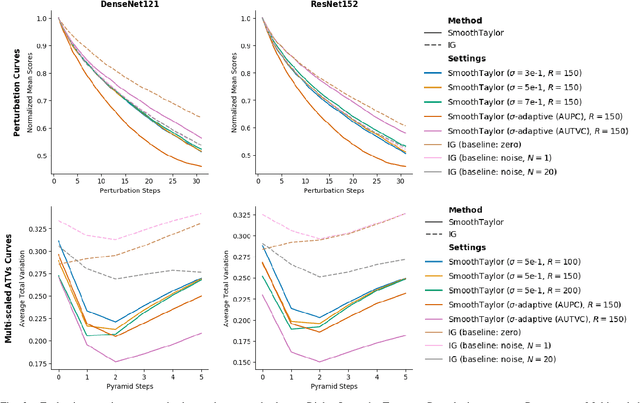
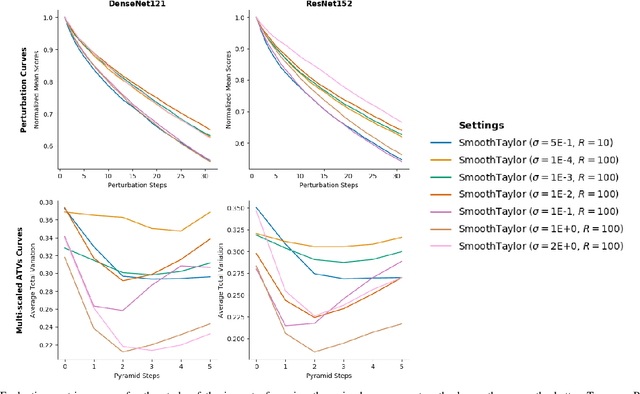
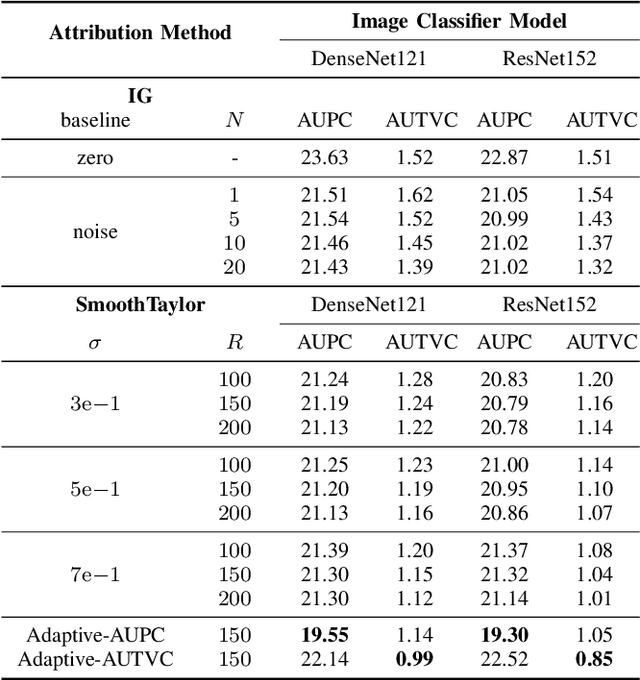
Integrated gradients as an attribution method for deep neural network models offers simple implementability. However, it also suffers from noisiness of explanations, which affects the ease of interpretability. In this paper, we present Smooth Integrated Gradients as a statistically improved attribution method inspired by Taylor's theorem, which does not require a fixed baseline to be chosen. We apply both methods to the image classification problem, using the ILSVRC2012 ImageNet object recognition dataset, and a couple of pretrained image models to generate attribution maps of their predictions. These attribution maps are visualized by saliency maps which can be evaluated qualitatively. We also empirically evaluate them using quantitative metrics such as perturbations-based score drops and multi-scaled total variance. We further propose adaptive noising to optimize for the noise scale hyperparameter value in our proposed method. From our experiments, we find that the Smooth Integrated Gradients approach together with adaptive noising is able to generate better quality saliency maps with lesser noise and higher sensitivity to the relevant points in the input space.
SideInfNet: A Deep Neural Network for Semi-Automatic Semantic Segmentation with Side Information
Mar 15, 2020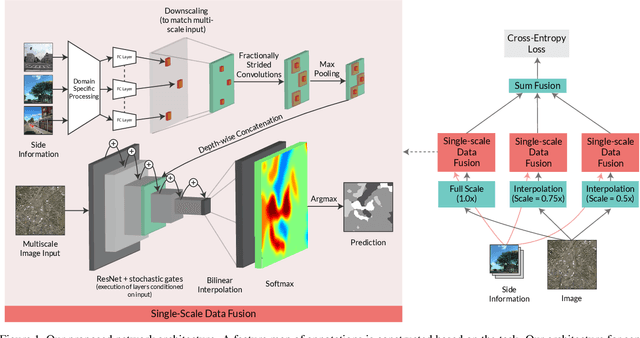
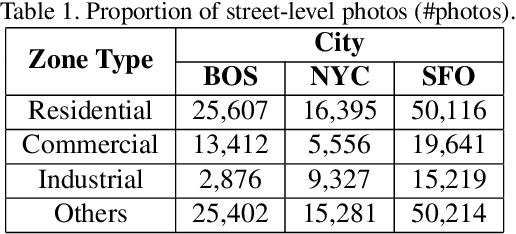

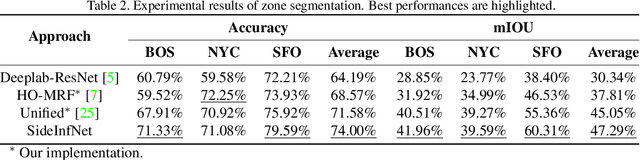
Fully-automatic execution is the ultimate goal for many Computer Vision applications. However, this objective is not always realistic in tasks associated with high failure costs, such as medical applications. For these tasks, a compromise between fully-automatic execution and user interactions is often preferred due to desirable accuracy and performance. Semi-automatic methods require minimal effort from experts by allowing them to provide cues that guide computer algorithms. Inspired by the practicality and applicability of the semi-automatic approach, this paper proposes a novel deep neural network architecture, namely SideInfNet that effectively integrates features learnt from images with side information extracted from user annotations to produce high quality semantic segmentation results. To evaluate our method, we applied the proposed network to three semantic segmentation tasks and conducted extensive experiments on benchmark datasets. Experimental results and comparison with prior work have verified the superiority of our model, suggesting the generality and effectiveness of the model in semi-automatic semantic segmentation.
Simple and Effective Prevention of Mode Collapse in Deep One-Class Classification
Jan 28, 2020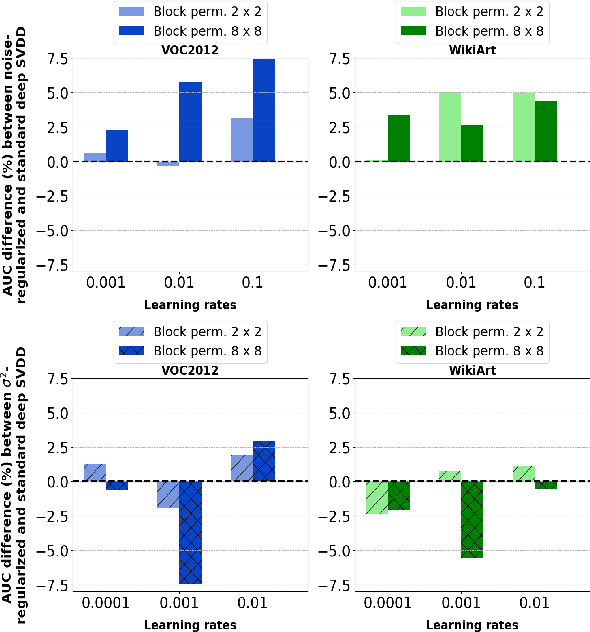
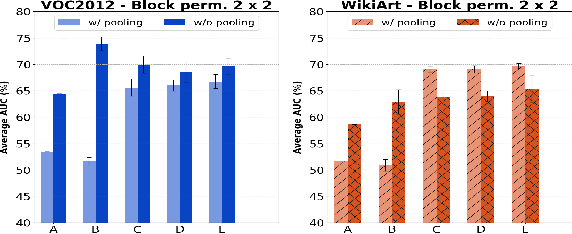
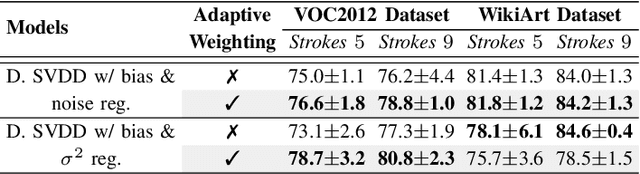
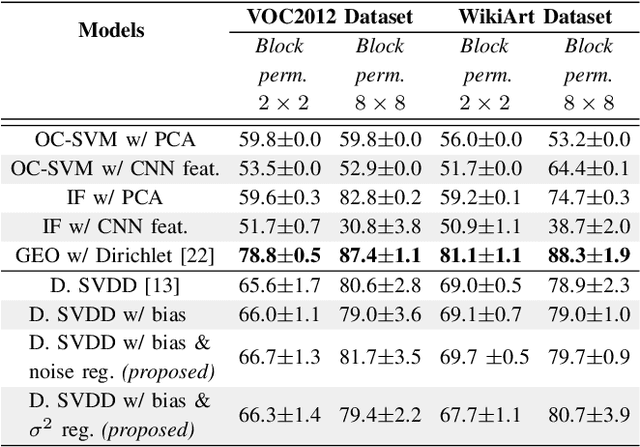
Anomaly detection algorithms find extensive use in various fields. This area of research has recently made great advances thanks to deep learning. A recent method, the deep Support Vector Data Description (deep SVDD), which is inspired by the classic kernel-based Support Vector Data Description (SVDD), is capable of simultaneously learning a feature representation of the data and a data-enclosing hypersphere. The method has shown promising results in both unsupervised and semi-supervised settings. However, deep SVDD suffers from hypersphere collapse---also known as mode collapse---, if the architecture of the model does not comply with certain architectural constraints, e.g. the removal of bias terms. These constraints limit the adaptability of the model and in some cases, may affect the model performance due to learning sub-optimal features. In this work, we consider two regularizers to prevent hypersphere collapse in deep SVDD. The first regularizer is based on injecting random noise via the standard cross-entropy loss. The second regularizer penalizes the minibatch variance when it becomes too small. Moreover, we introduce an adaptive weighting scheme to control the amount of penalization between the SVDD loss and the respective regularizer. Our proposed regularized variants of deep SVDD show encouraging results and outperform a prominent state-of-the-art method on a setup where the anomalies have no apparent geometrical structure.
Understanding Image Captioning Models beyond Visualizing Attention
Jan 22, 2020

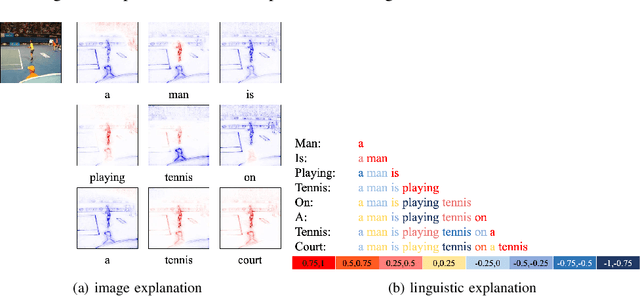
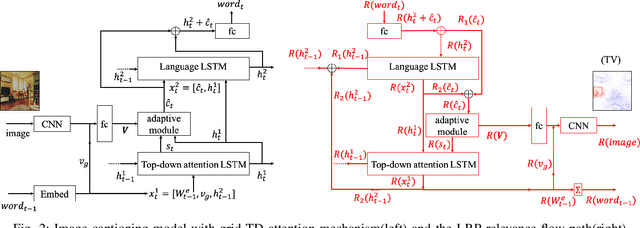
This paper explains predictions of image captioning models with attention mechanisms beyond visualizing the attention itself. In this paper, we develop variants of layer-wise relevance backpropagation (LRP) and gradient backpropagation, tailored to image captioning with attention. The result provides simultaneously pixel-wise image explanation and linguistic explanation for each word in the captions. We show that given a word in the caption to be explained, explanation methods such as LRP reveal supporting and opposing pixels as well as words. We compare the properties of attention heatmaps systematically against those computed with explanation methods such as LRP, Grad-CAM and Guided Grad-CAM. We show that explanation methods, firstly, correlate to object locations with higher precision than attention, secondly, are able to identify object words that are unsupported by image content, and thirdly, provide guidance to debias and improve the model. Results are reported for image captioning using two different attention models trained with Flickr30K and MSCOCO2017 datasets. Experimental analyses show the strength of explanation methods for understanding image captioning attention models.
Exploring the Back Alleys: Analysing The Robustness of Alternative Neural Network Architectures against Adversarial Attacks
Jan 07, 2020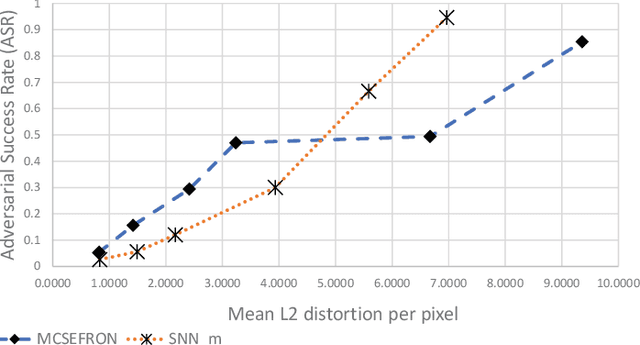
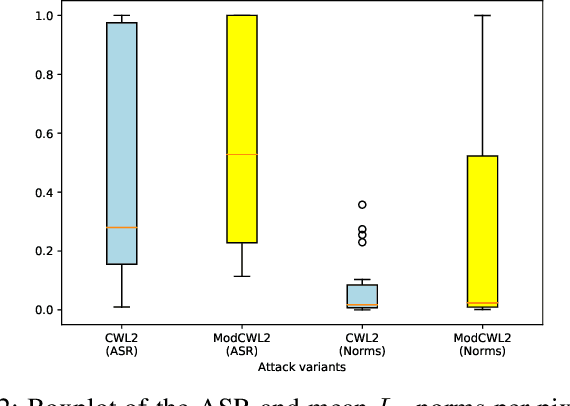

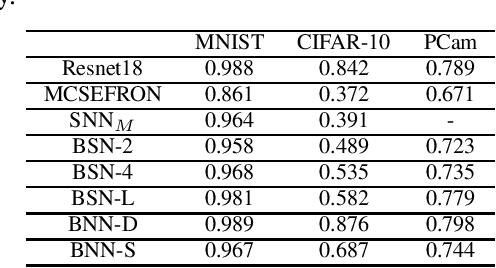
Recent discoveries in the field of adversarial machine learning have shown that Artificial Neural Networks (ANNs) are susceptible to adversarial attacks. These attacks cause misclassification of specially crafted adversarial samples. In light of this phenomenon, it is worth investigating whether other types of neural networks are less susceptible to adversarial attacks. In this work, we applied standard attack methods originally aimed at conventional ANNs, towards stochastic ANNs and also towards Spiking Neural Networks (SNNs), across three different datasets namely MNIST, CIFAR-10 and Patch Camelyon. We analysed their adversarial robustness against attacks performed in the raw image space of the different model variants. We employ a variety of attacks namely Basic Iterative Method (BIM), Carlini & Wagner L2 attack (CWL2) and Boundary attack. Our results suggests that SNNs and stochastic ANNs exhibit some degree of adversarial robustness as compared to their ANN counterparts under certain attack methods. Namely, we found that the Boundary and the state-of-the-art CWL2 attacks are largely ineffective against stochastic ANNs. Following this observation, we proposed a modified version of the CWL2 attack and analysed the impact of this attack on the models' adversarial robustness. Our results suggest that with this modified CWL2 attack, many models are more easily fooled as compared to the vanilla CWL2 attack, albeit observing an increase in L2 norms of adversarial perturbations. Lastly, we also investigate the resilience of alternative neural networks against adversarial samples transferred from ResNet18. We show that the modified CWL2 attack provides an improved cross-architecture transferability compared to other attacks.
Towards best practice in explaining neural network decisions with LRP
Oct 22, 2019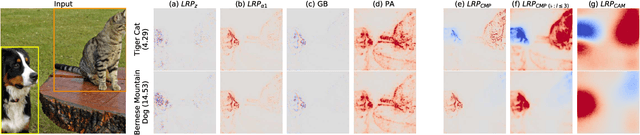
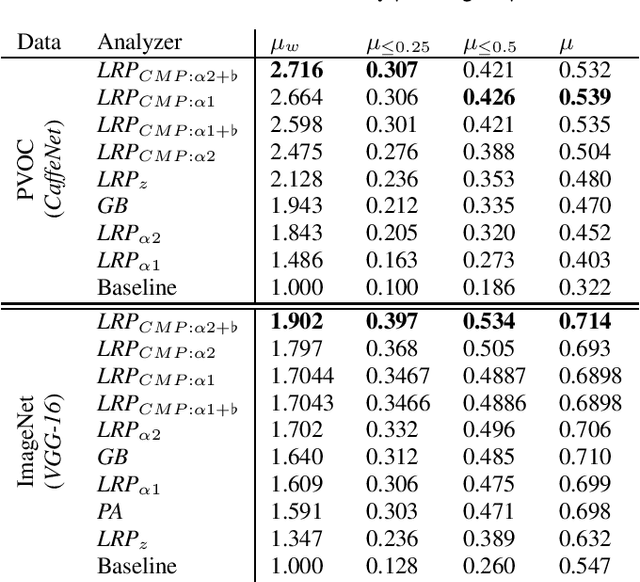
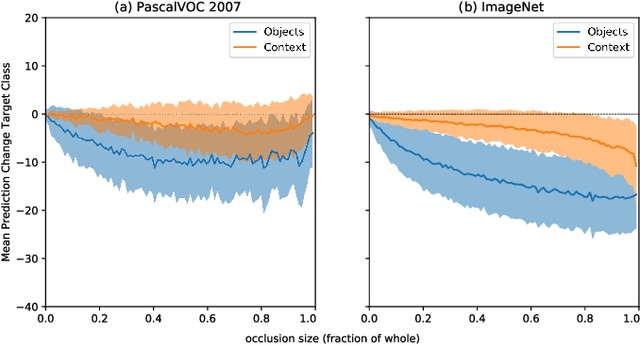
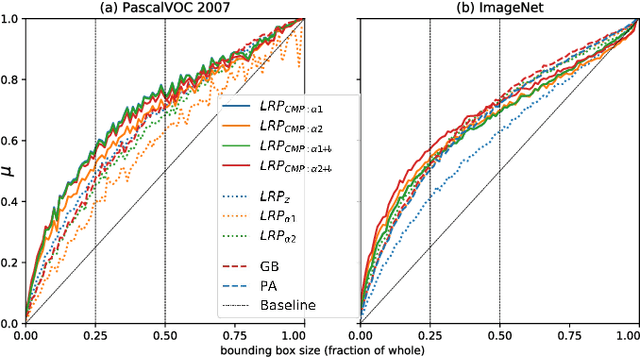
Within the last decade, neural network based predictors have demonstrated impressive - and at times super-human - capabilities. This performance is often paid for with an intransparent prediction process and thus has sparked numerous contributions in the novel field of explainable artificial intelligence (XAI). In this paper, we focus on a popular and widely used method of XAI, the Layer-wise Relevance Propagation (LRP). Since its initial proposition LRP has evolved as a method, and a best practice for applying the method has tacitly emerged, based on humanly observed evidence. We investigate - and for the first time quantify - the effect of this current best practice on feedforward neural networks in a visual object detection setting. The results verify that the current, layer-dependent approach to LRP applied in recent literature better represents the model's reasoning, and at the same time increases the object localization and class discriminativity of LRP.